当我们的算法不太符合自己的预期时,我们都有哪些改进手段?
- 去搜索更多的数据,增加训练集的数量
- 增加特征的数量,更高程度地利用已有的数据
- 尝试多项式特征
- 减少特征的数量,减轻过拟合的问题
- 增大或者减小λ
方法有很多,但是我们不能所有都用,而是要针对给出的问题选择性的做其中的一个或者几个
有时,我们的算法在训练集上有很好的表现,在实际使用时上却表现平平,这便很有可能是过拟合了
为了改善这种情况,我们将一个数据集,分为两部分
训练集(training set)和测试集(test set)
我们在训练集中训练我们的机器学习算法,然后用测试集来衡量这个算法在实际应用中的表现
通常,训练集和测试集分别占数据集的70%和30%
通常我们会:
- 在训练集中训练Θ,使其将Jtrain(Θ)最小化
- 根据Θ计算Jtest(Θ)
测试集中误差的公式如下:
-
线性回归中:与线性回归的代价函数差不多

-
逻辑回归中,我们根据错误的个数的总量除以数据总量来衡量
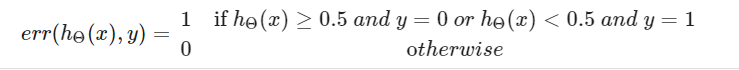

但是,慢慢的,问题来了
在选择算法时,我们一般用 d 来表示多项式的阶数 ,比如一个线性回归的问题,我可以选择用二次函数去拟合,也可以用三次函数去拟合,我们把这个阶数称为d
在这里做一点补充,一条数据,可以有很多个特征,可以是一次的,也可以是高次的,比如x1,x2这*种一次项,和x1x2,x12这种二次项等等,一般来说,特征的个数决定了线性空间,而最高次的次数决定了你这个超平面在线性空间种的形状
多项式的阶数高了,能够更好的拟合训练集
但是容易过拟合
多项式的阶数低了,则对数据的拟合就不是很理想
我们如何破局?
方法就是:
从低阶到高阶全都试一遍,然后依次带入测试集中,选出在测试集中使test error最小的 d
这样子,我们就找到了最合适的 d ,是不是感觉挺合理了?
但是但是,问题又来了
这个选出来的“最优”的 d ,也许只是针对这个test set是比较好的,所以我们选出的可能只是针对这个test error的最优解,而不一定具有普遍性,换句话说,可能泛化能力不够强
所以,我们引出接下来的概念
我们将数据集分为三部分:
1.训练集Training set 2.交叉验证集Cross validation set 3.测试集Test set
这三个集占数据集的比重比较经典的为
60%,20%,20%
我们的大致流程如下:
- 在Training set 中训练大小不同的d对应的最优的Θ
- 将各个Θ带入交叉验证集(Cross validation set)中,找到使test error 最小的解
- 将这个theta带入test set中,得到一个更加客观的性能判断
这样我们就能得到一个比较合适的 d ,从而得到一个比较合适的模型