上一篇:每天两小时学习编译原理――一个学期的第二天,希望能坚持长久?
在了解乐基本概念和学习意义之后,我们接下来对编译程序做一个概要介绍。其实包含编译程序的基本工作过程,结构还有常用的生成方法。

编译程序过程
首先咱们看一下编译程序的基本过程。
那其实,编译程序的过程与我们进行自然语言的翻译过程很是相似,那最适合的一个栗子就是翻译的过程,我们讲一个英文句子翻译成中文。

我来给大家读一下啊,
则 抗排雷儿 砍 穿丝雷塔 饿 脯肉格瑞姆 腐乳昂木 缫丝 兰桂芝 吐 他给儿他 兰桂芝。
那真正的翻译成中文就是右边的那句话。
那我们其实就是经过下面的过程阶段才一步一步的将英语翻译成了中文。
那其实我们编译程序的工作过程也经过了5个阶段。
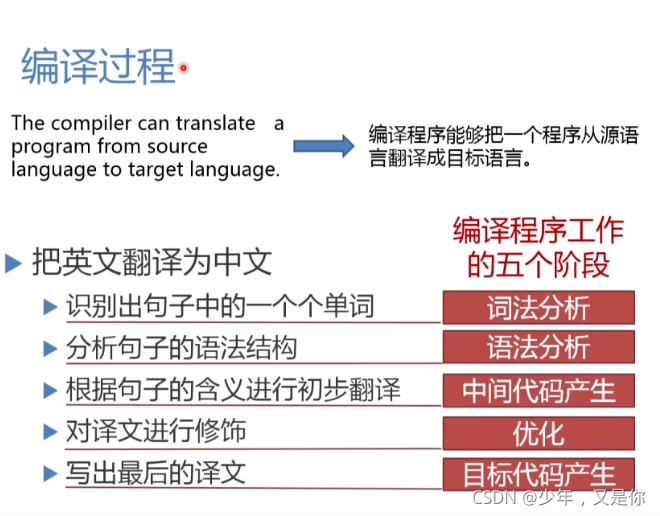
词法分析
接下来我们一个一个进行分析,首先来了解词法分析阶段。
 我们在进行词法分析的时候呢,依循的规则是词法规则,就是上面的构词规则。比如,我们在学习某个程序设计语言时,首先改语言的单词构成规则。例如,一般的程序设计语言会要求用标识符定义变量名,而标识符是明确规定的以字母开头的字符串。那在一些程序设计语言中还允许用户自定义整形常量,要求整形常量是有数字字符构成的字符串就是整形常量。那这些就是词法规则。编译程序就是根据这些规则对源程序的字符串进行扫描,识别出哪些字符串构成了标识符,常数。那前面的这些词法规则其实还都是用自然语言去描述的,那要是想让计算机理解这些规则,那就要有一个形式化的方法来描述,这是我们就可以利用有限自动机。那有限自动机这个知识点我们后面会接触到。
我们在进行词法分析的时候呢,依循的规则是词法规则,就是上面的构词规则。比如,我们在学习某个程序设计语言时,首先改语言的单词构成规则。例如,一般的程序设计语言会要求用标识符定义变量名,而标识符是明确规定的以字母开头的字符串。那在一些程序设计语言中还允许用户自定义整形常量,要求整形常量是有数字字符构成的字符串就是整形常量。那这些就是词法规则。编译程序就是根据这些规则对源程序的字符串进行扫描,识别出哪些字符串构成了标识符,常数。那前面的这些词法规则其实还都是用自然语言去描述的,那要是想让计算机理解这些规则,那就要有一个形式化的方法来描述,这是我们就可以利用有限自动机。那有限自动机这个知识点我们后面会接触到。
 这就可以说是词法分析,那这个基本字是一些语言预定义的一些符号或者说是字符串等。那在有些语言中基本字也被理解为关键字。
这就可以说是词法分析,那这个基本字是一些语言预定义的一些符号或者说是字符串等。那在有些语言中基本字也被理解为关键字。
语法分析

语法规则就不用我多少了吧,我们英语之前接触老多了,那这个意思就是可以理解为语句的结构或者说语句的合法形式是什么样的。那语法规则的本质就是描述语法单位构成的规则就是语法规则.
那编译程序再根据语法规则去分析之前的词法分析产生的的单词序列,看看那些单词可以构成表达式,进而构成语句,函数甚至整个程序。同样我们刚刚给出的也是自然语言描述的规则,那要想让我们的计算机能懂,我们就要使用描述的工具将其形式化,那我们用的工具就是:上下文无关文法

