目录
1.卷积神经网络的概念
卷积神经网络(Convolutional Neural Networks, CNN)是一类包含卷积计算且具有深度结构的前馈神经网络(Feedforward Neural Networks),是深度学习(deep learning)的代表算法之一 [1-2]? 。卷积神经网络具有表征学习(representation learning)能力,能够按其阶层结构对输入信息进行平移不变分类(shift-invariant classification),因此也被称为“平移不变人工神经网络(Shift-Invariant Artificial Neural Networks, SIANN)。
?2.卷积神经网络应用领域
卷积神经网络应用领域非常广泛,主要应用于有关图像相关的,例如:图像分类、图像语义分割、图像检索、物体检测等计算机视觉的问题,还有CV领域的发展,超分辨率重构,医学任务,无人驾驶,人脸识别等领域。

?
?
?3.卷积的作用
????????3.1卷积神经网络与传统神经网络的区别

?卷积神经网络相较于传统神经网络而言,不再是单指一列,不是一个向量,不是一个特征,而是一个三维的矩阵。
??????? 3.2整体架构
一个卷积神经网络主要由以下5种结构组成:

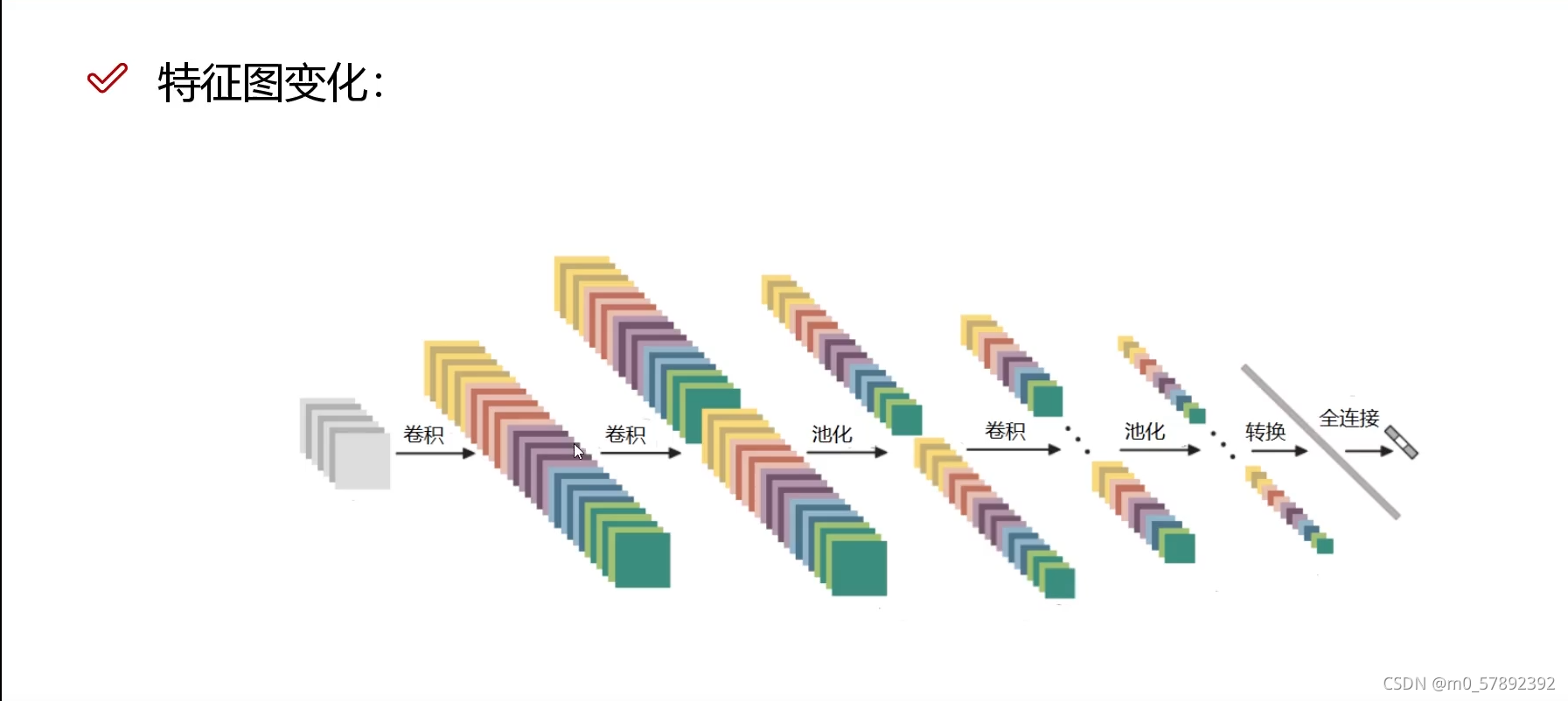
