һ������ѧϰ(���ѧϰ)�е���ѧ����
1.���Դ���:���ݱ�ʾ���ռ�任�Ļ�����
2.������(ͳ��):ģ�ͼ��衢������ƵĻ�����
3.���Ż�:���Ŀ�꺯���ľ����㷨��
4.��Ϣ��:���ڲ�ȷ���ԵĶ���,��Ϣ����ѡ������,�����ء�
5.����:��ʽ��,̩��չ����
6.�������Ա任,������˶�ԭʼ����ͬʱʩ�ӷ���仯�ͳ߶ȱ仯��������������,���������ֻ�г߶ȱ仯��û�з���仯���߶ȱ仯ϵ����������ֵ��
7.���Դ���:��
-
���Է�����ĽǶ�:������������֮�������ԡ�
-
���ݵ�ֲ��ĽǶ�:��ʾ������Ҫ����С������������
(1)���ݷֲ�ģʽԽ���ױ���,����Ҫ�Ļ�Խ��,�Ⱦ�ԽС��
(2)���������Խ��,��Ҫ�Ļ���Խ��,��ԽС��
(3)�������������ṹ����Ϣ,��ͼ���û�-��Ʒ����,����֮�����һ�������,һ���ǵ��ȵġ�
8.���ݽ�ά,����ֵ�ֽ�,�ϴ�����ֵ�����˾������Ҫ��Ϣ��
9.���Ƚ���,�����屣���������ݷֲ�������Ҫ��ģʽ/����(�����Ŀ������������������ؼ���Ϣ)������:�Ƽ�ϵͳ,ͼ��ȥ��ȡ�

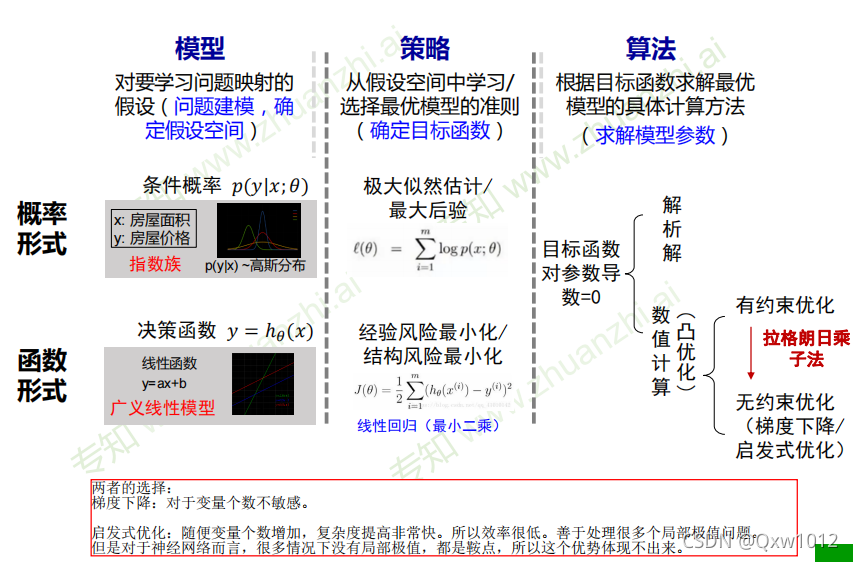
��������ѧϰ��Ҫ��:ģ�͡����ԡ��㷨
(һ)����/������ʽ��ͳһ
(��)�����š��IJ������
-
����Ŀ��:ѵ�����С & ���������
-
�������: �������Ͷ���,�����������,̸��ʲôѧϰ�㷨���á� �������� (��־��),Ҳ����˵û���κ�һ��ģ�Ϳ��������е�ѧϰ�����������á�
-
�������: �¿�ķ�굶ԭ��,�������ģ���ܹ�ͬ�ȳ̶ȵط���һ������Ĺ۲���,Ӧ��ѡ������ʹ�ü������ٵ�,Ҳ�������ģ�͡�
-
Ƿ���:ѵ������һ��������δ��ѧϰ��ѧ��,(ѵ������)��
�������:���ģ���Ӷ�
�� ������:��չ��֧
�� ������:����ѵ������ -
�����:ѧϰ����ѵ�����ص㵱��������,һ���ص�. (ѵ�����С,��������)��
�������:����ģ���Ӷ�
�� �Ż�Ŀ���������
�� ������:��֦
�� ������:early stop��dropout
�� ��������(ѵ����Խ��,Խ���������)��������Ӿ�:ͼ����ת�����š�����;��Ȼ���Դ���:ͬ����滻;����ʶ��:�������������
(��)��ʧ����
- ƽ����ʧ����(�ع�)��
L ( y , y ^ ) = ( y ? f ( x , �� ) ) 2 L(y,\hat y)=(y-f(x,\theta))^2 L(y,y^?)=(y?f(x,��))2 - ƽ������ֵ��ʧ-L1��ʧ(�ع�)
M A E = �� r = 1 n �O y i ? y i p �O MAE=\sum_{r=1}^n|y_i-y_i^p| MAE=r=1��n?�Oyi??yip?�O
- ������-������ʧ����(����)��
H ( p , q ) = ? �� r = 1 n p ( x i ) l o g ( q ( x i ) ) H(p,q)=-\sum_{r=1}^np(x_i)log(q(x_i)) H(p,q)=?r=1��n?p(xi?)log(q(xi?)) - 0-1��ʧ����(����)��
L ( Y , f ( X ) ) = { 0 , Y?=?f(X) 1 , Y? �� ?f(X) L(Y,f(X)) = \begin{cases} 0, & \text{Y = f(X)} \\ 1, & \text{Y $\neq$ f(X)} \end{cases} L(Y,f(X))={0,1,?Y?=?f(X)Y?��?=?f(X)? - hinge loss(����)
L ( y , f ( x ) ) = m a x ( 0 , 1 ? y f ( x ) ) L(y,f(x))=max(0,1-yf(x)) L(y,f(x))=max(0,1?yf(x))
����Ƶ��ѧ�� & ��Ҷ˹ѧ��

