CV�����õ�attentionģ���pytorchʵ��
����2021��,CV�����Ѿ���չ���˷dz��dz����ʱ����,attention�ij��ָ����þ���ģ��Ĺ��ܱ�ø���ǿ��;ͨ��attentionģ��,����ͼ�ܹ����õع�ע������Ȥ����,��ȡ��ʵ������������ϵ�������
�����ϵ����,����������ֵ�attentionģ����һ����Ҫ���ܽ�,���ҽ���Щattentionģ����pytorchʵ�ֳ��������е�attentionģ�鶼��װ����һ����,��ʵ�ʵ��õ�ʱ�弴��,����Ҫattention�ĵط�����ֱ��ʹ�á�
�սӴ�transformer����,��ϸ���ŷ���ԭ��attention����ô���,�ܶ���������������Ҳͦʵ�õġ������Ĵ��������github��,��ӭ��λ��һ��star��
ÿһ��attentionģ���Ӧ��ԭ�ĵ�ַҲ����github����,����ϸ���е�ͯЬ���������濴��
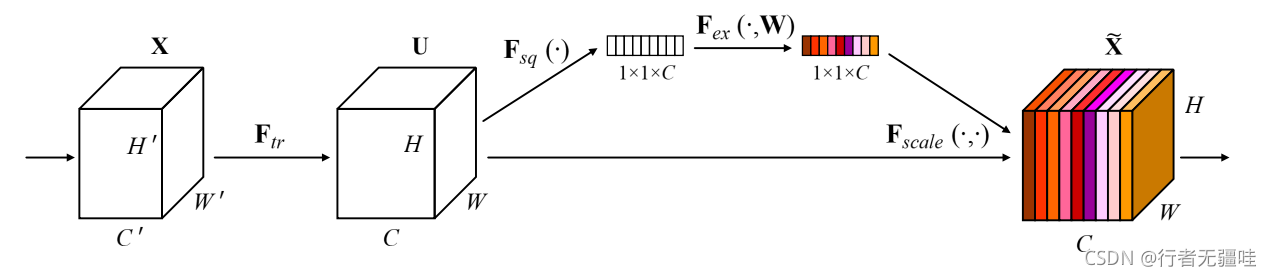
�����Ƚ���һ��attentionģ��,SENet,ȫ��ΪSqueeze-and-Excitation Network,���ĵ�ַ���������ȡ��SENetʹ�õ�attention��ͨ����ע��������,ʵ�ֵ�ԭ��ͼ����:���Ƚ����뾭�������Ȳ����õ�����ͼ,Ȼ������ͼ�ֳ���·,����һ·ͨ��ȫ��ƽ���ػ��õ�һ��Bx1x1xC������ͼ(B�C>batch_size, C�C>channel),Ȼ�����������ͼ����һ��ȫ��������,ͨ�������ԭ����1/r,�൱��һ����ѹͨ���Ĺ���(squeeze),����relu�����(excatation)֮��ͨ�����ԭ����C,�����µ�����ͼ��չΪ����������ͼ��ͬ��shape,��ӵõ�attentionģ��������
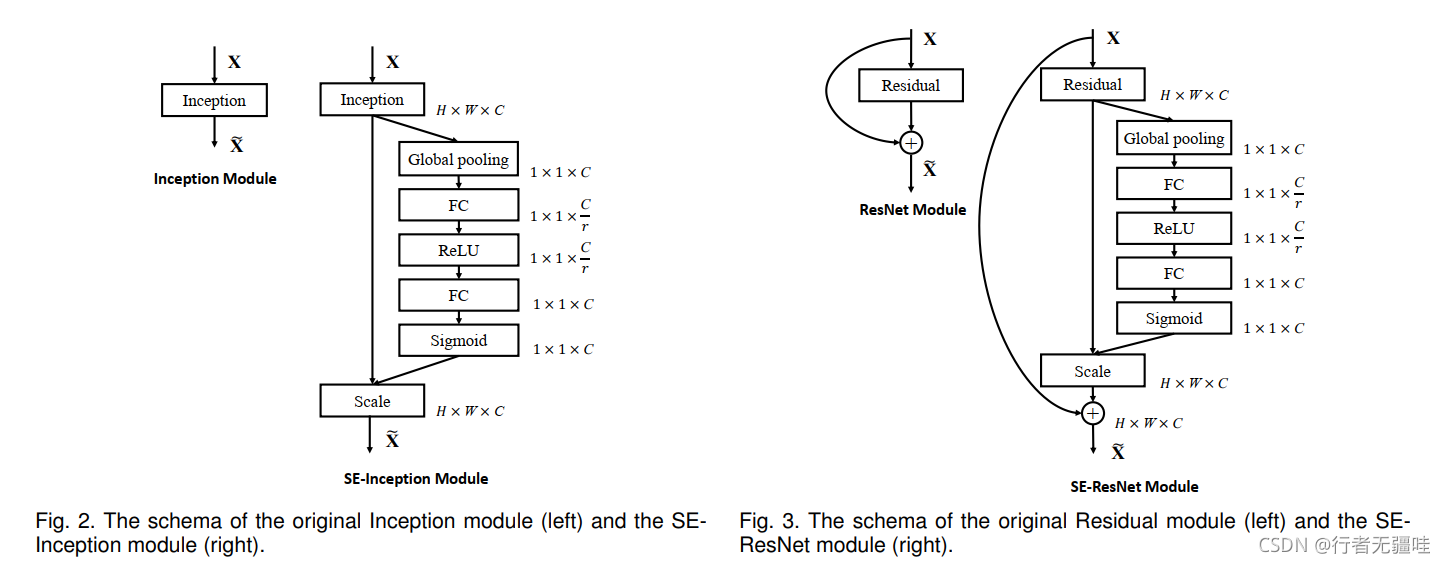
�����зֱ�չʾ��inception module���ͺ�residual module���͵�attention�ṹ��
pytorchʵ����������,����Ĵ���������ʾ:
import warnings
warnings.filterwarnings('ignore')
import torch
import torch.nn as nn
import torch.nn.functional as F
class SENet(nn.Module):
def __init__(self,channel,ratio = 16):
super(SENet,self).__init__()
self.global_pool = nn.AdaptiveAvgPool2d(1)
self.sigmoid = nn.Sigmoid()
self.fc_1 = nn.Linear(channel,channel//ratio)
self.relu = nn.ReLU()
self.fc_2 = nn.Linear(channel//ratio,channel)
def forward(self,x):
temp = x
temp = self.global_pool(temp).view(x.size(0),x.size(1))
temp = self.fc_1(temp)
temp = self.relu(temp)
temp = self.fc_2(temp)
temp = self.sigmoid(temp).view(x.size(0),x.size(1),1,1)
temp = temp.expand_as(x)
return x+temp