1.输入层。输入层是整个神经网络的输入,在处理图像的卷积神经网络中,它一般代表了一张图片的像素矩阵。比如在图6-7中,最左侧的三维矩阵的长和宽代表了图像的大小,而三维矩阵的深度代表了图像的色彩通道(channel)。比如黑白图片的深度为1,而在RGB色彩模式下,图像的深度为3。从输入层开始,卷积神经网络通过不同的神经网络结构下将上一层的三维矩阵转化为下一层的三维矩阵转化为下一层的三维矩阵,直到最后的全连接层。
2.卷积层。

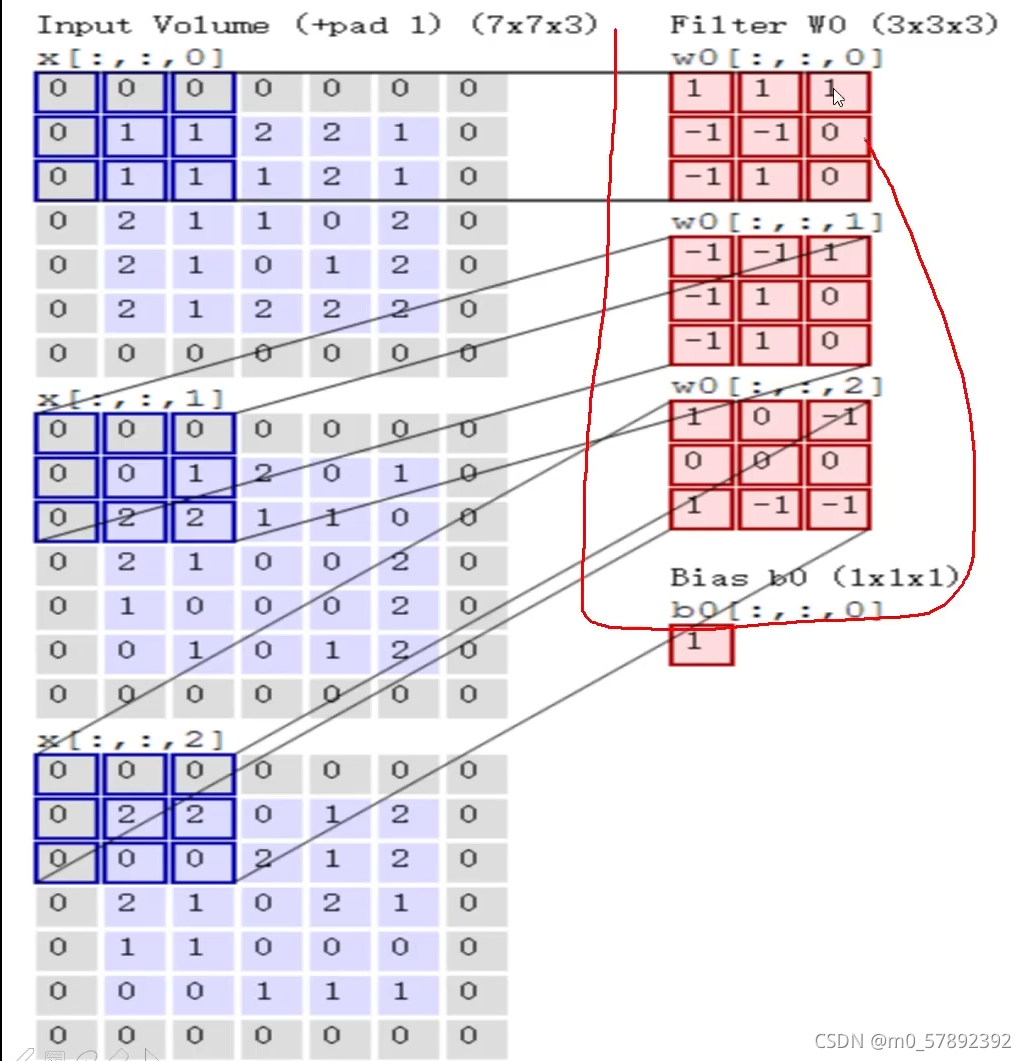
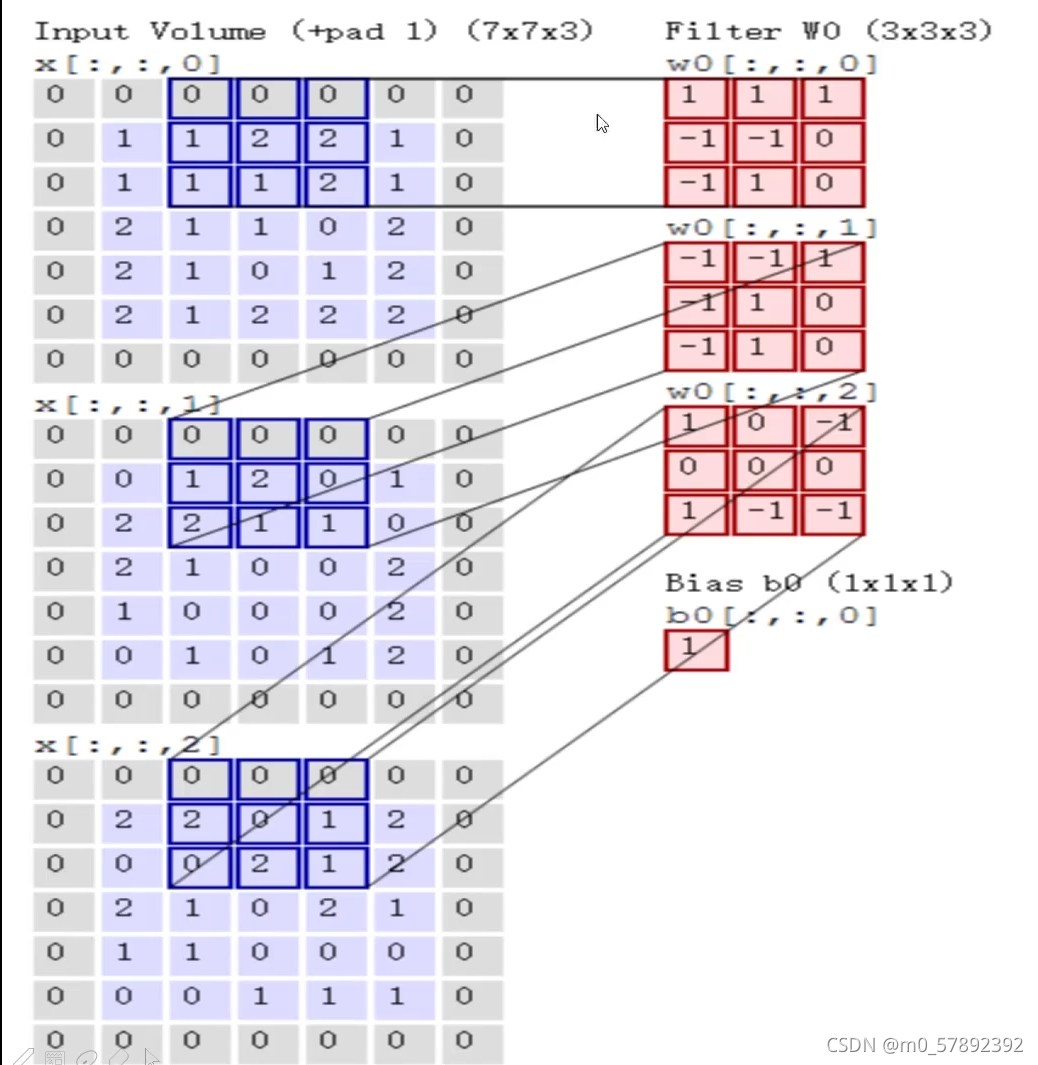
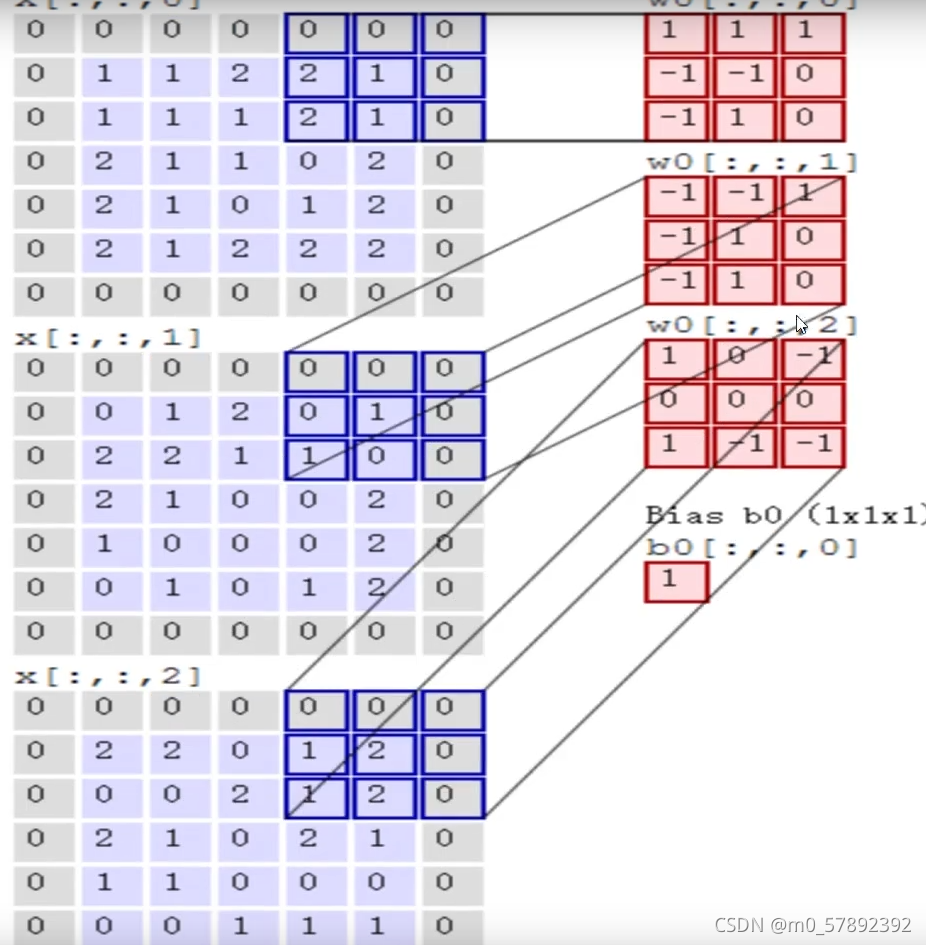
?简单来说,就是提取特征。我们都知道,一个照片有许多个像素点组成,按照上图来说,首先,我们先把图像(image)进行一个分割,分割成许多块,那么每一块就是由多个像素点组成的,通过从每一块中进行特征提取,通过权重参数来得到一个特征值。我们从中抽取出其中一个“1”小块,然后假设它是一个5*5的区域,通过一 一在每一个3*3大小的区域内(如下图区域1,2,3)选出来一个特征,因为每一个区域出来的特征是不一样的,接下来选择一个计算的方法对于每一个小区域进行计算它应该的特征值是等于多少。下面,我们对选出来的“区域1”进行,其对应一个权值参数矩阵w1=[0,1,2;2,2,0;0,1,2],将??? 区域“1”与w1作内积运算,那么就可以得出区域“1”对应的特征值即为“12”,经过一次卷积,就可以得到右边那个绿色的特征图了(一个颜色通道的特征图)
?那么,那个“32*32*3”中“3”是什么呢?
