1.首先理解这种任务型对话推荐
1.1过程


这一类型的对话推荐相较于传统对话推荐的一个显著优势在于:directly ask users about their preferred attributes on items(traditional methods suffer from the intrinsic limitation of passively acquiring user feedback in the process of making recommendations. )
1.2 需要解决的三个基本问题:
- what questions to ask regarding item attributes,
- when to recommend items,
- how to adapt to the users’ online feedback. To the best of our knowledge, there lacks a unified framework that addresses these problems
1.3 基于的两个假设
(1)It assumes that the user clearly expresses his preferences by specifying attributes without any reservations, and the items containing the preferred attributes are enough in the dataset
(2)It assumes that the CRS does not handle strong negative feedback.(This means, if a user rejects the asked attribute, the CRS does not distinguish whether the user does not care it or hates it. It is because such negative feedback is hard to obtain in current data, making it difficult to simulate in experimental surroundings. Therefore, the CRS equally treats all rejected attributes as does not care and only removes the attributes from the candidate set without further actions like removing all items that contain the rejected attributes.)
2.回顾一下这篇文章的baseline――EAR
该算法分为三个过程:
2.1 Estimation
在这一阶段the RC ranks candidate items and item attributes for the user, so as to support the action decision of the CC.
2.2 Action
the CC decides whether to choose an attribute to ask, or make a recommendation according to the ranked candidates and attributes, and the dialogue history.
If the user likes the attribute asked by the RC, the CC feeds this attribute back to the RC to make a new estimation again; otherwise, the system stays at the action stage: updates the dialogue history and chooses another action. Once a recommendation is rejected by a user, the CC sends the rejected items back to RC, triggering the reflection stage where the RC adjusts its estimations. After that, the system enters the estimation stage again.
2.3 Reflection
reflection是在action阶段被触发的。
3.文章摘要
CRS的一个优势是其可以“directly ask users about their preferred attributes on items.”,然而现有的CRS算法没有充分利用这一优势:“they only use the attribute feedback in rather implicit ways such as updating the latent user representation”。
本文utilizing the user preferred attributes in an explicit way:we proposeConversational Path Reasoning (CPR), a generic framework that models conversational recommendation as an interactive path reasoning problem on a graph.
By leveraging on the graph structure, CPR is able to prune off many irrelevant candidate attributes, leading to better chance of hitting user preferred attributes.
小结:
The key hypothesis of this work is that, a more explicit way of utilizing the attribute preference can better carry forward the advantages of CRS ― being more accurate and explainable
4.方法概述(作者是如何在工作中利用图结构的?)
A conversation session in our CPR is expressed as a walking in the graph. It starts from the user vertex, and travels in the graph with the goal to reach one or multiple item vertices the user likes as the destination. Note that the walking is navigated by users through conversation. This means, at each step, a system needs to interact with the user to find out which vertex to go and takes actions according to user’s response.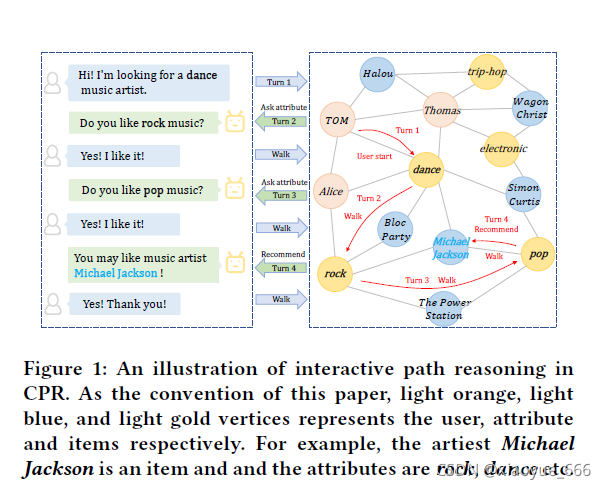
5.Contributions
(1)We propose the CPR framework to model conversational recommendation as a path reasoning problem on a heterogeneous graph which provides a new angle of building CRS. To the best of our knowledge, it is the first time to introduce graph-based reasoning to multi-round conversational recommendation.
(2)To demonstrate the effectiveness of CPR, we provide a simple instantiation SCPR, which outperforms existing methods in various settings. We find that, the larger attribute space is, the more improvements our model can achieve.
6.算法详解
The system treats attributes as the preference feedback. To explicitly utilize these feedback, CPR performs the walking (i.e., reasoning) over the attribute vertices. Specifically,CPR maintains an active path P, comprising the attributes confirmed by a user (i.e., all attributes in P_u) in the chronological order, and exploring on the graph for the next attribute vertex to walk.
Now, we move to the detailed walking process in CPR. Assumeth e current active path is P = p0,p1,p2, …,pt. The system stays at ptand is going to find the next attribute vertex to walk. This process can be decomposed into three steps: reasoning, consultation and transition.
6.1 Reasoning
与EAR模型相同,这一step也是为score items and attributes。
其中 items score也与EAR模型相同:
(但是这里利用了图信息:文章将与一个path直接相连的items作为candidate items )


相对于EAR模型的改进在于attribute scores:
(1)其利用图结构中的邻接结点,缩小了候选attributes的空间。
(2)其在打分过程中还使用了候选items
(The idea is that, with updated scores (i.e.,s_v) calculated in the first step,the items provide additional information to find proper attributes to consult the user. An expected strategy is to find the onethat can better eliminate the uncertainty of items.)
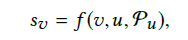
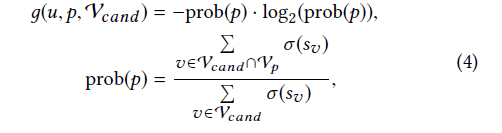
(这里采用了信息熵的方法,因为我们希望选出来的p可以减小在之后选取item时的不确定性,information entropy has proven to be an effective method of uncertainty estimation [27])
6.2 Consultation
这里也有对EAR模型的改进,EAR中搜索空间包含所有的attributes(因为其要在强化学习过程中学到要询问哪一个attribute),而这里作者搜索空间为2。
decide whether to ask an attribute or to recommend items
the standard Deep Q-learning――a two-layer feed forward neural network. The policy network takes the state vector s as input and outputs the values Q(s,a) for the two actions, indicating the estimated reward for a a s k a_{ask} aask? or a r e c a_{rec} arec?
6.3 Transition
(1)if the user confirms an asked attribute
p
t
p_t
pt?,

7.模型的优势
(1)It is crystally explainable. It models conversational recommendation as an interactive path reasoning problem on the graph, with each step confirmed by the user. Thus, the resultant path is the correct reason for the recommendation. This makes better use of the fine-grained attribute preference than existing methods that only model attribute preference in latent space
对最后一句话的解释说明:EAR模型feed the preferred attribute into a variant of factorization machine [20] to score items in the latent space.这属于隐式地对用户反馈的attribute进行利用。
(2)It facilitates the exploitation of the abundant information by introducing the graph structure. By limiting the candidate attributes to ask as adjacent attributes of the current vertex, the candidate space is largely reduced, leading to a significant advantage compared with existing CRS methods like [13, 24] that treat almost all attributes as the candidates
(3)It is an aesthetically appealing framework which demonstrates the natural combination and mutual promotion of conversation system and recommendation system. On one hand, the path walking over the graph provides a natural dialogue state tracking for conversation system, and it is believed to be efficient to make the conversation more logically coherent [12, 14]; on the other hand,being able to directly solicit attribute feedback from the user, the conversation provides a shortcut to prune off searching branches in the graph
8.模型训练
注意数据集只是静态的交互数据,而不包含对话,所以理解一下这里的训练过程。
(1)offline training
An offline training for scoring function of item in reasoning step. We use the historical clicking record in the training set to optimize our factorization machine offline (Eq. (3)). The goal is to assign higher score to the clicked item for each users.
注释:作者在这里采用了EAR模型的训练过程;

(2)online training
An online training for reinforcement learning
used in consultation step. We use a user simulator (c.f. Sec 5.2.2) to interact with the user to train the policy network using the validation set.


9.Conclusion and FUTURE WORK
We are the first to introduce graph to address the multi-round
conversational recommendation problem, and propose the Conversational Path Reasoning (CPR) framework. CPR synchronizes conversation with the graph-based path reasoning, making the utilization of attribute more explicitly hence greatly improving explainability for conversational recommendation. Specifically, it tackles what item to recommend and what attribute to ask problems through message propagation on the graph, leveraging on the complex interaction between attributes and items in the graph to better rank items and attributes. Using the graph structure, a CRS only transits to the adjacent attribute, reducing the attribute candidate space and also improving the coherence of the conversation. Also, since the items and attributes have been ranked during the message propagation, the policy network only needs to decide when to ask and when to recommend, reducing the action space to be 2. It relieves the modeling load of the policy network, enabling it to be more robust especially when the candidate space is large.
There are many interesting problems to be explored for CPR. First, CPR framework itself can be further improved. For example,CPR does not consider how to adapt the model when the user rejects a recommended item. How to effectively consider such rejected items would be an interesting and challenging task. Second, more sophisticated implementation can be considered. For example, it is possible to build more expressive models for attribute scoring other than the weighted max-entropy as adopted in this paper. Currently, the embeddings of items and attributes do not get updated during the interactive training. It would be better to build a more holistic model to incorporate the user feedback to update all parameters in the model, inclusive of user, item and attribute embeddings.