������Ŀ: AKUPM: Attention-Enhanced Knowledge-Aware User Preference Model for Recommendation
���Ĵ���:
��������:
�뷨
- ʲô�����䵽��ϵ�ռ�? (������һ����ϵ����,���ǹ�ϵ����ΪɶҪ��?)
- ʲô��������Ӧ?
- ���� h v u , m 0 h_{v_{u,m}}^0 hvu,m?0?��ʾ��item v u , m v_{u,m} vu,m?���ӵ�ʵ�������Ϊ0,���ʾ����ʷ�������ʼitems
����
- ʵ����û�; ��ô������Ҫ�Ե�?
- ʵ�屾��;��ô���ǹ�ϵ����ʵ�屾��������?
ժҪ
�ѵ�:
KG������ȷʵһ���̶ȸı�����������ϡ������,����Ҳ�����������ص�ʵ������ʾuser��Ƕ�롣 �ܶ����IJ�û����ʶ�������⡣
����:
̽����Щʵ��֮��Ľ���!�Ӷ����ݽ�������Դ��������������
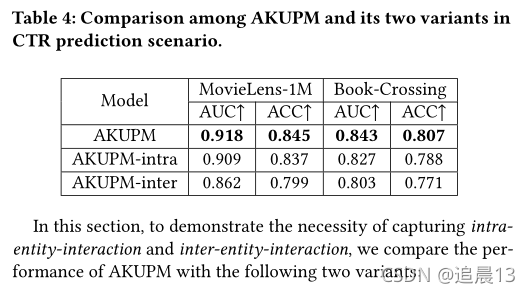
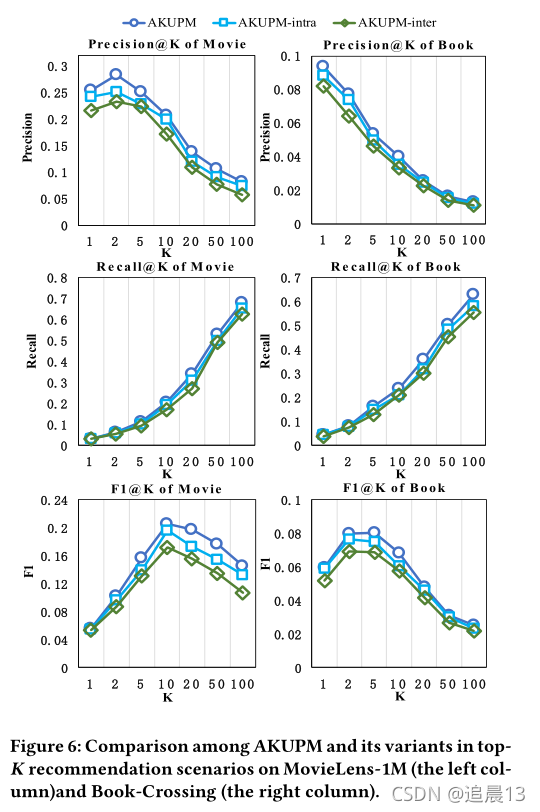
����: ���ǽ�ʵ��֮��Ľ�����Ϊ������:inter-entity-interaction��intra-entity-interaction�� Inter-entity-interaction��ʵ��֮��Ľ���,��Ӱ��ʵ������û�����Ҫ��; intra-entity-interaction���漰����ͬ�Ĺ�ϵʱ,һ��ʵ��ͻ��в�ͬ�������� (��������е����,���Կ�Introduction�еľ���)
���������ֽ���,���������AKUPMģ�������е����(CTR)Ԥ��,�����˵, Inter-entity-interaction,��ע��������ᱻ����ͨ��ѧϰÿ��ʵ�����û�֮���ʵ�����Ҫ��������ʵ���Ľ���; ����,intra-entity-interactionͨ����ÿ��ʵ��ӳ�䵽�����ӵĹ�ϵ�ռ����������ʵ�������,�Ӷ���ʵ���ڲ�������ý��н�ģ��
����ָ��: AUC��ACC��Recall@top-K
1. Introduction
ǰ�˵�ȱ��:
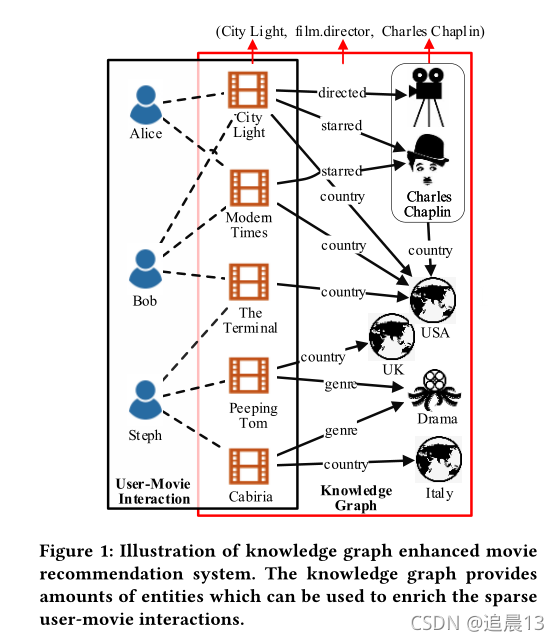
DKN(CNN)��RippleNet������KG���ḻ��RS��users/items�ı�ʾ��Ȼ��,ͼ�а�����ʵ�屾����items/users֮��Ĺ�ϵ��û�б��о�,����Ƽ�������ܻ��ܵ�һЩ����صĺϲ�ʵ���Ӱ�졣