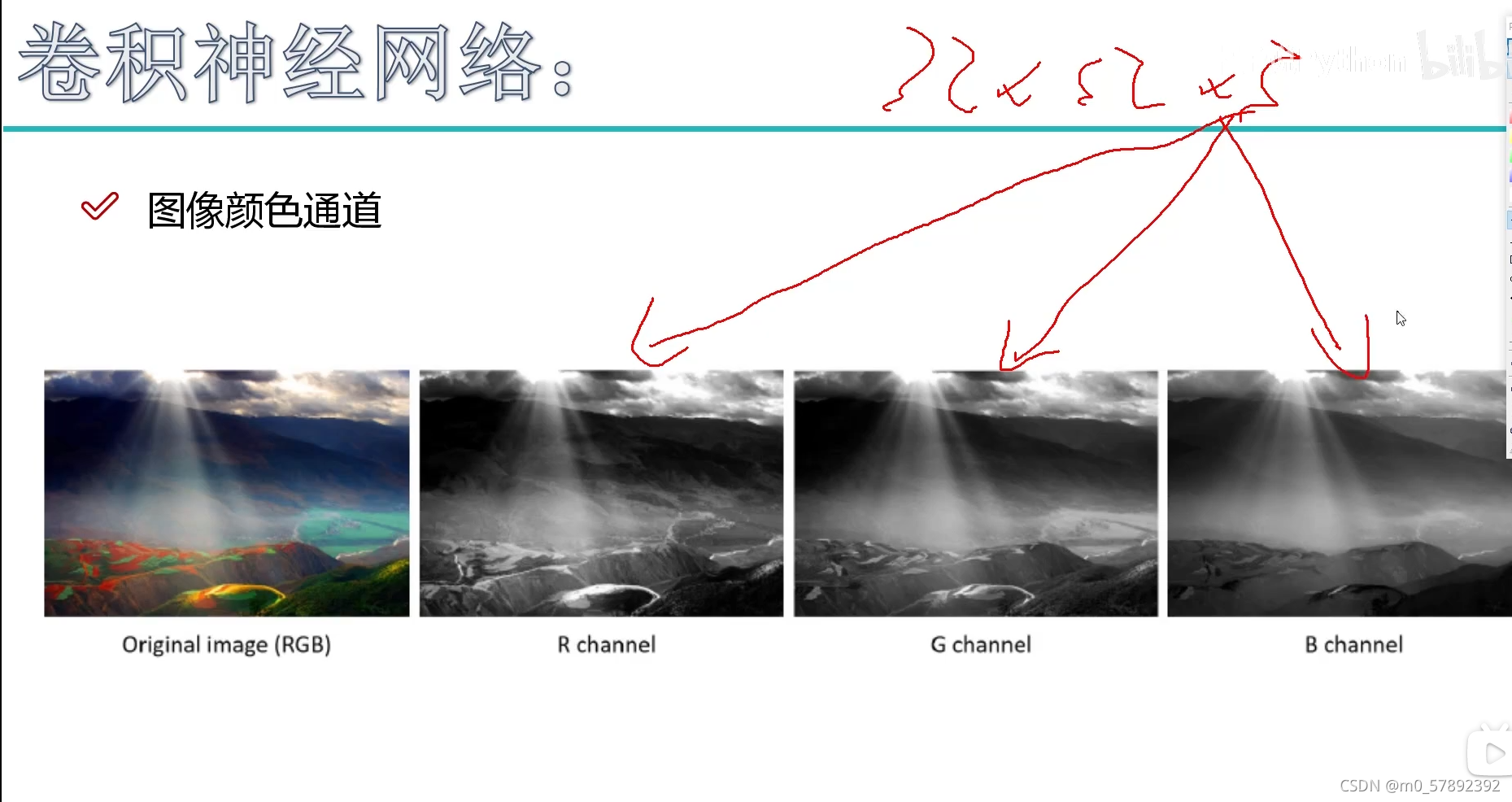
?实际上,当我们在算特征值时,我们是需要按照每个颜色通道分别去做计算,最终把每个通道卷积出来的结果加在一起就可以了。
接下来,又出现一个问题,那个特征图是如何得出来的?
