��Ȼ���Դ������Ƕ��
1. �ʻ����
��Ƕ��(word embeddings)�����Ա�ʾ��һ�ַ�ʽ,�������㷨�Զ�������һЩ���ƵĴ�,���� ���˶�Ů��,����������
�����ʹ�ø�one-hot ��������ʾ��,ȱ��:����ÿ���ʹ�������,�㷨����شʵķ���������ǿ(ÿ������֮��������ڻ�����0)

t-SNE(t-distributed stochastic neighbor embedding)��������ά��һ�ֻ���ѧϰ�㷨,�� Laurens van der Maaten �� Geoffrey Hinton��08�������t-SNE ��Ϊһ�������Խ�ά�㷨,�dz������ڸ�ά���ݽ�ά��2ά����3ά,���ڽ��п��ӻ���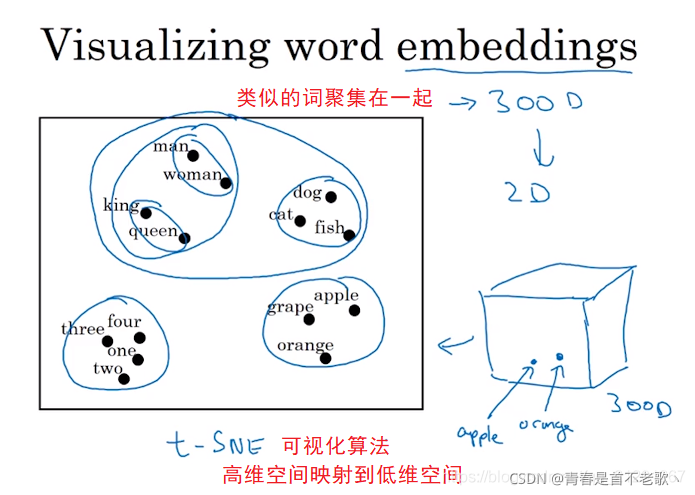
2. ʹ�ô�Ƕ��
��Ƕ��(Word Embedding)��һ�ֽ��ı��еĴ�ת�������������ķ���,Ϊ��ʹ�ñ�����ѧϰ�㷨�������ǽ��з���,����Ҫ����Щ��ת�������ֵ�������������ʽ��Ϊ���롣
��Ƕ��������ǰ�һ��ά��Ϊ���д���������ά�ռ�Ƕ�뵽һ��ά���͵ö�����������ռ���,ÿ�����ʻ���鱻ӳ��Ϊʵ�����ϵ�����,��Ƕ��Ľ������������������
������ģ����������ѧ�ġ����������ԡ�ԭ��,���Ժ�����֮��������ԡ�

����Ƕ����Ǩ��ѧϰ�IJ���:
-
�Ӵ������ı�����ѧϰ��Ƕ��,������������Ԥѵ���õĴ�Ƕ��ģ��
-
�ô�Ƕ��ģ�Ͱ���Ǩ��������µ�ֻ��������עѵ������������
����,�����300ά�Ĵ�Ƕ������ʾ��ĵ���,����ԭ����10000ά��one-hot���� -
�µ�����ѵ��ģ��ʱ,�����ѡ��Ҫ��Ҫ������,���µ����ݵ�����Ƕ�롣ʵ����,ֻ�еڶ��������ܴ�����ݼ���Ż�������,������ݼ����Ǻܴ�,ͨ������������Ƕ���Ϸ�����(������ݺ�С,����Ƕ��,Ч��Ҳ������)
��Ƕ�� ������ģ�͡��������������õ���һЩ,��Ϊ��Щ������������������(������ѵ��,����ʹ��Ǩ��)
����ʶ���е�����Encoding�㷨,δ�������漰��������������Ƭ
����Ȼ���Դ��� ��һ���̶��Ĵʻ�� embedding,����һЩû�г��ֹ��ĵ������Ǿͼ�Ϊ δ֪����UNK
�ܽ�:
�ô�Ƕ����ʵ��Ǩ��ѧϰ,����ԭ����one-hot��ʾ,���Dz���֮ǰ��Ƕ��������,����㷨�������ĸ���
3. ��Ƕ�������

ͨ��
argmax
?
Similarity
?
(
e
w
,
e
king?
?
e
man
?
+
e
woman?
)
\operatorname{argmax} \operatorname{Similarity}\left(e_{w}, e_{\text {king }}-e_{\operatorname{man}}+e_{\text {woman }}\right)
argmaxSimilarity(ew?,eking???eman?+ewoman??) Ѱ��һ������ w ,���ַ��������������ȷ�ʴ��ֻ��30%~75%
�����õı�ʾ��ʽ�������������ƶ�(�н�): sim ? ( u , v ) = cos ? ( �� ) = u T v �O u �� 2 �� v �� 2 \operatorname{sim}(u, v)=\cos (\theta)=\frac{u^{T} v}{\mid u\left\|_{2}\right\| v \|_{2}} sim(u,v)=cos(��)=�Ou��2?��v��2?uTv? , ������� u u u������ v v v�ͷdz�����, s i m ( u , v ) sim(u,v) sim(u,v) ���ӽ�1;������Dz�����,�� s i m ( u , v ) sim(u,v) sim(u,v)��ȡ�ý�С��ֵ��
4. Ƕ�����

���ǵ�Ŀ����ѧϰһ��Ƕ����� E��
���ǽ�����س�ʼ������,Ȼ��ʹ���ݶ��½�����ѧϰ���300��10000�ľ����еĸ�������,Ȼ��ȡ������Ҫ����
5. ѧϰ��Ƕ��
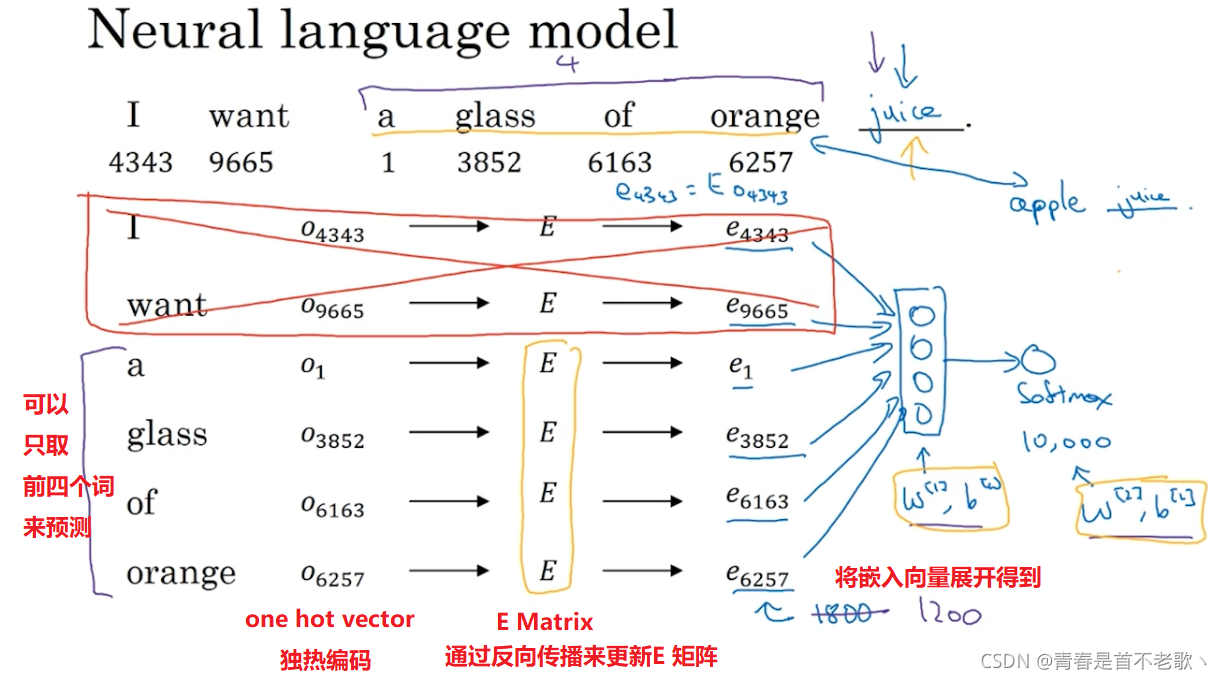
����뽨��һ������ģ��,��Ŀ��ʵ�ǰ����������Ϊ�������dz�������
������Ŀ����ѧϰ��Ƕ��,��ô��Ϳ�������Щ�������͵�������(��ͼ��ʾ),Ҳ�ܵõ��ܺõĴ�Ƕ��
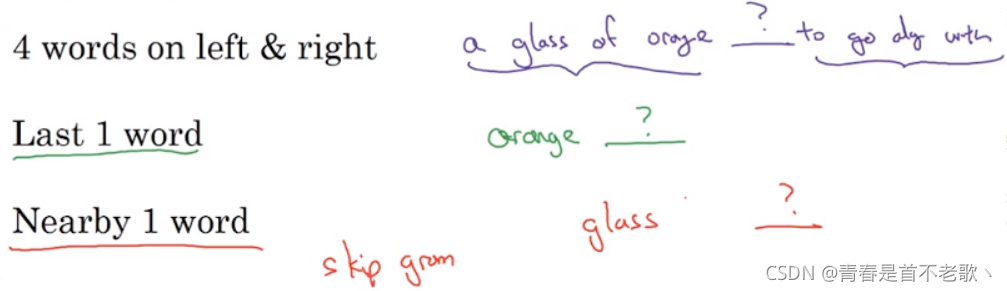
6. Word2Vec

s
o
f
t
m
a
x
:
p
(
t
�O
c
)
=
e
��
t
T
e
c
��
j
=
1
10
,
000
e
��
j
T
e
c
��
ʧ
��
��
:
L
(
y
^
,
y
)
=
?
��
i
=
1
10
,
000
y
i
log
?
y
^
i
softmax:p(t \mid c)=\frac{e^{\theta_{t}^{T} e_{c}}}{\sum_{j=1}^{10,000} e^{\theta_{j}^{T} e_{c}}}\\ ��ʧ����:L(\hat{y}, y)=-\sum_{i=1}^{10,000} y_{i} \log \hat{y}_{i}
softmax:p(t�Oc)=��j=110,000?e��jT?ec?e��tT?ec??��ʧ����:L(y^?,y)=?i=1��10,000?yi?logy^?i?
Ϊ�˽�� softmax �Է�ĸ��ͺ���������:
- ���� �ּ�(hierarchical)��softmax��������������(Negative Sampling)

����������Ľ���������Ȳ���,�� the��of��a��and��to ֮����ֵ��൱Ƶ��,��ô�����ĵ�Ŀ��ʵ�ӳ����൱Ƶ���صõ���Щ����Ĵ�,ʵ����,�� p ( c ) p(c) p(c) �ķֲ������ǵ�������ѵ�������Ͽ��Ͼ���������IJ����õ���,���������˲�ͬ�ķּ���ƽ��������ĴʺͲ���ô�����Ĵ���
���Ͼ��� Word2Vec �е� Skip-Gram ģ��,���ᵽ��һ�ֽ���CBOWģ��,�������ʴ�ģ��(Continuous Bag-Of-Words Model),������м�����ߵ�������,Ȼ������Χ�Ĵ�ȥԤ���м�Ĵ�,���ģ��Ҳ����Ч��
�ܽ�:
- CBOW�Ǵ�ԭʼ����Ʋ�Ŀ���ִ�;��Skip-Gram�����෴,�Ǵ�Ŀ���ִ��Ʋ��ԭʼ��䡣
- CBOW��С�����ݿ�ȽϺ���,��Skip-Gram�ڴ��������б��ָ���
7. ������
����һ���µļලѧϰ����,���Ǹ���һ�Ե���,����orange��juice,ҪȥԤ�����Ƿ���һ�������Ĵ�-Ŀ���(context-target)

ѡȡ��������������ֲ�:
P ( w i ) = f ( w i ) 3 4 �� j = 1 10 , 000 f ( w j ) 3 4 P\left(w_{i}\right)=\frac{f\left(w_{i}\right)^{\frac{3}{4}}}{\sum_{j=1}^{10,000} f\left(w_{j}\right)^{\frac{3}{4}}} P(wi?)=��j=110,000?f(wj?)43?f(wi?)43??
��Ϊ��softmax�������м���ɱ��ܸߡ���������ѧ�������ͨ������ת��Ϊһϵ�ж���������ʹ����Էdz���Ч��ѧϰ��������
��Ȼ����Ҳ�б���Ԥѵ�����Ĵ�����,����Ҫ��NLP������ȡ�ÿ��ٽ�չ,ȥ�������˵Ĵ������Ǻܺõķ���,���ڴ˻����Ͻ��иĽ�
8. GloVe ������
GloVe:�ôʱ�ʾ��ȫ�ֱ���(global vectors for word representation)
����GloVe�㷨,���ǿ��Զ��������ĺ�Ŀ���Ϊ��������λ������ĵ���,���������Ҹ�10�ʵľ���,��ô X i j X_{ij} Xij? ����һ���ܹ���ȡ���� i i i �͵��� j j j ����λ�����ʱ���DZ˴˽ӽ���Ƶ�ʵļ�����
GloVeģ�����ľ��ǽ����Ż�,���ǽ�����֮��IJ�������С������:
minimize
?
��
i
=
1
10
,
000
��
j
=
1
10
,
000
f
(
X
i
j
)
(
��
i
T
e
j
+
b
i
+
b
j
��
?
log
?
X
i
j
)
2
\operatorname{minimize} \sum_{i=1}^{10,000} \sum_{j=1}^{10,000} f\left(X_{i j}\right)\left(\theta_{i}^{T} e_{j}+b_{i}+b_{j}^{\prime}-\log X_{i j}\right)^{2}
minimizei=1��10,000?j=1��10,000?f(Xij?)(��iT?ej?+bi?+bj��??logXij?)2
9. ����
��з���һ��������ս���ǿ��ܱ�ǵ�ѵ����û����ô����
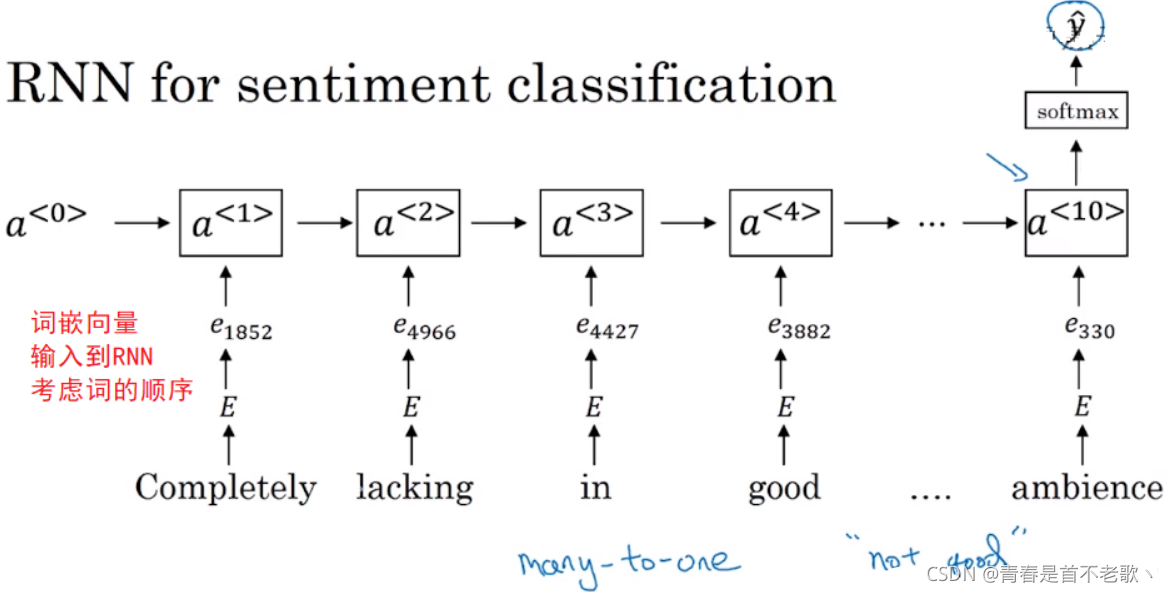
������з���������˵,ѵ������С��10,000��100,000�����ʶ��ܳ���,������ʱ��С��10,000������,��������Ƕ���ܹ��������õ�Ч��(������),������ֻ�к�С��ѵ����ʱ��

��ô�����?��Ƕ���������뵽RNN,ͨ��RNN��֪�ʵ�˳��
10. ��Ƕ���ƫ
����ѵ��ģ����ʹ�õ��ı�,��Ƕ���ܹ���ӳ���Ա����塢���䡢��ȡ������������ƫ��,��ѧϰ�㷨�������ܼ��ٻ������뻯������Щ��Ԥ�����͵�ƫ����ʮ����Ҫ��
- ��λƫ��
- �к�,������������ij�����ϵľ���(PCA)
- ����,���������������м����ߵȾ��һ�Ե���