精读西瓜书才了解西瓜书的由来,原来里面机器学习的例子都是拿西瓜举例啊。
一、机器学习的原理
对于某类任务T和性能度量P,如果一个计算机程序在T上以P衡量的性能随着经验E而自我完善,那么就称这个计算机程序从经验E中学习。这个经验实际就是数据。
机器学习就是把现实世界当中要研究的对象通过特征值将其数字化,然后让计算机通过这些已有的数字学习经验,即训练,得到判断能力即模型。
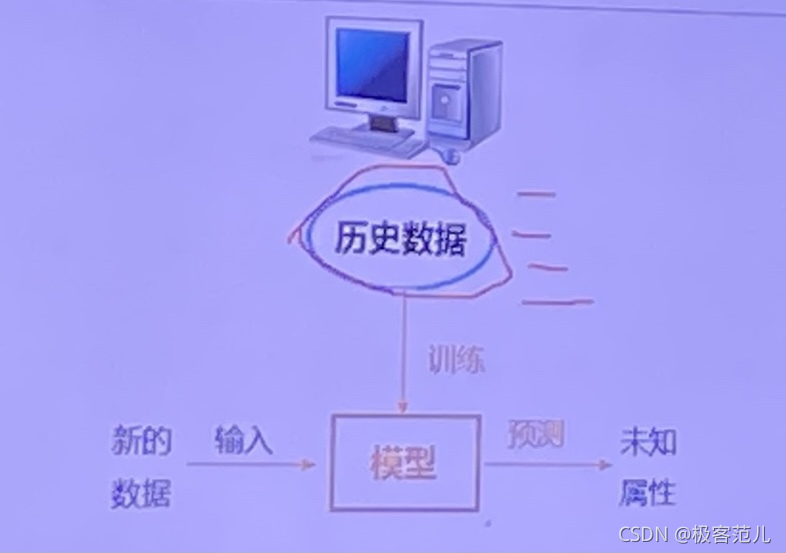
例子:
1、垃圾邮件识别/过滤:假定你的email程序观察到,哪些邮件被你标记为垃圾邮件,基于这个内容机器学习到了怎样更好的识别过滤垃圾邮件。
任务T:将邮件分类为垃圾邮件和非垃圾邮件
性能度量P:邮件被正确识别为垃圾邮件(非垃圾邮件的数量或比例)
经验E:观察你如何将邮件标记为垃圾邮件和非垃圾邮件
2、人脸识别
任务T:识别出人脸
性能度量P:识别准确率
经验E:很多人脸照片,没人的特征是是什么,什么样的眼睛、脸型、鼻子等等
计算机学习需要经验,这个经验就是数据集
有了经验,那机器要怎么样能像人类一样学习呢?
例如西瓜书上经典的例子:你这瓜保熟吗?
把西瓜对象提取出三种类型的特征值,然后通过算法让机器去学习,从而拥有了判断西瓜好坏的能力,我们把这个可以将经验转化为最终的模型的算法称之为学习算法。
西瓜特征提取:根蒂、色泽、敲声
现实世界的任何事物其实都可以通过属性或者特征来进行描述,三个属性就是西瓜的一组数据。属性的数目称之为维数,西瓜用了三个特征,因此就是三维。
二、机器学习算法分类
1、有监督学习:新闻文章故事的文章、数据集细分市场
2、无监督学习:邮件垃圾和非垃圾,糖尿病和非糖尿病
3、半监督学习
少量有标签数据+大量无标签数据,是监督学习和无监督学习的结合
监督学习分类:
分类:所有标签都是离散的值
回归:所有标签是连续的值
回归是具体的问题
特征提取:
1、观察
2、特征提取
3、特征筛选
4、训练、得到数据