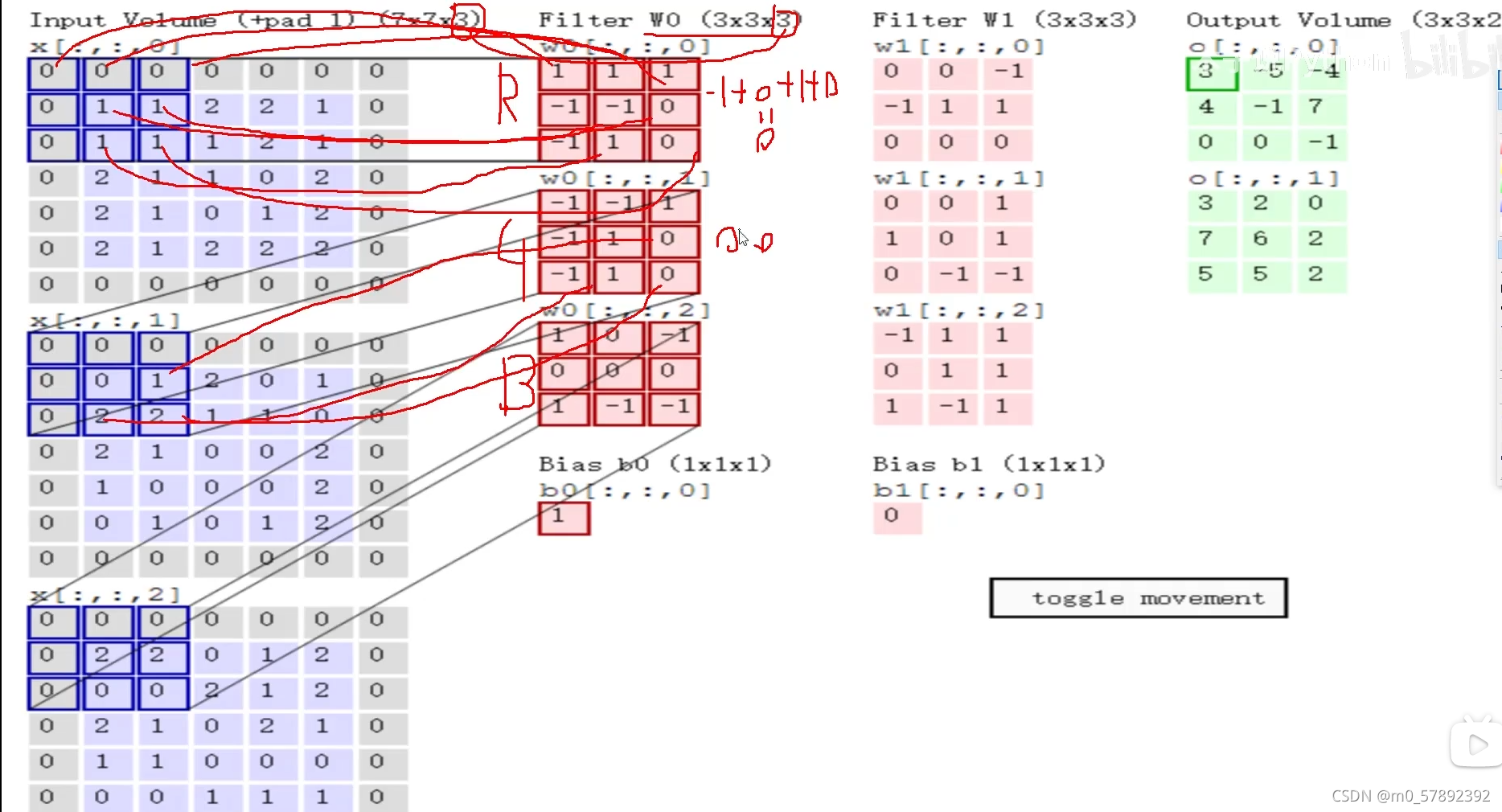
?通过上面这个例子说明一下:让每个通道的小区域的数据和对应的权值参数矩阵w做内积运算,得到的就是各通道的特征值,如此再让他们做和运算,再加上偏置b就可以得到三个通道的特征图了。
从名字就可以看出,卷积层是一个卷积神经网络中最重要的部分。和传统全连接层不同,卷积层中的每一个节点的输入只是上一层神经网络中的一小块,这个小块的大小有3*3或者5*5。卷积层试图将神经网络中的每一个小块进行更加深入的分析从而得到抽象程度更高的特征。一般来说,通过卷积层处理的节点矩阵会变得更深,所以图6-7中可以看到经过卷积层之后的节点矩阵的深度会增加。
4.全连接层。如图6-7所示,在经过多轮卷积层和池化层处理之后,在卷积神经网络的最后一般会由1到2个全连接 层来给出最后的分类结果。经过几轮的卷积层和池化层的处理之后,可以认为图像中的信息已被抽象成了信息含量更高的特征。我们可以将卷积层和池化层看成自动图像特征提取的过程。在特征提取完成之后,仍然需要使用全连接层来完成分类任务。
5.Softmax层。Softmax层主要用于分类问题。经过Softmax层,可以得到当前样例中属于不同种类的概率分布情况。
4.步长与卷积大小对结果的影响
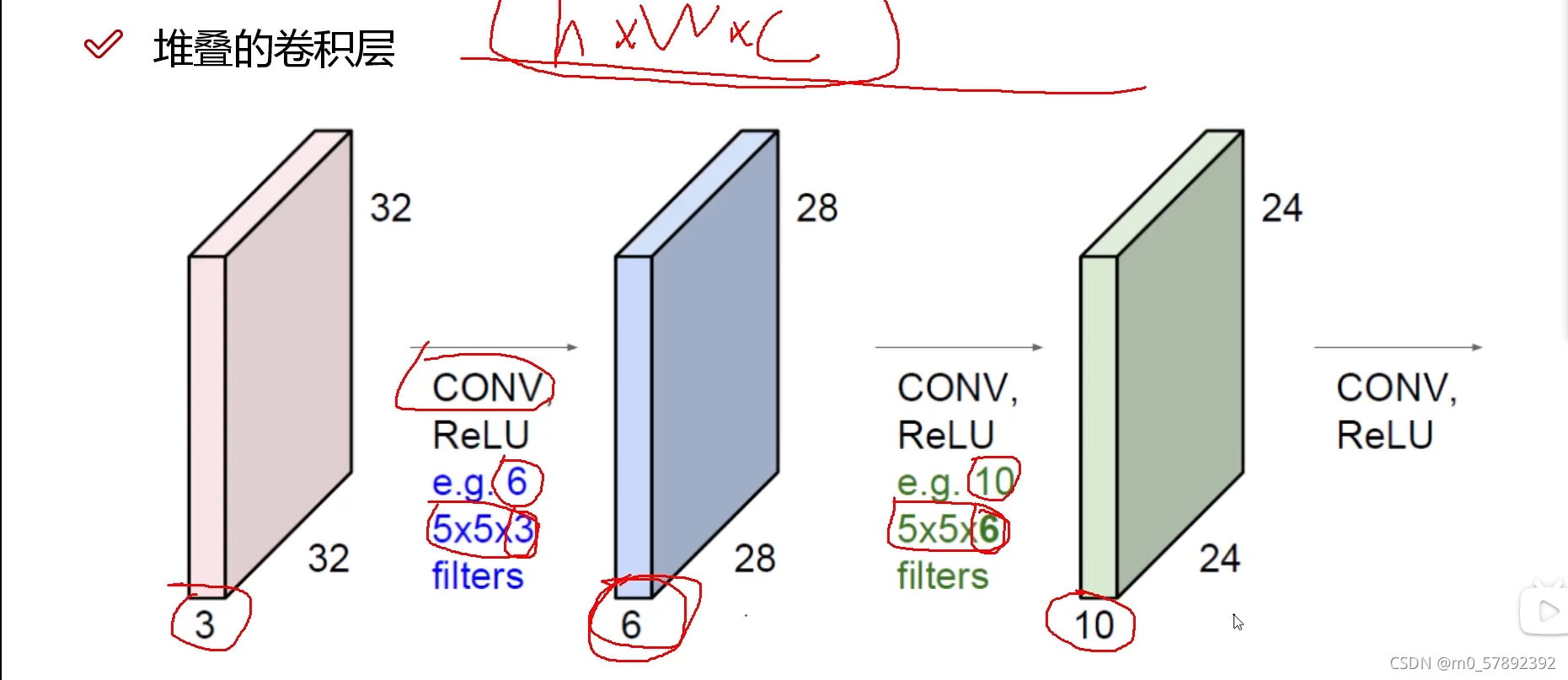
实际上,通过上面的解释,我们需求的目标――特征图,并不是一次卷积得出来的,那样得到的结果并不准确,所以就需要进行多次卷积,所谓堆叠卷积就是通过多次连续的卷积得到准确的卷积层。
4.1卷积层设计参数
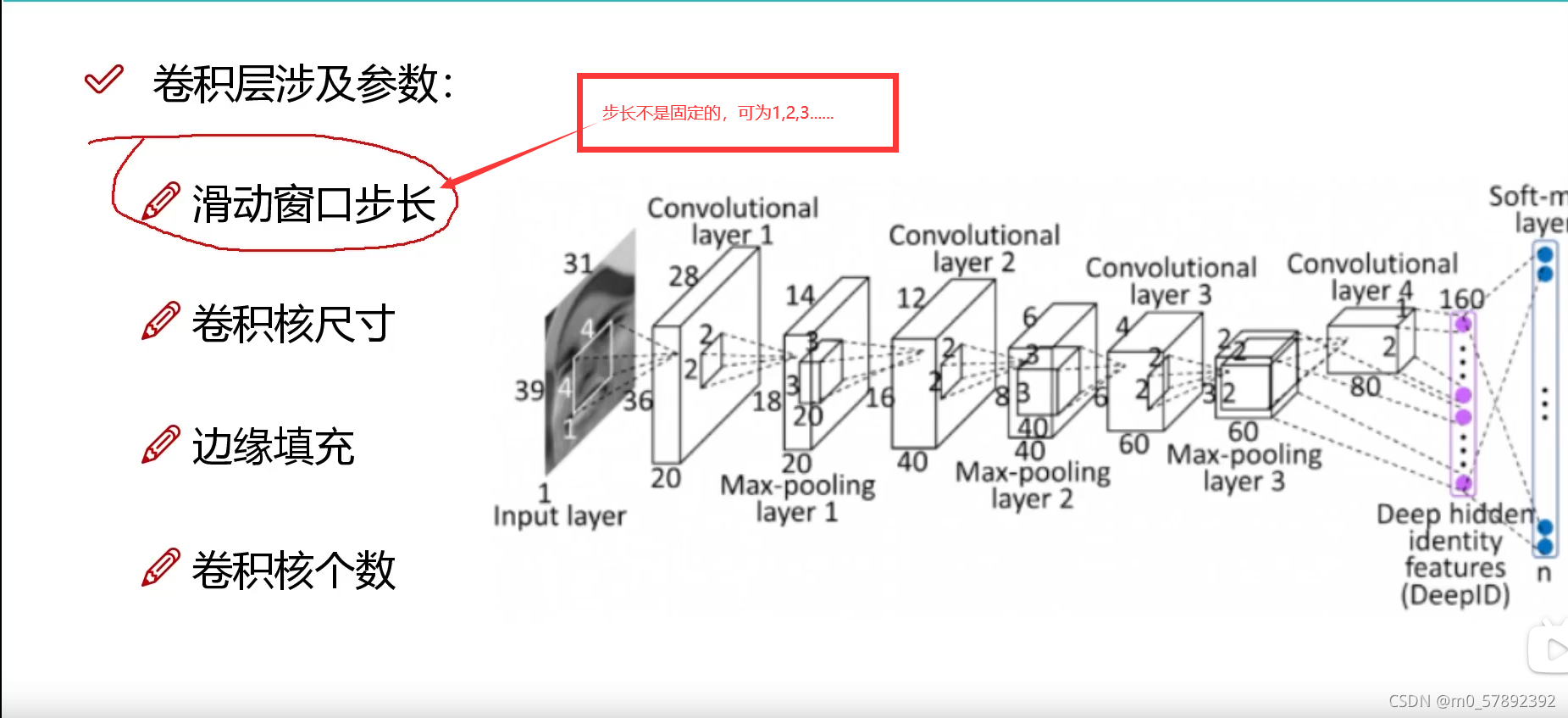
?4.1.1滑动窗口步长:
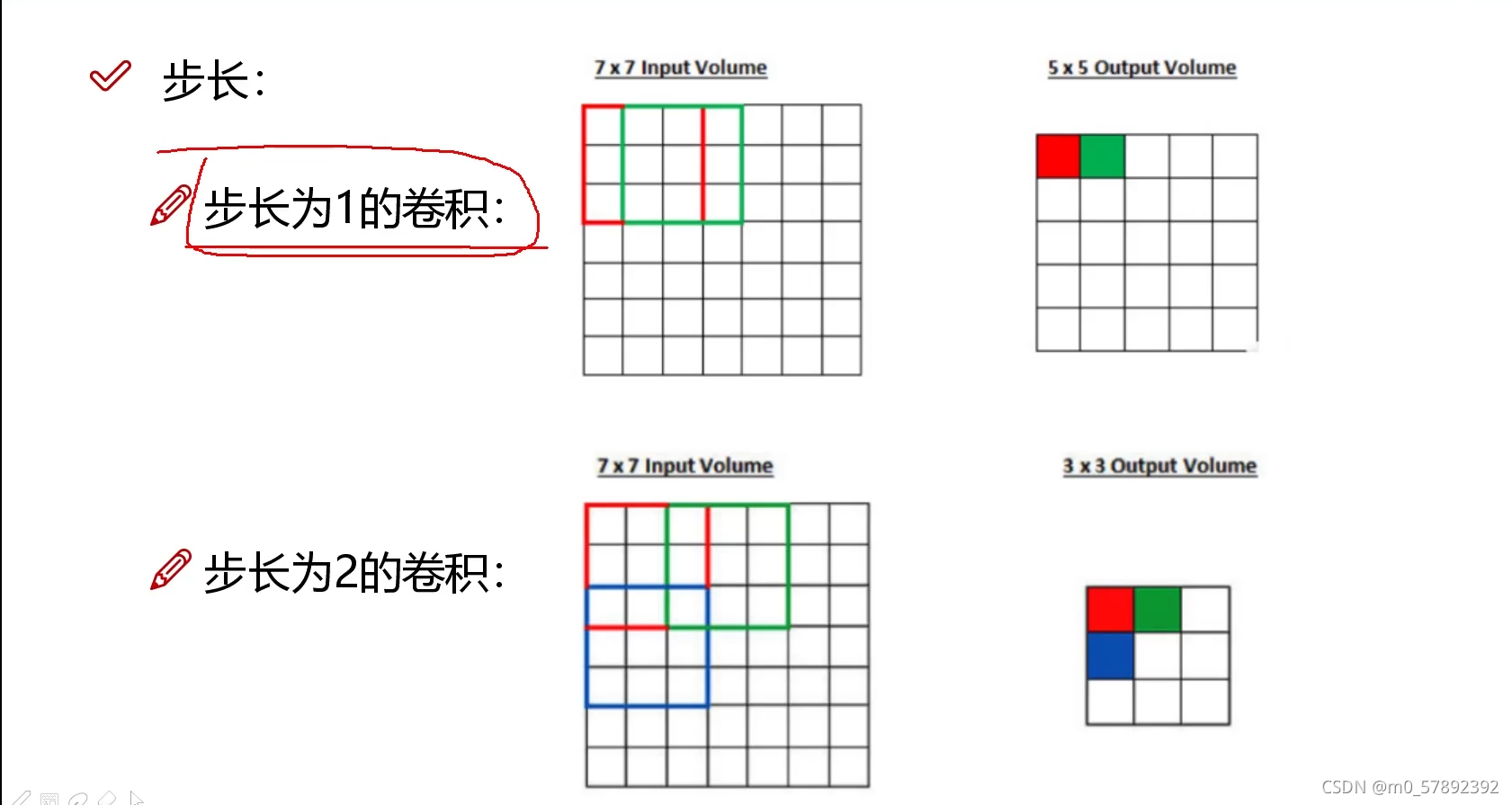
?步长越大时,所得到的特征图就比较粗糙,记过就会产生较大偏差,但同时效率会提升很多;步长较小时,得到的就比较精确,但工程量又比较大,所以步长选择要视情况而定。
4.1.2卷积核尺寸
我们所挑选的卷积核区域的大小,对我们上面讲述的就是一个“3*3”的区域
4.1.3边缘填充
卷积运算的缺点
假设图像的大小为nxn,过滤器是fxf,那么卷积运算的结果为(n-f+1)x(n-f+1)
??? 卷积运算后图像会缩小,经过若干次卷积运d算图像和图像的特征可能会缩小
??? 卷积运算中覆盖边缘和角落的像素点比中间像素点少,导致丢失图像边缘信息
为了解决这一问题,引入填充Padding
Paddingz
在图像周围填充一周的像素点(通常像素值为0),得到nxn → (n+2)x(n+2)的图像,经过卷积运算后得到nxn的图像,一般情况下卷积后图像的大小为(n+2p-f+1)x(n+2p-f+1)。
