参考链接:https://blog.csdn.net/u013733326/article/details/79869511
第一周测验 - 深度学习的实践
博主注:以下全部都是只显示正确答案。
1.如果你有10,000,000个例子,你会如何划分训练/开发/测试集?
解:训练集占98% , 开发集占1% , 测试集占1% 。
2.开发和测试集应该:
解:来自同一分布。
因为我们学习的是同一分布下的规律,如果开发集和测试集的分布不一样。那么我们通过开发集学习到的规律就不能应用到测试集上,例如,我们训练了能够识别猫的神经网络,不能直接使用来识别狗。
3.如果你的神经网络模型似乎有很高的方差,下列哪个尝试是可能解决问题的?
解:添加正则化;获取更多的训练数据
神经网络具有较高的方差,说明模型处于过拟合。可以通过添加正则化和获取更多的训练数据来解决过拟合问题。
4.你在一家超市的自动结帐亭工作,正在为苹果,香蕉和橘子制作分类器。 假设您的分类器在训练集上有0.5%的错误,以及开发集上有7%的错误。 以下哪项尝试是有希望改善你的分类器的分类效果的?
解:增加正则化参数lambda;获取更多的训练数据。
训练集上0.5%的错误,开发集上7%的错误,我们可以认为模型处于过拟合状态。过拟合可以通过增加正则化参数lambda以及获取更多的训练数据解决。
5.什么是权重衰减?
解:正则化技术(例如L2正则化)导致梯度下降在每次迭代时权重收缩。

6.当你增加正则化超参数lambda时会发生什么?
解:权重会变得更小(接近0)
增加正则化超参数lambda就意味着权重矩阵带来的影响变大,因此权重会变得更小。
7.在测试时候使用dropout:
解:不要随机消除节点,也不要在训练中使用的计算中保留1 / keep_prob因子。
在测试阶段不要用dropout,因为那样会使得预测结果变得随机。
8.将参数keep_prob从(比如说)0.5增加到0.6可能会导致以下情况
解:正则化效应被减弱;使神经网络在结束时会在训练集上表现好一些。
keep_prob增加,则保留的神经元数目变多,模型更为复杂,能够更好地拟合训练集的数据。正则化是引入了惩罚,来防止模型复杂的一种手段,因此,keep_prob增加也会导致正则化效应被削弱。
9.以下哪些技术可用于减少方差(减少过拟合):
解:Dropout;L2 正则化;扩充数据集
10.为什么我们要归一化输入x?
解:它使成本函数更快地进行优化
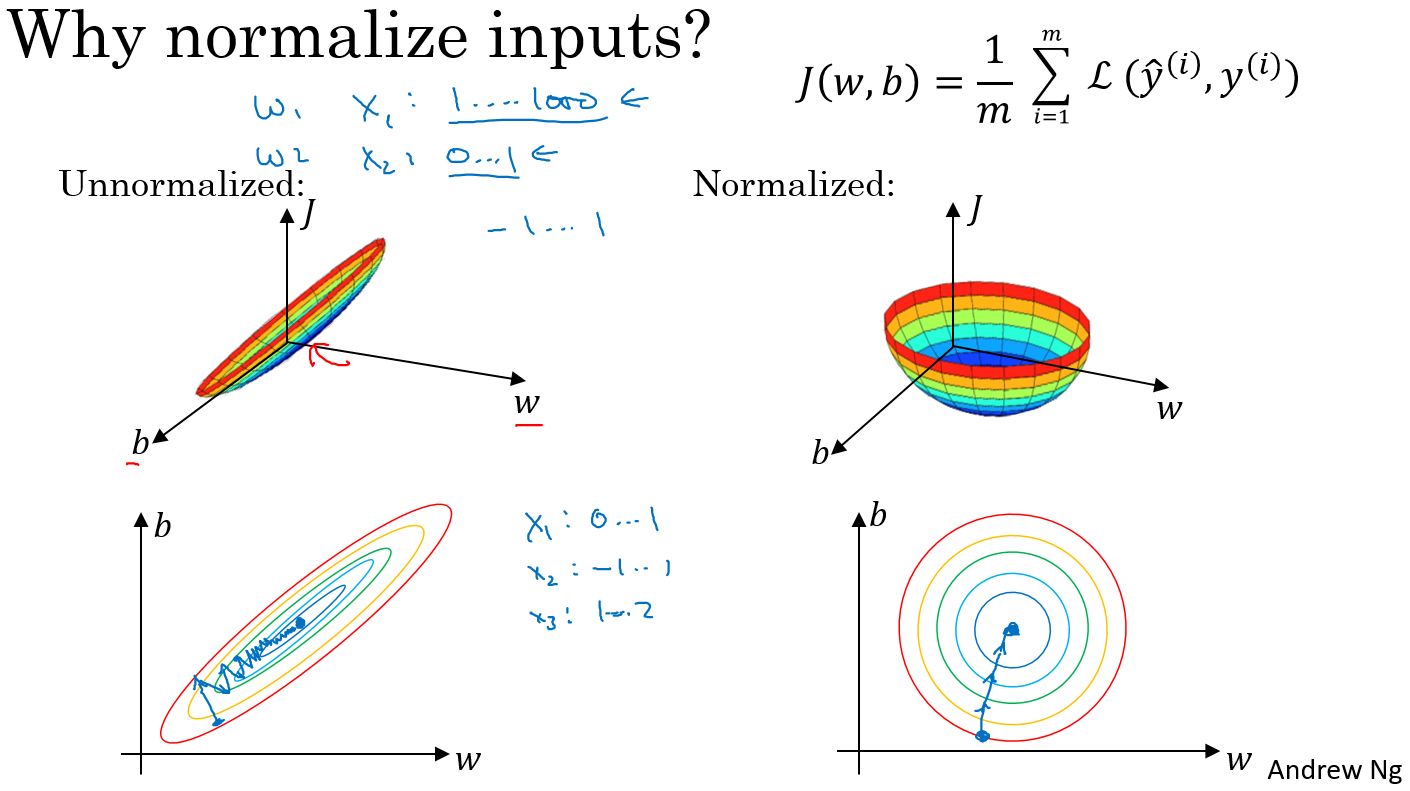
在不使用归一化的代价函数中,如果我们设置一个较小的学习率,那么很可能我们需要很多次迭代才能到达代价函数全局最优解;如果使用了归一化,那么无论从哪个位置开始迭代,我们都能以相对很少的迭代次数找到全局最优解。