�Ե�Ӱ�Ƽ�Ϊ��,ÿ���û�����KG����֮������ʵ�����,������֮��Ľ������Դ������涨��:
1)Inter-entity-interaction: (�������DZ��ʵ����û���Ӱ��)����ʵ��֮��������,һ��ʵ������ڲ�ͬ��ʵ�弯��ʱ,����Ҫ�Ի��кܴ�IJ��졣���������ͼ��,����Bob��˵,���ĵ�Ӱ����������USA,������Steph����,���Ը�������,��ôUSAʵ���Bob��Ӱ��Ҫ����Steph��
2)Intra-entity-interaction:(���������Լ�,�Լ��Բ�ͬ��Ӱ��ϲ��)�����ض����û�,ʵ�����漰��ͬ�Ĺ�ϵʱ���ܻ���ֳ���ͬ��������������ͼ��,Aliceϲ��City Lights ��ΪCharles Chaplin�Ǹõ�Ӱ�ĵ���,��ô������ϲ��Modern Time,��ΪCharles Chaplin�Ǹò������ݡ�
����ģ�ͼܹ���: ����user-item pair,AKUPM��Ŀ�ľ���Ԥ��CTR(�����)�� ���ȳ�ʼ��: һ���û��ı�ʾ���ᱻ���û��������items���ḻ�� ����Щ�������items���ᱻ��ʼ��,Ȼ������KG�ӽ���Զ�Ĵ����� ����,�Ϳ��Գ�ʼ��user��������items�� ����ٽ���inter\intra-entity interaction! ���ǵĹ�����Ҫ���ܽ�����:
(1)�����ո�µĻ�������Ӧ��ע����ģ��,ͬʱ�ǵ�һ�ν��û��ͱ�������ʵ��Ľ�����Ϊ���ֵ�;
(2)ͨ����ʵ��ӳ�䵽��ϵ�ռ�������Լල����,intra��inter���ᱻ������ ����AKUPM�ܹ��ҵ���ÿ���û�������ʵ������صġ�
2 RELATED WORK
2.1 Knowledge Graph Embedding
���п���������! TransE��R�ȵ�! ����ʹ��TransR
2.2 Attention Mechanism
�ڱ�����,�������ʹ��ע�������̽������item�뱻����ʵ��֮��Ĺ�ϵ������,������ע�����,ͨ����ÿ��ʵ������ʵ���Ȩ��,�ڹ���ʵ�弯�������ɱ�����ʵ��ı�ʾ
2.3 Knowledge-Aware Recommendation
Ҳ����ȥ������! �����˷ֿ���,����·����,�������ַ�����!
3 PRELIMINARIES
�����Ķ���,user���ϡ�item������������; ֪ʶͼ��G����Ԫ�顢����������ʵ���֪ʶͼ����ʵ��Ķ�Ӧ��
���յ�Ŀ�����CTR:

4 ����ķ���
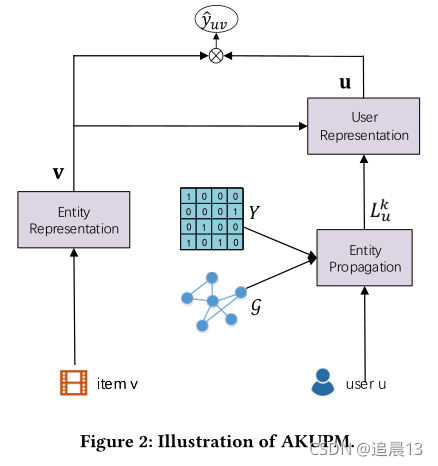
��ͼ��ʾ��AKUPM��������,����һ���û�����,Ϊ�˰�����һ��KG�а���������صķḻ��ʵ��Ӷ�̽��������Ȥ,һ�������û������ʷ��������Ƶ�ʵ�崫��(4.1)���ᱻ���ڰ��������ʵ�塣 ������Ϊ��������Щ��������ʵ��֮���intra-entity-interactions,���ǽ��齫ʵ��Ƕ�뵽��ϵ�ռ���(4.2)�� Ϊ�˶�inter-entity-interactions���н�ģ(4.3),����Ӧ��һ����ע�����������ÿһ��ʵ��ı�ʾ������ʵ��ı�ʾ��������,,�������Ӧ��һ��ע��������������item����ʾuser,ͨ���ۺϾ����ʵ�Ȩ�ص�ʵ���ʾ�����,���������û����������DZ�ڱ�ʾ����CTRԤ�⡣
4.1ʵ�崫��
ʵ�崫����˵�������л�ɫԲȦ��ʾ�ϲ�ʵ�塣��ͬ������ʵ�����ڲ�ͬ�Ķ�Ӧʵ�弯��

�������е�ʵ�嶼���û�����,����Ϊ�˹�����Щ����,���ǽ����ϲ����û������ʷ����֪ʶͼ�Ĺ�ϵ������ʵ��,����ÿ���ϲ���ʵ�嶼���û���ء�

ԭʼ��ʵ�崫���Ķ���Ϊ:
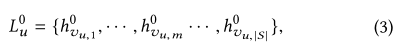
����
h
v
u
,
m
0
h_{v_{u,m}}^0
hvu,m?0?��ʾ��item
v
u
,
m
v_{u,m}
vu,m?���ӵ�ʵ�������Ϊ0,���ʾ����ʷ�������ʼitems�� Ȼ��
L
0
L^0
L0�е�ʵ���������relation�������Ĵ���,�������Դﵽ������ϵ��ʵ�塣 Ȼ�����Ƕ���ʵ���
k
t
h
k^{th}
kth��������:
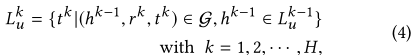
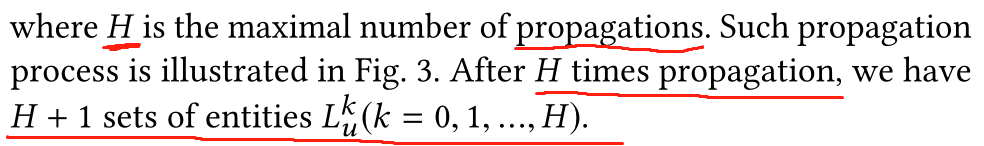
4.2 Entity Representation(intra-entity-interactions)
��������Ӧ��TransR��ʼ��ʵ�塣����ÿ����Ԫ�� ( h , r , t ) �� G (h,r,t)\in \mathcal{G} (h,r,t)��G�е�h��r��t������ʼ��Ϊdά�������� ����ÿ����ϵr,��������һ��ͶӰ���� R �� R d �� d \mathrm {R}\in \mathbb{R}^{d \times d} R��Rd��d,����ʵ����ʵ��ռ�ӳ�䵽��Ӧ�Ĺ�ϵ�ռ�(��һ��Ҫѧϰ�ľ���,��һ������),������ʾ:

���潫ͷ��β��ת��Ϊ��ϵ�ռ䡣
�����ڳ�ʼ��items(�û������items),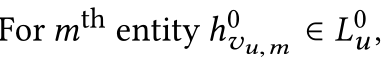 ,��û�й�ϵ��Ƕ���(������Ǵ���Ĺ�ϵ,�����Ǵ����Ĺ�ϵ)�� �������ʵ��ֻ����������Ƕ��:
,��û�й�ϵ��Ƕ���(������Ǵ���Ĺ�ϵ,�����Ǵ����Ĺ�ϵ)�� �������ʵ��ֻ����������Ƕ��:

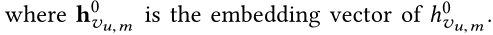
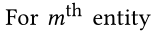