4.2.卷积结果公式
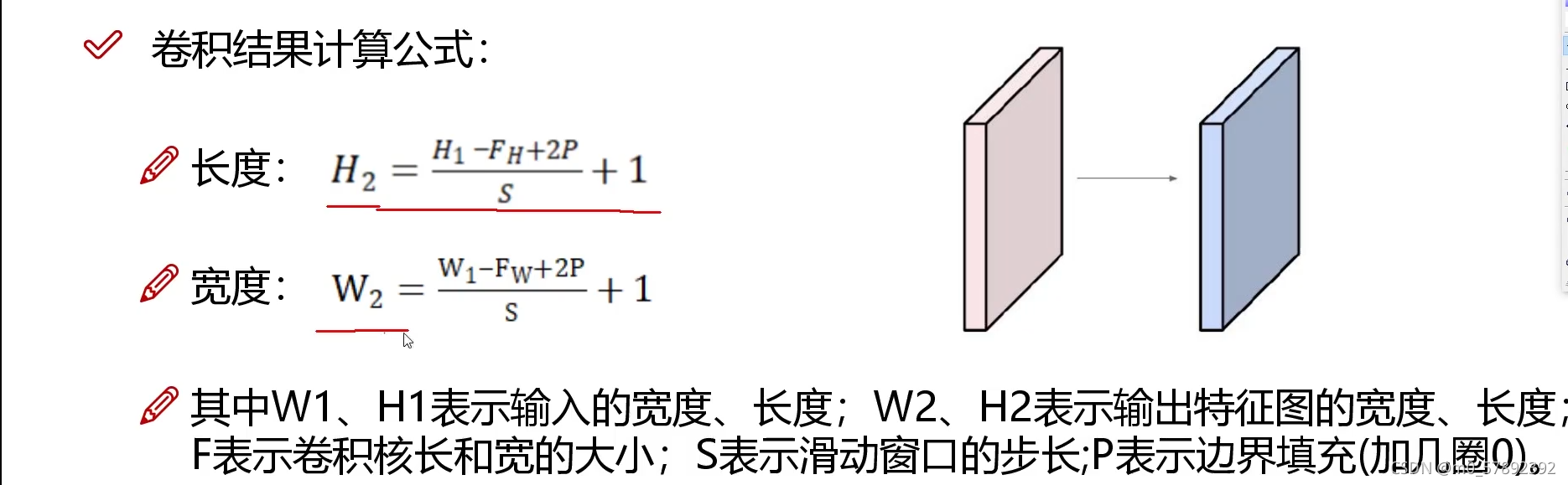
?下面举个例子说明一下:

在卷积参数当中,其中一个比较重要的特点就是――卷积参数共享:原则上讲,对于不同的区域,我们应该选择不同卷积核里面的值也应该不同,这样才会更加完美。但是,如果对每一个区域都取不同的filter核去做,那么所需要的总共的参数量就会非常庞大,这也是传统神经网络的一个弊端,那么,卷积神经网络是怎么来做的呢?它就是我们说的的――卷积参数共享,通俗来讲,就是使用同样的一组卷积核对每一个区域进行特征提取的时候,它里面的值都是一样的。
?
?

5.池化层。
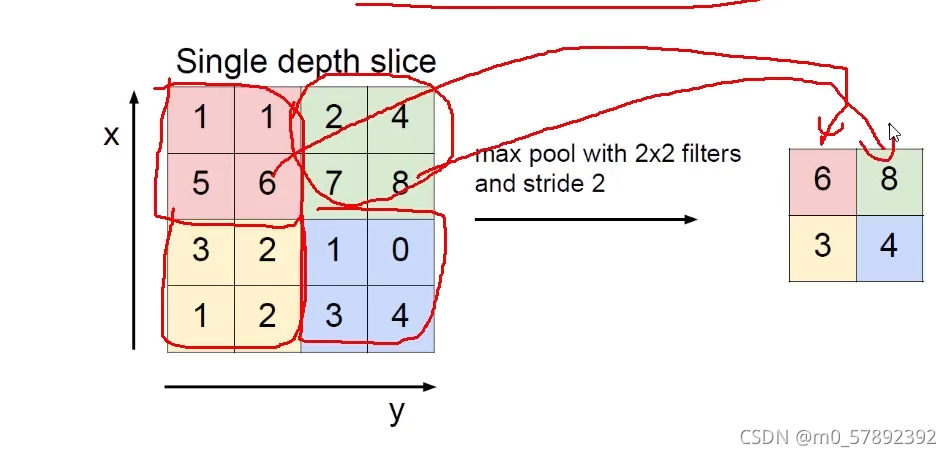
简单来讲就是压缩特征,池化层神经网络不会改变三维矩阵的深度,但是它可以缩小矩阵的大小。池化操作可以认为是将一张分辨率较高的图片转化为分辨率较低的图片。通过池化层,可以进一步缩小最后全连接层中节点的个数,从而达到减少整个神经网络中的参数的目的。
然而,压缩并不是随随便便的压缩,而是有选择性的,通过选择一些重要的留下来,不重要的丢弃。所谓的最大池化其实就是在你原始得到特征图的基础上进行一个筛选――最大池化。
下面,我们举一个例子,假设我们对其中某一个“4*4*1”特征图作最大池化,首先,他会先选择不同的区域,然后选择出每个区域里面最大的(即权重比较重要的值)
?6.整体架构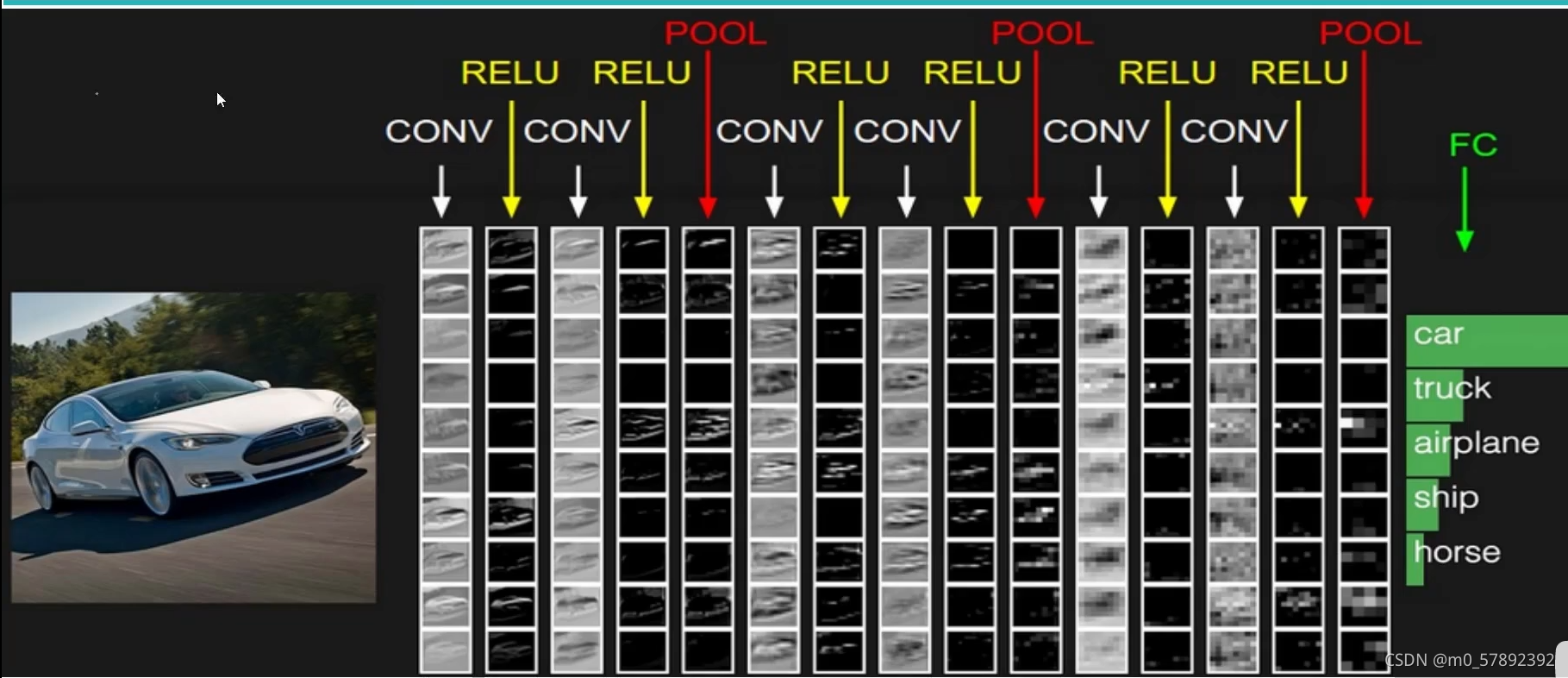
?上图中CNN要做的事情是:输入一张图片,是车还是马未知,是什么车也未知,现在需要模型判断这张图片里具体是一个什么东西,总之输出一个结果:如果是车 那是什么车。
?其中,
- CONV:卷积计算层,线性乘积 求和。
- RELU:激励层,ReLU是激活函数的一种。
- POOL:池化层,简言之,即取区域平均或最大。
- FC:全连接层。在整个卷积神经网络中起到“分类器”的作用,即通过卷积、激活函数、池化等深度网络后,再经过全连接层对结果进行识别分类。
那么,上图是一个多少层的卷积神经网络呢,它是如何来算的呢?
带参数计算的才能算做一层,在卷积层,激活层,池化层,全连接层中,只有卷积层,全连接层是带参数计算的,所以为7层。
7.特征图变化
8.运行
import torch
from torch import nn,optim
import torch.nn.functional as F
from torch.autograd import Variable
from torch.utils.data import DataLoader
from torchvision import transforms
from torchvision import datasets
import os
batch_size = 200 # 分批训练数据、每批数据量
learning_rate = 1e-2 # 学习率
num_epoches = 20 # 训练次数
DOWNLOAD_MNIST = True # 是否网上下载数据
# Mnist digits dataset
if not(os.path.exists('./mnist/')) or not os.listdir('./mnist/'):
# not mnist dir or mnist is empyt dir
DOWNLOAD_MNIST = True
train_dataset = datasets.MNIST(
root = './mnist',
train= True, #download train data
transform = transforms.ToTensor(),
download=DOWNLOAD_MNIST
)
test_dataset = datasets.MNIST(
root='./mnist',
train=False, #download test data
transform=transforms.ToTensor(),
download=DOWNLOAD_MNIST
)
#该接口主要用来将自定义的数据读取接口的输出或者PyTorch已有的数据读取接口的输入
# 按照batch size封装成Tensor,后续只需要再包装成Variable即可作为模型的输入
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True) #shuffle 是否打乱加载数据
test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False)
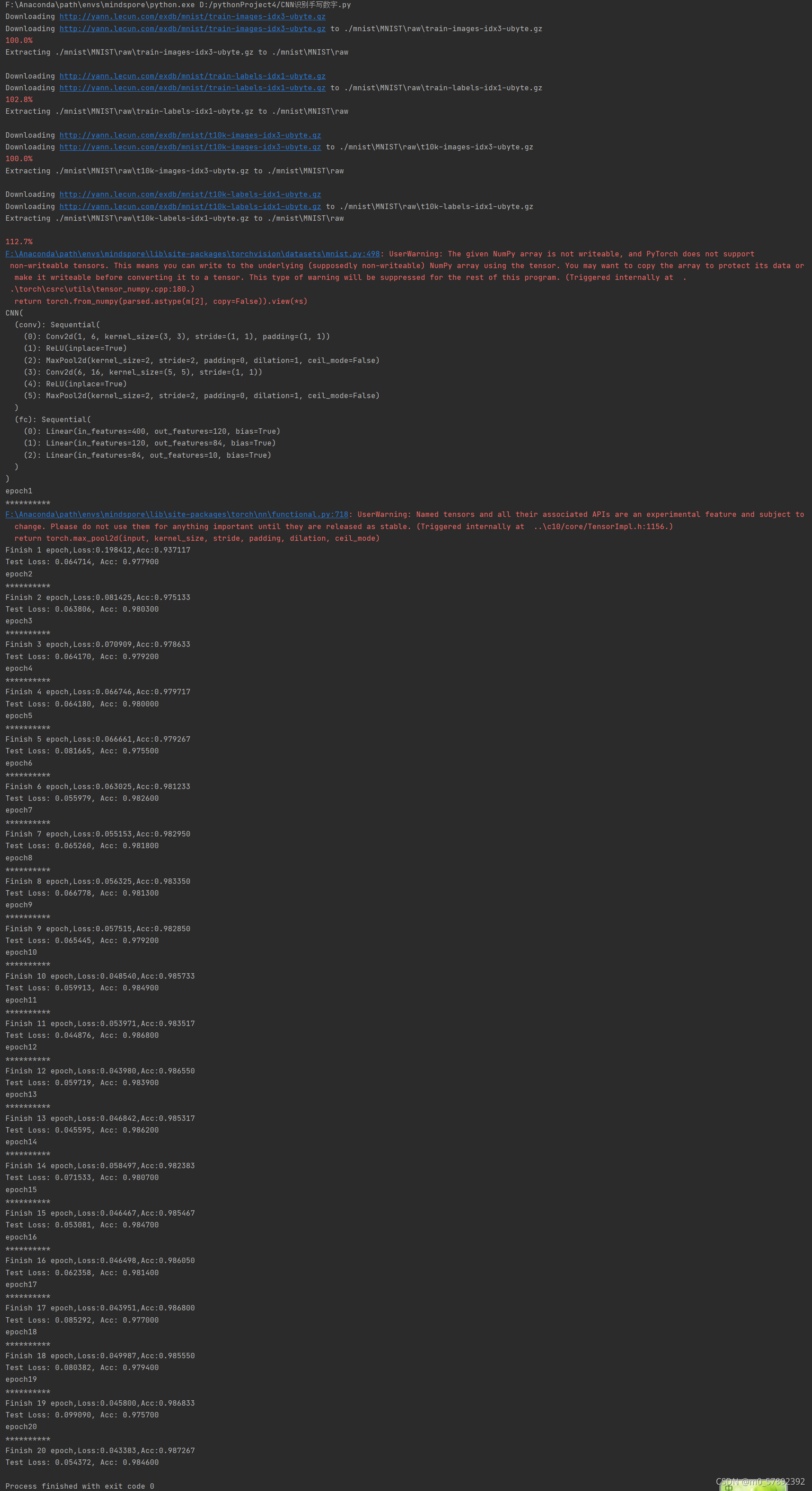
class CNN(nn.Module):
def __init__(self,in_dim,n_class):
super(CNN,self).__init__()
self.conv = nn.Sequential(
nn.Conv2d(in_dim,6,kernel_size=3,stride=1,padding=1),
# input shape(1*28*28),(28+1*2-3)/1+1=28 卷积后输出(6*28*28)
# 输出图像大小计算公式:(n*n像素的图)(n+2p-k)/s+1
nn.ReLU(True), # 激活函数
nn.MaxPool2d(2,2), # 28/2=14 池化后(6*14*14)
