RNN 递归

本质上就是数学,各种模型只是去拟合一个数学公式或者函数而已,既然是函数,就明确好输入和输出

CNN 窗口遍历

attention,没个词做注意力计算

本质理解,不同维度的序列转换

调节因子的作用
注意力只是一种方式,不一定是点乘

参数不共享然后结果拼接

数学公式

一步到位捕捉全局信息


多头借鉴CNN的多个卷积核的思想
局部注意力借鉴了卷积窗口的思想
本质上是相同的
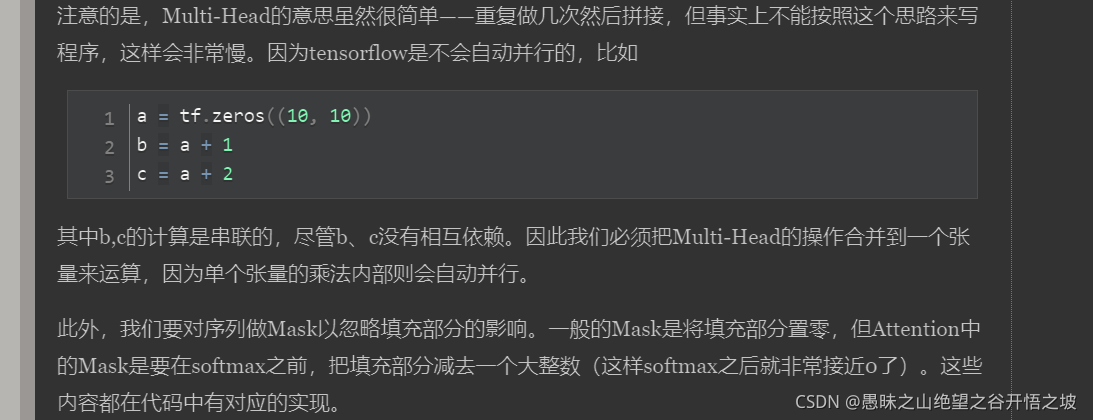
代码实现除了遵循原文公式还要考虑效率问题,会有不一样的操作,tf不能并行,mask机制等

