Yolov4-Tiny讲解
https://www.bilibili.com/video/BV18h411d7by?p=4
Yolov4-Tiny-backbone

Github-代码下载
https://github.com/bubbliiiing/yolov4-tiny-pytorch
数据集下载
这里用的数据集是VOC2007或者2012
官网下载地址:https://pjreddie.com/projects/pascal-voc-dataset-mirror/

下载好了之后。目录为下图

数据集处理
找到voc_annotation.py文件,修改对应的数据集路径

训练后生成 只有2007_train.txt有东西,我们训练的时候只需要这个文件,所以其它的无关紧要,然后就可以开始训练了。
只有2007_train.txt有东西,我们训练的时候只需要这个文件,所以其它的无关紧要,然后就可以开始训练了。
训练网络
从github下载下来之后就可以先修改训练类别的路径(和数据集所需要的类别保持一致,如果有自己的数据集,就按照VOC格式生成,并载入自己的类别名就好了),然后就可以运行train.py了。

其它的就没有什么可以改的了,如果环境配置也没问题的话,其实最主要就是pytorch的环境,其它的看需要pip install就好了。然后开始训练
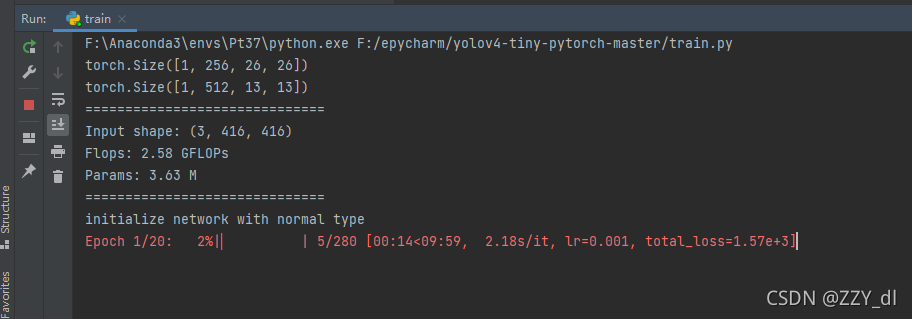
预测网络
这里包括三种预测的方式:1.测试图片 2.测试视频 3.测试摄像头 4.测试图片的fps,修改yolo.py里的这两个位置,一个是你训练好的模型,一个是你的类别文件,然后,打开predict.py,选择你想要预测的方式,就可以开始预测。


我训练50次之后的结果(没有加预训练模型)
测试图片:


评估网络
这里用Map来进行评估,map就是所有类的AP50-95的平均值,50指的是iou=0.5,95指的是iou=0.95,iou指的是预测框和真实框的交并比。越大说明预测结果越准确。
1.找到
2.修改16,17行,分别是VOC2007中所有sml文件的路径和你想要保存结果的路径(建议别放在你原来的VOC数据集中)

3.如果你想要拥有测试集就将trainval_percent的值修改为0.9,这样里面所有的图片就会有1%生成为测试集
4.然后开始运行voc2yolo4.py,就可以看到生成下面的4个txt文档

5.找到get_gt_txt.py然后修改image_ids所对应的路径,也就是上面我们得到的test.txt。

运行后就可以生成下面这个文件夹a,里面的每个结果是类别+坐标位置

6.生成检测结果的文件夹,为了和原始框做对比,通过get_dr_txt.py,需要注意以下地方。
- 36行:将confidence设置为0.01,因为后面计算map是要通过iou进行筛选的,所以这里应该设置得低一些
- 117行:测试的test.txt需要和生成ground_truth的测试文件保持一致
- 127行:修改成对应的JPEGImage文件的路径
运行结果如下:

7.直接运行get_map.py就可以得到所有的值得map,以及各类的ap指标。

这是没有进行预训练的mAP,如果进行了预训练应该能提升接近一倍。