nn.Conv2d(6,16,5,stride=1,padding=0), # (14-5)/1+1=10 卷积后(16*10*10)
nn.ReLU(True),
nn.MaxPool2d(2,2) #池化后(16*5*5)=400,the input of full connection
)
self.fc = nn.Sequential( #full connection layers.
nn.Linear(400,120),
nn.Linear(120,84),
nn.Linear(84,n_class)
)
def forward(self, x):
out = self.conv(x) #out shape(batch,16,5,5)
out = out.view(out.size(0), -1) #out shape(batch,400)
out = self.fc(out) #out shape(batch,10)
return out
cnn = CNN(1, 10)
print(cnn)
if torch.cuda.is_available(): #是否可用GPU计算
cnn = cnn.cuda() #转换成可用GPU计算的模型
criterion = nn.CrossEntropyLoss() #多分类用的交叉熵损失函数
optimizer = optim.Adam(cnn.parameters(), lr=learning_rate)
#常用优化方法有
#1.Stochastic Gradient Descent (SGD)
#2.Momentum
#3.AdaGrad
#4.RMSProp
#5.Adam (momentum+adaGrad) 效果较好
for epoch in range(num_epoches):
print('epoch{}'.format(epoch+1))
print('*'*10)
running_loss = 0.0
running_acc = 0.0
#训练
for i,data in enumerate(train_loader,1):
img,label = data
# 判断是否可以使用GPU,若可以则将数据转化为GPU可以处理的格式。
if torch.cuda.is_available():
img = Variable(img).cuda()
label = Variable(label).cuda()
else:
img = Variable(img)
label = Variable(label)
out = cnn(img)
loss = criterion(out,label)
running_loss += loss.item() * label.size(0)
_, pred = torch.max(out,1)
num_correct = (pred == label).sum()
accuracy = (pred == label).float().mean()
running_acc += num_correct.item()
optimizer.zero_grad()
loss.backward()
optimizer.step()
print('Finish {} epoch,Loss:{:.6f},Acc:{:.6f}'.format(
epoch+1,running_loss/(len(train_dataset)),running_acc/len(train_dataset)
))
#测试
cnn.eval() #eval()时,模型会自动把BN和DropOut固定住,不会取平均,而是用训练好的值
eval_loss = 0
eval_acc = 0
for i, data in enumerate(test_loader, 1):
img, label = data
#判断是否可以使用GPU,若可以则将数据转化为GPU可以处理的格式。
if torch.cuda.is_available():
img = Variable(img).cuda()
label = Variable(label).cuda()
else:
img = Variable(img)
label = Variable(label)
out = cnn(img)
loss = criterion(out,label)
eval_loss += loss.item() * label.size(0)
_, pred = torch.max(out, 1)
num_correct = (pred == label).sum()
accuracy = (pred == label).float().mean()
eval_acc += num_correct.item()
print('Test Loss: {:.6f}, Acc: {:.6f}'.format(eval_loss / (len(
test_dataset)), eval_acc/len(test_dataset)))
# Save the Trained Model
ckpt_dir = 'F:/'
save_path = os.path.join(ckpt_dir, 'CNN_model_weight2.pth.tar')
torch.save({'state_dict': cnn.state_dict()}, save_path)运行结果
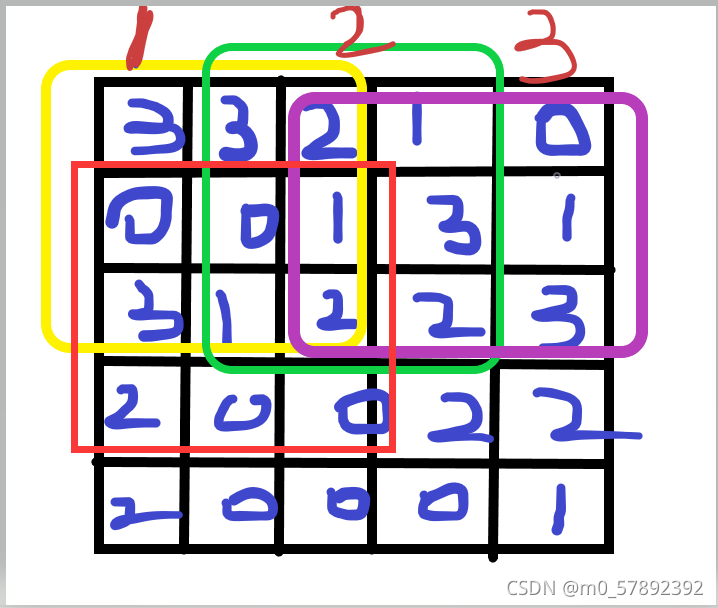
?手写数字

?测试二:
?
?
?