那我们一般会用上下文无关文法,去描述语法规则,明确语法单位的构成关系。同样在后面我们也会接触到上下文无关文法的理论,这些理论为形式化的描述语法规则进行语法分析,提供了很好的基础。
还有一个例子:
 我们从右往左进行分析,首先是一个常量和一个变量Y进行乘法算数运算,之后与变量X相加,最后赋值给这个Z,那其实这就属于我们一步一步通过分析此逻辑语句的语法,得到最后的结果,先乘后加再赋值这个就是“语法”。
我们从右往左进行分析,首先是一个常量和一个变量Y进行乘法算数运算,之后与变量X相加,最后赋值给这个Z,那其实这就属于我们一步一步通过分析此逻辑语句的语法,得到最后的结果,先乘后加再赋值这个就是“语法”。
语义分析与中间代码生成
识别完语法单位之后,就需要对各类不同的语法单位按照语言的语义进行初步的翻译。这就是中间代码产生阶段。那其实在这个阶段中的,我们首先是进行静态语义检查(语义分析),产生中间代码。那这一阶段我们依循的原则是语义规则。

那我们回顾一下我们学习程序设计语言语句的情形。我们除了要知道语句的结构规范(语法规则),我们还要准确的理解语句的功能,那这个就是语句的语义。
例如:上面的红字。
那对于这个赋值语句,我们通常是这样对其进行描述的。
首先计算赋值号右面的值,然后将这个值送到左边的变量的内存存储单元中,这就是赋值语句的语义。
同样的,我们上述都是用自然语言进行描述,那为了让那个计算机能够进行语义分析,我们采用了一个工具:属性文法,这个也是我们后面会学习到的。那这个属性文法算是从翻译的角度去阐明语法单位的意义.
这样一来,我们的语义分析又和翻译产生了联系。但是我们这一阶段的语义分析并不会产生目标代码,那还是因为高级语言和计算机的机器语言的差别太大,所以很难一步就完成转换,所以我们就引入了中间代码。
一般而言,中间代码是一种独立于具体硬件的记号系统,那常用的中间代码,比如说三元式,四元式,逆波兰记号,还有树形表示等等。
那我们引入了中间代码好处多多啊,不仅可以将高级语言更便捷的转换成计算机的机器语言,而且还未我们下一阶段的优化创造了有利条件。
那我们还拿之前的赋值语句来进行举例:
 那就这样我们就将一个高级语言的赋值语句通过词法分析,语法分析,再通过中间代码产生,翻译成了这样的一个四元式。
那就这样我们就将一个高级语言的赋值语句通过词法分析,语法分析,再通过中间代码产生,翻译成了这样的一个四元式。
优化
那我们在生成了中间代码之后并不会直接生成目标代码,那我们有可能会再经过一个对中间代码的优化的阶段。

那这一部分其实不用多说,其实在不管我们编写的任何代码都是要去思考的个问题,程序员在编写代码中就要去思考,我们程序的可读性与效率的权衡,那一个高效的代码肯定都是讨人喜欢的,但有时候我们对于可读性的优化也是必不可少的,而效率我们也可以在编译器中利用其本身的优化进行效率的提高。所以最终我们可以实现可读性与效率的双赢,那优化的例子有很多,可参考本书的第三到四页,有个案例供大家学习。
目标代码的生成

那我们目标代码的三种形式的第一种汇编指令代码其实还不是机器语言,所以还需要汇编器将代码汇编成机器指令才能够执行。
而第二种绝对指令其实就是机器语言,那就可以直接运行。
那我们要知道,我们现在多数用编译程序所产生的目标代码都是一种可重定位的指令代码。什么是可重定位不用多说吧,在java中我们有可重定向和转发两种方式对地址进行定位跳转。那这里,其实也是一样的意思,这里的指令代码中的地址是一个相对地址,这种指令代码可以在内存中的任何位置开始装载。那装载的过程其实是将指令代码中的相对地址与初始地址进行追加(相加,可参考java中append的含义),就能够得到最终的绝对地址,那就能实现正确的访问。那这个过程其实就是链接.
这种可重定位的指令代码能够很好的支持模块化的软件开发,使得每个程序模块都能够独立开发编译,然后通过链接程序,将各个模块变成可执行的程序。
看一个老师的例子:
 那我们可以看到,这个模块A可以在程序P1中间,也可以在程序P2的底部,这个位置也是随机的,那也就是说模块A的绝对地址(最终的地址)是无法确定的。但是我们知道这个a变量(地址)相对于模块A起点的偏移量,我们是知道的,那我们在独立编译这个模块A的时候,就可以吧这个偏移量作为相对地址。 那我们有地址就有目标文件对应,比如说生成了
那我们可以看到,这个模块A可以在程序P1中间,也可以在程序P2的底部,这个位置也是随机的,那也就是说模块A的绝对地址(最终的地址)是无法确定的。但是我们知道这个a变量(地址)相对于模块A起点的偏移量,我们是知道的,那我们在独立编译这个模块A的时候,就可以吧这个偏移量作为相对地址。 那我们有地址就有目标文件对应,比如说生成了.obj文件,那这个文件实际上大多都是可重定位的指令代码,那地址其实就是相对于本模块起始位置的相对地址。
而当需要生成可执行的程序的时候,我们就要将这些可重定位的模块进行链接与装配,将相对地址变成绝对地址。那如何替换这里有一个简单的公式:绝对地址 = 起始地址 + 相对地址。
那这样,我们就将.obj文件执行代码变成.exe文件。
编译程序的结构

