Torch:?
from torch.utils.data import Dataset 数据读取模块from torch.utils.data import DataLoader 数据分批from torchvision import transforms
图像处理,灰度处理;缩放图像;90%的数据灰度化;将图像转换为tensor;归一化import torch.nn as nn 导入网络模块import torch.nn.functional as F #F.relu/max_pool/fcfrom torch.optim import SGD # 随机梯度下降图像处理:
from PIL import Imageimport cv2cv2.CascadeClassifier(" ")# 人脸检测
img = cv2.imread("girl.jpg")
cv2.imwrite("girl_v2.jpg", img)
# cv2.imshow("img", img)??# cv2.waitKey(0)机器学习:
公用(公用部分):
from sklearn.model_selection import train_test_split
#拆分数据集from sklearn.preprocessing import StandardScaler 预处理标准差标准化:
std = StandardScaler()
std.fit(X_train)
X_train = std.transform(X_train)
X_test = std.transform(X_test)## 多项式特征:
from sklearn.preprocessing import PolynomialFeatures #CV网格搜索:
from sklearn.model_selection import GridSearchCV
param_grid = {"criterion": ["gini", "entropy"],
"max_depth": range(2, 20)}
grid = GridSearchCV(dt, param_grid=param_grid,cv=10)
grid.fit(X_train, y_train) print(grid.best_params_)评估结果:

?
?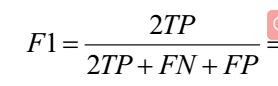
?
?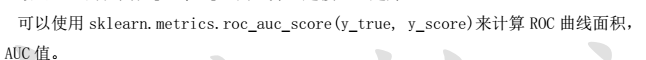
?
?PR曲线:
from sklearn.metrics import accuracy_score # 准确率
from sklearn.metrics import recall_score # 查全率
from sklearn.metrics import precision_score # 查准率
from sklearn.metrics import confusion_matrix
from sklearn.metrics import classification_report # 分类报告from sklearn.metrics import plot_precision_recall_curve
plot_precision_recall_curve(alg, X_test, y_test)
plt.show() #画PR曲线# 3. 观察相关性
print(data.corr()) # 相关性的计算方式:
{'pearson', 'kendall', 'spearman'}from sklearn.metrics import mean_squared_error # MSE
from sklearn.metrics import mean_absolute_error # MAE
print("均方误差", mean_squared_error(y_test, y_pred))
print("均方根误差RMSE", np.sqrt(mean_squared_error(y_test, y_pred)))
print("平均绝对误差MAE", mean_absolute_error(y_test, y_pred))
print("R2", lr.score(X_test,y_test))算法类的:
Xgbboost:
from xgboost import XGBClassifier
from xgboost import XGBRegressor
from xgboost import plot_tree
from xgboost import plot_importance #画树图
import matplotlib.pyplot as plt
from xgboost import to_graphviz randomFrest:

?
?
?
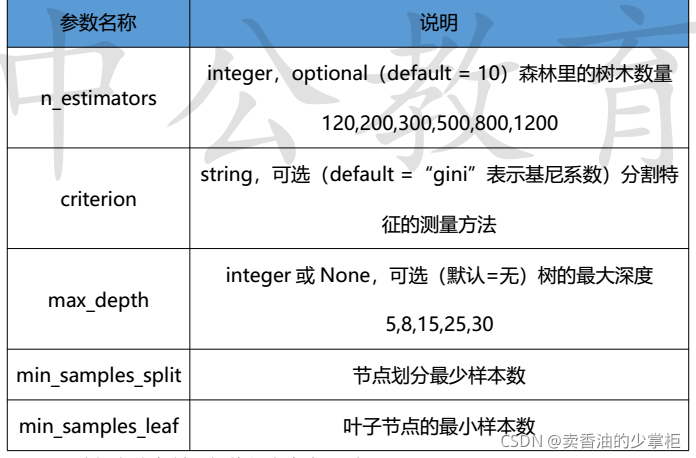
from sklearn.ensemble import RandomForestClassifier
from sklearn.ensemble import RandomForestRegressordot_file = to_graphviz(xgb, num_trees=1, fmap='iris_xgb_v2.fmap')
dot_file.render("iris_xgb.dot")决策树:
from sklearn.tree import DecisionTreeClassifier
from sklearn.tree import export_graphviz
?词频向量化:
import jieba #中文分词
from sklearn.feature_extraction.text import CountVectorizer # 词频向量化
import joblibout = " ".join(list(jieba.cut(text)))
cnt = CountVectorizer(stop_words=stop_words)
cnt.fit(train_X)
train_X = cnt.transform(train_X).toarray()
test_X = cnt.transform(test_X).toarray()joblib.dump(cnt, "词频向量化.model") # 保存词频向量化
joblib.dump(alg, "垃圾邮件分类.model") # 保存模型jcnt = joblib.load("词频向量化.model")
test_text = cnt.transform(test_text).toarray()alg = joblib.load("垃圾邮件分类.model")
print("预测结果", alg.predict(test_text))贝叶斯:
from sklearn.naive_bayes import MultinomialNB #多项式?
?
?
?
?逻辑回归:
from sklearn.linear_model import LogisticRegression
# 逻辑回归
from sklearn.linear_model import SGDRegressor
# 随机梯度下降的线性回归
from sklearn.linear_model import LinearRegression
# 正规方程的线性回归回归算法的评估导包:

?
from sklearn.linear_model import Ridge # 岭回归
基础回归+L2正则化
from sklearn.linear_model import Lasso # 套索回归
基础回归+L1正则化
# pf = PolynomialFeatures(degree=2)
# X = pf.fit_transform(X) #特征多项式增维度KNN算法:
from sklearn.neighbors import KNeighborsClassifier # KNN的分类算法
?
?k-means :
from sklearn.cluster import KMeans
?
?
from sklearn.metrics import silhouette_score
silhouette_score(train, y_pred) # 轮廓系数 范围【-1,1】
; 最好情况是1#TD-idf :
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.feature_extraction.text import TfidfTransformer词云 :
from wordcloud import WordCloud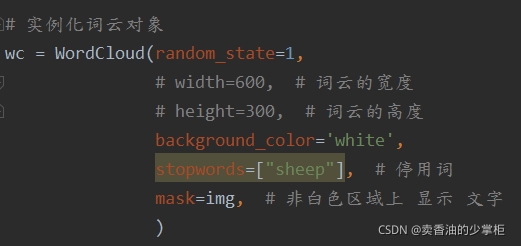
?
# 从文本中生成词云文本
wc_text = wc.generate_from_text(texts)
plt.imshow(wc_text)
plt.show()#pyecharts 词云 :
from pyecharts.charts import WordCloud
cnt = Counter(texts) # 每个词出现的次数
wc = WordCloud()
wc.add(series_name="",
data_pair=out,
mask_image="../ML_data/qie.png",
)
wc.render("中文词云.html")
?
?