pytorch-CycleGAN-and-pix2pix
���ͼ���
�����ҵ�һ����csdn��д����,��ѧ��һ,�Լ���ʼ��ѧ���ѧϰ,��ƪ����������Ҫ����Ի���pytorch��CycleGAN-and-pix2pix��һ��С���ڸ��㷨��һ��dz�Դ��Ե����⡣���ܻ��кܶ����,���Լ�����Ҳ����������ͨ,����ϣ�������ǿ���ָ��һ��,�����������ġ�
��Ŀ��������
pytorch-CycleGAN-and-pix2pix�����Ŀ��Ҫ����CycleGAN��pix2pix����һ���,������Ҫ�ֱ��˽�CycleGAN��pix2pix�Ǹ�ʲô������
��Ŀ���ص�ַ:https://github.com/junyanz/pytorch-CycleGAN-and-pix2pix
GAN
��������Ҫ֪��ʲô��GAN���ɶԿ�������?��û�д�����ǩ����ͬʱ����ﵽһ���ܺõ�Ч��,�Ӷ�������ٶԼලʽѧϰ������,GAN����˵�Ƕ��ڷǼලʽѧϰ��һ��������
�ڲ���ȷ����ģ�͵��ܶȷֲ�,����ֱ����ģ�͵ķֲ������ݵķֲ�������,����ȡ��,�����Ϊ����:1.һ�����ôﵽƽ�Ⱥ�������ɷ�����ȡ��,������������������GSN��2.����һ�����GAN,GAN��һ����ʽ����,��GAN��G����(������:�����ܻ����б�����ͼƬ,��һ���ݶ��½��Ĺ���)��D����(�б���:�������������ɵ�ͼƬ����ʵ��ͼƬ,��һ���ݶ������Ĺ���)��������Կ�ѵ��,Эͬ�������ؼ�����ѵ����ʽ������ͬ:����G����D��û��ֱ��ȥѵ�����Ǽ�ӶԿ�,��ѵ���б����̶�������,�����������������б�����ͼƬ,����0�Ͳ���ˮ����һ�������ҵ����⿴��,������Ż�����,���Dz�������Ľ�,�������һ����ʲ���⡣
��һ��������,α��minst���ݼ�:
1.����������,����һ�� ArgumentParser ����:parser = argparse.ArgumentParser(),parser ��������������н����� Python �������������ȫ����Ϣ��
2.���Ӳ���:ͨ������ add_argument() ������ parser�������ӳ�������IJ�����Ϣ,�Դ��������ڶ�ɱ��ȫ�ֱ�������һ����������,100��������ʼ,���ɳ���һ�����,����minst���ݼ�
parser.add_argument("--latent_dim", type=int, default=100, help="dimensionality of the latent space")
3.��������:ͨ�� parse_args() ������������,������ظ�opt��
4.����ͼƬshape(ͨ��������)(12828)�Լ�ʹ��cuda������
5.����G��:������������block��forward
def block(in_feat, out_feat, normalize=True): # �������Ϊ(����,���,�Ƿ��һ��)
layers = [nn.Linear(in_feat, out_feat)] # �ȶ����һ��ȫ���Ӳ�,���������ɵ�100ά����
if normalize: # �����Ҫ��һ���Ļ�,�����б�ĩ��������������:��һ�����й¶���������Ե�Ԫ
layers.append(nn.BatchNorm1d(out_feat, 0.8))
layers.append(nn.LeakyReLU(0.2, inplace=True))
return layers
self.model = nn.Sequential(
*block(opt.latent_dim, 128, normalize=False), #�����Ĵ�bolock����
*block(128, 256),
*block(256, 512),
*block(512, 1024),
nn.Linear(1024, int(np.prod(img_shape))), #������������������ԭʼ������һ����,ԭʼ28*28*1,������784,һ�ỹ��reshape��ȥ
nn.Tanh() #np.prod������������Ԫ�صij˻�,�����ж��ά�ȵ��������ָ����,��axis=1ָ������ÿһ�еij˻�
)
6.����D��:
self.model = nn.Sequential(
nn.Linear(int(np.prod(img_shape)), 512),
nn.LeakyReLU(0.2, inplace=True),
nn.Linear(512, 256),
nn.LeakyReLU(0.2, inplace=True),
nn.Linear(256, 1),
nn.Sigmoid(),
)
7.����ʧ�庯��.,ʵ�������硣
ֵ��һ�����BCE��ʧ������ѧ����Ϊ(����*o[i]*����ĸ���ֵ���Ѿ����sigmoid()����������õ���)
8.�������ݼ���������dataloader,���ú�batch-size�����������Ż���������Ȼһ������Ҳ��������
9.**(�ص�)**ѵ����������ʧ����:��dataloader��ѭ��batch��ѵ��
valid = Variable(Tensor(imgs.size(0), 1).fill_(1.0), requires_grad=False)#��ľ��Ǵ�minst���ݼ��ó�����,�����ݱ�ǩ����1
fake = Variable(Tensor(imgs.size(0), 1).fill_(0.0), requires_grad=False) #һ��ʼ100ά����,�������������õ���ͼ�����һ�ٵı�ǩ����0
# ---------------------
# Train Generator
# ---------------------
#����ĸ�˹�ֲ�����,��ֵΪ0����Ϊ1,z����˼���������ʼ��һ��batch������,ά����(ͼƬͨ����,opt��ά��)Ҳ��1*100
z = Variable(Tensor(np.random.normal(0, 1, (imgs.shape[0], opt.latent_dim))))
real_imgs = Variable(imgs.type(Tensor)) #��ʵͼƬ
optimizer_G.zero_grad() #�������ݶ�����
gen_imgs = generator(z) #�õ�������,ͨ���������罫100ά��������784ά������
g_loss = adversarial_loss(discriminator(gen_imgs), valid) #��ʧ�����Ķ��巽��:gen_imgs�����ɽ��,��ƭ���б���,����������б���,������������˵��ϣ����ƭ��ȥ��,���Դ���ı�ǩֵ��1��Ҳ���ü����ݺ����ǩѵ��������
g_loss.backward() #����������,������ʧֵ�Ǿ������б����˵�,��������ʽ����,���Դ�ʱ�б������ò������ݶ�
optimizer_G.step() #ֻ�������������ݶ�
# ---------------------
# Train Discriminator
# ---------------------
optimizer_D.zero_grad() # ����������ʧ�����ݶȷ���ʱ,˳��������б��������ݶ����
real_loss = adversarial_loss(discriminator(real_imgs), valid) #�б����ĵ�һ����ʧֵ:���������ǩ��ѵ���б���
fake_loss = adversarial_loss(discriminator(gen_imgs.detach()), fake) #�б����ĵڶ�����ʧֵ:�����ݺͼٱ�ǩ��ѵ���б���
d_loss = (real_loss + fake_loss) / 2 #��ƽ��,�õ��б���������ʧ
d_loss.backward() #��ʧ�ش�,����
optimizer_D.step() #�ݶȸ���
10.ѵ�����,�õ���������
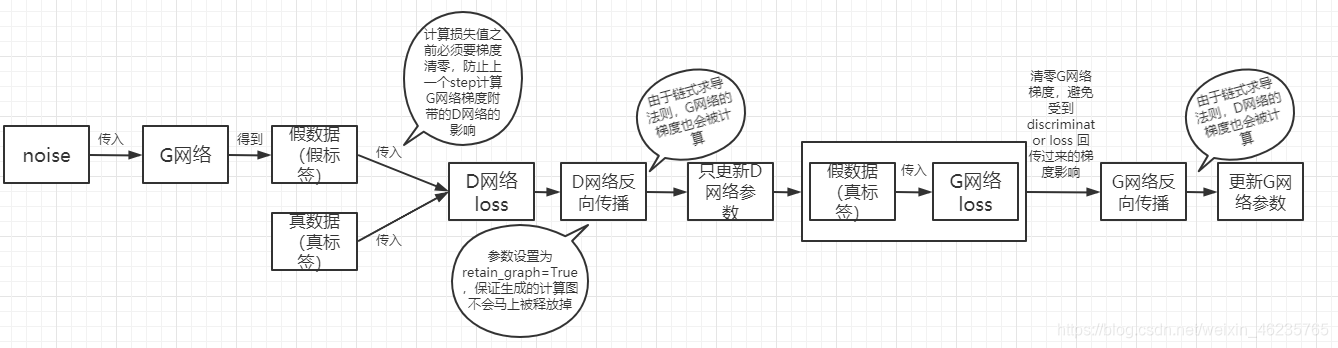
**(�ص�)**��������ͻȻ�ֳ�����һ������,����֮ǰ˵�õ�����ѵ���б�����ѵ��������������Ϊʲô��չʾ����������з�����ѵ����������ѵ�����б�����?
��:����������Ҫ�������ͼ�ĸ���,��pytorch�м���ͼ�ı�����һ�ֶ�̬��������ͼ,����ͼʲôʱ��ᱻ�ͷ���?��ÿ�ε���backwardʱ���ͷ�(��һ���������:�����б�����torch.stack()����ʱ�����µ�ά�Ƚ��жѵ�,���Ӧ�ķ�������ִ��,���Ի���ǰ�ͷ�,һ��Ľ��������������retain_graph=True;��Ҷ�ӽڵ�detach��)��
�������ѵ����ʱ�����ϣ������һ���ֵ������������,ֻ������һ���ֵIJ������е���;����ֻѵ�����ַ�֧����,���������ݶȶ���������ݶ����Ӱ��,torch.tensor.detach()��torch.tensor.detach_()�������ж�һЩ��֧�ķ���,torch.tensor.detach_()��torch.tensor.detach()������:detach()��detach_()����,�������������detach_()�ǶԱ����ĸ���,detach()����������һ���µ�variable��
�ص�������,�����ѵ���б���,��ѵ���������Ļ�,���б��������Լٱ�ǩ�ͼ����ݵĹ�����Ҳ��������������ݶ�,��ֻ�����б������ݶȡ������������ڷ�����ʱ��,���ڼ����ݺ����ǩҲͬ�������б���������,��Ҫ�������η������Ҳο���ƪ����,�����������ƪ�����С�������Ȼ����Щͬѧ��������,Ϊ�˸��õ�����,�����˻�ͼ��ʶ,ͨ�����������������ַ���:
1.��D��G:�������noise,һ��ǰ�����η���(��һ�η���Ϊ�˸��� discriminator �IJ���,����������� generator ���ݶȡ��ڶ��η���Ϊ�˸��� generator �IJ���,���Ǽ����� discriminator ���ݶ�),����Ҫ�ڵ�һ�η���������֤����ͼ���ᱻ�ͷ�,�����ò������ơ�
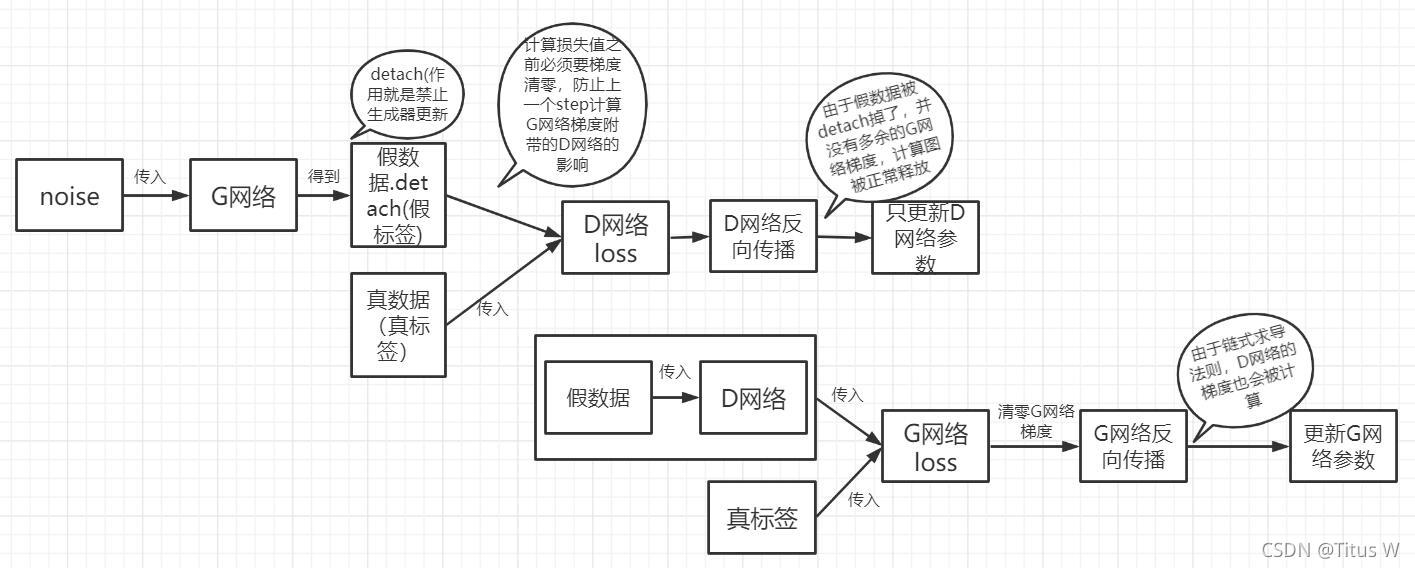
2.��D��G:�ڶ������Ǽ����������б�����һ��������,Ҳ��һ�ַ���
3.��G��D:
�������������ҪҪ���б����������������� retain_graph=True ʮ����Ҫ,�������ͼ�ڴ潫�ᱻ�ͷ�,Ϊ�˱��ּ���ͼ�����ͷš���Ϊ pytorch Ĭ��һ������ͼֻ����һ�η���,������,�������ͼ���ڴ�ͻᱻ�ͷ�,����������������Ƽ���ͼ�����ͷš�����һ�ַ�������ʹ��detach()����,Ҳ���������б�����������ݵ�ʱ��,�������ݼ���.detach()����,pred_gen_det = discriminator(gen_imgs.detach()) # ������detach(),��ֹ����������,�б����Լ����ݵ������
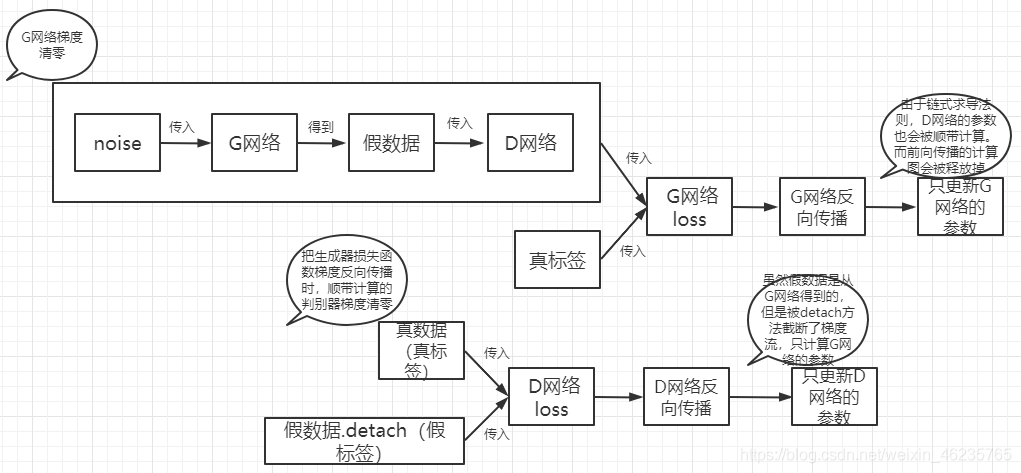
��ʵ�ϸ��ַ��������Ǻܴ�,ʵ������Ҳ���Ǻܴ���������������ʱ��,����������ַ��������һЩЧ��,һ����˵��������Ҫ���б����縴��һЩ,�б����籾����Ҳֻ��һ������ʵķ�������,���Ծ������ٵļ�����������ǰ���ļ������Ǹ��õġ�
�������ϵķ���֮������Ҷ����ɶԿ�����GAN��dz�Դ��Ե�����:����GAN����Ҫ�����Ǵ������������ϲ����ڵ�����,��Ҫ��Ϊ��������,���ɡ��б𡢶Կ����������������Ǹ�����������������ݡ��б��������ж������Ƿ�����ʵ��,ͨ���������һ�����ʡ��Կ��ǽ���ѵ���Ĺ���,ֱ���б������������ݵ�Ԥ����ʶ��ӽ�0.5,Ҳ�������ֱ���پ�ֹͣѵ����GAN�����Ӵ�,����WGAN(wasserstein distance),DCGAN(�����þ����������GAN),Cycle GAN(ӵ�������������������б���),StyleGAN(�ں�����),3DGAN(��ά)����������ƹ��ܵĻ��в���������������Ա������ȡ�
Cycle GAN
���˽�������������ɶԿ�����ĸ���֮��,��������Ҫ����Cycle GAN��,��Ƚ������������������б�����ɵ����ɶԿ����硣��Ҫ�˽�Cycle GAN������֪����ԭʼ�����Ľṹ������ʲô�仯,������Щ������?
��Ҫ��˵�������˱Ƚ����Ե������仯:1.��������ܹ�
2.�漰��������ʧ����:G����,D����,Cycle,Identity
3.D�����PatchGAN
Χ��������,������һ������һ��ѧϰ��̽��:
��������������ܹ�Cycle GAN�������������������б���,����һ������������Aת����B,��ʹB������ͨ��B�б�������顣����һ������������Bת����A,����A������ͨ��A�б�������顣Ȼ����β����,�þ�������ת�������ݾ�������ԭʼ������һ��,���Ǿͻ�ӵ��������ǿ��������,����ͼ:һ�����ĸ�����,������������������б�����
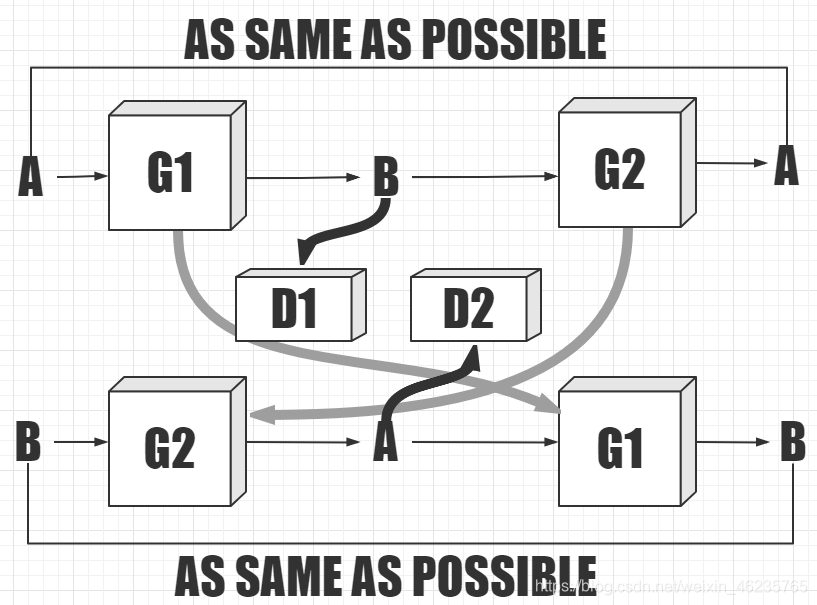
����������������ʧ������,G�����D�������ʧ������֮ǰһ�����ؼ�����A��B��A��������С������A�ͻ�ԭ���ɵ�A���������ص�ÿһ��pix����һ��lrloss,����ÿһ�����ص�֮���ֵ����ƽ�����������identityӳ��:���ɳ�����ͼ���ٴδ����������������ٴ����,������ԽСԽ�á�
PatchGAN������:PatchGAN�������һ��NN�ľ���,��Ҫ���ڸ���Ұ��������ʧ�����ڸ���Ұ������ͼ�ϵ�Ԥ����,�ͱ�ǩ(Ҳ�����ó�NN)������ʧ����ô˵������Щ�ٷ�,�����Լ���������Cycle GAN���б��������ǵõ�һ�����ֵ����˵�Ǹ���ֵ,����ͨ��CNN�õ�������ͼ���������ȫ���Ӳ�,�����ᴫ��sigmoid�����С�������������ͼ�϶�����ά��NN1,���������ͼ��ÿһ�����ص㶼����ԭʼ����Ұ��ijһ������,�������ͽ���һ��patch�����Դ�ʱ������ͨ�����������ͼ�����б������б����,���ǻ���ÿһ��Сpatch�����жϡ�����ʱ��ǩҲ��������һ��ֵ��,Ҳ��һ��N*N�ľ���,ͨ��������������ͼ���������бȽϡ�
CGAN
û�Ӵ�֮ǰ,����ΪcGAN��Cycle GAN��һ����д,����Ҵ��ˡ�cGAN������ʽ���ɶԿ�����(Conditional Generative Adversarial Nets)�ļ�ơ�ͨ��ԭʼ�����˽,��ͨ��Ϊ��������label�����й���,��G�����D����������϶�����label,Ȼ��ͨ����������ʵ��,��������y�������ֲ�,���ɷ���������y��������
��������ʲôʵ����?1.mnist���ݼ�,���ڸ���label�����ض����ֵ�ģ��ʵ�顣2.����multi-model- model��ģ̬ѧϰ,���ɲ�����ѵ���������Ա�ǡ��Ҹ��˲�û����������ʵ��,��Ҫ��Ϊ������cGAN�ĸ��
֮ǰ��������GAN��,���ɵ������Dz��ɿص�,���Ǹ�����ǩ��cGAN����,���Ի���label�����ض���ͼ����one-to-many mappingģ��,����image tag����,һ��ͼ����ܲ�ֹһ��tag,��ͳģ�������,��˿���ʹ���������ɸ���,������ͼ����Ϊconditional variable(��������),ʹ������Ԥ��ֲ�ȥ��ȡһ�Զ��ӳ���ϵ��
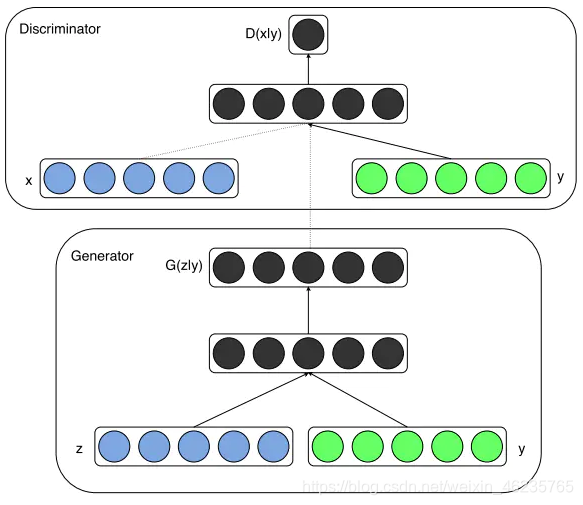
D�б������������ͼ��֮�������y��ǩ(��ɫ��ԲȦ)��y�������ά����x��ͬ����Ϊ��ģ���ڲ�������embedding������G�������������������֮��,Ҳ������y��ǩ��ά�ȹ�ϵͬ�ϡ�Ȼ�����ɵ�ͼ����Ϊһ��������y������뵽D�б�����
������һһ�μĴ���������CGAN:
class Discriminator(nn.Module):
'''ȫ�����б���,����1x28x28��MNIST����,��������ݺ����'''
def __init__(self):
super(Discriminator, self).__init__()
self.model = nn.Sequential(
nn.Linear(28 * 28 + 10, 512),
nn.LeakyReLU(0.2, inplace=True),#inplaceΪTrue,����ı���������� ,����ı�ԭ����,ֻ������µ����
nn.Linear(512, 256),
nn.LeakyReLU(0.2, inplace=True),
nn.Linear(256, 1),
nn.Sigmoid()
)
def forward(self, x, c): #����ͱ�ǩ
x = x.view(x.size(0), -1) #չƽ��һά
validity = self.model(torch.cat([x, c], -1))���� #cat()����,���Ӻ���,��������tensor,torch.cat( ( ) ,0 ) ����������,torch.cat( ( ) ,1 or-1 ) �Ǻ�������
