BERT(Bidirectional Encoder Representations from Transformers)
论文: https://arxiv.org/abs/1810.04805.
代码及预训练模型: https://github.com/google-research/bert.
序言
BERT is designed to pretrain deep bidirectional representations from
unlabeled text by jointly conditioning on both left and right context in all layers. As a result, the pre-trained BERT model can be finetuned with just one additional output layer to create state-of-the-art models for a wide
range of tasks, such as question answering and language inference, without substantial taskspecific architecture modifications.
BERT作为大规模预训练模型,使用unlabel的语料进行预训练,但其经过微调后在下游任务中却能取得非常好的表现。
有人用“一切过往, 皆为序章”形容BERT可以说非常有趣,BERT的提出改变了NLP的生态,就如同word embedding被提出时一般,现在的相关比赛都逃不开BERT及其衍生的模型。
在这篇文章,我们主要介绍三个方面内容
- BERT模型结构
- 怎么pre-train
- 怎么fine-tuning
BERT网络架构
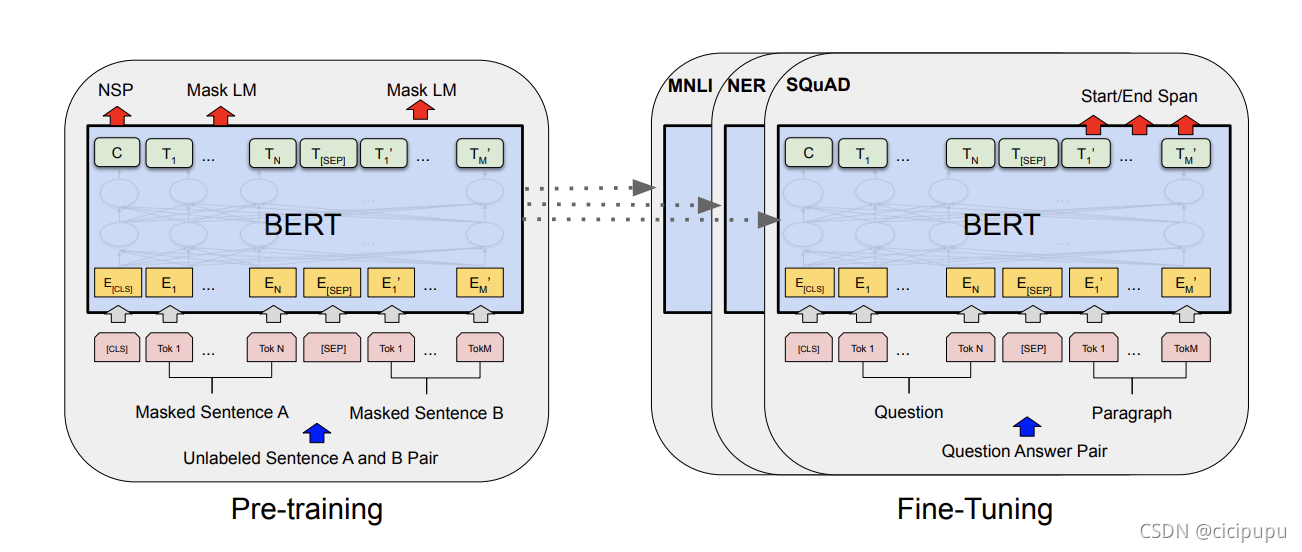
BERT采用了双向Transformer堆叠的网络结构,其中large bert 和base bert对应复杂和简单两个bert模型。
