特征工程
1、特征提取:从文字,图像,声音等其他非结构化数据中提取新信息作为特征。
2、特征创造:把现有特征进行组合,或互相计算,得到新的特征。
3、特征选择:从所有的特征中,选择出有意义,对模型有帮
助的特征,以避免必须将所有特征都导入模型
去训练的情况。
在做特征选择之前一定要先跟数据提供者交流,所以特征选择的第一步,其实是根据我们的目标,用业务常识来选择特征。
特征工程的第一步是理解业务。
当所遇到的情况和数据无法通过业务理解来进行特征选择。
则可以通过四种方法进行特征选择:
1.过滤法(Filter)
过滤方法通常用作预处理步骤,特征选择完全独立于任何机器学习算法。它是根据各种统计检验中的分数以及相关性的各项指标来选择特征。
全部特征――>最佳特征集――>算法――>模型评估
最近邻算法KNN,单棵决策树,支持向量机SVM,神经网络,回归算法,都需要遍历特征或升维来进行运算,所以他们本身的运算量就很大,需要的时间就很长,因此方差过滤这样的特征选择对他们来说就尤为重要。但对于不需要遍历特征的算法,比如随机森林,它随机选取特征进行分枝,本身运算就非常快速,因此特征选择对它来说效果平平。这其实很容易理解,无论过滤法如何降低特征的数量,随机森林也只会选取固定数量的特征来建模;而最近邻算法就不同了,特征越少,距离计算的维度就越少,模型明显会随着特征的减少变得轻量。因此,过滤法的主要对象是:需要遍历特征或升维的算法们,而过滤法的主要目的是:在维持算法表现的前提下,帮助算法们降低计算成本
方差过滤的影响总结如下:

2.相关性过滤
方差挑选完毕之后,我们就要考虑下一个问题:相关性了。
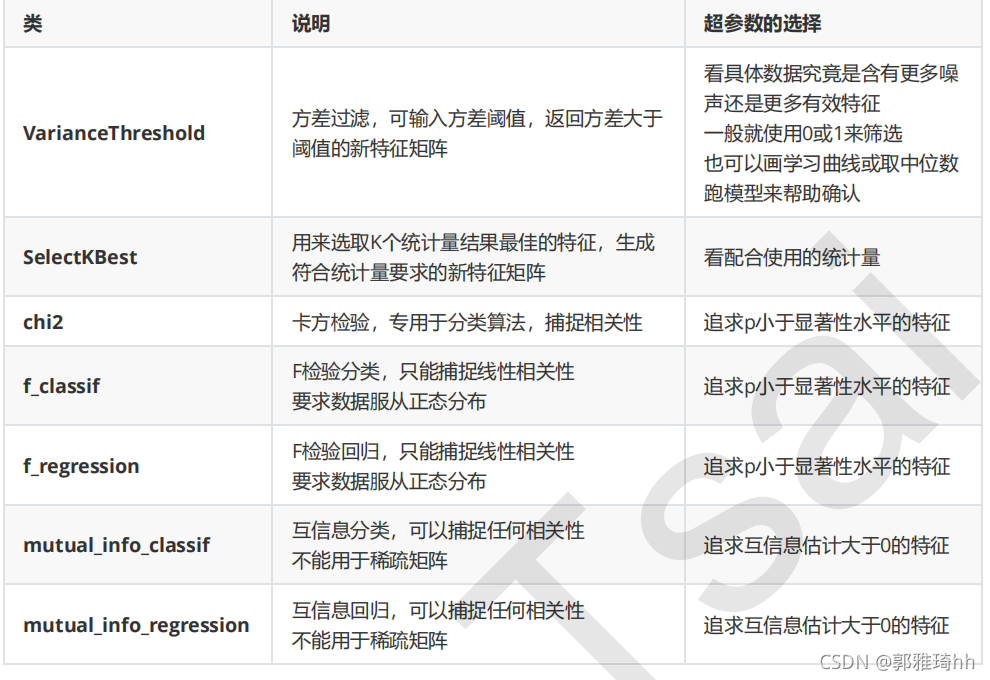
我们希望选出与标签相关且有意义的特征,因为这样的特征能够为我们提供大量信息。如果特征与标签无关,那只会白白浪费我们的计算内存,可能还会给模型带来噪音。在sklearn当中,我们有三种常用的方法来评判特征与标签之间的相关性:卡方,F检验,互信息。
(1)卡方过滤:卡方过滤是专门针对分类问题的相关性过滤。
卡方检验类feature_selection.chi2计算每个非负特征和标签之间的卡方统计量,并依照卡方统计量由高到低为特征排名。再结合这个可以输入“评分标准”来选出前K个分数最高的特征的类,我们可以借此除去最可能独立于标签,与我们分类目的无关的特征。
另外,如果卡方检验检测到某个特征中所有的值都相同,会提示我们使用方差先进行方差过滤。
(2)选取超参数K:,可通过学习曲线得知。卡方检验的本质是推测两组数据之间的差异,其检验的原假设是”两组数据是相互独立的”。卡方检验返回卡方值和P值两个统计量,其中卡方值很难界定有效的范围,而p值,我们一般使用0.01或0.05作为显著性水平,即p值判断的边界,
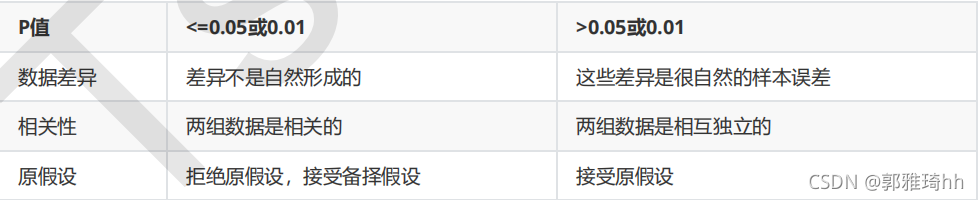
从特征工程的角度,我们希望选取卡方值很大,p值小于0.05的特征,即和标签是相关联的特征。
(3)F检验:又称ANOVA,方差齐性检验,**是用来捕捉每个特征与标签之间的线性关系的过滤方法。**它即可以做回归也可以做分类,因此包含feature_selection.f_classif(F检验分类)和feature_selection.f_regression(F检验回归)两个类。其中F检验分类用于标签是离散型变量的数据,而F检验回归用于标签是连续型变量的数据。
(4)互信息法:互信息法是用来捕捉每个特征与标签之间的任意关系(包括线性和非线性关系)的过滤方法。和F检验相似,它既可以做回归也可以做分类,并且包含两个类eature_selection.mutual_info_classif(互信息分类)和feature_selection.mutual_info_regression(互信息回归)。这两个类的用法和参数都和F检验一模一样,不过互信息法比F检验更加强大,F检验只能够找出线性关系,而互信息法可以找出任意关系。
过滤法总结
2.嵌入法
嵌入法是一种让算法自己决定使用哪些特征的方法,即特征选择和算法训练同时进行。在使用嵌入法时,我们先使用某些机器学习的算法和模型进行训练,得到各个特征的权值系数,根据权值系数从大到小选择特征。这些权值系数往往代表了特征对于模型的某种贡献或某种重要性,比如决策树和树的集成模型中的feature_importances_属性,可以列出各个特征对树的建立的贡献,我们就可以基于这种贡献的评估,找出对模型建立最有用的特征。因此
相比于过滤法,嵌入法的结果会更加精确到模型的效用本身,对于提高模型效力有更好的效果。并且,由于考虑特征对模型的贡献,因此无关的特征(需要相关性过滤的特征)和无区分度的特征(需要方差过滤的特征)都会因为缺乏对模型的贡献而被删除掉,可谓是过滤法的进化版。
3.包装法
包装法也是一个特征选择和算法训练同时进行的方法,与嵌入法十分相似,它也是依赖于算法自身的选择,比如coef_属性或feature_importances_属性来完成特征选择。但不同的是,我们往往使用一个目标函数作为黑盒来帮助我们选取特征,而不是自己输入某个评估指标或统计量的阈值。包装法在初始特征集上训练评估器,并且通过coef_属性或通feature_importances_属性获得每个特征的重要性。然后,从当前的一组特征中修剪最不重要的
特征。在修剪的集合上递归地重复该过程,直到最终到达所需数量的要选择的特征。区别于过滤法和嵌入法的一次训练解决所有问题,包装法要使用特征子集进行多次训练,因此它所需要的计算成本是最高的。
总结
经验来说,过滤法更快速,但更粗糙。包装法和嵌入法更精确,比较适合具体到算法去调整,但计算量比较大,运行时间长。当数据量很大的时候,优先使用方差过滤和互信息法调整,再上其他特征选择方法。使用逻辑回归时,优先使用嵌入法。使用支持向量机时,优先使用包装法。迷茫的时候,从过滤法走起,看具体数据具体分析。其实特征选择只是特征工程中的第一步。