return validity
class Generator(nn.Module):
'''ȫ����������,����1x28x28��MNIST����,���������������'''
def __init__(self, z_dim):
super(Generator, self).__init__()
self.model = nn.Sequential(
nn.Linear(z_dim + 10, 128), #����ά�ȼ�10,Ϊ10����ǩֵԤ���ռ�
nn.LeakyReLU(0.2, inplace=True),
nn.Linear(128, 256),
nn.BatchNorm1d(256, 0.8),
nn.LeakyReLU(0.2, inplace=True),
nn.Linear(256, 512),
nn.BatchNorm1d(512, 0.8),
nn.LeakyReLU(0.2, inplace=True),
nn.Linear(in_features=512, out_features=28 * 28),
nn.Tanh()
)
def forward(self, z, c): #�����ͱ�ǩ
x = self.model(torch.cat([z, c], dim=1))
x = x.view(-1, 1, 28, 28) #x���б���������,-1����˼������Ӧ
return x
# ��ʼ�������б�����������
discriminator = Discriminator().to(device)
generator = Generator(z_dim=z_dim).to(device)
# ��ʼ����ֵ��������ʧ
bce = torch.nn.BCELoss().to(device)
ones = torch.ones(batch_size).to(device)
zeros = torch.zeros(batch_size).to(device)
# ��ʼ���Ż���,ʹ��Adam�Ż���
g_optimizer = optim.Adam(generator.parameters(), lr=learning_rate)
d_optimizer = optim.Adam(discriminator.parameters(), lr=learning_rate)
# ��ʼѵ��,һ��ѵ��total_epochs
for epoch in range(total_epochs):
# torch.nn.Module.train() ָ����ģ������ BatchNormalization �� Dropout
# torch.nn.Module.eval() ָ����ģ�Ͳ����� BatchNormalization �� Dropout
# ���,train()һ����ѵ��ʱ�õ�, eval() һ���ڲ���ʱ�õ�
generator = generator.train()
# ѵ��һ��epoch
for i, data in enumerate(dataloader):
# ������ʵ����
real_images, real_labels = data
real_images = real_images.to(device)
# �Ѷ�Ӧ�ı�ǩת���� one-hot ����
tmp = torch.FloatTensor(real_labels.size(0), 10).zero_()
real_labels = tmp.scatter_(dim=1, index=torch.LongTensor(real_labels.view(-1, 1)), value=1)
real_labels = real_labels.to(device)
# ��������
# ����̬�ֲ��в���batch_size���������
z = torch.randn([batch_size, z_dim]).to(device)
# ���� batch_size �� ont-hot ��ǩ
c = torch.FloatTensor(batch_size, 10).zero_()
c = c.scatter_(dim=1, index=torch.LongTensor(np.random.choice(10, batch_size).reshape([batch_size, 1])),
value=1) #�ӡ�srcԴ���ݡ��л�ȡ������,���ա�dimָ����ά�ȡ��͡�indexָ����λ�á�,�滻input�е����ݡ�
c = c.to(device)
# ��������
fake_images = generator(z, c)
# �����б�����ʧ,���Ż��б���
real_loss = bce(discriminator(real_images, real_labels), ones)
fake_loss = bce(discriminator(fake_images.detach(), c), zeros)
d_loss = real_loss + fake_loss
d_optimizer.zero_grad()
d_loss.backward()
d_optimizer.step()
# ������������ʧ,���Ż�������
g_loss = bce(discriminator(fake_images, c), ones)
g_optimizer.zero_grad()
g_loss.backward()
g_optimizer.step()
# �����ʧ
print("[Epoch %d/%d] [D loss: %f] [G loss: %f]" % (epoch, total_epochs, d_loss.item(), g_loss.item()))
# ���������������������һ��ͼ��,����CGAN��Ч��:
# ��������Ч��ͼ
# ����100�������������
fixed_z = torch.randn([100, z_dim]).to(device)
# ����100��one_hot����,ÿ��10��
fixed_c = torch.FloatTensor(100, 10).zero_()
fixed_c = fixed_c.scatter_(dim=1, index=torch.LongTensor(np.array(np.arange(0, 10).tolist() * 10).reshape([100, 1])),
value=1)
fixed_c = fixed_c.to(device)
generator = generator.eval()
fixed_fake_images = generator(fixed_z, fixed_c)
plt.figure(figsize=(8, 8))
for j in range(10):
for i in range(10):
img = fixed_fake_images[j * 10 + i, 0, :, :].detach().cpu().numpy()
img = img.reshape([28, 28])
plt.subplot(10, 10, j * 10 + i + 1)
plt.imshow(img, 'gray')
```ut_dim=self.latent_dim))
���ݴ���,���Ǻ���������֮ǰ��ͳ��GAN������,�������������ֵ��������ʵͼƬ�����ǩ,��������ij�ʼ����z_dimension֮ǰ�õ���100ά,����MNIST��10��,Onehot�Ժ�һ��ͼƬ�����ǩ��10ά,���Խ����ǩ���ں���z_dimension=100+10=110ά;ѵ����������ʱ��,���������������������z_dimension=110ά,������100ά���������10ά��ʵͼƬ��ǩƴ��,��Ҫ����Ӧ��cat()ƴ�Ӳ���;
DCGAN
���˽�DCGAN֮ǰ,������Ҫ���˽�ʲô����ת�þ���,Ҳ�з������������Ҿ�������з�������Щ��̫��,���ڳ�ѧ����˵����Щ�����ӵܡ���Ϊ���������������Dz������,������,��������������ȡ����Ϣ��ʧ�Ĺ���,��ô�ܹ���ԭ������?���Կ�����,����һ�����������������������Ķ���һƪ��������������ת�þ���,��Ȼ��ƪ�����Ѿ�д�ķdz�ͨ������,�����һ�����һ��С�ĽǶ���˵һ���Ҷ�ת�þ��������⡣
��������֪������ͨ�����Ĺ�����,�������ڸ���Ұ�ϸ��ݲ�����ͣ�Ļ����Ӷ�����õ�����,��ʵ�����������̼����������ͨ�����ַ�ʽ�����е�,���ǰѾ�������Χ���ϼ�Ȧֱ��0ʹ�����˺����������ȫһ��,�ٰ�����������������������ȡת��,ֱ�ӺͲ���0֮������о�����ƴ���������,��õ����������ת�á�������̲���ת�þ���,����������������ת�ó��Ͼ�����ƴ�Ӻ��ת��,�õ��Ľ������״��Ҳ������������������ת������ͬ����?�����ת�þ���˼�������,�����Ⲣ����һ�����������������,��������ʽ�������������,����ͬһ��������,����ת�þ�������֮���ָܻ���ԭʼ����ֵ,������ֻ��ԭʼ����״��
Ҳ����˵��ʵ�ʾ����Ĺ�����:��������Ĺ���=����ά��ת��������ȡת��*�����˲�0ƴ�Ӻ����ɵ�������
��ʵ��ת�þ����Ĺ�����:����ά��ת��������(��Ϊ̫С,��Ҫ��0)*�����˲�0ƴ�Ӻ����ɵ�������=����һ������ľ������ٳ�����ԭʼ�����ά�ȵı߿���л������㡣
�Ժ���������ת�þ�����ʱ��,��ʵ����һ�������ֱ�Ӿ���,ֻ����������Щ��̫һ��,����Ҳ�ܼ�,��Ϊ�����˴�С�Ѿ�����������,���Ը��ݾ����˴�С�ߴ���Ϊԭʼ���벹��0����ߴ�,Ȼ���ٽ��������������·�ת(��ת180��),ֱ�ӽ��о������ɡ�
```python
class D_dcgan(nn.Module):
'''�����������'''
def __init__(self):
super(D_dcgan, self).__init__()
self.conv = nn.Sequential(
nn.Conv2d(in_channels=1, out_channels=16, kernel_size=3, stride=2, padding=1),
nn.LeakyReLU(0.2, inplace=True),
nn.Conv2d(in_channels=16, out_channels=32, kernel_size=3, stride=2, padding=1),
nn.BatchNorm2d(32),
nn.LeakyReLU(0.2, inplace=True),
nn.Conv2d(in_channels=32, out_channels=64, kernel_size=3, stride=2, padding=1),
nn.BatchNorm2d(64),
nn.LeakyReLU(0.2, inplace=True),
nn.Conv2d(in_channels=64, out_channels=128, kernel_size=4, stride=1),
nn.BatchNorm2d(128),
nn.LeakyReLU(0.2, inplace=True)
)
# ȫ���Ӳ�+Sigmoid�����
self.linear = nn.Sequential(nn.Linear(in_features=128, out_features=1), nn.Sigmoid())
def forward(self, x):
x = self.conv(x)
x = x.view(x.size(0), -1)
validity = self.linear(x)
return validity
class G_dcgan(nn.Module):
'''ת�þ���������'''
def __init__(self, z_dim):
super(G_dcgan, self).__init__()
self.z_dim = z_dim
# ��һ��:���������Ա任��256x4x4�ľ���,���������������ת�þ�������
self.linear = nn.Linear(self.z_dim, 4*4*256)
self.model = nn.Sequential(
nn.ConvTranspose2d(in_channels=256, out_channels=128, kernel_size=3, stride=2, padding=0),
nn.BatchNorm2d(128),
nn.ReLU(inplace=True),
nn.ConvTranspose2d(in_channels=128, out_channels=64, kernel_size=3, stride=2, padding=1),
nn.BatchNorm2d(64),
nn.ReLU(inplace=True),
nn.ConvTranspose2d(in_channels=64, out_channels=1, kernel_size=4, stride=2, padding=2),
nn.Tanh()
)
def forward(self, z):
# ����������������Ա任,resize��256x4x4�Ĵ�С
x = self.linear(z)
x = x.view([x.size(0), 256, 4, 4])
# ����ͼƬ
x = self.model(x)
return x
�б��� �� ������ ������ṹ,��֮ǰ����,ֻ��ʹ���˾����ṹ��
Pix2pix
Pix2pix���
���˽���Cycle GAN�Ļ���������ṹ֮��,����֪����Cycle GAN����������������Ϣ����������Ҳ����������������Ϣ,������Ϊͼ��ʱ,Pix2pix�͵����ˡ�ͨ������ΪPix2pix������ͼ�����CGAN,���ñȽ��������,���о��ܵĵ��β��������Ľ��������Pix2pix����Ҫ��Եı�ǩͼ���ʵ��ͼ��ġ���Ȼͼ�����Ч���ܺ�,�����ҵĵ��Բ�̫��,��û�취��
��ô��ѧϰpix2pix֮ǰ,������Ҫ�˽�pix2pix�Ľṹ,�����˽�pix2pix�Ľṹ֮ǰ,����Ҫ���˽����������Զ���������U-net��
Auto-encoder
�����Զ�������,������Ͳ������Ĵ�̸��,ֻ�ǰ����Լ�ѧ���Ĺ����Զ���������֪ʶ������dz̸һ�¡�
�����Ǹ���:�Ҹ����������ڸ������Ĵ���ǩ�����ݼ��Ǻ��ѵú�����,������δ���Ǽලѧϰ��Ӧ�ý����ӹ㷺,�ҰѰѱ���������Ϊһ�ִ����뵽�����ӳ�䡣ͨ����������������һ��������(��������ָһ��ѹ����ı�ʾ),��ͨ����������ԭ�ع�������ݡ�Ҳ����˵�������ͽ������ܾ����ܻ�ԭ��ԭʼ�����롣������ʲô����?���ȥ��������?��ʵ�����õ�,�����еĹؼ������м��embedding��,����˵Ҳ���м��ѹ����ʾ(compressed representation),���ѹ����ʾ����ͨ����ά������,����֪����ά���ڷǼලѧϰ��һ��,���ﲻ�ò��ᵽ�ľ����������ˡ�
������������ʲô?��ʲô����?������Ķ���ܼ�,��������������������������и��㶼�������㡣֮ǰ���ѧϰ�ķ�չͣ��,��Ҫ�������������ò������,���Ƿ����Լ����������������ͻ����һ����,һ����Ԫ���һ��ֱ��,�����Ԫ������Ϸ����Եı߽�,ͨ��һ��һ�����ȡ,������Ϳ����������ݵ�����������һ��ά�ȵĿռ�,����Щ�������ӳ���,�������Ի��֡���������������ܽ��ƶ�������ֻҪ��һ���������������,�����ϾͿ�������κ�һ�ֺ��������������ͽ��������ǿ���ͨ���������������ġ�
�ص��Զ���������˵,��Ϊ�Զ���������������һ��������,���Կ�������ͨ��ǰ��������,����ʵ�Ͼ����������Ч������á��ڱ����������õ������dzػ�,�Ѵ��feature-map���С��feature-map,���ڽ����������õıȽ϶������ת�þ�����
������Ҫ̸һ̸�Զ������������:
1.����м����������ԭʼ����ά��ҪС,��֮ΪǷ�걸�Զ�������,��ΪҪǿ���Ա�������ѵ��������������������,����ѧϰ���̵ȼ�����С��һ����ʧ����(MSE����L2)��
2.��֮���Ϊ���걸�Զ�������:���ر����ά�ȴ��ڻ��������ά��,���ֱ�������Ϣ��������,ѧ�������õĶ�����
3.ȥ���Ա�����:��������,������Ǵ�����������,���������ȥ������������,Ҳ���ǽ�����������Ϊ����,��ѵ����Ԥ��ԭʼδ�������ݡ�
4.��ֵ��Զ�������:���ڱ���Զ�����������Ҫ��˵�����ˡ�
��ͳ���Զ�������ת��������:���ݡ�>��������>�ع����µ����ݡ�
������Զ���������ת�������� :ÿһ����������Ҫ�ҵ�һ����̬�ֲ�(������ͨ�����ķ�ʽ��ÿһ���������ֲ�����Ϊ��̬�ֲ�),ÿһ����̬�ֲ���Ҫ��Ͼ�ֵ�ͷ���,ÿһ����������ݶ��ܶ�Ӧһ���������ķֲ�����Ϊ��̬�ֲ��������������Ƚϳ������������Ҳ���ÿһ�����������õ�һ���ֲ���,�Ҿ;���ÿһ���ֲ��ϲ���,�ܲźü������ü�����ֵͬ,ÿһ�����������ع���ԭ����ֵ��
�������ܳ���һ���¸���б��,����һ�������������һ������������ֽ�����,���������ֽ�����֡��Ƿ�������ʲô��?�ҿ��˼��ڿγ�,�����������̫����,������:������ȻҲ��һ������һ����ӳ���ϵ,����ȷʵ��Ȼ��ͬ��һ������,�ؼ��IJ�֮ͬ���������ڴ���ӳ�䵽��,�����о���������ά�ռ�������ά�ռ���ӳ��,���������뵽�������Կռ���ȥ�����˹���,�о�ûɶ��Ҫ�˾͡�
U-net
���˽����Զ�������֮��,U-net��һ��ȫ������������,�ڵ����շ���ʱ���кܺõĴ�����,�Ҷ�����㷨���Ⲣ���Ǻܳ��,������ͼ���Լĸ���һ��U-net�Ļ���˼·: ���һ��֪���Ļش�������ṹ�����ܵ�λ:U-Net��һ�ֵ��͵ı���-����ṹ,�������������óػ���������²���,�������������÷������������ϲ���,ԭʼ����ͼ���еĿռ���Ϣ��ͼ���еı�Ե��Ϣ�ᱻ�ָ�,�ɴ�,�ͷֱ��ʵ�����ͼ���ջᱻӳ��Ϊ���ؼ��ķָ���ͼ����Ϊ�˽�һ���ֲ�������²�����ʧ����Ϣ,������ı������������֮��,U-Net�㷨����Concatƴ�Ӳ����ں����������ж�Ӧλ���ϵ�����ͼ,ʹ�ý������ڽ����ϲ���ʱ�ܹ���ȡ������ĸ߷ֱ�����Ϣ,���������Ƶػָ�ԭʼͼ���е�ϸ����Ϣ,��߷ָ�ȡ���������skip connection�ṹ��U-Net,�ܹ�ʹ��������ÿһ�����ϲ���������,����������Ӧλ�õ�����ͼ��ͨ���Ͻ����ںϡ�ͨ���ײ�������߲��������ں�,�����ܹ���������߲�����ͼ�̺��ĸ߷ֱ���ϸ����Ϣ,�Ӷ������ͼ��ָ�ȡ�
���һ��֪���Ļش�������ṹ�����ܵ�λ:U-Net��һ�ֵ��͵ı���-����ṹ,�������������óػ���������²���,�������������÷������������ϲ���,ԭʼ����ͼ���еĿռ���Ϣ��ͼ���еı�Ե��Ϣ�ᱻ�ָ�,�ɴ�,�ͷֱ��ʵ�����ͼ���ջᱻӳ��Ϊ���ؼ��ķָ���ͼ����Ϊ�˽�һ���ֲ�������²�����ʧ����Ϣ,������ı������������֮��,U-Net�㷨����Concatƴ�Ӳ����ں����������ж�Ӧλ���ϵ�����ͼ,ʹ�ý������ڽ����ϲ���ʱ�ܹ���ȡ������ĸ߷ֱ�����Ϣ,���������Ƶػָ�ԭʼͼ���е�ϸ����Ϣ,��߷ָ�ȡ���������skip connection�ṹ��U-Net,�ܹ�ʹ��������ÿһ�����ϲ���������,����������Ӧλ�õ�����ͼ��ͨ���Ͻ����ںϡ�ͨ���ײ�������߲��������ں�,�����ܹ���������߲�����ͼ�̺��ĸ߷ֱ���ϸ����Ϣ,�Ӷ������ͼ��ָ�ȡ�
Pix2pix�ṹ
������һЩ�̵�֪ʶ֪ʶ�Ժ�,�Ϳ����˽�Pix2pix�Ľṹ��,Pix2pix�ӱ����Ͻ���һ�ָ�ǿ��CGAN,����Ľṹ���DZȽϼ�
��Ŀ�ṹ
����Ŀ�漰�Ĵ����ļ��Ƚ϶�,�����һ��Ȱ����ļ������������л��֡�
�ļ���data
���ļ��а������ݵļ��غʹ����Լ��û��������Լ������ݼ�,����һ�������������ݼ��ࡣ
init_.py: ʵ�ְ���train��test�ű�֮��Ľӿڡ�train.py �� test.py ���ݸ����� opt ѡ��������������ݼ� from data import create_dataset��dataset = create_dataset(opt)
**base_dataset.py:**�̳��� torch �� dataset ��ͳ������,���ļ���������һЩ���õ�ͼƬת������,�����������ʹ�á�
���ļ���Ҫ������һ��BaseDataset�ļ̳л���Ľӿ����������ַ���,�̳�BaseDataset���������ʵ�������ַ���:
1.init:(��ʼ�������),���ݻ�ȡ����opt���dataroot���õ����ݼ��Ĵ��·����
2.len:(�������ݼ��Ĵ�С),@abstractmethod�ӿڵ�ע�⡣
3.getitem(�õ�һ��data),@abstractmethod�ӿڵ�ע�⡣
4.modify_commandline_options(��ѡ��,�������ݼ���һЩĬ��ѡ��),@staticmethodע�⽫�÷�����Ϊ��̬����,��Ϊ�÷�������Ҫ�õ������е��κ���Դ,����IJ���Ϊ�Ƿ�ѵ��������parser��
����ýӿ�,��д������ͼ��仯��صķ���:
get_params(�����û�ָ���ķ�ʽresize����crop�����ʴ�С������ߴ�,�������������boolֵ)
get_transform(�˺�����ͨ��transform_list�б��еIJ�������ͼ��任,ʹ��transforms.Lambda��װ��Ϊtransforms����,ͨ��transforms.Compose()�����ֱ任�������ߡ���ת�ü���������transform������������,��Щ���������������涨���)
���������������Ϊget_transform����������:
__make_power_2(������Ӧ�ߴ�,������С)
__scale_width(����ͼƬ�Ŀ���,������ͬ�ı���)
__crop(���ƽ�ƻ����ü�,�ü����ĵ���������ɵ�)
__flip(ͼ������������ҷ�ת��ת)
__print_size_warning(��ӡһЩ������Ϣ)
image_folder.py:�����˹ٷ�pytorch��image folder�Ĵ���,ʹ�ôӵ�ǰĿ¼����Ŀ¼���ܼ���ͼƬ,Ŀ�ľ��ǻ��ָ��Ŀ¼�µ�ͼƬ·���� ����·��ͼƬ�����Ȼᶨ��һ��Ԫ������Ÿó���֧��ͼƬ�ĺ���������ͼƬ��ʽ,�����Ż�д��������:
is_image_file:��鴫���б��е��ļ����Ƿ����Ҫ��,������һ��any()������Ҫע��һ��,any()���������жϸ����Ŀɵ�������iterable�Ƿ�ȫ��ΪFalse,��False,�����һ��ΪTrue,��True��
make_dataset:����ͼƬ���ݼ��ļ��е�·�����������ݼ���������ȶ���һ�����б�,Ȼ����·���Ƿ����,��·������os.walk()������Ϊ��������,ͨ�������õ��ļ���·����ͼƬ���Ʋ������֮ǰ����Ŀ��б���,��ظ��б���ǰһ���֡�
default_loader:�Ѷ�����ͼƬת��RGB��ʽ,��ת������ͨ����
����������ҪдImageFolder�������,һ�����������ͼ���������ʱ,����ùٷ�д�õ�torchvision.datasets.ImageFolder�ӿ�ʵ�����ݵ���,��Ϊ���ڷ�������,���ݼ�·����һ����������ļ���,train��test,ÿ���ļ������а���N�����ļ���,N���Ƿ�����������������Щ����Ͳ���������,����һ���ļ�������������ͼ�����ݶ���,��һ����Ӧ��txt�ļ�������Ӧ�ı�ǩ�ļ�,����������¾���Ҫ�Զ���һ�����ݵĽӿ��ˡ�������Pytorch�к����ݶ�ȡ��ص��������Ҫ�̳�data.Dataset�������,Ȼ���д���е�__init__��len��__getitem__�ȷ�����
1.init:��ʼ��,���ж��Ƿ���ʵ����ͼƬ��
2.len:����Ŀ¼��ͼƬ��������
3.getitem:����ͼƬ��ͼƬ��·����
template_dataset.py:Ϊ�����Լ����ݼ��ṩ��ģ��Ͳο�,����ע��һЩϸ����Ϣ,�����ṩһ��ʵ���Զ������ݼ���ģ��,��Ϊʵ����BaseDataset�ӿ�,ͬ��Ҫʵ�����ĸ�������
1.init:��ʼ�����ݼ�����,����ѡ���ȡ���ݼ���ͼ��·����Ԫ��Ϣ,����ͼ��任,����Ĭ�ϵı任������������ʹ��,Ҳ���Զ����Զ���任������
2.len:����ͼ�����������
3.getitem:�������������������������,���������Ƶ������ֵ䡣(��������ܹ���Ϊ�IJ�:����1:��ȡ���ͼ��·��������2:�Ӵ��̼������ݡ�����3:������ת��ΪPyTorch����������4:�����ݵ���Ϊ�ֵ䷵�ء�)
4.modify_commandline_options:���� add_argument() �������Ӳ���,����set_defaults()������һЩĬ��ֵ,����Ĺ���Ľ�������
single_dataset.py:�̳�BaseDataset�ඨ�����dataset��,ֻ����ָ��·���µ�һ��ͼƬ,�����Լ�����·��dataroot /path/to/dataָ����һ�鵥��ͼ����Ҳ���������������ڵĽ����Ϊһ����ģ��ѡ��-ģ�Ͳ��ԡ�
colorization_dataset.py:�����Լ���RGB��ʽ����Ȼͼ��,����RGB��ʽת��Ϊʵ������ɫ�ռ��е�(L, ab)�ԡ�����һ�� RGB ͼƬ��ת����(L,ab)���� Lab ��ɫ�ռ�,pix2pix�������Ʋ�ɫģ�͡����ǻ���pix2pixel����ɫģ��(����ģ����ɫ)����Ҫ�ġ�ͬ���̳���BaseDataset��Ҫʵ�������ַ���,��ͬС��,�����ﲻ����,���伸��������:
os.path.join(): ��ƴ�Ӻ���,��������������·���������
sorted():���������пɵ����Ķ���������������
assert():����ֻ��һ����������,����һ����,�൱��һ��if���,��������������������ش���,����ֹ�����ִ�С�
color.rgb2lab():��RGB��Ԫ��ת��ΪLAB��Ԫ�顣
aligned_dataset.py:��ͬһ���ļ����м��ص���һ��ͼƬ {A,B},���Թ�������Ҫ��һ��Ŀ¼/path/��/data/test��Ϊ�������ݡ�
unaligned_dataset.py:��������ͬ���ļ����·ֱ���� {A},{B} ,�ڲ����ڼ���Ҫ������Ŀ¼/path/to/data/testA��/path/to/data/testB��
���������ݼ���������������__getitem__()������ʵ��,�ڵõ���������֮��
ǰ��:��������������һ��AB_path��·��,�õ�AB����,��ͨ����AB�ļ��÷ֱ�õ�A��B������,��A��B������ͬ��get_transform90����,���A��B�Ѿ����Ǹ��Ե�·��,���Ǹ��Ե�·��������ͬ�Ķ���AB_path��
����:���������ֱ�A��B��·��A_path��B_path,��Ҫע������Ҫȷ����������ȷ�ķ�Χ��,���������Щ��������̶���,��ͨ����Щ�����õ�A��B����,��A��B������ͬ��get_transform90����,���A��B�Ѿ����Ǹ��Ե�·��,���Ǹ��Ե�·���Dz�ͬ�ġ�
����ļ��о���˵������,�ܽ�һ��,��Ҫ�Ƕ�����һ�²������ݼ����ࡣ
�ļ���models
�����������Ŀ�ĺ��Ĵ���,������ոս��ܵ�dataһ��,������Ҳ��Ҫ�̳�BaseModelд���ַ�����
init_.py: ʵ�ְ���train��test�ű�֮��Ľӿڡ�train.py �� test.py ���ݸ����� opt ѡ��������������ݼ� from data import create_dataset��dataset = create_dataset(opt)
base_model.py:�̳��˳�����,Ҳ����һЩ�������õĺ���:setup,test,update_learning_rate,save_networks,load_networks,�������лᱻʹ�á��������һ��ģ����Ľӿ�,Ҫ��������,����Ҫʵ�������������:
�C<init>:��ʼ���ࡣ��Ҫ�����ĸ��б�:1.�Cself.loss_name(str list):ָ��Ҫ���ƺͱ����ѵ����ʧ��
2.�Cself.model_name(str list):ָ��Ҫ��ʾ�ͱ����ͼ��
3. --self.visual_name(str list):������ѵ��ʹ�õ����硣
4.�Cself.optimizers(�Ż����б�):����ͳ�ʼ���Ż���������Ϊÿ�����綨��һ���Ż�����
5.�Cself.image_paths(str list):����ͼƬ�Ĵ��·����
�C<modify_commandline_options>:(��ѡ)�����ض���ģ�͵�ѡ�����Ĭ��ѡ��,�������ĺ�Ľ�������
�C<set_input>:�����ݼ��н�ѹ�����ݲ�Ӧ��Ԥ������
�C:���������
�C<optimize_parameters>:������ġ��ݶȲ���������Ȩ�ء�
�������ֶ�����һЩ����:
1.setup(���غʹ�ӡ����;�������ȳ���):����ѵ��,����networks.py�е�get_scheduler�������Ż����е���;�������ѵ���ҵ�����������0,������load_suffix,��������������load_networks�������ظ�����,ѧϰ��˥����
2.eval(�����ڼ�ʹģ�ʹ�������ģʽ��):��ѭ�����ж��������ֵ������Ƿ�Ϊstr,�õ��������ֺ����eval()��
3.test(����ʱ����ʹ�õ�������,��������<compute\u visuals>,�����ɶ���Ŀ��ӻ������):ǰ����ʹ��with torch.no_grad():ǿ�Ʋ����м���ͼ�Ĺ�����
4.compute_visuals(����visdom��HTML���ӻ����������ͼ��):ֱ��һ��passĿ��ֻ��Ϊ�˷�ֹ����,�Ͼ���Щ���ú�������C����C++д�ġ�
5.get_image_paths(�������ڼ��ص�ǰ���ݵ�ͼ��·����)
6.update_learning_rate(��ÿ��epoc����ʱ����,�������������ѧϰ�ʡ�):��һ�������,scheduler.step()��Ҫ��optimizer.step()�ĺ������,��Ϊscheduler.step()������һ�������ǵ���ѧϰ��,�������scheduler.step(),���ı�optimizer�е�ѧϰ�ʡ�
7.get_current_visuals(���ؿ��ӻ�ͼ��train.py��ʹ��visdom��ʾ��Щͼ��,����ͼ�浽HTML��):����ʵ����һ��OrderedDict��,ʹ��OrderedDict����ݷ���Ԫ�ص��Ⱥ�˳���������,���������ֵ���ź���ġ�������ѭ�����ж����ͷ��ض���
8.get_current_losses(����ѵ����ʧ/����train.py���ڿ���̨�ϴ�ӡ��Щ����,�������DZ��浽�ļ��С�)ͬ�ϡ�
9.save_networks(���������籣�浽���̡�)ͬ��������ѭ�����ж����͵õ�����,�ж�cuda��װû��GPU�Ƿ����,Ȼ�档
10.__patch_instance_norm_state_dict(��InstanceForm���㲻����(0.4֮ǰ�İ汾)��)
11.load_networks(�Ӵ��̼����������硣)ͬ����ѭ�����ж����͵õ��ļ������ļ�·��,��������������epoch�㹻���ʱ��,ʹ��nn.DataParallel�������ö��GPU������ѵ��ͬʱ������̻Ὣkeyֵ��һ��module,Ȼ��һ���µĶ���,��torch.load()���ļ��м���һ����torch.save()����Ķ���,�����hasattr() ���������ж϶����Ƿ������Ӧ������,��ʱ�Ϳ�����load_state_dict()�������ոռ����˵�ģ��load����һ������ģ�͡�
12.print_networks(��ӡ�����(�����ϸ)������ϵ�ṹ�еIJ���������)
13.set_requires_grad(Ϊ������������requires_grad=Fasle,�Ա��ⲻ��Ҫ�ļ��㡣)���ж������Ƿ�Ϊ�б�,���������ת���б���
template_model.py: ʵ���Լ�ģ�͵�һ��ģ��,����ע����һЩϸ�ڡ���ʵ����һ���Ļ��ڻع���ʧ��ͼ��ͼ���ת�����ߡ���������-�����(����A������B),��ѧϰһ��������С������L1��ʧ������netG:
<modify_commandline_options>:��������д��ģ�͵�Ĭ��ֵ������,��ģ��ͨ��ʹ�ö�������ݼ���Ϊ�����ݼ��������ѵ���Ļ�Ҳ����Ϊ��ģ�Ͷ����²�����
<init>: ��ʼ��ģ��,����һЩ��ʧ����loss_G,ͼƬ�������֡�data_A��, ��data_B��, ��output��,��������G,�Ż���Adam�ȡ�
<set_input>:�����Զ�����<model.setup>��������ȳ���������ʹ�ӡ����,��dataloader�н�ѹ���������ݲ�ִ�б�Ҫ��Ԥ�������衣ʹ�ý�������A������B��
: ������A����G������һ��ǰ����
: ������ʧ������
<optimize_parameters>: ����G�����Ȩ�ز���
pix2pix_model.py:ʵ����pix2pix ģ��,�����ڸ����ɶ����ݵ������ѧϰ������ͼ�����ͼ���ӳ�䡣ģ��ѵ����Ҫ�����ݼ��ǨCdataset_mode aligned��Ĭ�������������netG����u-net256,���б���netD����basic�б���(PatchGAN)����ʧ���� vanillaGAN loss (ԭʼ������ʹ�õ��DZ�������)�����������̳���BaseModel,����BaseModel�ж��������������϶���Ҫʵ�ֵġ�
�C<modify_commandline_options>:�����ض���ģ�͵�ѡ�����Ĭ��ѡ��,�������ĺ�Ľ�����������IJ����ǽ�������ѵ��״̬,����Ĭ��ֵ������һЩ������
�C<init>:��ʼ��pix2pix�ࡣ��Ҫ�����ĸ��б�:1.�Cself.loss_name(str list):ָ��Ҫ���ƺͱ����ѵ����ʧ,��Щ��ʧҪ��ӡ������ ���ǡ�G_GAN��, ��G_L1��, ��D_real��, ��D_fake��
2.�Cself.model_name(str list):ָ��Ҫ��ʾ�ͱ����ͼ��real_A��, ��fake_B��, ��real_B����
3. --self.visual_name(str list):������ѵ��ʹ�õ�ģ�͵����֡�G��, ��D���� ���ﶨ���netG���� ��netDҪ������networks.py���define_G������define_D����,��Ϊ������GAN,����Ҫͬʱ��ȡ��������ͼ��opt.input_nc + opt.output_nc��Ϊ��������������input_nc��
4.�Cself.optimizers(�Ż����б�):����ͳ�ʼ���Ż���������Ϊÿ�����綨��һ���Ż�����
�C<set_input>:�����ݼ��н�ѹ�����ݲ�Ӧ��Ԥ������direction�����ڽ�����A����B�е�ͼ��
�C:�����м�����real_A����G����õ�fake_B��
�C<backward_D>:�����б�������ʧ������֮ǰ������CGAN,��ʵ����real_A�����������ɵļ�����fake_B�ͱ�ǩ1ͨ��cat������ͬ��Ϊ�б���������fake_AB,fake_AB����һ���б���������detach������D����õ�pred_fakeֵ,�����Ԥ��ֵpred_fake�ͼٱ�ǩFalse������ʧ�����õ������ݼٱ�ǩ����ʧֵloss_D_fake��ͬ��,��ʵ����real_A����ʵ����real_B�ͱ�ǩ1ͨ��cat������ͬ��Ϊ�б���������real_AB,real_AB����һ���б�����������ʱ����Ҫdetach�˴���D����õ�pred_realֵ,�����Ԥ��ֵpred_real�ͼٱ�ǩTrue������ʧ�����õ������ݼٱ�ǩ����ʧֵloss_D_fake����������������ʧֵ��ƽ���������ɡ�
�C<backward_G>:��������������ʧ������������Ҫƭ���б���,ͬ��һģһ����ԭ���õ���pred_fake�����ǩTrue������ʧ�����õ�һ����ʧֵloss_G_GAN,��Ҫ���ǻ���һ����ʧֵ��Ϊ���������ɵļٰ���fake_B����ʵ�İ���real_BҪ�����ܵ�һ��,����L1�������ܵõ�һ����ʧֵloss_G_L1,ͬ����������ʧֵ��ӵõ�������ʧֵ,�ٷ�����
�C<optimize_parameters>:������ġ��ݶȲ���������Ȩ�ء�����֪��G(A)=fake_B,����һ��ǰ��,�ٷֱ����D�����G����IJ�����
colorization_model.py:�̳���pix2pix_model,ģ����������:���ڰ�ͼƬӳ��Ϊ��ɫͼƬ��������ʵ�ֵ��ĸ�����:
�C<modify_commandline_options>:�������������
�C<init>:���ڿ��ӻ�,���ǽ���visual_names������Ϊ��real_A��(������ʵͼ��,����),��real_B_rgb��(��ʵrgbͼ��)��fake_B_rgb��(Ԥ��rgbͼ��),���ǽ���real_B��(��Pix2pixModel�̳�)ת��ΪRGBͼ��real_B_RGB��,���ǽ���fake_B��(��Pix2pixModel�̳�)ת��ΪRGBͼ��fake_B_RGB����������Ҫ����һ���б�,�б��е�������ָ�����ӻ�ͼ������ơ�
�C:��Ҫ�ǽ�tensor���͵�ͼƬת����RGB numpy���͵������
��ͨ����tensor����: L (1-channel tensor array): L channel images (range: [-1, 1], torch tensor array)
˫ͨ����tensor����: AB (2-channel tensor array): ab channel images (range: [-1, 1], torch tensor array)
����ֵ��һ��RGB���ͼ��,������һ��numpy array���͵ġ�
�C<compute_visuals>:�������ͼ��__init__�����е�fake_B_rgb��real_B_rgb������,ͨ��lab2rgb������real_A��real_Bת����RGB���͵�ͼƬ��
cycle_gan_model.py:��ʵ��cycleganģ�͡�����ѧϰͼ��ͼ���ת��Ҳ��ͼ����,����ɶ����ݡ�����ģ��ѵ����Ҫ���Cdataset_mode unaligned�����ݼ���Ĭ�������,��ʹ�á��CnetG resnet_9blocks��resnet������,���CnetD basic��������(��pix2pix�����PatchGAN),��һ����С����GANsĿ��(���Cgan_ģʽlsgan��)������ͬ���̳�BaseModel,һ������9�����������������һ���ؼ���,���dz���GAN����������Ҫ����ʧ����֮��,���ǻ���������µ���ʧ����lambda_A, lambda_B, and lambda_identity����ͼ����һ�ε���һ��:A (source domain), B (target domain).
Generators: G_A: A -> B; G_B: B -> A.(������ȫ��ͬ��������,ֻ�����벻ͬ)
Discriminators: D_A: G_A(A) vs. B; D_B: G_B(B) vs. A. (�������)
Forward cycle loss: lambda_A * ||G_B(G_A(A)) - A|| (Eqn. (2) in the paper)
Backward cycle loss: lambda_B * ||G_A(G_B(B)) - B|| (Eqn. (2) in the paper)
Identity loss (optional): lambda_identity * (||G_A(B) - B|| * lambda_B + ||G_B(A) - A|| * lambda_A) (Sec 5.2 ��Photo generation from paintings�� in the paper)
����ͨ��CycleGAN������Dropout�������á�
�C<modify_commandline_options>:�����ڽ����������ò�ʹ��ʧ��no_dropout=True,Ȼ����������������¼����������ʧ�����ĸ��������
�C<init>:��ʼ��:1.ָ��������ʧ����������loss_names��һ���б���[��D_A��, ��G_A��, ��cycle_A��, ��idt_A��, ��D_B��, ��G_B��, ��cycle_B��, ��idt_B��], ���а˸���ʧ������
2.ָ���������ݵ�����visual_names_A��visual_names_B�ֱ�ͬ���б���[��real_A��, ��fake_B��, ��rec_A��]��[��real_B��, ��fake_A��, ��rec_B��]�����lambda_identity�Ѿ���ʹ���˵Ļ�,�������б�������������ʧ����������idt_B��idt_A��ѵ�������л��õ���G_A��, ��G_B��, ��D_A��, ��D_B�����ĸ���ʧ����,���Խ�ֻ���õ���G_A��, ��G_B����
3.ͨ��define_G������define_D�����ֱ���������������������б������硣
4.����һ�������������м����ɵļ�ͼƬ��
5.������ʧ����:MSELoss�������pixcel,��ӳͼ���G_A��G_B�ٵ���ԭ�����ͼ������Ƴ̶ȡ�
L1Loss���ݾ���ֵ��������ԡ�
6.�����Ż�����
�C<set_input>:�����ݼ������н�ѹ���������ݲ�ִ�б�Ҫ��Ԥ�������衣
�C:ǰ���ܹ���Ϊ�IJ�:1.G_A(A)=G_A(real_A)=fake_B
2.G_B(G_A(A))=G_B(fake_B)=rec_A
3.G_B(B)=G_B(real_B)=fake_A
4.G_A(G_B(B))=G_A(fake_A)=rec_B
�C<backward_D_basic>:�������ֻҪ�����б�������ʧֵ,�������������,�ֱ���D���硢������(tensor)��������(tensor)���������ͺܳ�����,���������ǩ��������.detach()�ٱ�ǩ,��ʧֵ��ƽ��,������
�C<backward_D_A>:�ӻ�����еõ���fake_B(���ɳ����İ���)��real_B(��İ���),�Լ�D_A���籾������<backward_D_basic>������
�C<backward_D_B>:�ӻ�����еõ���fake_A(���ɳ�������)��real_A(�����),�Լ�D_B���籾������<backward_D_basic>������
�C<backward_G>:�����������������ɼ������Ի��б�����������ǰ������,���������G_A�в�����A,���Ƿ���B,�������Ľ������B������?���ǵ�,������֮��IJ�൱Ȼ��ԽСԽ��ඡ�
G_A(B)=G_A(real_B)=B
G_B(A)=G_B(real_A)=A
ͨ��������ʽ�ӻ������������������ʧֵ��
�����б���A�������������ĸ�����B,�ĸ��Ǽ�B;���б���B�������������ĸ�����A,�ĸ��Ǽ�A���������ǰѼ�B�����ǩ�����б���A,�Ѽ�A�����ǩ�����б���B�������ֻ�õ�������ʧֵ��
�����ĸ���ʧֵ��������������
�C<optimize_parameters>:�ݶȸ��µĹ���Ҳ��Ϊ����:ǰ��,�ٷ����б������ݶȲ����µ�ǰ����,�������������ݶ�;�����������б����ݶȡ�
networks.py:�������������б���������ܹ�,normalization layers,��ʼ������,�Ż����ṹ(learning rate policy)GAN��Ŀ�꺯��(vanilla,lsgan,wgangp)�� ��Ҫ��ʵ��һЩ��ͨ��ʵ�ֹ���,дһЩ�������������һ��ÿһ������������,���Ǿ����ʵ�ֹ��̲�����������
1.get_norm_layer(���ع�һ����һ��):functools.partial(����,����˺����IJ���)����װһ������,��ʵ��Ҫ���þ��Ǽ������߰�������Ĵ��ݡ�
2.get_scheduler(����һ��ѧϰ�ʵļ�ʱ��):���ѧϰ�ʵ��Ż����������Ե�,���ڵ�һ�����ڱ�����ͬ��ѧϰ��,���ڽ������������ֶ�ʵ������˥�����������������Ż����Ի����ǵ�����(��Ծstep��ƽ��plateau������cosine)�͵�PytorchĬ�ϵĺ�����
3.init_weights(��ʼ������Ȩ��):hasattr()���������ж϶����Ƿ������Ӧ������,���жϴ��뺯����m�����Ƿ���Ȩ�غ�ƫ������Щ����,Ȼ��ѡ���Ӧ�ij�ʼ�����͡�
4.init_net(��ʼ������):����ܶ�GPU���С�
5.define_G(����һ��������):���ǵ�ǰ��ʵ���ṩ���������͵�������(ÿ�����ͷֱ�������������):
1.U-Net:[unet_128](����128x128����ͼ��)��[unet_256](����256x256����ͼ��)
2.����Resnet��������:[Resnet_6��](����6��Resnet��)��[Resnet_9��](����9��Resnet��)
����Resnet���������ɼ����²���/�ϲ�������֮��ļ���Resnet����ɡ�����������<init\u net>��ʼ������ʹ��RELUʵ�ַ����ԡ�
6.define_D(����һ���б���):��ǰ��ʵ���ṩ���������͵ļ�����:
1.[basic]:Ĭ��PatchGAN������,����������70��70�ص��߿������Ǽ�,������Ƭ���б����ṹ���н��ٵIJ���,��һ��������ͼ�������,��������ȫ�����ķ�ʽ�����������С��ͼ��
2.[n_layers]:ʹ�ô�ģʽ,��ԭ���Ļ��������˸��������,�������б�����ָ��conv�������(��[basic](PatchGAN)��ʹ�õ�Ĭ��ֵΪ3)��
3.[pixel]:ÿһ�����ط���,���Ծ���1x1 PixelGAN�������ɶ������Ƿ���ʵ���з��ࡣ�������������ɫ������,���Կռ�ͳ��û��Ӱ�졣
�б�������<init\u net>��ʼ������ʹ��й©RELUʵ�ַ����ԡ�
7.����һ����GANLoss,��������ж�����һЩ����: 1.init:��ʼ��һЩ��ʧ������
2.get_target_tensor:�����������ǩ��ͬ�ı�ǩ����, ���ǰѴ���ı�ǩת����tensor�ĸ�ʽ,��ͨ��expand_as�����tensorת���ɺ�Ԥ��ֵһ������״��
3.call:�����б����������ʵ��ǩ����ʧ��
8.cal_gradient_penalty:�����ݶȳͷ���ʧ��
9.����һ����ResnetGenerator,����Resnet��������,�ɼ����²���/�ϲ�������֮���Resnet�����:
1.init:����һ������Resnet����������assert()��������������������������������ִֹ��,����һ��������ģ��,Ȼ��Ϊģ�����������²�����,������ResNet��,�����Ӽ����ϲ����㡣
2.forward:ǰ����
10.����һ����ResnetBlock,��������Resnet�顣��в�����һ��,resnet���Ǿ����������ӵ�conv��,������build_conv_block��������һ��conv��,���ڹ�����ʵ����Խ����: 1.build_conv_block:ͨ���ж�padding���ͺ��Ƿ�ʹ��dropout����*conv_block��
2.forward:������Ծ����out = x + self.conv_block(x)��
11.����һ����UnetGenerator,����һ������U-net��������,ͨ��������Ҫ�����UnetSkipConnectionBlock��,����unet�ṹ,ʹ��ngf8�����������м��(ngfΪ���ľ������й�����������),��������������ngf8���ٵ�ngf��
12.����һ����UnetSkipConnectionBlock,���������Ծ���ӵ�U-net��ģ��,��ģ���������Ϊ�²����Ľ�������ϲ����Ļ�����
13.����һ����NLayerDiscriminator,����һ��PatchGAN���б���,���һͨ�����б�����
14.����һ����PixelDiscriminator,����һ��1*1��PatchGAN���б�����
test_model.py:�˲���ģ�Ϳ����ڽ�Ϊһ����������CycleGAN�������ģ�ͽ��Զ����á��Cdataset_mode single��,������һ�����ϼ���ͼ��
�ļ���options
����ѵ��ģ��,����ģ�������TrainOptions��TestOptions���� BaseOptions�����ࡣ��ϸ˵��options�µ��ļ���
base_options.py:��������������в���,һ��ѵ���Ͳ��Զ���Ҫ����ֵ����������в�����ඨ��������ļ�����,�����ݼ���·���ȡ�,����training,test���õ���option,����һЩ��������:parsing,printing,saving options,������ӡ�ͱ���ѡ�
�C<init>:������;��ʾ������δ��ʼ����
�C:�ڽ�����������һЩ����������ģ�Ͳ��������ݼ���������������ȡ�
�C<gather_options>:�������ij�ʼ��,���жϽ������Ƿ�ʼ����,���û�б���ʼ���͵�����һ�������ѽ���������ȥ��ʼ��һ��,Ȼ��ͨ����������ȡһЩ����,����ģ�ͺ����ݼ���صĽ�����ѡ��,��档
�C<print_options>:������ӡ��ǰѡ���Ĭ��ֵ(�����ͬ)����������ѡ��浽txt�С�
�C:�������ǵ�ѡ��,��������Ŀ¼��suffix,������gpu�豸��
train_options.py:ѵ����Ҫ��options��
test_options.py:������Ҫ��options��
�ļ���util
��Ҫ����һЩ���õĹ�����,�����ݵĿ��ӻ�����ϸ˵��utils�µ��ļ�:
get_data.py:�����������ݼ��Ľű���
���ȶ���һ��GetData����:1.�C<init>:��ʼ��pix2pix��cyclegan��Դ�ĵ�ַ��
2.�C<_get_options>:ͨ��BeautifulSoup����ҳ��ץȡ����,��find_all()������������ֵȡ�����һ���б�,��ͨ��text.endswith�����ж��б�����ѹ���ļ�����Ϊ��β���ַ�����
3���C<_present_options>:ͨ��r=request.get(url)����һ���������������Դ��url����
4���C<_download_data>:ʶ���ļ�����,����ѹ������·�����뺯��extractall()��ѹ��
5.�C:�������ݼ�������·����
html.py:����ͼƬд��html������diminate�е�DOM API����HTML���������ǽ�ͼ����ı����浽����HTML�ļ��С�����������<add_header>(��HTML�ļ������ı�ͷ)�ȹ���,<add_images>(��һ��ͼ�����ӵ�HTML�ļ�)��(��HTML���浽����)��
������Python�⡰dominate��,һ��ʹ��DOM API�����Ͳ���HTML�ĵ���Python��:
1.�C<init>:��ʼ��HTML�ࡣ
2.�C<get_image_dir>:���ش洢ͼ���Ŀ¼��
3.�C<add_header>:��HTML�ļ��в���ͷ��
4.�C<add_images>:��HTML�ļ��в���ͼƬ��
5.�C:��������HTML�ļ������ݡ�
image_pool.py:����ʵ����һ���洢֮ǰ���ɵ�ͼ���ͼ����,�û�����ʹ�����ܹ�ʹ������ͼ�����ʷ�����б�������ʹ��unsqueeze()����ͼƬ���ݵ�ά��,0��������չ,1��������չ,��������һֱ����(ͼƬ����С�ڻ�������С),��һֱ���ֲ���ͼƬ���ݡ������ͼƬ�������ڻ�������С,����һ��������ɵĸ���ֵ,�аٷ�֮50�ļ���,Ҳ���ǰ�ͼƬ���ݷֳ�������,�����֮ǰ������б������ӡ�
visualizer.py:����ͼƬ,չʾͼƬ:
1.�C<save_images>:�ȸ���·����ȡ�ļ���ntpath.basename(),����os.path.splitext()���ļ�������չ���ֿ�,ֻȡ����ĵ�һ��ȡ�ļ���,Ϊ��ҳ����һЩͷ����Ϣ������һЩ�б�,����util.py�е�save_image����,����һЩ��Ϣ���ӵ��б��С�
����һ����Visualizer,������������������ʾ/����ͼ��ʹ�ӡ/������־��Ϣ�ĺ�������ʹ��Python�⡰visdom��������ʾ,ʹ��Python�⡰dominate��(��װΪ��HTML��)��������ͼ���HTML�ļ�:
1.�C<init>:����ʼ�����ӻ�������:1.������ѵ/����ѡ�2.���ӵ�visdom��������3.�������ڱ���HTMLɸѡ����HTML����4.������־�ļ��Դ洢��ѵ��ʧ��
2.�C<reset_>:�������ұ����״̬��
3.�C<create_visdom_connections>:������������ӵ�Visdom������,�˺������ڶ˿�<self.port>�������·�������
4.�C<display_current_results>:��visdom����ʾ��ǰ���;����ǰ������浽HTML�ļ���
5.�C<plot_current_losses>:��visdom��ʾ������ʾ��ǰ��ʧ:�����ǩ��ֵ�ֵ䡣
6.�C<print_current_losses>:�ڿ���̨��ӡ���ڵ���ʧ�����浽���̡�
utils.py:����һЩ��������:tensor2numpyת��,mkdir,��������ݶȵ�:
1.�C:��tensor����ת��Ϊnumpy���͡�
2���C:���㲢��ӡ�����ݶȵ�ƽ��ֵ��
3���C<save_image>:��numpy���͵�ͼ�浽�����С�
4���C<print_numpy>:��ӡnumpy�����ƽ��ֵ����Сֵ�����ֵ����ֵ����ֵ�ʹ�С��
5���C:���·�������ھʹ����յ�Ŀ¼��
6���C:���·�������ھʹ�����һ�Ŀ�Ŀ¼��
train.py
�ص�:�˽ű������ڸ���ģ��,֧�ֲ�ͬ��ģ��(����ѡ�-model��:����,pix2pix��cyclegan����ɫ��)��֧�ֲ�ͬ�����ݼ�ģʽ(����ѡ�-dataset_mode��:����,���롢δ���롢��һ����ɫ)����Ҫָ�����ݼ�(���Cdataroot��)��ʵ������(���Cname��)��ģ��(���Cmodel��)���������ڸ���ѡ�������´���ģ�͡����ݼ��Ϳ��ӻ����ߡ�Ȼ����б���������ѵ������ѵ�ڼ�,�������Կ��ӻ�/����ͼ��ӡ/������ʧͼ�ͱ���ģ�͡�
֧�ּ���/��ͣѵ����ʹ�á��Ccontinue_train���ָ���ǰ����ѵ��
import time
from options.train_options import TrainOptions #����,��Ȼ�ǵ���,���ﵼ��ѵ������,���û��д__init__.py�ļ��ᱨ��Ŷ
from data import create_dataset
from models import create_model
from util.visualizer import Visualizer
#�������cycleGan,��Ҫ��������ʧ����������,g�����d�������ʧ�����Ƚϼ�,�ؼ���cycle:��Ϊ֮ǰ����������ջ�ԭ�����Ҫ����������ص�ıȽ�(ÿ�����ص�֮���ֵ����ƽ������ϲ�����),����һ��ӳ��identity��ʧ����,
#��Ϊ������Ҫ����һ���ٵ�,����һ��ӳ�����ʧ,�ٰ�����ٵ��ٴδ���������,��ʱҪһģһ��,������ͼ��֮��IJ���ҪԽСԽ��
#��cycleGAN����,�б�������Щ����ͬ,�б������þ�������õ�������,����������������sigmoid�������洫,Ҳ������ʲôȫ���Ӳ�,����һ������ͼ,��ʱ�������ͼ�е�ÿһ�������ԭʼ����Ұ��һ������patch(�������ʵͼ��,��ǩ����������һ����,ÿһ������patch���б�����������1�Ŵﵽ����)
#����patchGAN�����þ��Dz������һ��sigmoidֵ,���ǵõ�һ������ͼ,�������ͼÿһ��λ�ö�����һ��С����,�����ǩ��ʱ������Ǻͱ�ǩһ���ľ���,Ȼ��ͨ����ǩ�ľ��������ͼ�Ƚ�
#���patch�����б�����ӵ�һ������
if __name__ == '__main__':
opt = TrainOptions().parse() # get training options �õ�ѵ����ѡ��opt
dataset = create_dataset(opt) # create a dataset given opt.dataset_mode and other options ����opt�õ����ݼ�dataset
dataset_size = len(dataset) # get the number of images in the dataset. �������ݼ��õ����ݼ�ͼƬ������
print('The number of training images = %d' % dataset_size)
model = create_model(opt) # create a model given opt.model and other options ����opt�õ�ģ��model
model.setup(opt) # regular setup: load and print networks; create schedulers ����opt����ģ������
visualizer = Visualizer(opt) # create a visualizer that display/save images and plots ����opt����һ�����ӻ�����visualizer
total_iters = 0 # the total number of training iterations ѵ������������
for epoch in range(opt.epoch_count, opt.niter + opt.niter_decay + 1): # outer loop for different epochs; we save the model by <epoch_count>, <epoch_count>+<save_latest_freq> ѭ����opt.epoch_count��ʼ,��opt.niter + opt.niter_decay����(Ϊ�˼����ϴε�ѵ��)
epoch_start_time = time.time() # timer for entire epoch ��ʼ��ʱ
iter_data_time = time.time() # timer for data loading per iteration ��ʱÿһ�ε������ص�����
epoch_iter = 0 # the number of training iterations in current epoch, reset to 0 every epoch ÿһ�����ڵ�����������Ϊ0
visualizer.reset() # reset the visualizer: make sure it saves the results to HTML at least once every epoch ���ÿ��ӻ�����:ȷ��������ÿһ�ν��������ΪHTML
for i, data in enumerate(dataset): # inner loop within one epoch
iter_start_time = time.time() # timer for computation per iteration ÿ�ε�������ļ�ʱ��
if total_iters % opt.print_freq == 0:
t_data = iter_start_time - iter_data_time
total_iters += opt.batch_size #�Ѿ������˵�����
epoch_iter += opt.batch_size #ÿ�����ڵĵ�����
model.set_input(data) # unpack data from dataset and apply preprocessing ��ѹ���ݲ���Ԥ����
model.optimize_parameters() # calculate loss functions, get gradients, update network weights ����Ȩ��
if total_iters % opt.display_freq == 0: # display images on visdom and save images to a HTML file չʾͼƬ������ͼƬ��html�ļ���
save_result = total_iters % opt.update_html_freq == 0
model.compute_visuals()
visualizer.display_current_results(model.get_current_visuals(), epoch, save_result)
if total_iters % opt.print_freq == 0: # print training losses and save logging information to the disk ��ӡѵ����ʧ�����浽����
losses = model.get_current_losses()
t_comp = (time.time() - iter_start_time) / opt.batch_size
visualizer.print_current_losses(epoch, epoch_iter, losses, t_comp, t_data)
if opt.display_id > 0:
visualizer.plot_current_losses(epoch, float(epoch_iter) / dataset_size, losses)
if total_iters % opt.save_latest_freq == 0: # cache our latest model every <save_latest_freq> iterations
print('saving the latest model (epoch %d, total_iters %d)' % (epoch, total_iters))
save_suffix = 'iter_%d' % total_iters if opt.save_by_iter else 'latest'
model.save_networks(save_suffix)
iter_data_time = time.time()
if epoch % opt.save_epoch_freq == 0: # cache our model every <save_epoch_freq> epochs
print('saving the model at the end of epoch %d, iters %d' % (epoch, total_iters))
model.save_networks('latest')
model.save_networks(epoch)
print('End of epoch %d / %d \t Time Taken: %d sec' % (epoch, opt.niter + opt.niter_decay, time.time() - epoch_start_time))
model.update_learning_rate() # update learning rates at the end of every epoch.
����ṹ:options.train_options.TrainOptions().parse()
ѵ��ʱ�����ֶ����������ѡ���
����ֵparse:�����IJ���:
1.��baseoptions�Ļ�����,��baseoptions��IJ�������
2. ���ӻ�����
��ʾƵ��
���ӻ�visdom��һЩ��������ҳ�IJ���
��ӡƵ��
3.���籣��ͼ��ز���
��������ģ�͵���iter����Ƶ��
��epoch��ΪƵ�ʱ���ģ��
�Ƿ���iterationΪƵ�ʱ���
�Ƿ�����ϴ�ѵ��
����ѵ��,�Ӷ���epoch��ʼ
4.ѵ������
ѧϰ��Ϊ0��iter��
lr��ʼ��ѧϰ��
gan��ģʽ��ѡ
�ػ����size
ѧϰ��˥������
ѧϰ��ÿ���ٸ�iter����gamma
test.py
train.py���л����ǰ���ͷ�����,��test.pyģ�ͽ�������ǰ��������ͼ��ͼ�����ͨ�ò��Խű���
ʹ��train.pyѵ��ģ�ͺ�,����ʹ�ô˽ű�����ģ�͡������ӨCcheckpoints\u dir���ر����ģ��,����������浽�Cresults\u dir��
�������ڸ���ѡ�������´���ģ�ͺ����ݼ�������Ӳ����һЩ������
Ȼ��ԨCnum_����ͼ�������ƶ�,����������浽HTML�ļ��С�
����pix2pixģ��:
if __name__ == '__main__':
opt = TestOptions().parse() # ��ȡ���Բ���
# Ӳ����һЩ���Բ���
opt.num_threads = 0 # ���Դ����֧��num_threads=1
opt.batch_size = 1 # ���Դ����֧�� batch_size = 1
opt.serial_batches = True # �������ݴ���; �����Ҫ���ѡ��ͼ��Ľ��,��Դ��н���ע�͡�
opt.no_flip = True # ����ת;�����Ҫ��תͼ��Ľ��,��Դ��н���ע�͡�
opt.display_id = -1 #���Ӿ���ʾ;���Դ��뽫������浽HTML�ļ��С�
dataset = create_dataset(opt) # ʹ��opt.dataset_ģʽ������ѡ������ݼ�
model = create_model(opt) # ����opt.model������ѡ���ģ��
model.setup(opt) # ��������:���غʹ�ӡ����;�������ȳ���
# ������վ
web_dir = os.path.join(opt.results_dir, opt.name, '{}_{}'.format(opt.phase, opt.epoch)) #������վ����
if opt.load_iter > 0: # Ĭ�������,load_iterΪ0
web_dir = '{:s}_iter{:d}'.format(web_dir, opt.load_iter)
print('creating web directory', web_dir)
webpage = html.HTML(web_dir, 'Experiment = %s, Phase = %s, Epoch = %s' % (opt.name, opt.phase, opt.epoch))
# ʹ������ģʽ���в��ԡ���ֻӰ��batchnorm��dropout�Ȳ㡣
# ����[pix2pix]:������ԭʼpix2pix��ʹ��batchnorm��dropout��������ʹ��eval()ģʽ�Ͳ�ʹ��eval()ģʽ�������顣
# ����[CycleGAN]:����Ӧ��Ӱ��CycleGAN,��ΪCycleGANʹ��instancenorm��û���˳���
if opt.eval:
model.eval()
for i, data in enumerate(dataset):
if i >= opt.num_test: # �������ǵ�ģ��Ӧ����opt.num_����ͼ��apply our model to opt.num_test images.
break
model.set_input(data) # �����ݼ������������
model.test() # ��������
visuals = model.get_current_visuals() # ��ȡͼ����
img_path = model.get_image_paths() # ��ȡͼ��·��
if i % 5 == 0: # ��ͼ�浽HTML�ļ�
print('processing (%04d)-th image... %s' % (i, img_path))
save_images(webpage, visuals, img_path, aspect_ratio=opt.aspect_ratio, width=opt.display_winsize)
webpage.save() # save the HTML
��������ʵ��̫����,��Ŀ�����ҷ����´Ρ