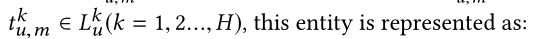

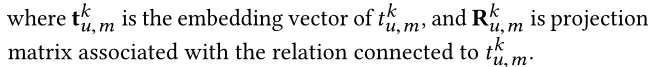
����֮��,����item v�ı�ʾ
v
\mathrm{v}
v�Dz�ͶӰ����ϵ�ռ��:

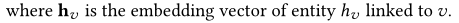
����:�����û���ʷ�����ԭʼitems������item֮��,��������Ҫ������ϵ����
4.3 Attention-based User Representation
���÷���:
����H+1ʵ��ļ���
L
u
k
(
k
=
0
,
1
,
.
.
.
,
H
)
L_u^k(k=0,1,...,H)
Luk?(k=0,1,...,H),һ�����õķ�ʽ�������û��ı�ʾ
u
\mathrm{u}
u���dz��������Щʵ�弯�ϵı�ʾ,Ҳ����
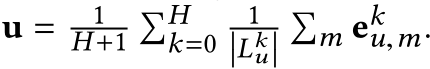
�����
e
\mathrm{e}
e������������intra-entity(�˹�ϵ������)��ʵ����ʾ!!
��
L
u
k
(
k
=
0
,
1
,
.
.
.
,
H
)
L_u^k(k=0,1,...,H)
Luk?(k=0,1,...,H)�����е��ھ�Ŷ!
���������ʽ�Ӿ��ǰ����еĺ�u��صĶ�����һ����ƽ��! ����û�п���inter-entity��!
���ߵķ���: (�ֳ�����,ÿ��һ���ۺ�)
Ȼ��,���ַ��������˵�1�������۵�inter-entity-interactions��
����,���Ƕ�ÿ��
L
u
k
L_u^k
Luk?Ӧ��һ����ע��������ѧϰһ��DZ�ڵı�ʾ
a
u
k
a_u^k
auk?,������ʵ��֮��Ľ�������������;���,�õ�
a
u
k
(
k
=
0
,
1
,
.
.
.
,
H
)
a_u^k(k=0,1,...,H)
auk?(k=0,1,...,H)��,�����������item
v
v
v,������Ҫ����һ��ע����network������ÿ��
a
u
k
(
k
=
0
,
1
,
.
.
.
,
H
)
a_u^k(k=0,1,...,H)
auk?(k=0,1,...,H)����Ҫ�ԡ������ʾ���û��Բ�ͬ����item�IJ�ͬ��Ȥ(��Ϊ�����ÿһ���ھӴ���ھۺϵĻ�,����ÿ��item������һ�ַ��!)��
-
��ע����
����ʲô��attention mechanism��self attention? ע�������ƿ�������Ϊ��query��һ��key-value pairsӳ�䵽����������values�ļ�Ȩ�����������,���������ÿ��value��Ȩ����ͨ����ѯ����Ӧkey�ļ����Ժ���(�����Է���,����Ϊ�ڻ������)�� ���Լල��,the query, key and value ����һ���ġ�
(����ļ����Ժ�����ʵ���Dz�ѯ����key�ĵ��,�鿴���������ƶ�)
��������,���Dz�����һ��scaled dot-product ע������ ������Ϊ a u k a_u^k auk?�ļ����������ͼչʾ��
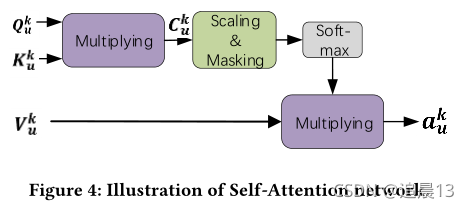
����,����ÿ�� L u k L_u^k Luk?,��ѯ�� Q u k Q_u^k Quk?����ֵ K u k K_u^k Kuk?��ֵ V u k V_u^k Vuk?���Ǵ� e u , m k e_{u,m}^k eu,mk?�õ���!
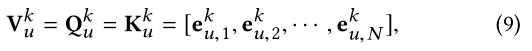
����N���ھ�ʵ�������,������һ���������� ��� �O L u k �O �� N \left | L_u^k \right | \ge N �O�O?Luk?�O�O?��N,��ô���������ѡN��;�෴,����Ҫȫ������ΪNull(Ҳ����zero vectors)��
�����Ժ�����ѯ�� Q u k Q_u^k Quk?�ͼ�ֵ K u k K_u^k Kuk?֮��ı���������:


���ն�ÿ�� a u k a_u^k auk?��Ӧ��softmax����:
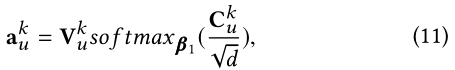
d \sqrt{d} d?�������ż����Ծ���(�����Է���),�Ա���ʽ��10�еĵ����ù����� ���softmax �������ռ���ÿ�� e u , m k �� V k ( m = 1 , . . . , N ) e_{u,m}^k \in V^k(m=1, ...,N) eu,mk?��Vk(m=1,...,N)��Ȩ��,
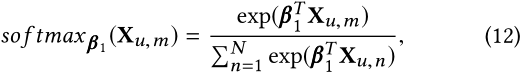
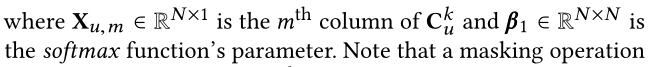
ע������������softmax֮ǰ,�����masking����(Ҳ���� C u k C_u^k Cuk?�ĶԽ��߶�����Ϊ0),�������Ա�������Է���̫�� -
ע��������
�ڸ���ʽ��11�õ�Ȩ���ܺͺ�,���ǻ����DZ�ڱ�ʾ a u k �� R d , ( k = 0 , . . . , H a_u^k \in \mathbb{R}^d,(k=0,...,H auk?��Rd,(k=0,...,H�� �� a u k a_u^k auk?���� e u , m k e_{u,m}^k eu,mk?��Ȩ���ܺ͵õ�һ��, u \mathrm{u} uҲ���� a u k a_u^k auk?��Ȩ���ܺ͵õ��ġ�
������һ��,��ѯ�� Q u k Q_u^k Quk?����ֵ K u k K_u^k Kuk?��ֵ V u k V_u^k Vuk?����������:
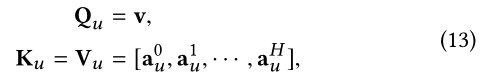
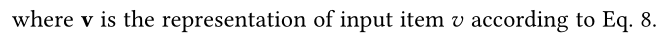
����u��ʽ��11һ��,����������:
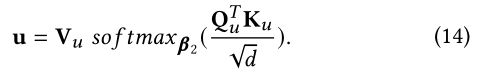
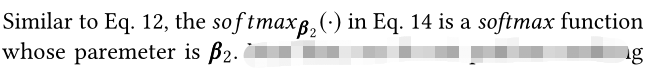
����,���Dz���ʹ��masking,��˲�ѯ����key���ϲ���ͬ��
���,�����û��ı�ʾ������Ŀ�ı�ʾ��v,�����Ԥ���CTR

5 LEARNING ALGORITHM
����user-item�Ľ�������
Y
Y
Y��֪ʶͼ��
G
\mathcal{G}
G, Ŀ����ѧϰAKUPM�����Ų���
�ٶ�
��
\Theta
������AKUPM�����еIJ���,���������h��t��r��Ƕ��,ǰ��˵�Ĺ�ϵӳ�����(ӳ��ռ�)
R
\mathrm{R}
R,��ע��������IJ���
��
1
\beta_1
��1?��ע��������IJ���
��
2
\beta_2
��2?,�ڹ۲���
G
\mathcal{G}
G��
Y
Y
Y��,����ϣ�������
��
\Theta
��������:
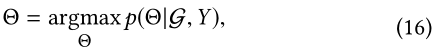
����ȼ�����������:
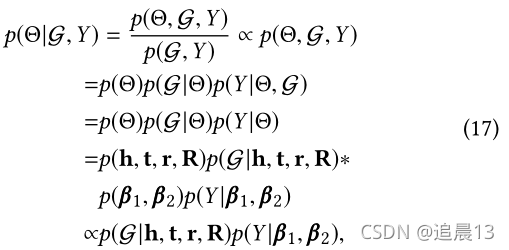

��һ�ڽ�������֪ʶͼ����ʽ�������Ż�ϸ��
5.1 Likelihood of Observed Knowledge Graph and Implicit Feedback
������Ԫ��
(
h
,
r
,
t
)
��
G
(h,r,t)\in \mathcal{G}
(h,r,t)��G,���Ǹ�������Ĺ���,�������������:
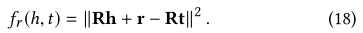
����Ķ��ŵ��˹�ϵ�ռ���!
���ǻ������ȡ��tailʵ��,�Ӷ�����µ�֪ʶͼ��
(
h
,
r
,
t
��
)
?
G
(h, r, t') \notin \mathcal{G}
(h,r,t��)��/?G,Ȼ���µ�֪ʶͼ��
G
��
\mathcal{G}'
G��,����һ����Ԫ��
(
h
,
r
,
t
,
t
��
)
��
G
��
(h, r, t, t') \in \mathcal{G}'
(h,r,t,t��)��G��,���Ҽ���������Ȼ����,
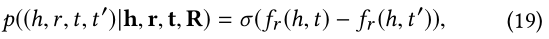
���,�۲쵽��֪ʶͼ���Ƹ��ʿ�������Ϊ:
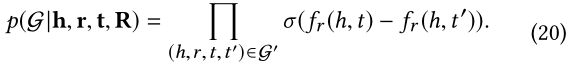
����ÿ�����ھ��� Y Y Y�����Ŀ y u v y_{uv} yuv?,���ʿ��Զ���Ϊ��Ŭ���ֲ��ij˻�:
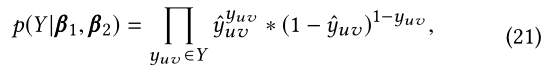
����
y
^
u
v
\hat{y}_{uv}
y^?uv?��ʽ��15�������
(
u
,
v
)
(u, v)
(u,v)��CTRԤ��
5.2 Loss Function
��ʽ��20��ʽ��21�ŵ�ʽ��16:
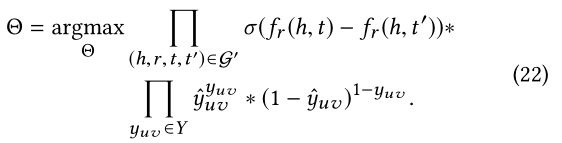
��Eq. 22ȡ�������������������,���ǵõ�AKUPM����ʧ��������:
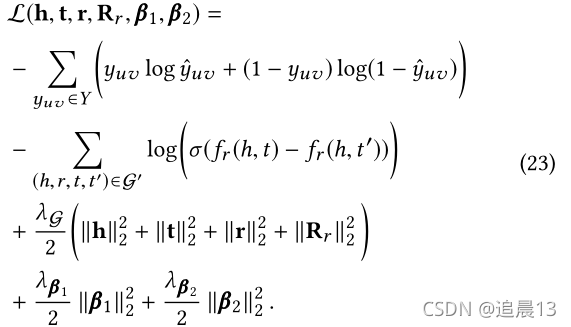
Ϊ����С��Eq. 23�е�Ŀ��,����ʹ����һ���������ݶ��½��㷨,ͨ�������۲��ѵ����
Y
Y
Y��
G
��
\mathcal{G}'
G��,��ʹ����ʧ��������Ӧ�ݶȸ���ÿ������
6 EXPERIMENTS
���ݼ�: MovieLens-1M �� Book-Crossing
��ΪAKUPM�ǻ�����ʽ������,�������ǻ�������ֵ���������ݼ�����ʾ����ת��Ϊ��ʽ������ ����ľ��ǽ���/�����в�������ֵ������ת��Ϊ��������ʽ����,Ҳ����ͬ������δ��ֵĵ�Ӱ����Ϊ�����ġ�
�Աȵ�ģ��: CKE��DKN��RippleNet��LibFM��DeepWide;

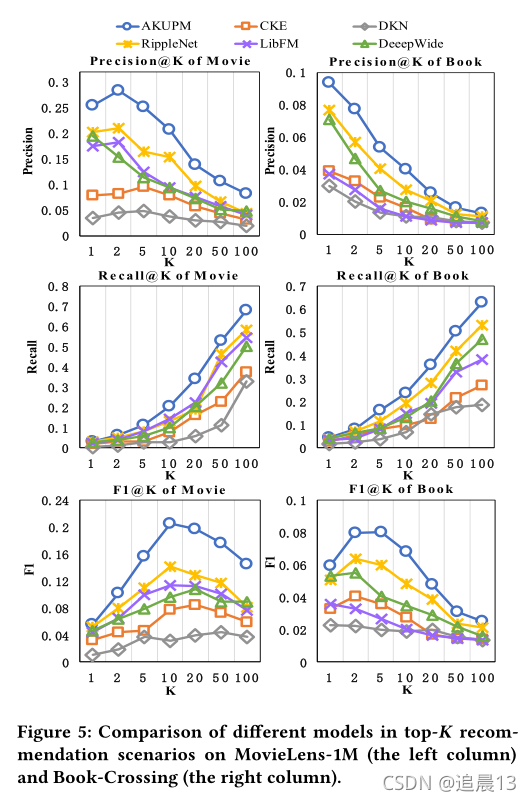
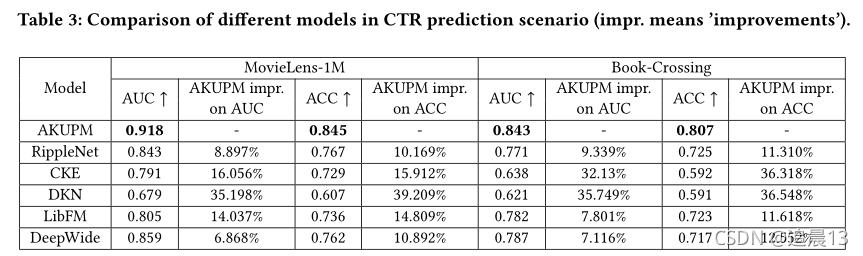
(2)����ģ����Book-Crossing���ݼ��ϵı��ֶ�������MovieLens-1M���ݼ��ϵı��֡���Ҫԭ����Book-Crossing���ݼ���ÿ�û�ƽ��������(3.91)ԶС��MovieLens-1M���ݼ�(62.44)�����,��Book-Crossing���ݼ���û���㹻����Ϣ����ģ���˽��û�����Ȥ
(3)���������,DKN������ԭ�������,��Ӱ���鼮�ı�������Ŷ̵ö�,ʹ�õ��ʼ�Ƕ���ʵ�弶Ƕ���������Ϣ����,��������顣
(4)CKE�����ǵ�ʵ���б��ֺܲԭ�����������:�ı������Ϳ���ͼ�������ǵ����ݼ��в�����;AKUPM��RippleNet�����������������������ص�ʵ��,��CKEֻʹ����������ֱ����ص�һ��ʵ������Ƽ���
(5)Ƕ�������õ�
(6)RippleNet�����л����м����ﵽ��������ܡ�AKUPM��RippleNet�ںϲ�ʵ���Ա�ʾ�û��IJ��ƫ�÷��������Ƶġ�Ȼ��,RippleNetû��̽���û��ͺϲ�ʵ��֮��Ĺ�ϵ,��˽�����ܻ��ܵ������ʵ��ĺܴ�Ӱ�졣
����������ʵ��: