这是我研究2D buttom-up HPE算法遇到的一些问题。
问题描述:
3个网络模型都是2D姿态估计网络,代码相似度很高。然而默认都是使用了imagenet的与训练模型。咨询了CVPR的作者,推荐我使用coco的预训练模型来训练CrowdPose数据集。
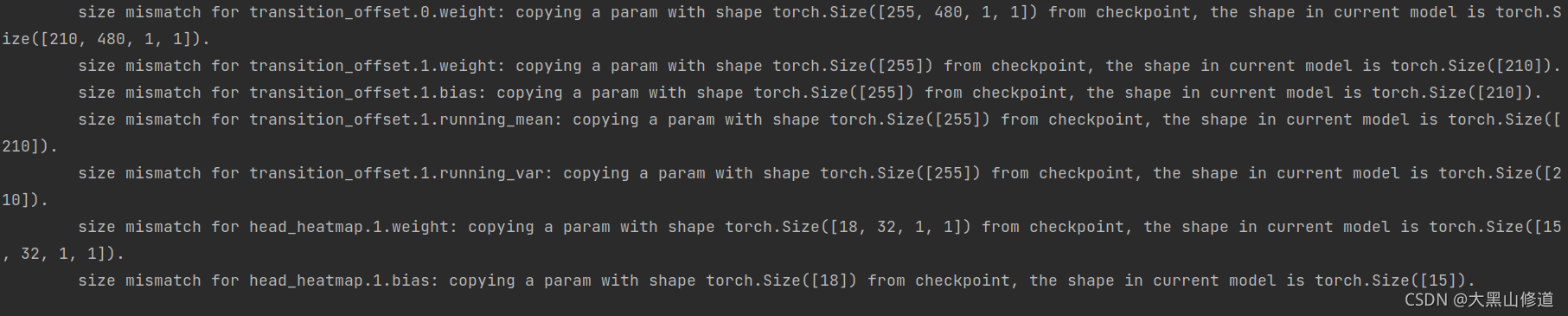
然而训练CrowdPose数据集的时候使用了coco的预训练模型,DEKR模型报错:通道数错误,这个情理之中的。因为coco采用17个关键点,而CrowdPose采用14个关键点,模型在hrnet之后就会卷积出不同的通道。然后疑惑的是,SWAHR,HigherHRNet的模型居然可以。
留两个问题,后面总结部分会有解答,不想看实验验证部分的可以直接跳过去:
为何DEKR导入自己的COCO模型作为预训练模型会报错,而SWAHR和HigherHRNet不会?
如何认识预训练模型,是否预训练模型的网络结构要和自身的网络结构相同?
研究过程:
1. 预训练模型都设为imagenet的预训练模型
然后我将SWAHR模型和DEKR的与训练模型都统一为imagenet的预训练模型hrnet_w48-8ef0771d.pth。
然后在lib/models/网络.py文件中的init_weight()函数中进行打印观察。(SWAHR与DEKR的init_weight函数几乎一样)
都是同样的代码,同样的预先训练模型:
if os.path.isfile(pretrained):
pretrained_state_dict = torch.load(pretrained,
map_location=lambda storage, loc: storage)
logger.info('=> loading pretrained model {}'.format(pretrained))
need_init_state_dict = {}
for name, m in pretrained_state_dict.items():
if name.split('.')[0] in self.pretrained_layers \
or self.pretrained_layers[0] is '*':
if name in parameters_names or name in buffers_names:
if verbose:
logger.info(
'=> init {} from {}'.format(name, pretrained)
)
need_init_state_dict[name] = m
self.load_state_dict(need_init_state_dict, strict=False)
打印结果一样,最后结尾部分一致:
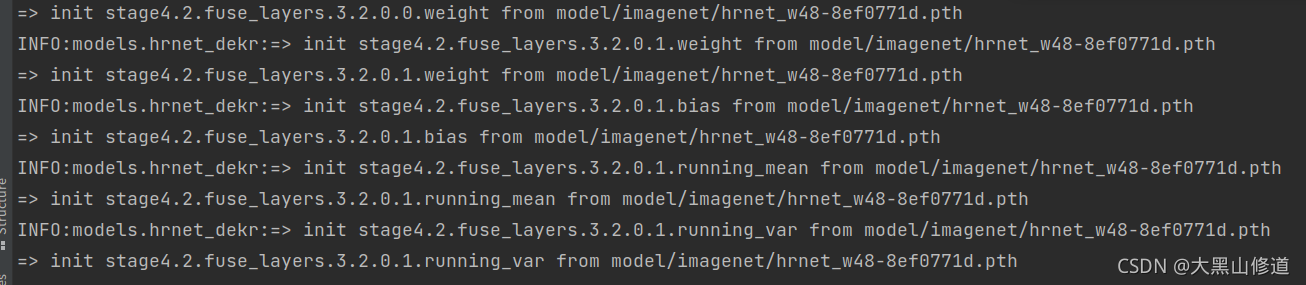
然后head.3.0.0.bn2.weight
我们打印代码抽离出来:
第一步
首先是打印:
for name, m in pretrained_state_dict.items():
print(
'=> {}'.format(name)
)
最后打印结果完全一致
第二步
增加一个判断
for name, m in pretrained_state_dict.items():
if name.split('.')[0] in self.pretrained_layers \
or self.pretrained_layers[0] is '*':
print(
'=> {}'.format(name)
)
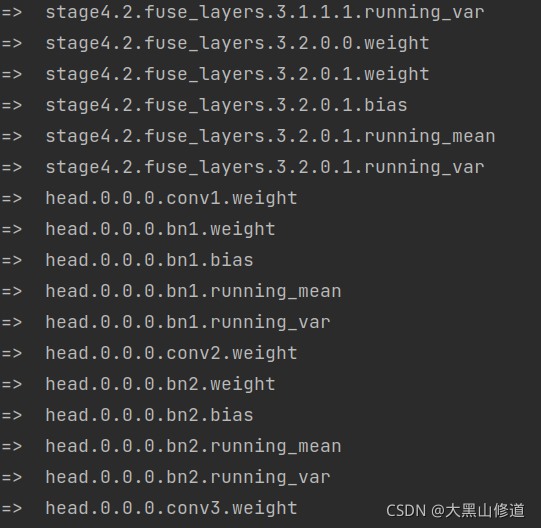
打印结果出现区别!!!
DEKR:
SWAHR:
head.3.0.0.bn2.weight
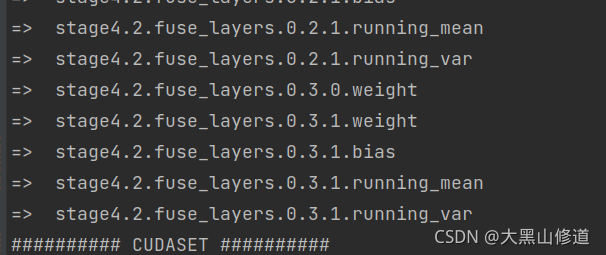
可以看出DEKR是打印全的,SWAHR是只有部分的,这就是判断的效果
head.3.0.0.bn2.weight
if name.split('.')[0] in self.pretrained_layers \
or self.pretrained_layers[0] is '*':
大概意思就是预训练模型的参数名需要在self.pretrained_layers内,
或者self.pretrained_layers[0] == *
然后继续查看self.pretrained_layers:
self.pretrained_layers = self.spec.PRETRAINED_LAYERS
也就是说,这个变量读取的是cfg文件中的PRETRAINED_LAYERS的数据
然后分别在两个cfg中找到了PRETRAINED_LAYERS:
DEKR:

SWAHR:

也就是说DEKR是全部读取预训练模型的权重,而SWAHR是读取制定变量名下的权重。
第三步
我们把源码上的判断语句全部加上:
for name, m in pretrained_state_dict.items():
if name.split('.')[0] in self.pretrained_layers \
or self.pretrained_layers[0] is '*':
if name in parameters_names or name in buffers_names:
print(
'=> {}'.format(name)
)
最后DEKR与SWAHR的输出又一致了:
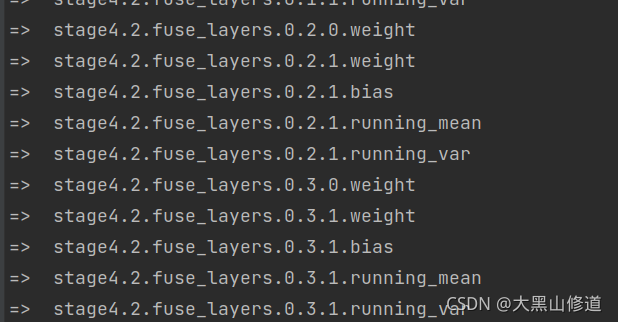
最后我们分析一下这条判断语句:
if name in parameters_names or name in buffers_names:
很难跳转,但我们可以推理得出,这行代码的意思就是筛选出预训练模型中名称与网络模型中名称一致的变量。
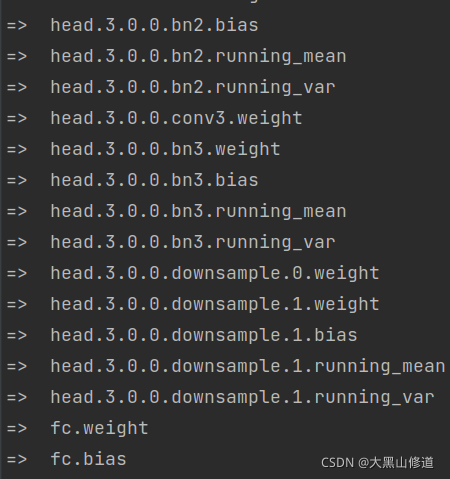
这样,DEKR网络模型中类似与head.3.0.0.bn2.weight的权重就被排除了,最后只留下相同的部分。
所以,DEKR网络与SWAHR网络这个测试中最后输出的一致。
2. 预训练模型都设为coco数据集的预训练模型
第四步:
首先我们把训练CrowdPose的预训练模型从imagenet改为用这个网络训练coco得到的pose_coco模型pt文件。
修改cfg文件:
PRETRAINED: 'model/imagenet/hrnet_w48-8ef0771d.pth'
改为:
PRETRAINED: 'model/pose_coco/pose_dekr_hrnetw48_coco.pth'
然后打印:
for name, m in pretrained_state_dict.items():
if name.split('.')[0] in self.pretrained_layers \
or self.pretrained_layers[0] is '*':
if name in parameters_names or name in buffers_names:
print(
'=> {}'.format(name)
)
得到一下结果:
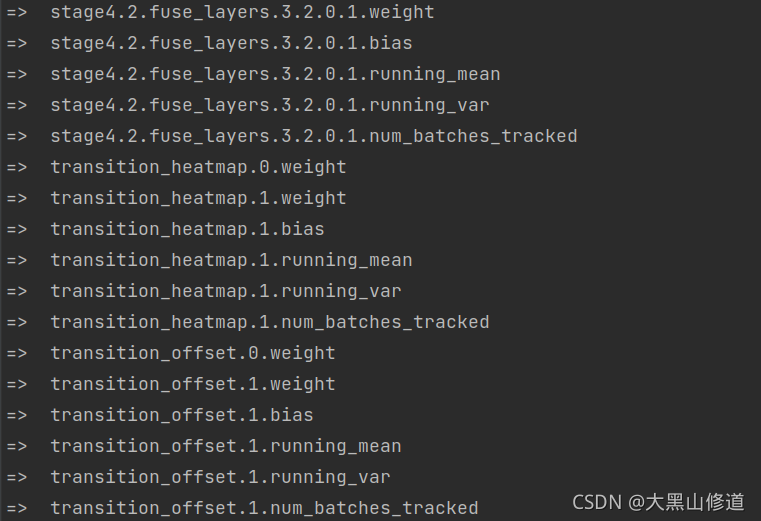
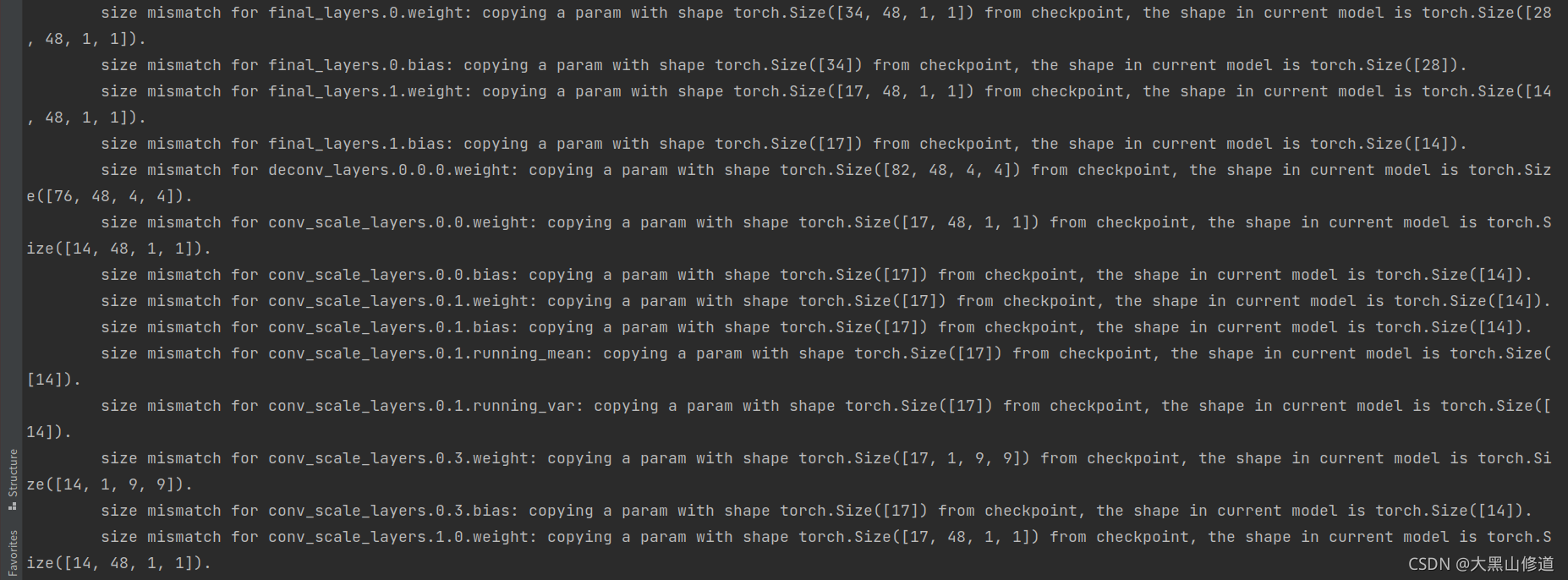
因为dekr读取全部的预训练模型节点权重,pose_coco的模型训练和dekr完全一致,所以所有训练节点名称都保留下来了。
所以理所当然就报错了,因为transition_offset的通道数不一样。
第五步:
我们将SWAHR进行对照实验,利用完全一致的coco预训练模型,完全一致的代码打印:
SWAHR结果:
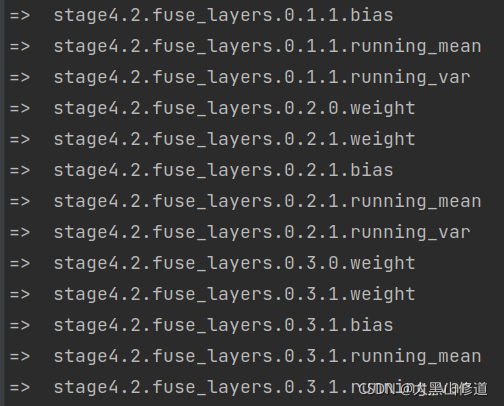
原因前面说的很清楚了,因为SWAHR只读取部分预训练模型,也就是HRNet的主干网部分,不会涉及到后面根据关键点个数进行通道数变换的卷积,因此不会出现因为姿态估计关键点不一致造成的错误。
第六步:
我们最后修改一下SWAHR的cfg部分:
令
PRETRAINED_LAYERS: ['*']
PRETRAINED: 'models/pytorch/pose_coco/pose_higher_hrnet_w48_640.pth'
导入了自己训练的coco模型全部的权重作为预训练模型,最后的实验过程:
导入coco预训练模型导入了全部的模型权重:
 最后理所当然的报错了:
最后理所当然的报错了:
总结
回到最初的问题:
为何DEKR导入自己的COCO模型作为预训练模型会报错,而SWAHR和HigherHRNet不会?
因为DEKR在代码中导入了全部的权重,最终会导致最后通道数不同的部分报错;SWAHR一类只导入了主干网络HRNet部分,所以不会报错。
如何认识预训练模型,是否预训练模型的网络结构要和自身的网络结构相同?
预训练模型实际上就是用神经网络在其他数据集中训练出来的模型,是一个具备正常功能的模型。一般情况下使用预训练模型,就是将模型在一个数据集下训练出来模型,作为预训练模型来训练另一个模型,本质上类似与扩充数据集。
预训练模型的网络结构要不需要与自身的网络结构完全相同。比如你在一个数据集上训练的模型拿来做另一个数据集的预训练模型,两个数据集的一些参数差异会导致在两个数据集上的模型不完全一致,又比如你的模型所用的预训练模型并不是用你模型的代码在其他数据集中训练出来的,而是其他的模型训练出来的。但是,必须保证的是,从预训练模型中导入权重部分网络结构必须要和自身接受权重部分的网络结构完全相同。 比如两个模型都包含同一个结构的主干网络,那么主干网络的部分,权重就可以分享,类似于HRNet。模型与预训练模型不需要完全相同,但必须有部分结构相同。