三次序列映射,KQV,两次矩阵乘法
问题
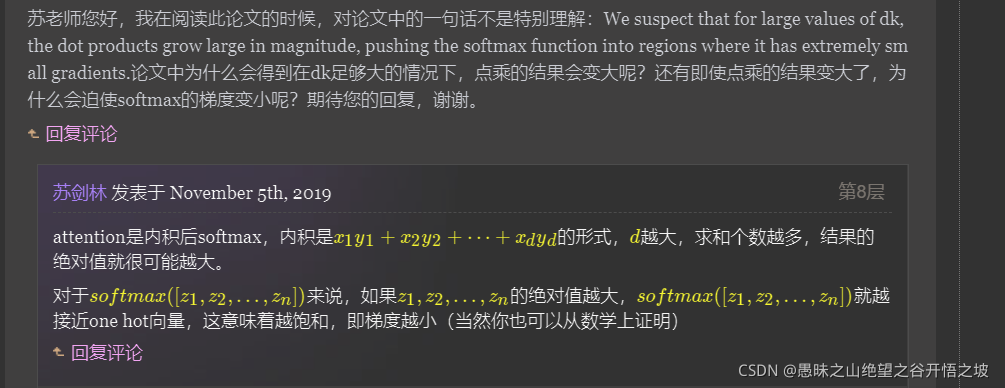
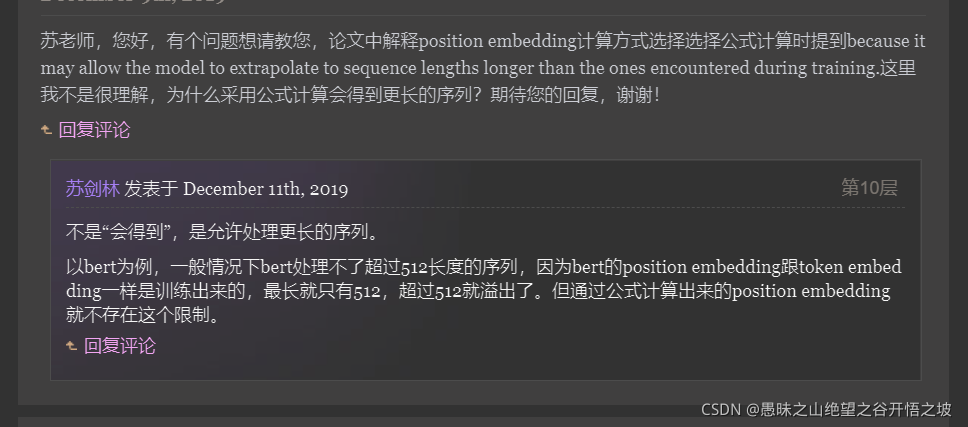
原来为长文本做了铺垫
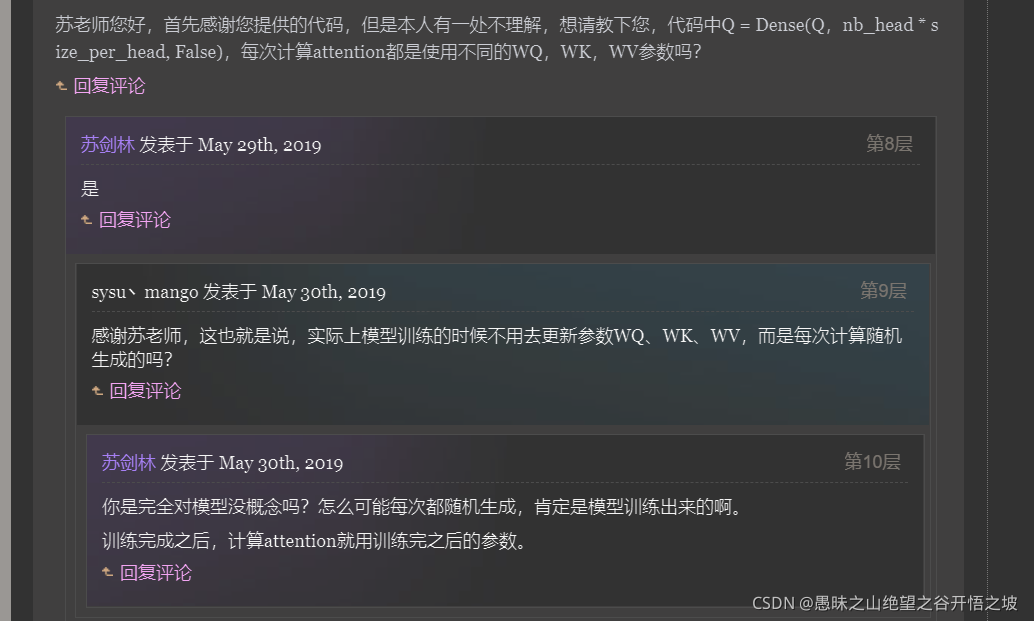
除了输入是ID,其他转换成向量,以及向量之间的参数运算,都是模型本身的参数而已
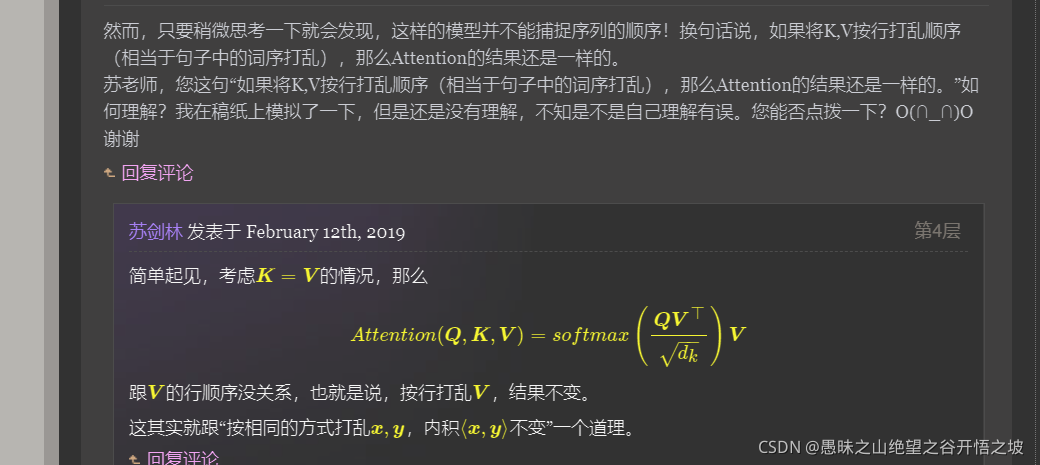
本质上是数学公式的运算
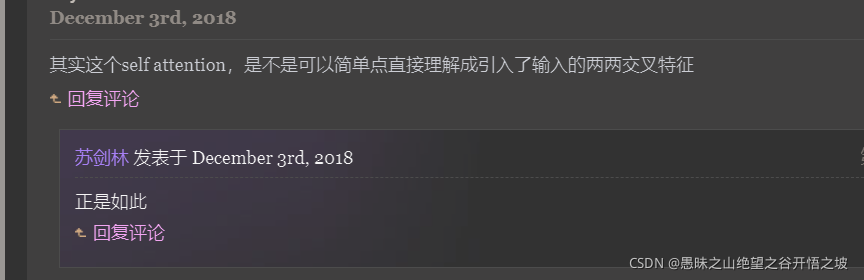
增加了一些特征
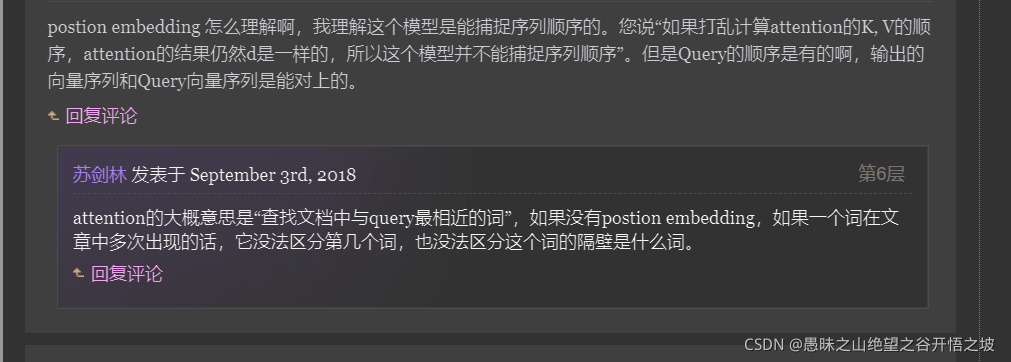
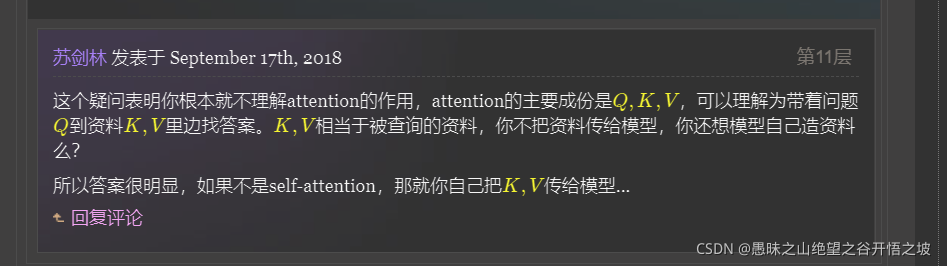
Q KV的理解,KV不就是类似字典的key和value吗
不同的epoch也有过拟合
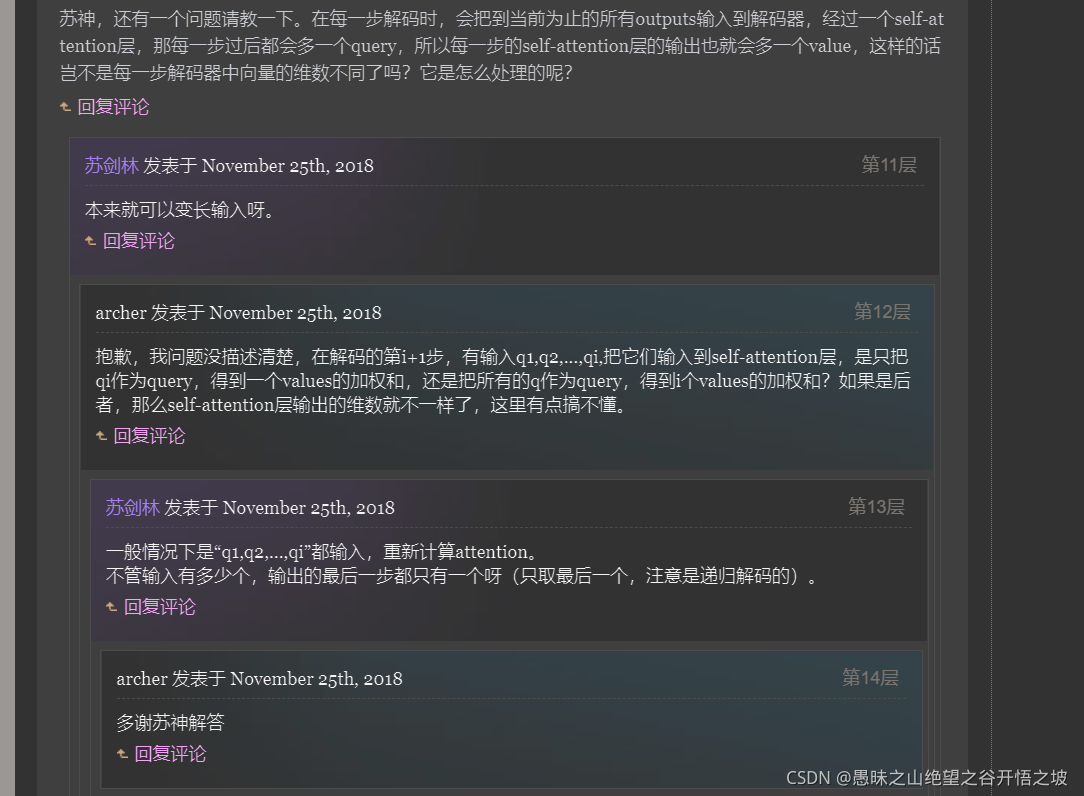
解码attention后只取最后一步的


有padding时候的mask,有解码的时候屏蔽未来信息的mask,本质上都是为了方便底层做矩阵运算,采取的数学上面的技巧而已。
因为解码的训练过程,也是一次性的矩阵运算,但是为了训练和测试尽可能一致,假如mask的机制。
如果您需要引用本文,请参考:
苏剑林. (Jan. 06, 2018). 《《Attention is All You Need》浅读(简介+代码) 》[Blog post]. Retrieved from https://kexue.fm/archives/4765