编译程序总框
那这一部分就不再多说,书上的总结很全面,大家按照上面的学习就是了,看视频再听一遍也是不错的巩固:
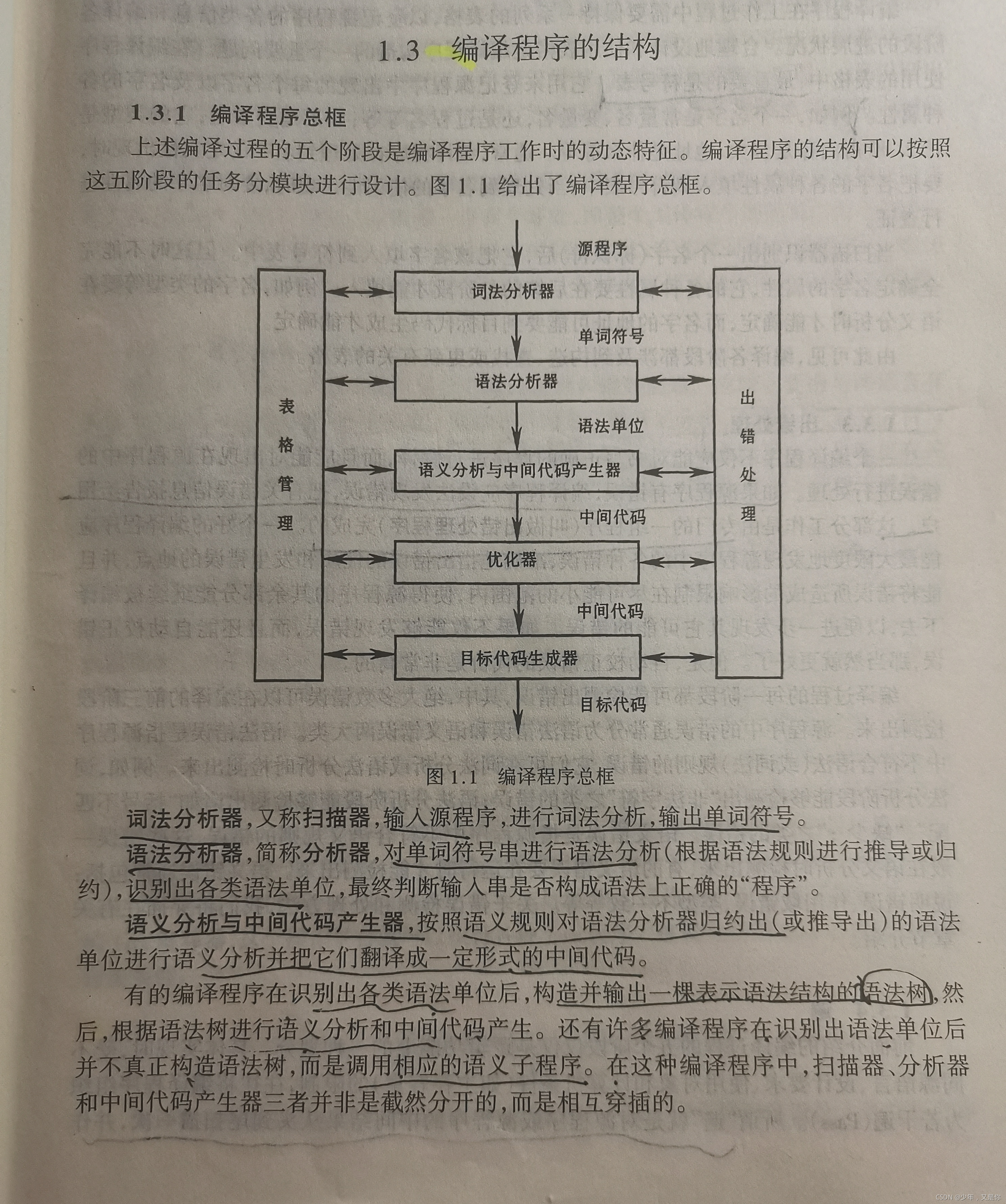
那我们其中多了解一下出错程序,身为一个程序员,我们编写的代码难免会出现这样或者是那样的错误:所以只就需要我们的出错处理程序来帮助我们改错。
 那源程序的错误通常就分为语法错误和语义错误两大类。
那源程序的错误通常就分为语法错误和语义错误两大类。
遍
继续往下进行,我们来总结一下遍。遍讲可以理解为遍历,就是扫描。
 那在我们实际的开发过程中,从效率和软件设计的角度考虑,我们常常把若干个联系非常紧密的阶段合成一遍处理。那书上的例子就很好,大家可以自行参考。
那在我们实际的开发过程中,从效率和软件设计的角度考虑,我们常常把若干个联系非常紧密的阶段合成一遍处理。那书上的例子就很好,大家可以自行参考。
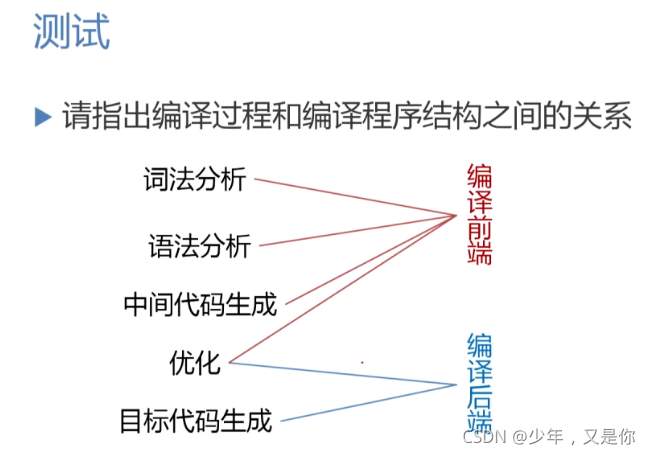
编译前端与后端
我们首先来看一下编译程序总框图:
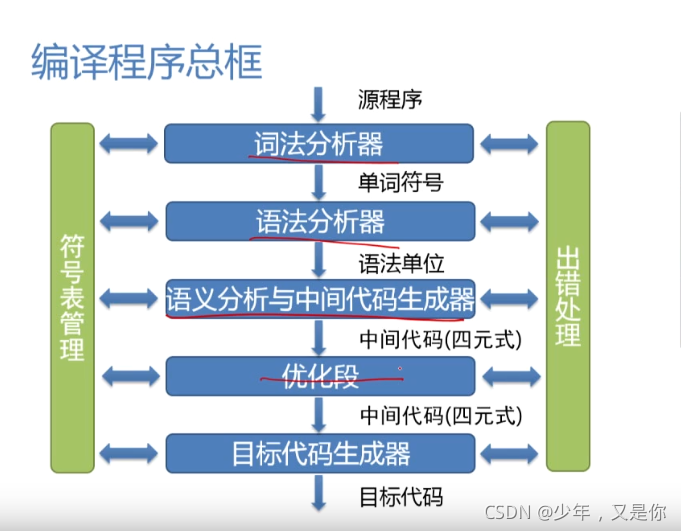
那我们其实从中可以发现,我们的词法分析,语法分析,语义分析,其实并没有和目标代码有直接关系,甚至优化的一些实现也是与目标代码是无关的,那有些是有关的,由此以来我们就可以将编译程序划分成为编译前端和编译后端。


这就可以说一个关于java的例子:
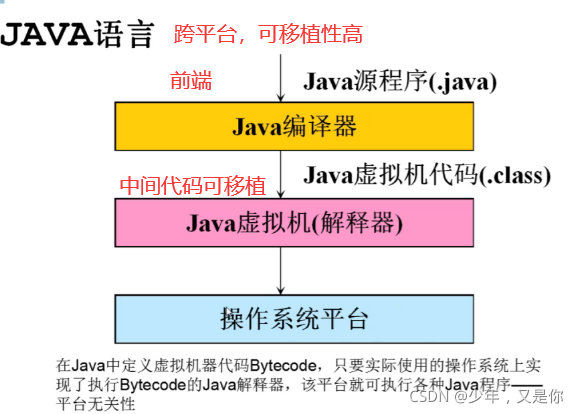
那这里就体现了我们之前讲到的:分解与权衡的思维体现。

最后来一个连线:但是记住这不是全部情况。
今天特别晚了,我们明天再见。
当然若本篇内容对您有所帮助,请三连点赞,关注,收藏支持下。
别问,问就是
创作不易,白嫖很爽,但是求各位手下留情。
如果本篇博客有任何错误或者疏漏,请批评斧正,感激不尽 !