目录
试错
一开始尝试的是形态学提取字符,但发现有些情况是相悖的,会顾此失彼,无法兼顾很多情况。?
1、没有膨胀/膨胀过小:无法连接上单个字符。?
可以看到,一些没有连接上的汉字,轮廓提取就把它们当成了多个字符。


2、膨胀过大:错误连接相邻字符。
给予膨胀之后,膨胀又太大了,虽然同一个字符的不同笔画连接成功,但是又错误地把两个字符连接在了一起。?

?
??
????????上面的算法感觉很难行得通了,除非借助其他分割算法。下面是优化后的更佳算法,用直方图处理。
一、直方图处理原理

?
1、横向分割
分割上下边框
????????把图像分为上下两部分,根据像素点的个数,找到最小的像素行(最小波谷)。?上半部分的最小波谷作为顶,下半部分的最小波谷作为底。

?
2、纵向分割
切割字符。
每一个字符前面都一定会有波谷出现,波谷出现再上升的时候,作为字符开始的判断标志。
?
?
?
过程:
一、中值滤波、灰度化
# 1、中值滤波
mid = cv.medianBlur(image, 5)
# 2、灰度化
gray = cv.cvtColor(mid, cv.COLOR_BGR2GRAY)二、二值化(统一黑底白字)
# 3、二值化
ret, binary = cv.threshold(gray, 0, 255, cv.THRESH_OTSU)
# 统一得到黑底白字
if(IsWhiteMore(binary)): #白色部分多则为真,意味着背景是白色,需要黑底白字
ret, binary = cv.threshold(gray, 0, 255, cv.THRESH_OTSU | cv.THRESH_BINARY_INV)
cv.imshow('binary', binary)# 得到黑底白字(白色多则返回真)
def IsWhiteMore(binary):
white = black = 0
height, width = binary.shape
# 遍历每个像素
for i in range(height):
for j in range(width):
if binary[i,j]==0:
black+=1
else:
white+=1
if white >= black:
return True
else:
return False
?
三、膨胀处理
?主要就是为了连接像“川”这样的横向不连接的字符。
# 4、膨胀(粘贴横向字符)
kernel = cv.getStructuringElement(cv.MORPH_RECT, (7,1)) #横向连接字符
dilate = cv.dilate(binary, kernel)
cv.imshow('dilate', dilate)
 ?
?
?
四、统计各行各列白色像素个数(为绘制直方图做准备)
# 5、统计各行各列白色像素个数(为了得到直方图横纵坐标)
ptx, pty = White_Statistic(dilate)# 二-5、统计白色像素点(分别统计每一行、每一列)
def White_Statistic(image):
ptx = [] # 每行白色像素个数
pty = [] # 每列白色像素个数
height, width = image.shape
# 逐行遍历
for i in range(height):
num = 0
for j in range(width):
if(image[i][j]==255):
num = num+1
ptx.append(num)
# 逐列遍历
for i in range(width):
num = 0
for j in range(height):
if (image[j][i] == 255):
num = num + 1
pty.append(num)
return ptx, pty五、绘制直方图(横、纵)
有了直方图,可以很直观地看出每一行、每一列的像素分布情况。?
# 6、绘制直方图(横、纵)
Draw_Hist(ptx, pty)# 二-6、绘制直方图
def Draw_Hist(ptx, pty):
# 依次得到各行、列
rows, cols = len(ptx), len(pty)
row = [i for i in range(rows)]
col = [j for j in range(cols)]
# 横向直方图
plt.barh(row, ptx, color='black', height=1)
# 纵 横
plt.show()
# 纵向直方图
plt.bar(col, pty, color='black', width=1)
# 横 纵
plt.show()
?
?
