神经机器翻译(NMT)中的不确定性(Uncertainty)应用思考
前言
本文的目的是帮助笔者对实习一个多月来调研的NMT不确定性课题进行整理和复盘,笔者以个人较为粗浅的理解阐述不确定性在NMT领域的State-of-the-art(SOTA)研究工作,以及近年来学术界在NMT uncertainty这个方向的着眼点。大家取其精华去其糟粕,如有谬误欢迎各位批评指正~
什么是不确定性?
不确定性(Uncertainty),一直以来是ML/DL领域非常重视的问题,由于深度学习模型天生就具有“黑盒”的特点,可解释性较差,因此在很多高精尖领域都不敢应用ML/DL模型,对结果的输出不允许有差错。所以不确定性研究的是怎么样去更好的判断模型的输出结果是否可靠(reliable)。
近年来的神经机器翻译领域中存在一类问题,称为不确定性(Uncertainty),具体表现为译文的不可控现象,比如重复翻译、漏翻译、错翻译,如果一些涉政人名、地名、否定、数词翻译错误可能会带来很大的隐患或者安全隐患,如果翻译安全问题处理不当,可能上升为国家与国家之间的政治,经济,领土,军事等层面的安全问题。同时,研究NMT不确定性可帮助提升模型的可解释性和预测结果的置信度,最终提升翻译质量。
不确定性主要包括两种类型:
-
1.偶然/数据不确定性(Aleatoric/Data Uncertainty)
源自数据收集过程,是不可降低的随机性 -
2.认知/模型不确定性 (Epistemic/Model Uncertainty)
模型做出预测的正确程度
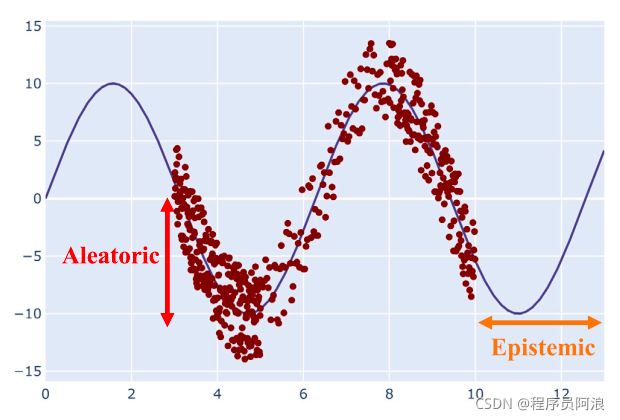
另外在模型做推断(inference)的时候,会遇到一类超出数据分布问题(Test Time:Out-of-distribution),指的是当模型的输入不同于训练数据时出现的不确定性。
Uncertainty 应用

从上图容易看出,Uncertainty在NMT中是一个比较具体的应用分支,近年来Uncertainty在NMT中的应用也越来越多元化,主要包括:
?Back translation
?Under translation
?Curriculum learning
?Quality estimation
?Self-training sampling
?Semantic Augmentation
? …
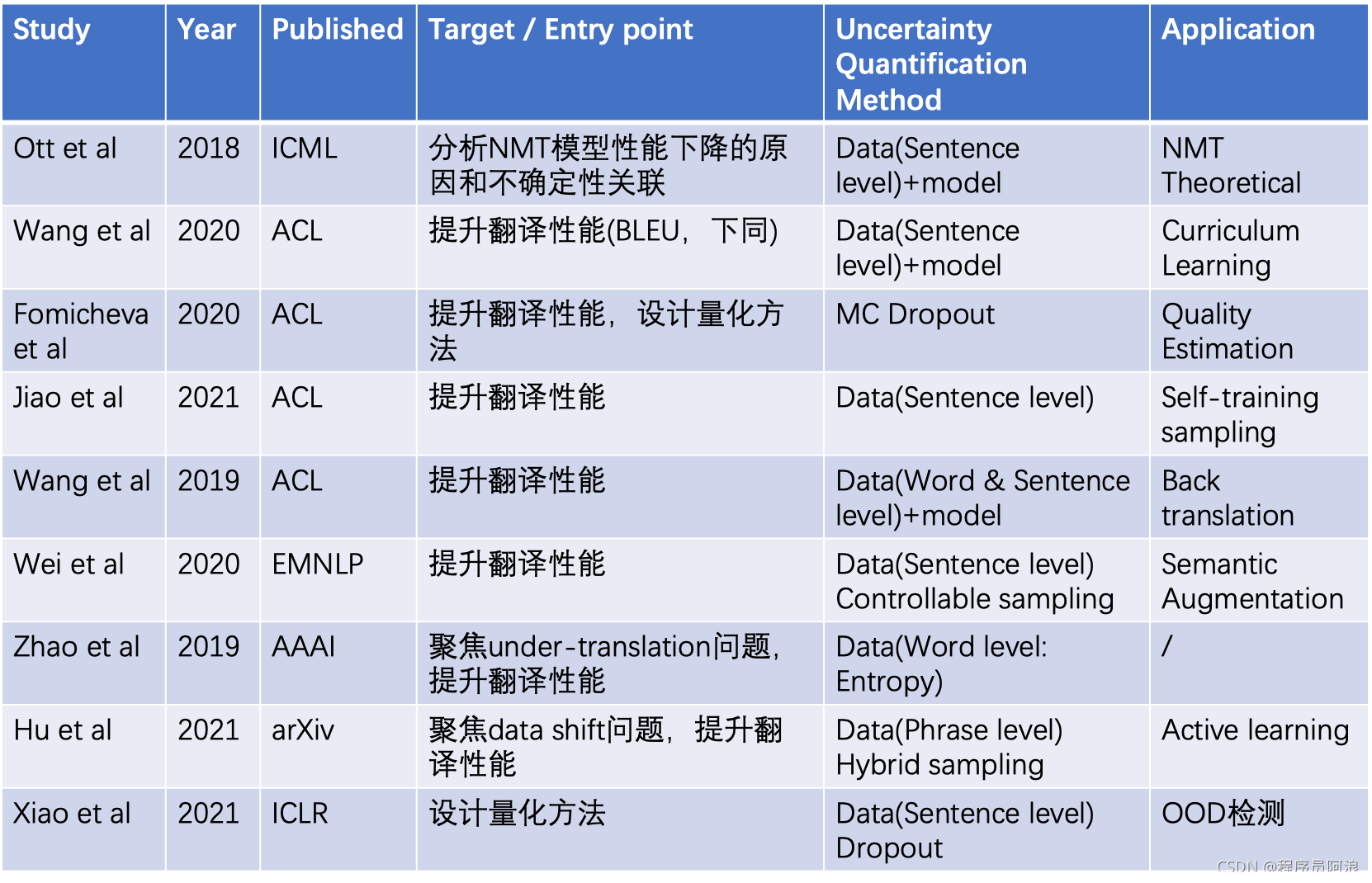
其中,表格里的参考文献从上往下分别是:
[1] Myle Ott, Michael Auli, David Grangier, and Marc’Aurelio Ranzato. 2018. Analyzing uncertainty in neural machine translation. In ICML
[2] Zhou, Yikai et al. “Uncertainty-Aware Curriculum Learning for Neural Machine Translation.” ACL(2020).
[3] Fomicheva, M. et al. “Unsupervised Quality Estimation for Neural Machine Translation.” Transactions of the Association for Computational Linguistics 8 (2020): 539-555.
[4] Jiao, Wenxiang et al. “Self-Training Sampling with Monolingual Data Uncertainty for Neural Machine Translation.” ACL/IJCNLP (2021).
[5] Wang, Shuo et al. “Improving Back-Translation with Uncertainty-based Confidence Estimation.” ArXiv abs/1909.00157 (2019): n. pag.
[6] Wei, Xiangpeng et al. “Uncertainty-Aware Semantic Augmentation for Neural Machine Translation.” EMNLP (2020).
[7] Zhao, Yang et al. “Addressing the Under-Translation Problem from the Entropy Perspective.” AAAI(2019).
[8] Hu, Junjie, and Graham Neubig. “Phrase-level Active Learning for Neural Machine Translation.” arXiv preprint arXiv:2106.11375 (2021).
[9] WAT ZEI JE? DETECTING OUT-OF-DISTRIBUTION TRANSLATIONS WITH VARIATIONAL TRANSFORMERS
NMT中量化Uncertainty的常见思路

在NMT中,研究者们通常也聚焦在两种类型的Uncertainty上下功夫,对于数据不确定性,研究者通常是利用数据过滤/增强等方法,抽取出确定性更高的数据(个人理解是数据提炼,使得生成的NMT模型具有更明显的in-domain特点)进行训练,并依据BLEU值的提升来评估模型的翻译效果。
对于模型不确定性,研究者通常聚焦在Dropout策略(最常用的方法是蒙特卡洛/Monte-Carlo(MC) Dropout,MC体现在需要对同一个输入进行多次前向传播过程,它的核心思想是在模型测试阶段(训练的时候MC dropout 表现形式和 dropout 没有什么区别)的前向传播过程不关闭dropout(这是和平常使用的唯一区别),这样就可以得到“不同网络结构”的输出,将这些输出进行平均和统计方差,即可得到模型的预测结果及 uncertainty。而且,这个过程是可以并行的,所以在时间上可以等于进行一次前向传播。),通过计算“多个模型结构”预测结果的均值/方差,以此来量化模型的不确定性。
总结
- 在NMT领域,应用Uncertainty的主要目的是:
- 过滤掉不确定性较高的训练数据来提升NMT模型翻译性能;
- 量化模型输出target sentence的置信度,该置信度可以通过设计word/phrase/sentence level的评估函数实现;而评估函数又通常结合模型输出结果空间(probability mass)的均值方差来表示,现有方法通常结合Bayesian inference(如MC Dropout)、Ensemble approaches 计算均值方差【核心是群体决策的熵思想】
参考链接:
