ФПТМ
вЛЁЂаДдкЧАУц
1:БОЮФжївЊЬжТлИъЕЧдіГЄФЃаЭЕФгХЛЏМАЯжЪЕвтвх;СэЭт,БОЮФЪЙгУpythonЪЕЯжФЃаЭВЂвдФГжЄШЏЮЊР§НјааЙРжЕ
2:БОЮФжївЊааЧщЪ§ОнЭЈЙ§Tushare(ID:444829)Н№ШкДѓЪ§ОнЦНЬЈНгПкЛёШЁ, ВПЗжВЦЮёжИБъ,РћТЪжИБъЭЈЙ§ХРГцЛёШЁ
3:БЪепЯЃЭћДюНЈГівЛЬзНЛвзЬхЯЕ,ддђЪЧжЛзіИЩЛѕЕФЗжЯэЁЃКѓајНЋИќаТИќЖрФЃПщ,ЕЋЙЄзїбЇЯАжЎгрЕФЯаЯОЪБМфгаЯо,ИќаТЫйЖШТ§ЛЙЧыСТНт
4:ЮФжаМйЩшгыЙлЕуЪЧЛљгкБЪепЖдФЃаЭМАЪ§ОнЕФвЛПзжЎМћ,ШєгаВЛЭЌМћНтЛЖгЫцЪБСєбдНЛСї
5:ФЃаЭЪЕЯжЛљгкpython3.8
ЖўЁЂдЕЦ№
? ? ? ? ЯШРДЖЮПЊГЁАз,БЪепШЯЮЊвЛаЉРэФюадЕФЖЋЮїМлжЕдЖГЌЙ§ДњТыКЭФЃаЭБОЩэ,ВЛЙ§ЖдГЄЦЊДѓТлВЛИааЫШЄЕФаЁЛяАщУЧПЩвджБНгЬјЙ§,ДгЕкШ§ВПЗжПЊЪМПД~
????????ИъЕЧдіГЄФЃаЭ(Gordon Growth Model, GGM) БЪепГЃЯЗГЦжЎЮЊИчИчУЧЁЃ?ИъЕЧдіГЄФЃаЭЦфЪЕЪЧЙЩЯЂЬљЯжФЃаЭ(DDM)ЕФвЛжжгХЛЏ,ЭЈЙ§МЦЫуЙЋЫОдЄЦкЮДРДжЇИЖИјЙЩЖЋЕФЙЩРћЯжжЕ,РДШЗЖЈЙЩЦБЕФФкдкМлжЕ,МДЪЧЙЩРћгРајСїШыЁЃGGMдкЩЯЪРМЭЮхЪЎФъДњБЛJohn Burr WilliamsЗЂВМГіРД,ЖјЫќЕФЕмЕмЁЊЁЊDDMдђдчдкЩЯЪРМЭШ§ЪЎФъЖШБЛЬсГіЁЃЪТЪЕЩЯ,ФЧИіЪБДњЖдЙЩЦБЕФРэФюБуЪЧТђШыВЂГжгавдзЌШЁЗжКьЁЃЯжШчНёНќАйФъЙ§ШЅ,етбљЕФРэФюдчБЛМБВЛПЩФЭЕФ"ааЮЊН№ШкбЇДѓЪІУЧ"ХзЦњ;гШЦфдкAЙЩ,ЪаГЁЩЯЕФЭЖзЪепЖрЮЊТђШыВЂГжгавдзЌШЁВюМлЁЃ
????????АЭЗЦЬиЫЕЙ§:ЁАШчЙћУЛгаГжгавЛжЇЙЩЦБЪЎФъЕФДђЫуОЭВЛвЊТђШыЁБЁЃРЯШЫМвЕФЕзЦјЦфЪЕПЩвдгУетбљЕФЙЋЪННтЪЭ:еОдкНёЬьПДЮДРДПЩвдЛёЕУЕФКУДІ,ШчЙћГЌЙ§НёЬьЫљИЖГіЕФЖдМлФЧБузЌСЫЁЃ

? ? ? ? дкБЪепблжаетЪЧБШбІЖЈкЬЕФУЈЛЙвЊИпЮЌЖШЕФДцдкЁЊЁЊетИіКазгРяУїЬьгаУЛгаУЈЁЃзїЮЊвЛИіЮЈЮяжївхЮоЩёТлеп,ЮвЩѕжСУЛгаФмСІжЊЕРЯждкКазгРяЪЧЗёгаУЈ,ИќхиТлЮДРДЙЩМлЪЧЖрЩй? ЪТЪЕЪЧаЁЕНаЁЩЂУЧЕФХжРвЛЪжЕФНЛвз,ДѓЕНЗжЮіЪІБЈИцРяЕФжНЩЯЬИБј(? Тђ!),жЛвЊВЛЪЧгаФмСІЛKЯпЕФЕФжїСІ,ЛђЪЧФкФЛЕФжЊ(lao)Чщ(shu)ШЫ(cang),ЮвУЧЖМдкЦДУќЕФв§ШыЮДРДКЏЪ§ЁЃ
????????ЪВУД?АЭЗЦЬи?ЫћРЯШЫМввВв§ШыСЫ,ВЛШЛ20ФъвпЧщГЕзКНПеЙЩвЛГГдкАыЩНбќ?
?
????????(БОЮФжЛТлЛљБОУц,РЯВјЪІЧыВЛвЊгыЮвТлЕР)З№Эггабд:ЁАвЛЧагаЮЊЗЈ,НдД§дЕЖјЦ№ЁБЁЃЪРМфЕФНсЙћЖМЪЧвђИїжжвђдЕЖјГЩ,МДЮЊдЕЦ№ЁЃЙЩМлКЭЙЩРћврЪЧШчДЫ,БЪепШЯЮЊДѓПЩВЛБиЪгЮДРДКЏЪ§ШчКщЫЎУЭЪо,ЕЋЦфаХКХЦЏвЦЪЧвЛЖЈашвЊПМТЧЕФ,ЮвУЧЫљФмзіЕФОЭЪЧМгЩЯЯоЖЈЬѕМў,Р§ШчИјЮввЛжЛАыЭИУїЕФКазгЛђЪЧвЛИЫГг,ФЧУДПЩвдЭЈЙ§ЙлВьКазгЛђЪЧГЦжиСПМфНгжЊЕРКазгРяЪЧВЛЪЧгаУЈЁЃ
? ? ? ? ?ЪТЪЕЧщПіШДдЖБШбІЖЈкЬЕФУЈРДЕУИДдг:ЪзЯШЫќеОдкПеМфЮЌЖШ(НёЬьЛсВЛЛсгаУЈ);ЖдвЛИіЦѓвЕРДЫЕ,ФПЧАЫљДІаавЕ,ВЦЮёЫЎЦН,ЙмРэВужЪСПЕШЕШХаЖЯЦѓвЕ(Казг)ЛсВЛЛсДѓИХТЪВњЩњГжајЕФРћШѓ(УЈ)ЁЃЦфДЮЪЧеОдкЪБМфЮЌЖШ(УїЬьЛсВЛЛсгаУЈ)ЕМжТИїжжаХКХВњЩњЕФЦЏвЦ,етЪЧЭДЕуЫљдк,ЙЩРћЪЧЗёФмгРајСїШы?ЦѓвЕФмЗёвдФПЧАзДПігРајОгЊ?ЭтВПКкЬьЖьЪТМў,ЭтВПГхЛїet al. ЭђЪТНдПЩЮНЁАдЕЦ№ЁБ ЁЃ
? ? ? ? ЕкЖўжжЧщПіНЯЮЊИДдг,ГігкФкШнЙцЛЎПМТЧ,БЪепЯыдкКѓајФЃПщжабАЧѓИќКУЕФНтЗЈЁЃ
? ? ? ? ЕквЛжжЧщПіНЯЮЊМђЕЅ,ЕЋгЩгкN-holding period ЬЋЙ§ПСПЬ,ЖдШЈвцЙЄОпРДЫЕФбвдЪЕЯжЁЃБОЮФОЭДгЯрЖдЯжЪЕвЛаЉЕФGGMЧаШыЁЃ
Ш§ЁЂУшЛцвЛИіЯжЪЕжаЕФРэЯыЪРНч
? ? ? ? ЯШЮЊаТЪРНчЕМШыБивЊЕФФЃПщ
import pandas as pd
import tushare as ts
from sklearn.linear_model import LinearRegression
import matplotlib.pyplot as plt
import seaborn as sns? ? ? ??
? ? ? ? ЮЊСЫЧѓГіЙЩМлБиаыЯШЧѓГі:
? ? ? ? ЮЊБЃжЄФЃаЭгааЇад,НЈвщВЩгУ10ФъЕФЪ§Он,5ФъвВПЩЁЃНгЯТРДвдФГЪаГЁжИЪ§, МАФГжЄШЏзд2011Фъ1дТ1ШеЦ№,жС2021Фъ9дТ7ШеЫљгаНЛвзШеЪ§ОнЮЊР§НјаабнЪО(ЮЊБмУтМіЙЩЯгвЩОЭВЛеЙЪООпЬхДњТыСЫ,ЯТУцЯрЙиаХЯЂвВЖМЛсвўШЅ)ЁЃвдЯТНсЙћОљЪЧЭЈЙ§row dataМЦЫуЕУЕН,здМКМЦЫуИїжжжИБъЕФзюДѓЕФКУДІОЭЪЧНЋвЛЧаЮЪЬтПЩПи,ЧвПЩвдНјааКмЧПЕФИіадЛЏДІРэЁЃ
1:дЄЦкЪевцТЪr
? ? ? ? r ЕФЧѓЗЈгаКмЖр,етРяЭЈЙ§CAPMЪЕЯж,МД
?
? ? ? ? ЯШРДИіПЩАЎЕФУдФуХРГцЛёШЁзюаТЕФЙњеЎРћТЪзіЮЊЮоЗчЯеЪевцТЪrf,ШчЙћЯгТщЗГвВПЩвдзіКУФЃаЭжБНгЕМШыОпЬхЪ§жЕЁЃtableДцЕФЪЧЙњеЎЪевцТЪБэ,Ш§ФъЕНЪЎФъЖМга,етРяШЁШ§ИідТЖЬЦкЙњеЎЪевцТЪзіЮЊЮоЗчЯеЪевцТЪ,МДtable.loc[1,2]ЁЃ
def risk_free(Date): ## Date: year-month-day
url = "https://yield.chinabond.com.cn/cbweb-cbrc-web/cbrc/historyQuery?startDate=" +
Date+ "&endDate=" + Date+ "&gjqx=0&qxId=ycqx&locale=cn_ZH&mark=1 "
content = pd.read_html(url)
table = content[1]
print('Risk_free rate(Short term (3 month) T-Bill):', table.loc[1, 2], "%")
return table.loc[1, 2]? ? ? ? НгзХЪЧЪаГЁЛиБЈМАУєИаЯЕЪ§beta?
????????етРяв§ШывЛПюЗЧГЃЗНБуЕФЪ§ОнЛёШЁФЃПщtushare,ЭЈЙ§МђНрЕФЪ§ОнНгПкПЩвдЛёШЁИїРрН№ШкЪ§Он,ЪЁШЅДѓАбаДХРГцЕФЪБМфЁЃЭЈЙ§етИіСДНгTushareДѓЪ§ОнЩчЧјзЂВсГЩЙІКѓМДПЩЭЈЙ§здМКЕФtokenБуНнЕїгУЪ§Он,ОпЬхПЩВЮПМTushareЕФММЪѕЮФЕЕЁЃ
? ? ? ? жЛашвЊЖдpro.dailyДЋШыжЄШЏДњТыМАЦ№жЙШеЦкМДПЩЛёШЁЫљгаШеЯпМЖБ№Ъ§Он,ВЂШчЗЈХкжЦЛёШЁЪаГЁжИЪ§Ъ§ОнЁЃ
def date_input(token, cp, mk, start, end):
pro = ts.pro_api(token)
cp = pro.daily(ts_code=cp, start_date=start, end_date=end) #companyЪ§Он
mk = pro.index_daily(ts_code=mk, start_date=start, end_date=end) #marketЪ§Он
beta = beta_value(cp, mk) # МЦЫуbeat
Mr = mean_value(mk) # МЦЫуЪаГЁЛиБЈТЪ? ? ? ? ЪЙгУsklearnЖдШеЛиБЈНјааФтКЯ,етРяЖдУЛгаЪ§ОнЕФЭЃХЦНЛвзШеНјааЬоГ§вдБЃжЄжИЪ§гыИіЙЩЪ§ОнЪЧГЩЖдГіЯжЁЃ
def beta_value(cp, mk):
for i in mk['trade_date'].values:
if i not in cp['trade_date'].values:
# Match the market data-set with securities, some securities may halt
mk = mk[~mk['trade_date'].isin([i])] # ЬоГ§ИіЙЩЭЃХЦШе
return_cp = cp ["pct_chg"]
return_mk = mk ["pct_chg"]
return_cp = return_cp.reshape(-1, 1)
return_cp = return_cp[::-1]
return_mk = return_mk.reshape(-1, 1)
return_mk = return_mk[::-1]
Mod = LinearRegression()
Mod.fit(return_mk, return_cp) # ВЩгУЯпадЛиЙщЖдЪаГЁМАИіЙЩЪ§ОнНјааФтКЯ
beta = Mod.coef_[0][0] # МЦЫуГіЯрЙиЯЕЪ§,МДІТ
print("Beta is", beta)
# print("R_squareЪЧ", Model.score(return_mk, return_cp))
return beta????????МЦЫуЕУИУжЄШЏ
????????МШШЛЕУЕНСЫЪЎЖрФъЕФЪ§Он,ЪжбїЫГБуПДЯТжааФЧїЪЦМАЗжВМзДПіЪЧЪВУДбљЕФ
def dis_function(cp, mk):
m, s = pd.Series(mk["pct_chg"]), pd.Series(cp["pct_chg"])
print("market mean:",mk["pct_chg"].mean(),"market median:",mk["pct_chg"].median())
print("security mean", cp["pct_chg"].mean(), "security median:",cp["pct_chg"].median())
print("market skewness:",m.skew(),"market kurtosis:",m.kurt())
print("security skewness:",s.skew(),"security kurtosis:",s.kurt())
dataset = pd.DataFrame({"market": mk["pct_chg"].values, "security":
cp["pct_chg"].values})
sns.jointplot(x= "security", y = "market", data = dataset, kind = "reg")
plt.show()????????ПЩЕУ:?


? ? ? ? НќЫЦЪЧИіе§ЬЌ,ЙигкЗжВМБЪепЛсдкКѓајЕФЮФеТжагУЕН,етРяНізїеЙЪОЁЃ
????????НгзХАбжИЪ§ЕФШееЧЕјЗљОљжЕМЦЫуГіРДВЂФъЛЏДІРэ:
def mean_value(mk):
mean = mk['pct_chg'].mean()
mean_yield = ((1 + mean / 100) ** 365 - 1) * 100
print("Average return of the Market(Suggest 10 years):", mean_yield, "%")
return mean_yieldМЦЫуЕУ
????????жСДЫ,ЮвУЧБуЕУЕНСЫЫљгаМЦЫуЛиБЈТЪ r ЕФвЊМў,ЕїгУжЎЧАЕФФЃПщВЂМЦЫуrЮЊ:
rf = float(risk_free()) # Calculate risk free rate
beta_Mr = data_input(company, market, start, end)
beta = beta_Mr[0] # Beat value
Mr = beta_Mr[1]
expt_r = rf + beta * (Mr - rf)МЦЫуПЩЕУE(r): 5.1745 %
2:ЯТвЛЦкЙЩРћгыдіГЄТЪg
????????ЕквЛИіУджЎаХбіРДСЫ:ЯждкУЛгаЗжКь,ШчКЮжЊЕРЯТвЛЦкЙЩРћ?НсКЯдіГЄТЪgРДПДДѓИХгаМИжжНтЗЈ:
????????1):ЙЋЪНЗЈ
? ? ? ? ЭЈЙ§ROE*(1-Payout Ratio)ЧѓГідіГЄТЪg,етИідіГЄТЪМДЪЧМйЩшЙЋЫОЕФРћШѓТЪВЛБф,гЏРћаЇТЪВЛБф,ВЦЮёеўВпВЛБфЕФЧщПіЯТ,ПЩвдЪЕЯжЕФдіГЄТЪЁЃгкЪЧдйЪЙгУЕБЦкЙЩРћГЫвдетИідіГЄТЪвдМЦЫуГіЯТвЛЦкЙЩРћ?ЁЃ
? ? ? ? 2):РњЪЗЪ§ОнЗЈ
? ? ? ? ЭЈЙ§Й§ШЅЭЦЮДРД,МЦЫуЙ§ШЅвЛЖЮЪБМфФкЕФЙЩРћФъЛЏдіГЄТЪ,дйгУЕБЦкЙЩРћГЫвдетИідіГЄТЪвдМЦЫуГіЯТЦкЙЩРћ
? ? ? ? 3):ПфЯТКЃПкЗЈ
? ? ? ? гЩвдЩЯСНжжЗНЪНМЦЫуГіgЁЃИљОнЗжЮіЪІСщ(pou)Ує(gai)ЕФжАвЕХаЖЯЖдМЦЫуЕФgНјааЕїећВЂЯђЭЖзЪепПфЯТКЃПкЁЃ
? ? ? ? ШчЙћНсКЯФкФЛЯћЯЂЛђЪЧзВДѓдЫе§КУВТжа,ЮвУЧПЩвдЕУЕНЕкЫФжжНтЗЈ:
? ? ? ? 4):ЪВУДЖМВЛИЩ,жБНгАбвбжЊЕФЯТвЛЦкЙЩРћЗХШыЙЋЪНЁЃ
????????ПЩвдПДЕНвдЩЯШ§жжЗНЪНЖМгУЕНСЫдіГЄТЪgЕФИХФю,КѓУцЛсдйЖдgНјааЬжТл,НгЯТРДЯШвдЙЋЪНЗЈЮЊР§НјааМЦЫуЁЃ
????????ЪзЯШРДИіОЋжТЕФХРГцДгаТРЫЩЯЛёШЁРњЪЗЙЩРћаХЯЂ:
def craw_dividend(company): #start, end,
url = "http://vip.stock.finance.sina.com.cn/corp/go.php/vISSUE_ShareBonus/stockid/" \
+ str(company.split(".")[0]) + ".phtml"
table = pd.read_html(url, attrs={"id": "sharebonus_1"}, header=[2])
div_inform = pd.DataFrame(table[0][::-1])? ? ? ? printГіБэИёвЛПД,ЪВЁЃЁЃЪВУД!вЛФъОЙШЛЗжКУМИДЮКьЙЋЫОКЭВЛЗжКьЕФЬњЙЋМІ?ДІРэвЛЯТБэИё,ВЛЗжКьЮЊ0,ЗжКьЖрДЮЕФЧѓЦфКЯМЦЪ§зіЮЊИУФъЙЩРћЁЃ
# НгЩЯвЛИіДњТыПщ
year = []
div = []
div_hist = div_inform["ХЩЯЂ(ЫАЧА)(дЊ)"]
for i in div_inform["ЙЋИцШеЦк"]:
row = div_inform[(div_inform["ЙЋИцШеЦк"] == i)].index.tolist()
div.append(float(div_hist[row].values))
year.append(i.split("-")[0])
dataset = {"year": year, "dividend": div}
div_table = pd.DataFrame(data=dataset) # жЛАќКЌЗжКьаХЯЂКЭФъЗнЕФБэИё
rows_list = []
for i in div_table["year"]:
index = div_table[(div_table["year"] == i)].index.tolist()
rows_list.append(div_table[(div_table["year"] == i)].index.tolist()) if index not in
rows_list else next
for rows in rows_list:
if len(rows) == 1:
continue
else:
total_div = 0
for row in range(1, len(rows)):
total_div = total_div + div_table["dividend"][rows[row]]
div_table.drop(rows[row], inplace=True)
div_table.loc[rows[0], "dividend"] = total_div + div_table["dividend"][rows[0]]
div_table.reset_index(drop=None, inplace=True)
print(div_table)
return div_table, div_inform ## divd_inform has all div. information,div_table only hasЁОyearЁПand ЁОdivЁП? ? ? ? етРяСєСЫИіПкзгАбdiv_inform вВШЁСЫГіРД,ЗНБувдКѓаДГЬађПЩвджБНгЕїгУЁЃ
? ? ? ? ЕУЕНdiv_tableШчЯТ:
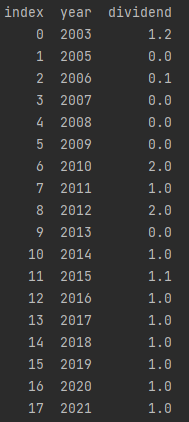
?????????ИааЫШЄЕФаЁЛяАщПЩвдЭЈЙ§РњЪЗЪ§ОнЗЈМЦЫуЭЦГіЯТвЛЦкЙЩРћ,етРяВЩгУЙЋЪНЗЈжЛШЁГіЕБЦкЙЩРћЁЃ
3:гРајдіГЄТЪg
????????ЭЈЙ§ROE*(1-Payout Ratio)ЧѓГідіГЄТЪg
? ? ? ? МЬајвЛИіДРУШЕФУдФуХРГцЛёШЁROE
def craw_roe(company):
url
="http://money.finance.sina.com.cn/corp/go.php/vFD_FinancialGuideLine/stockid/"+str(company.split(".")[0])+"/ctrl/2019/displaytype/4.phtml"
ratio = pd.read_html(url, attrs={"id":"BalanceSheetNewTable0"})
return ratio? ? ? ? НгзХЭЈЙ§TushareНгПкЛёШЁЯрЙиВЦЮёжИБъвдМЦЫуg:
def tus_growth(ts_code,period):
global growth
period_beg = str(int(period) -1) +"1231"
period = period+"1231"
ratio_end = pro.query('fina_indicator', ts_code=ts_code , period=period)
gl_table= pro.income(ts_code=ts_code, period=period, fields='ts_code,n_income', report_type=1)
ratio_beg = pro.query('fina_indicator', ts_code=ts_code , period=period_beg)
roe = float(ratio_end["roe"][0]) # ROE
re_beg =float(ratio_beg["retained_earnings"][0]) # Retain earning at the beg of period
re_end= float(ratio_end["retained_earnings"][0]) # Retain earning at the end of period
n_income = float(gl_table["n_income"][0]) # Net income
growth = roe *(1-(re_end-re_beg)/ n_income)
print("Growth rate of",ts_code,"is",growth,"%","with ROE:",roe, " net income:",n_income," at the period "
"end of", str(period)[:4])
return growth?МЦЫуЕУ:
????????НсКЯжЎЧАЙЩРћРњЪЗзДПі,1.3%ЕФдіЫйвВПЩвдРэНтЁЃЁЃПЩвдЪгЮЊМИКѕУЛгадіЫйЁЃОЛРћШѓКЭКѓУцЕФШеЦкетаЉаХЯЂОЭВЛеЙЪОСЫЁЃ
? ? ? ? НгЯТРД,ЭђЪТОпБИжЛЧЗЖЋЗч!
?4:ФкдкМлжЕМЦЫу
? ? ? ? ?ЕїгУжЎЧАЕФФЃПщ,ДЋШыЪаГЁДњТы,жЄШЏДњТы,Ц№жЙШеЦк,ЙЩРћМЦЫуШеЦк,ДѓЙІИцГЩ!
if __name__ == '__main__':
market = input('Market Code') # 000001.SH
company = input('Security Code') # 600522.SH
start = input('Start Date(Dealing Day)')
end = input('End Date(Dealing Day)')
#Clac risk free , beta & E(r)
rf = float(risk_free()) # Calculate risk free rate
beta_Mr = data_input(company, market, start, end)
beta = beta_Mr[0] # Beat value
Mr = beta_Mr[1]
expt_r = rf + beta * (Mr - rf)
print("Output", company, "E(r):", expt_r, "%")
# calc dividend at beginning
div_table = craw_dividend(company)[0]
div_date = input("Input a complete financial period (year) for dividend")
div_date = str(div_date[:4])
row = div_table[(div_table["year"] == div_date)].index.tolist()
div_value = div_table.iloc[int(row[0])]["dividend"]
print("The dividend for {0}".format(div_date),"is:", div_value)
# calc g
div_date= int(div_date)-1 ## still need adjustment
tus_growth(company, str(div_date))
# Formular(Golden growth model)
price = div_value*(1+(growth/100)) / ((expt_r - (growth))/100)
print("The intrinsic value of", company,"is", price)? ? ? ЫФЁЂФЃаЭНсЙћ? ? ? ??
????????ИУжЄШЏФЃаЭНсЙћЮЊ:
????????БЪепЖдИУНсЙћЦФЮЊТњвт,БЪепРћгУЯрЖдЙРжЕЗЈМЦЫувВгазХЯрЫЦЕФМлжЕЁЃВЛЙмФЃаЭЪЧВЛЪЧеце§ЙРМЦЕНСЫетжЛУїЬьКазгРябІЖЈкЬЕФУЈ,дкБЪепаФРявбОГЩЙІСЫЁЃ
ЮхЁЂаДдкКѓУц
? ? ? ? ГЬађПЩвдИіадЛЏВщПД,ЕЋвВПЩвдХњСПХм,АбInputЕФаХЯЂБфГЩСаБэБуРћМДПЩАбДѓAЫФЧЇМвЙЋЫОЭГЭГпЃвЛБщЁЃ
? ? ? ? ЙигкРэЯыЙњ:БЪепЫљгУЙЋЫОЪЧОЙ§ЬєбЁЕФ,ЛЛОфЛАЫЕжЛгаЗћКЯЬѕМўЕФЙЋЫОВХФмгыЮвЕФЪРНчЦѕКЯЁЃетЛљгквдЯТМИЕуЬѕМўЛђМйЩш:
????????1):ИУЙЋЫОдіГЄТЪМЋЕЭ,вђДЫЙЩРћелЯжЪБgЕФЭўСІЖдФЃаЭУЛгаЪВУДгАЯь;ЕЋЖдгквЛаЉИпЗжКь,ИпROEЕФЙЋЫОРДЫЕ,ИУФЃаЭЛђУцСйЪЇаЇ;2):ФЃаЭНсЙћЪЧИУЙЋЫОдкБЪепблжаЕФМлжЕ,ИУЙЋЫООгЊЛљБОУцЮШЖЈ,ЧвЮДРДГЄЦкгРајОгЊ,БЪепвВНјааГЄЦкЭЖзЪ;3):етМвЙЋЫОгазуЙЛЖрЕФЪ§Он(жСЩйНќЪЎФъ)ЙЉМЦЫу,ЖдгквЛаЉЩЯЪаЪБМфНЯЖЬЕФЙЋЫО,ФЃаЭгааЇадЛђНЋДѓДђелПл;
? ? ? ? ЮвЕФЪРНчвВВЂЗЧвЊвЛГЩВЛБфЕФЁЃЯжЪЕЧщПіЪЧаэЖрЙЋЫОЗжКьЖМЪЧВЛЮШЖЈЛђГЪЯжжмЦкадВЈЖЏ,етбљПЩвдНЋЙ§ШЅМИФъЕФЙЩРћОљжЕЪгЮЊНјааМЦЫуЁЃдіГЄТЪgвВВЂЗЧгРајЧвЙЬЖЈ,ЖрНзЖЮелЯж,ВЩгУИќБЃЪиЕФЗНЪНелЯжЖМПЩвдЙРМЦГівЛИіЧјМф,етИіЧјМфЯТЯоНЋЪЧБЃЪижЕ,ЩЯЯпНЋЪЧдЄОЏжЕЁЃ
? ? ? ? зюКѓ,БЪепШЯЮЊОіЖЈвЛИіЙЋЫОЙЩМлИпЖШЕФЪЧЪажЕЖјВЂЗЧЦфФкдкМлжЕ,ФкдкМлжЕжЛФмОіЖЈвЛИіОљжЕЛиЙщЪБЕФжаЪр,вдФкдкМлжЕНјааНЛвзЪЧВЛвЛЖЈЛЎЫуЕФЁЃ?