1. 引言
作为自然语言处理方向的研究人员,我们称ACL,EMNLP,NAACL和COLING为自然语言处理领域的国际顶级会议(也有人说只有第一个称为顶级会议,其他的都只能是重要会议),尽管CCF协会里也已经给出了四个会议的等级,其中ACL为A类,EMNLP和COLING为B类,NAACL为C类,看起来好像是ACL>EMNLP≈COLING>NAACL。在知乎上讨论的结果是ACL>NAACL≈EMNLP>COLING。
那么通过实验的结果证明如何呢?利用我们自身的NLP的工具,我们通过常用的预训练模型XLNet分析了最近三年的各个顶会的论文摘要,从一个实验的角度来看看它们之间的差异。
2. 任务定义
为了看出各个会议上论文的差异,我们提取了ACL2019-2021,EMNLP2019-2020,NAACL2019-2021和COLING2018-2020中的全部主会论文作为主要研究数据,并使用了CCL2020-2021的数据作为区分数据,研究的对象为各个论文的摘要。
我们想做的,就是通过XLNet模型预测各个论文的摘要的会议归属情况。
3. 实验设置
我们使用的XLNet模型为XLNet-base的分类模型,batch-size=8,ephoch=5,learning-rate=1e-5。随机抽取10%的数据作为测试集,即训练集与测试集为9:1。
4. 实验结果
实验结果如图所示:
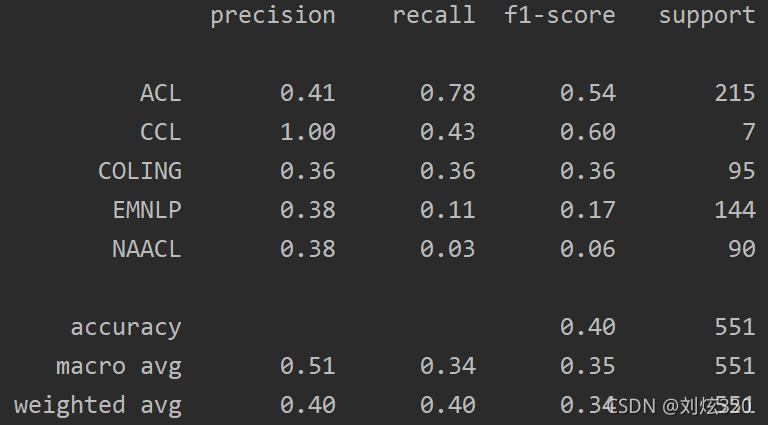
可以看到其性能并不是特别好,整体ACC只有40%,宏F1只有35%.其中对于CCL的识别最好,ACL的识别次之,CLONG的识别再次之。这应该说明这三类是最容易区分的类别。那么错误究竟发生在哪呢?我们对于混淆矩阵进行了进一步的分析。
5. 实验分析
混淆矩阵如下图所示,图中的数字被正则化为百分比,同一行中各个数字之和为100%。
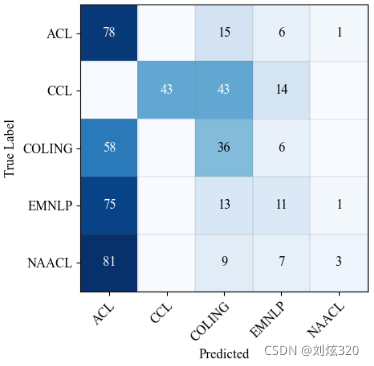
对于这张图我们可以看到这样三个结论:
- 作为大家公认的老大哥ACL和公认的小老弟CCL,两个人之间存在着不可逾越的鸿沟,即使在正确率仅为40%的情况下,两个会议的论文竟然没有1篇混淆的,可以看出两个会议之间的差异非常的巨大。
- 真实结果与知乎上的讨论应该是一致的,从第一列的结果可以看出,NAACL最像ACL,EMNLP次之,COLING最低。
- CCL与COLING更像,但是与EMNLP还有联系,但是与NAACL就没有任何交集,这应该和作者的归属有关。
6. 总结
因此,通过本文的实验,最终结论是各个顶会是有差异的,与ACL的相似程度依次为NAACL,EMNLP,COLING,CCL,论文的质量应该也是这个顺序。然而,目前的数据并不能排除是作者归属地的撰写论文习惯或者是论文主题对于论文质量产生了影响,而且目前准确率太低,在接下来的工作中将会考虑如何提高准确率。