六、分割车牌图像
# 二-7、分割车牌图像(根据直方图)
def Cut_Image(ptx, pty, binary, dilate):
h1 = h2 = 0
#顶 底
begin = False #标记开始/结束
# 1、依次得到各行、列
rows, cols = len(ptx), len(pty)
row = [i for i in range(rows)]
col = [j for j in range(cols)]
# 2、横向分割:上下边框
h1, h2 = Cut_X(ptx, rows)
# 3、纵向分割:分割字符
Cut_Y(pty, cols, h1, h2, binary)1、横向分割:分割上下边框
????????把图像分为两部分:上半图和下半图,分别找它们的波谷,就可以确定字符上下边缘,进行分割。?
1-1、下半图波谷
在下半图找波谷,确定字符的下边缘。?
# 1、下半图波谷
min, r = 300, 0
for i in range(int(rows / 2)):
if ptx[i] < min:
min = ptx[i]
r = i
h1 = r # 添加下行(作为顶)?1-2、上半图波谷
在上半图找波谷,确定字符的上边缘。?
# 2、上半图波谷
min, r = 300, 0
for i in range(int(rows / 2), rows):
if ptx[i] < min:
min = ptx[i]
r = i
h2 = r # 添加上行(作为底)代码 及效果
# 2、横向分割:上下边框
h1, h2 = Cut_X(ptx, rows)
cut_x = binary[h1:h2, :]
cv.imshow('cut_x', cut_x)# 二-7-2、横向分割:上下边框
def Cut_X(ptx, rows):
# 横向切割(分为上下两张图,分别找其波谷,确定顶和底)
# 1、下半图波谷
min, r = 300, 0
for i in range(int(rows / 2)):
if ptx[i] < min:
min = ptx[i]
r = i
h1 = r # 添加下行(作为顶)
# 2、上半图波谷
min, r = 300, 0
for i in range(int(rows / 2), rows):
if ptx[i] < min:
min = ptx[i]
r = i
h2 = r # 添加上行(作为底)
return h1, h2?可以看到,上下边框明显得到了适当的切割,尤其是下边框。
?
?
?
2、纵向分割:分割字符
2-0、极大值判断(去除左右两边过大的噪声)
如果在左边或者右边出现极大值(左右按10%计算),则视为噪声,进行处理。
?
?
?
?
?
?
# 0、极大值判断
if pty[j] == max(pty):
if j < 30: # 左边(跳过)
w2 = j
if begin == True:
begin = False
continue
elif j > 270: # 右边(直接收尾)
if begin == True:
begin = False
w2 = j
b_copy = binary.copy()
b_copy = b_copy[h1:h2, w1:w2]
cv.imshow('binary%d-%d' % (count, con), b_copy)
cv.imwrite('car_characters/image%d-%d.jpg' % (count, con), b_copy)
con += 1
break2-1、前谷(前一个波谷)
# 1、前谷(前面的波谷)
if pty[j] < 12 and begin == False: # 前谷判断:像素数量<12
last = pty[j]
w = j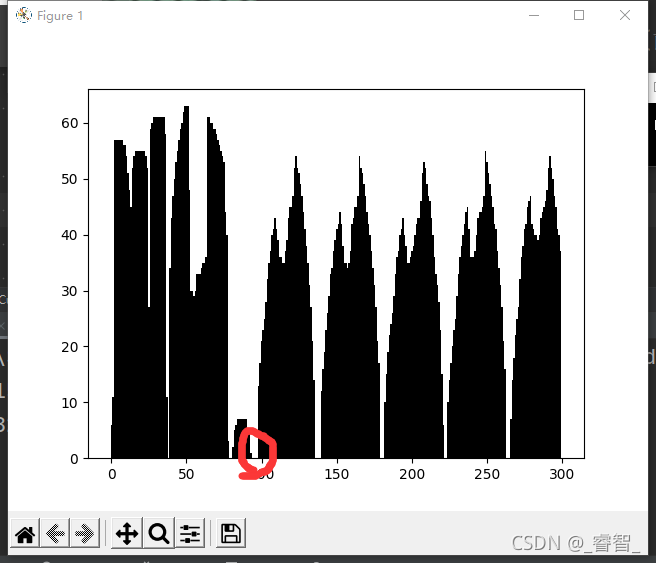
?
?2-2、字符开始(上升)
# 2、字符开始(上升)
elif last < 12 and pty[j] > 20:
last = pty[j]
w1 = j
begin = True?
?
2-3、字符结束
情景一:单个字符:直接分割(判断语句中过滤掉噪声)
# 3-1、分割并显示(排除过小情况)
if 10 < width < WIDTH + 3: # 要排除掉干扰,又不能过滤掉字符”1“
b_copy = binary.copy()
b_copy = b_copy[h1:h2, w1:w2]
cv.imshow('binary%d-%d' % (count, con), b_copy)
cv.imwrite('car_characters/image%d-%d.jpg' % (count, con), b_copy)
con += 1?
情景二:多个字符:从多字符中分割单字符
 ?
?
?
?
# 3-2、从多个贴合字符中提取单个字符
elif width >= WIDTH + 3:
# 统计贴合字符个数
num = int(width / WIDTH + 0.5) # 四舍五入
for k in range(num):
# w1和w2坐标向后移(用w3、w4代替w1和w2)
w3 = w1 + k * WIDTH
w4 = w1 + (k + 1) * WIDTH
b_copy = binary.copy()
b_copy = b_copy[h1:h2, w3:w4]
cv.imshow('binary%d-%d' % (count, con), b_copy)
cv.imwrite('car_characters/image%d-%d.jpg' % (count, con), b_copy)
con += 12-4、分割尾部杂质
由于车牌提取的时候没处理好,导致车牌尾部有些许杂质 。

?
# 4、分割尾部噪声(距离过远默认没有字符了)
elif begin == False and (j - w2) > 30:
break?
?2-5、最后的处理:检查收尾情况
?如果最后没有下降沿(波谷),那么它就不会判断为字符,那么可能会遗漏掉最后一个字符。所以我们进行一个收尾的操作。

?
# 最后检查收尾情况
if begin == True:
w2 = 295
b_copy = binary.copy()
b_copy = b_copy[h1:h2, w1:w2]
cv.imshow('binary%d-%d' % (count, con), b_copy)
cv.imwrite('car_characters/image%d-%d.jpg' % (count, con), b_copy)?
?总代码及效果
# 车牌识别
import cv2 as cv
import numpy as np
import os
from matplotlib import pyplot as plt
# 得到黑底白字(白色多则返回真)
def IsWhiteMore(binary):
white = black = 0
height, width = binary.shape
# 遍历每个像素
for i in range(height):
for j in range(width):
if binary[i,j]==0:
black+=1
else:
white+=1
if white >= black:
return True
else:
return False
# 限制图像大小(车牌)
def Limit(image):
height, width, channel = image.shape
# 设置权重
weight = width/300
# 计算输出图像的宽和高
last_width = int(width/weight)
last_height = int(height/weight)
image = cv.resize(image, (last_width, last_height))
return image
# 二-5、统计白色像素点(分别统计每一行、每一列)
def White_Statistic(image):
ptx = [] # 每行白色像素个数
pty = [] # 每列白色像素个数
height, width = image.shape
# 逐行遍历
for i in range(height):
num = 0
for j in range(width):
if(image[i][j]==255):
num = num+1
ptx.append(num)
# 逐列遍历
for i in range(width):
num = 0
for j in range(height):
if (image[j][i] == 255):
num = num + 1
pty.append(num)
return ptx, pty
# 二-6、绘制直方图
def Draw_Hist(ptx, pty):
# 依次得到各行、列
rows, cols = len(ptx), len(pty)
row = [i for i in range(rows)]
col = [j for j in range(cols)]
# 横向直方图
plt.barh(row, ptx, color='black', height=1)
# 纵 横
plt.show()
# 纵向直方图
plt.bar(col, pty, color='black', width=1)
# 横 纵
plt.show()
# 二-7-2、横向分割:上下边框
def Cut_X(ptx, rows):
# 横向切割(分为上下两张图,分别找其波谷,确定顶和底)
# 1、下半图波谷
min, r = 300, 0
for i in range(int(rows / 2)):
if ptx[i] < min:
min = ptx[i]
r = i
h1 = r # 添加下行(作为顶)
# 2、上半图波谷
min, r = 300, 0
for i in range(int(rows / 2), rows):
if ptx[i] < min:
min = ptx[i]
r = i
h2 = r # 添加上行(作为底)
return h1, h2
# 二-7-3、纵向分割:分割字符
def Cut_Y(pty, cols, h1, h2, binary):
WIDTH = 32 # 经过测试,一个字符宽度约为32
w = w1 = w2 = 0 # 前谷 字符开始 字符结束
begin = False # 字符开始标记
last = 10 # 上一次的值
con = 0 # 计数
# 纵向切割(正式切割字符)
for j in range(int(cols)):
# 0、极大值判断
if pty[j] == max(pty):
if j < 30: # 左边(跳过)
w2 = j
if begin == True:
begin = False
continue
elif j > 270: # 右边(直接收尾)
if begin == True:
begin = False
w2 = j
b_copy = binary.copy()
b_copy = b_copy[h1:h2, w1:w2]
cv.imshow('binary%d-%d' % (count, con), b_copy)
cv.imwrite('car_characters/image%d-%d.jpg' % (count, con), b_copy)
con += 1
break
# 1、前谷(前面的波谷)
if pty[j] < 12 and begin == False: # 前谷判断:像素数量<12
last = pty[j]
w = j
# 2、字符开始(上升)
elif last < 12 and pty[j] > 20:
last = pty[j]
w1 = j
begin = True
# 3、字符结束
elif pty[j] < 13 and begin == True:
begin = False
last = pty[j]
w2 = j
width = w2 - w1
# 3-1、分割并显示(排除过小情况)
if 10 < width < WIDTH + 3: # 要排除掉干扰,又不能过滤掉字符”1“
b_copy = binary.copy()
b_copy = b_copy[h1:h2, w1:w2]
cv.imshow('binary%d-%d' % (count, con), b_copy)
cv.imwrite('car_characters/image%d-%d.jpg' % (count, con), b_copy)
con += 1
# 3-2、从多个贴合字符中提取单个字符
elif width >= WIDTH + 3:
# 统计贴合字符个数
num = int(width / WIDTH + 0.5) # 四舍五入
for k in range(num):
# w1和w2坐标向后移(用w3、w4代替w1和w2)
w3 = w1 + k * WIDTH
w4 = w1 + (k + 1) * WIDTH
b_copy = binary.copy()
b_copy = b_copy[h1:h2, w3:w4]
cv.imshow('binary%d-%d' % (count, con), b_copy)
cv.imwrite('car_characters/image%d-%d.jpg' % (count, con), b_copy)
con += 1
# 4、分割尾部噪声(距离过远默认没有字符了)
elif begin == False and (j - w2) > 30:
break
# 最后检查收尾情况
if begin == True:
w2 = 295
b_copy = binary.copy()
b_copy = b_copy[h1:h2, w1:w2]
cv.imshow('binary%d-%d' % (count, con), b_copy)
cv.imwrite('car_characters/image%d-%d.jpg' % (count, con), b_copy)
# 二-7、分割车牌图像(根据直方图)
def Cut_Image(ptx, pty, binary, dilate):
h1 = h2 = 0
#顶 底
begin = False #标记开始/结束
# 1、依次得到各行、列
rows, cols = len(ptx), len(pty)
row = [i for i in range(rows)]
col = [j for j in range(cols)]
# 2、横向分割:上下边框
h1, h2 = Cut_X(ptx, rows)
# cut_x = binary[h1:h2, :]
# cv.imshow('cut_x', cut_x)
# 3、纵向分割:分割字符
Cut_Y(pty, cols, h1, h2, binary)
# 一、形态学提取车牌
def Get_Licenses(image):
# 1、转灰度图
gray = cv.cvtColor(image, cv.COLOR_RGB2GRAY)
# cv.imshow('gray', gray)
# 2、顶帽运算
# gray = cv.equalizeHist(gray)
kernel = cv.getStructuringElement(cv.MORPH_RECT, (17,17))
tophat = cv.morphologyEx(gray, cv.MORPH_TOPHAT, kernel)
# cv.imshow('tophat', tophat)
# 3、Sobel算子提取y方向边缘(揉成一坨)
y = cv.Sobel(tophat, cv.CV_16S, 1, 0)
absY = cv.convertScaleAbs(y)
# cv.imshow('absY', absY)
# 4、自适应二值化(阈值自己可调)
ret, binary = cv.threshold(absY, 75, 255, cv.THRESH_BINARY)
# cv.imshow('binary', binary)
# 5、开运算分割(纵向去噪,分隔)
kernel = cv.getStructuringElement(cv.MORPH_RECT, (1, 15))
Open = cv.morphologyEx(binary, cv.MORPH_OPEN, kernel)
# cv.imshow('Open', Open)
# 6、闭运算合并,把图像闭合、揉团,使图像区域化,便于找到车牌区域,进而得到轮廓
kernel = cv.getStructuringElement(cv.MORPH_RECT, (41, 15))
close = cv.morphologyEx(Open, cv.MORPH_CLOSE, kernel)
# cv.imshow('close', close)
# 7、膨胀/腐蚀(去噪得到车牌区域)
# 中远距离车牌识别
kernel_x = cv.getStructuringElement(cv.MORPH_RECT, (25, 7))
kernel_y = cv.getStructuringElement(cv.MORPH_RECT, (1, 11))
# 近距离车牌识别
# kernel_x = cv.getStructuringElement(cv.MORPH_RECT, (79, 15))
# kernel_y = cv.getStructuringElement(cv.MORPH_RECT, (1, 31))
# 7-1、腐蚀、膨胀(去噪)
erode_y = cv.morphologyEx(close, cv.MORPH_ERODE, kernel_y)
# cv.imshow('erode_y', erode_y)
dilate_y = cv.morphologyEx(erode_y, cv.MORPH_DILATE, kernel_y)
# cv.imshow('dilate_y', dilate_y)
# 7-1、膨胀、腐蚀(连接)(二次缝合)
dilate_x = cv.morphologyEx(dilate_y, cv.MORPH_DILATE, kernel_x)
# cv.imshow('dilate_x', dilate_x)
erode_x = cv.morphologyEx(dilate_x, cv.MORPH_ERODE, kernel_x)
# cv.imshow('erode_x', erode_x)
# 8、腐蚀、膨胀:去噪
kernel_e = cv.getStructuringElement(cv.MORPH_RECT, (25, 9))
erode = cv.morphologyEx(erode_x, cv.MORPH_ERODE, kernel_e)
# cv.imshow('erode', erode)
kernel_d = cv.getStructuringElement(cv.MORPH_RECT, (25, 11))
dilate = cv.morphologyEx(erode, cv.MORPH_DILATE, kernel_d)
# cv.imshow('dilate', dilate)
# 9、获取外轮廓
img_copy = image.copy()
# 9-1、得到轮廓
contours, hierarchy = cv.findContours(dilate, cv.RETR_EXTERNAL, cv.CHAIN_APPROX_SIMPLE)
# 9-2、画出轮廓并显示
cv.drawContours(img_copy, contours, -1, (255, 0, 255), 2)
# cv.imshow('Contours', img_copy)
# 10、遍历所有轮廓,找到车牌轮廓
i = 0
for contour in contours:
# 10-1、得到矩形区域:左顶点坐标、宽和高
rect = cv.boundingRect(contour)
# 10-2、判断宽高比例是否符合车牌标准,截取符合图片
if rect[2]>rect[3]*3 and rect[2]<rect[3]*7:
# 截取车牌并显示
print(rect)
img_copy = image.copy()
image = image[(rect[1]):(rect[1]+rect[3]), (rect[0]):(rect[0]+rect[2])] #高,宽
try:
# 限制大小(按照比例限制)
image = Limit(image)
cv.imshow('license plate%d-%d' % (count, i), image)
cv.imwrite('car_licenses/image%d-%d.jpg'%(count, i), image)
i += 1
return image
except:
pass
return image
# 二、直方图提取字符
def Get_Character(image):
# 1、中值滤波
mid = cv.medianBlur(image, 5)
# 2、灰度化
gray = cv.cvtColor(mid, cv.COLOR_BGR2GRAY)
# 3、二值化
ret, binary = cv.threshold(gray, 0, 255, cv.THRESH_OTSU)
# 统一得到黑底白字
if(IsWhiteMore(binary)): #白色部分多则为真,意味着背景是白色,需要黑底白字
ret, binary = cv.threshold(gray, 0, 255, cv.THRESH_OTSU | cv.THRESH_BINARY_INV)
cv.imshow('binary', binary)
# 4、膨胀(粘贴横向字符)
kernel = cv.getStructuringElement(cv.MORPH_RECT, (7,1)) #横向连接字符
dilate = cv.dilate(binary, kernel)
# cv.imshow('dilate', dilate)
# 5、统计各行各列白色像素个数(为了得到直方图横纵坐标)
ptx, pty = White_Statistic(dilate)
# 6、绘制直方图(横、纵)
Draw_Hist(ptx, pty)
# 7、分割(横、纵)(横向分割边框、纵向分割字符)
Cut_Image(ptx, pty, binary, dilate)
# cv.waitKey(0)
if __name__ == '__main__':
global count
count=0 #计数:第几张图片
# 遍历文件夹中的每张图片(车)
for car in os.listdir('cars'):
# 1、获取路径
path = 'cars/'+'car'+str(count)+'.jpg'
# 2、获取图片
img = cv.imread(path)
image = img.copy()
# cv.imshow('image', image)
# 3、提取车牌
image = Get_Licenses(image) #形态学提取车牌
# 4、提取字符
Get_Character(image)
count += 1
cv.waitKey(0)
?

?
?(“沪”前面的痕迹由于提取的过程处理不到位,这里实在是不好处理,直方图上和它都连一起了,所以无能为力,有办法的伙伴可以建议建议)

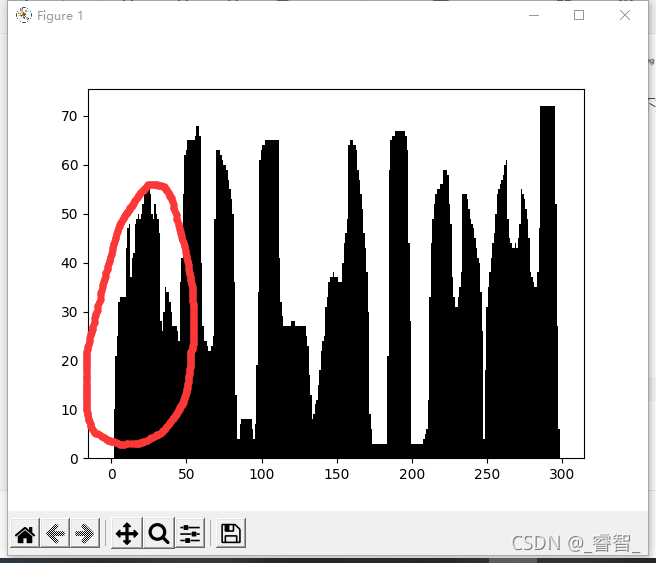
?(好家伙,直方图上看完全就是一个字了。。。)
?
?????????后面的一部分车牌提取都做的不到位,字符也分离自然不是很好。目前做的还挺菜的,有好建议的伙伴可以提出来。
?
?