����Ŀһ����Ϊ��������:
- esp32������Ƶ��������
- facenetʵ����Ƶ��������ʶ��
- ��esp32���������Ե���Ƶ������ʶ��
- ʶ���Ŀ�������,�����Զ�����
Ŀ¼
һ��esp32������Ƶ��
����facenetʵ����Ƶ������ʶ��
- ��������
- facenetԴ���ȡ
- ��װ������facenet����
- ����LFW���ݼ�
- ��LFW���ݼ�����Ԥ����
- ����ѵ���õ�����ģ��
- ����Ԥѵ��ģ�͵�ȷ��
- �����Ա�
- �ռ��Լ������ݼ�
- ѵ��������
- ��Ƶ��������ʶ��
������esp32���������Ե���Ƶ������ʶ��
�ġ�ʶ���ָ�������,��������
�塢��Ҫ����
һ��esp32������Ƶ�� {#1}
-
��������
���� ���� esp32-CAM(������ͷ) 1ö USBתTTLת��ͷ 1ö �Ű��� ���� -
esp32����ͼ
-
���е���ģʽ����ͼ:
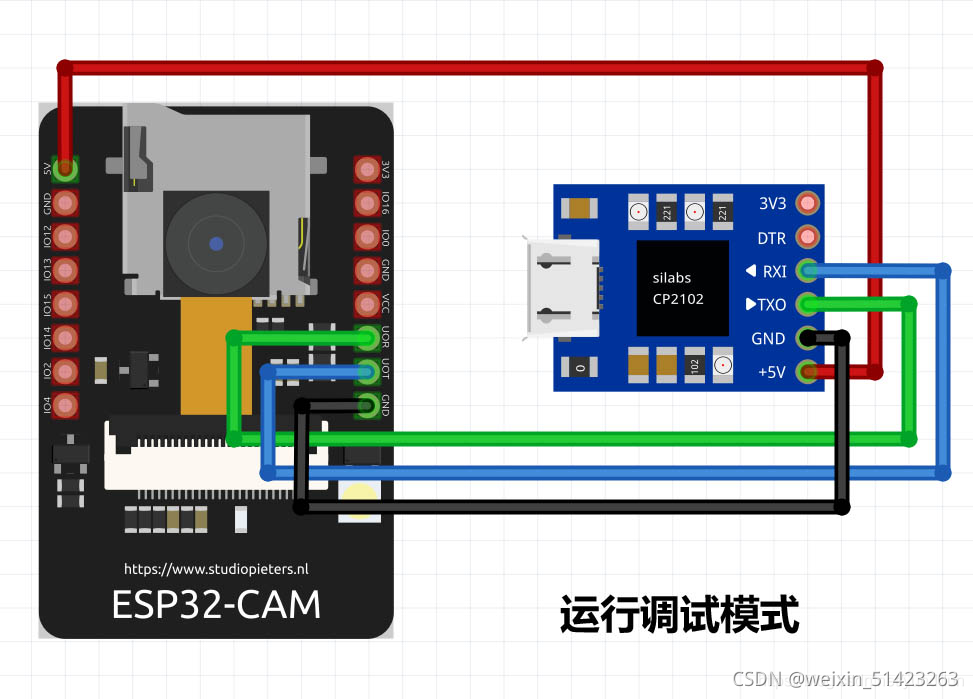
-
����ģʽ����ͼ:

-
������ο�csdn������
-
-
esp32������������
-
��Arduino IDE,�����Ͻǵ��ļ�����ѡ�������Ӹ��ӿ����������ַ:
http://arduino.esp8266.com/stable/package_esp8266com_index.json,https://dl.espressif.com/dl/package_esp32_index.json,https://www.jianshu.com/p/1e72a6a7cb7b.
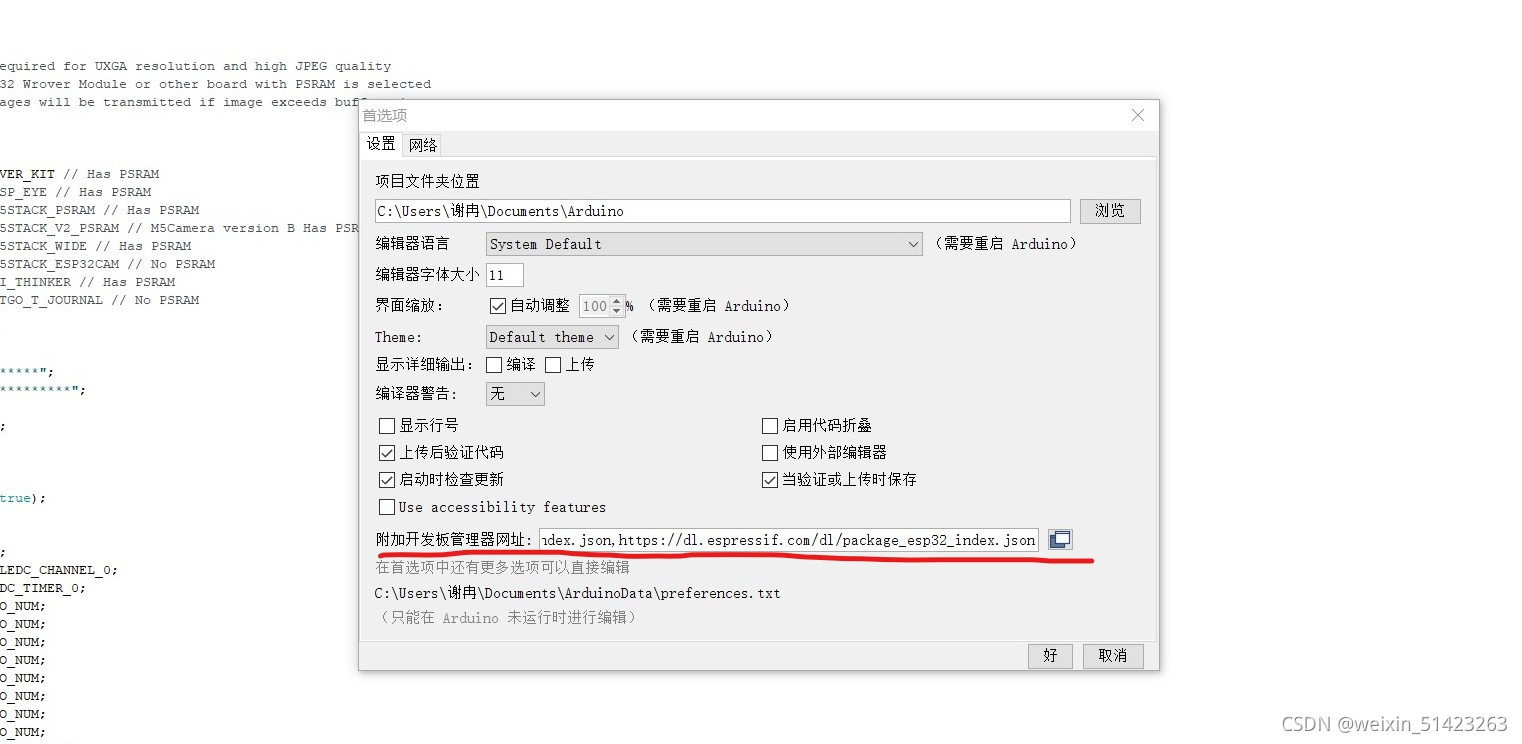
-
������ɺ�,ѡ�����ߨC>������C>�����������,��������������ESP32����װ��

-
��װ���֮��,������ߨC>������C>ESP32 Arduino,ѡ�����ͺ�Ϊ
AL Thinker ESP32-CAM��
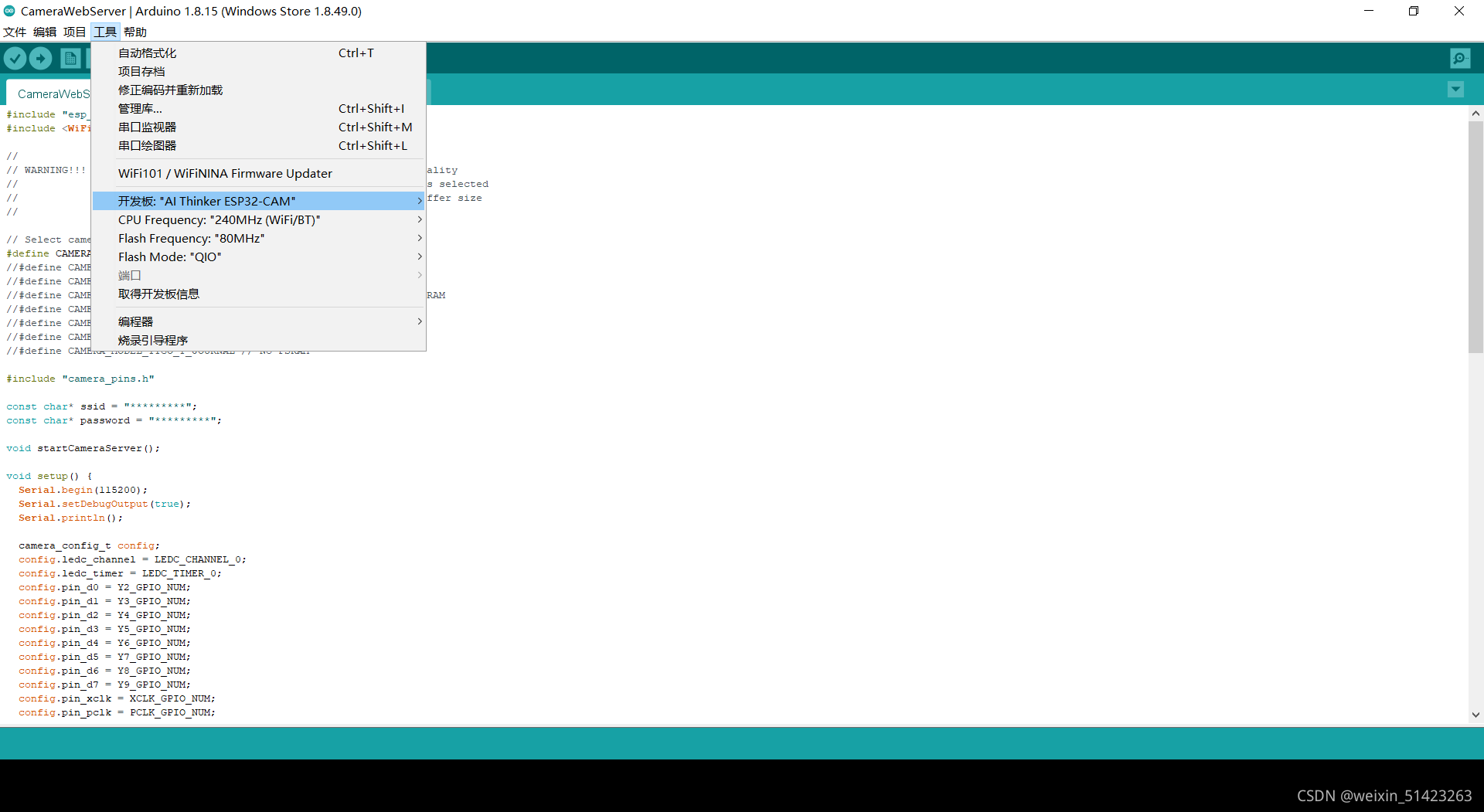
-
-
���뼰ʵ��Ч��
-
Arduino�����Դ���ʾ�������ֳɵĴ���,����ֻ��Ҫ������,�������Լ���д��
-
���ļ��C>ʾ���C>ESP32�C>Camera�C>CameraWebServer�ļ�,Ȼ��Դ�����������:��������ԭ��������ͷ����ע�͵�,ʹ��AI THINKER������ͷ���塣
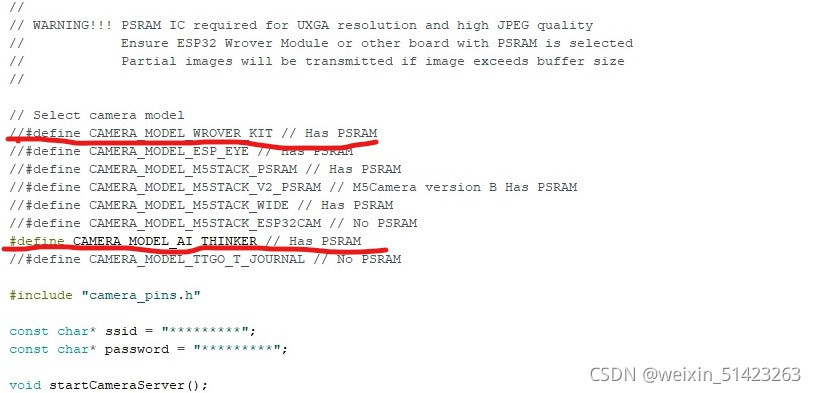
-
�����ָ��λ�ø�Ϊ�Լ���WiFi��������,֮��esp32����Ϊ����ģʽ,��ʼ���벢�ϴ����롣
-
������뱨��,�����Ƿ�װWiFi��,��δ��װ�����Ŀ�C>���ؿ�C>����������WiFi����װ��
-
������¼��Ϻ�,��esp32����Ϊ���е���ģʽ,��
RSt��,֮����ڹ�����,����������Ϊ115200,������������봮�ڷ��ص�url���ɡ�
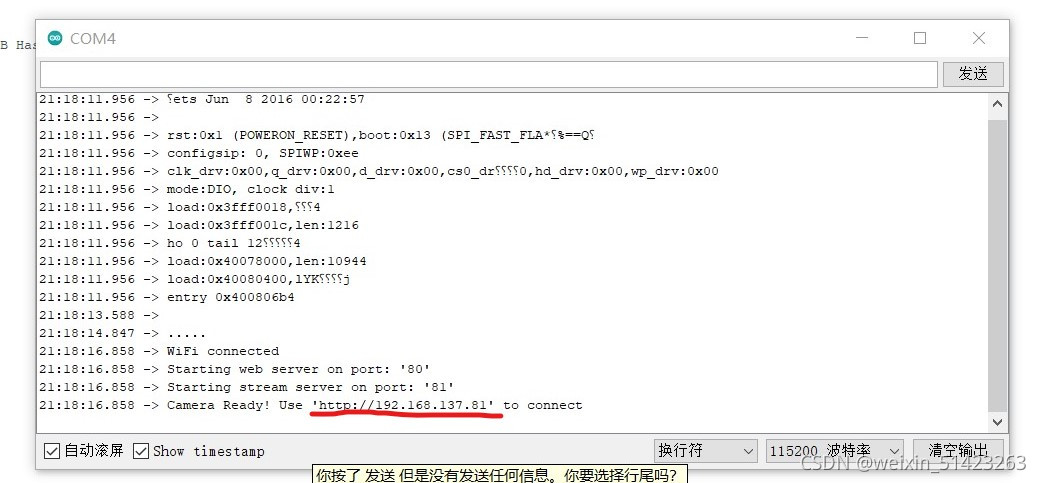
-
����ҳ�����¶˵��
Start Stream���ɿ�����Ƶ����
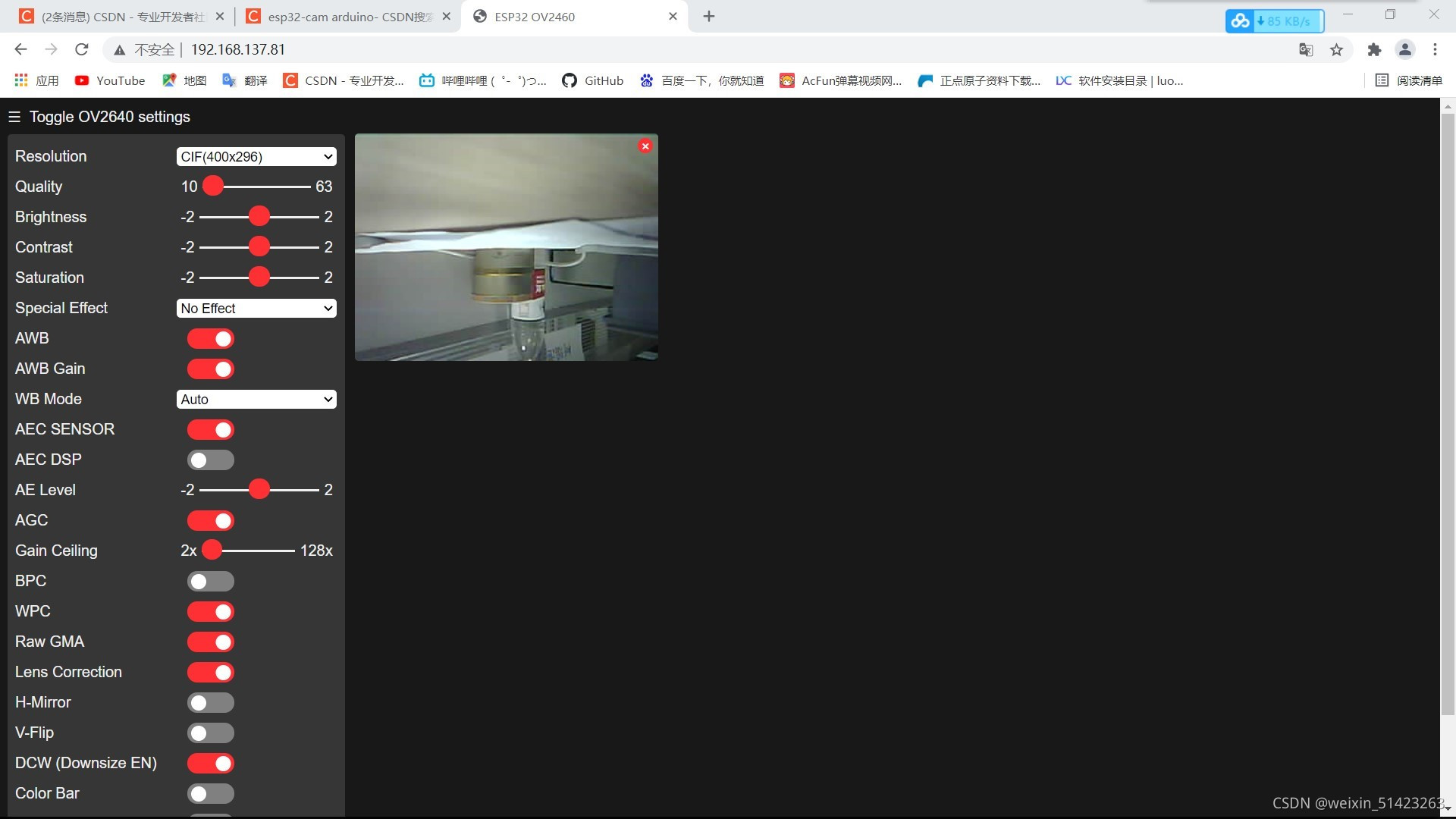
-
����facenetʵ����Ƶ������ʶ�� {#2}
-
��������
- python==3.6
- tensorflow==1.7
- scikit-learn
- opencv-python
- h5py
- matplotlib
- Pillow
- requests
- psutil
- scipy==1.2.1
- pandas
- numpy==1.16.1
-
facenetԴ���ȡ
-
��װ������facenet����
-
�ڵ���
Anconda3\Lib\site-packagesĿ¼���½�һ����Ϊfacenet���ļ��С���Ϊ�����ҵ�����װ��һ�������,����·����Щ��һ��,�������ʵ�����������
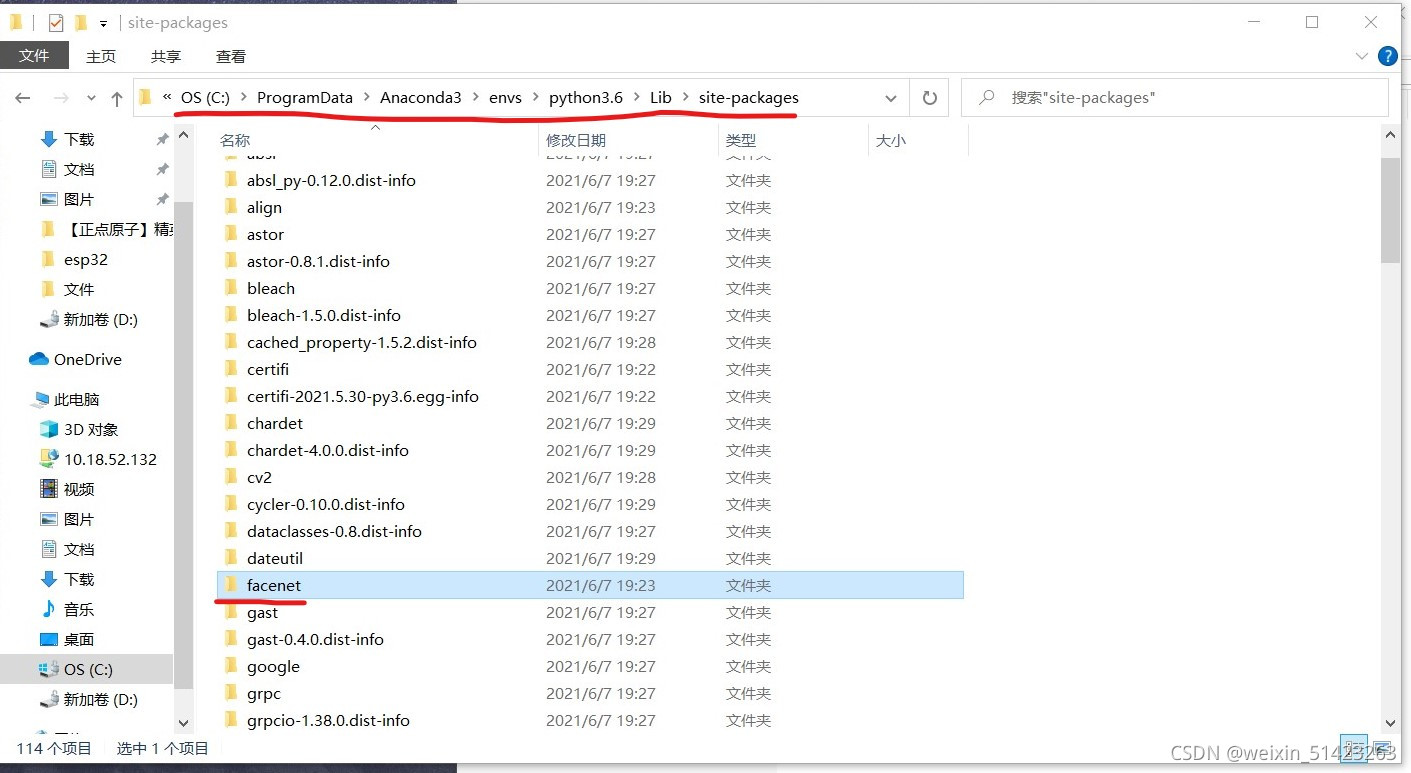
-
Ȼ��,��
facenet-master\src�ļ����µ������ļ������Ƶ��ո��½���facenet�ļ����¡�
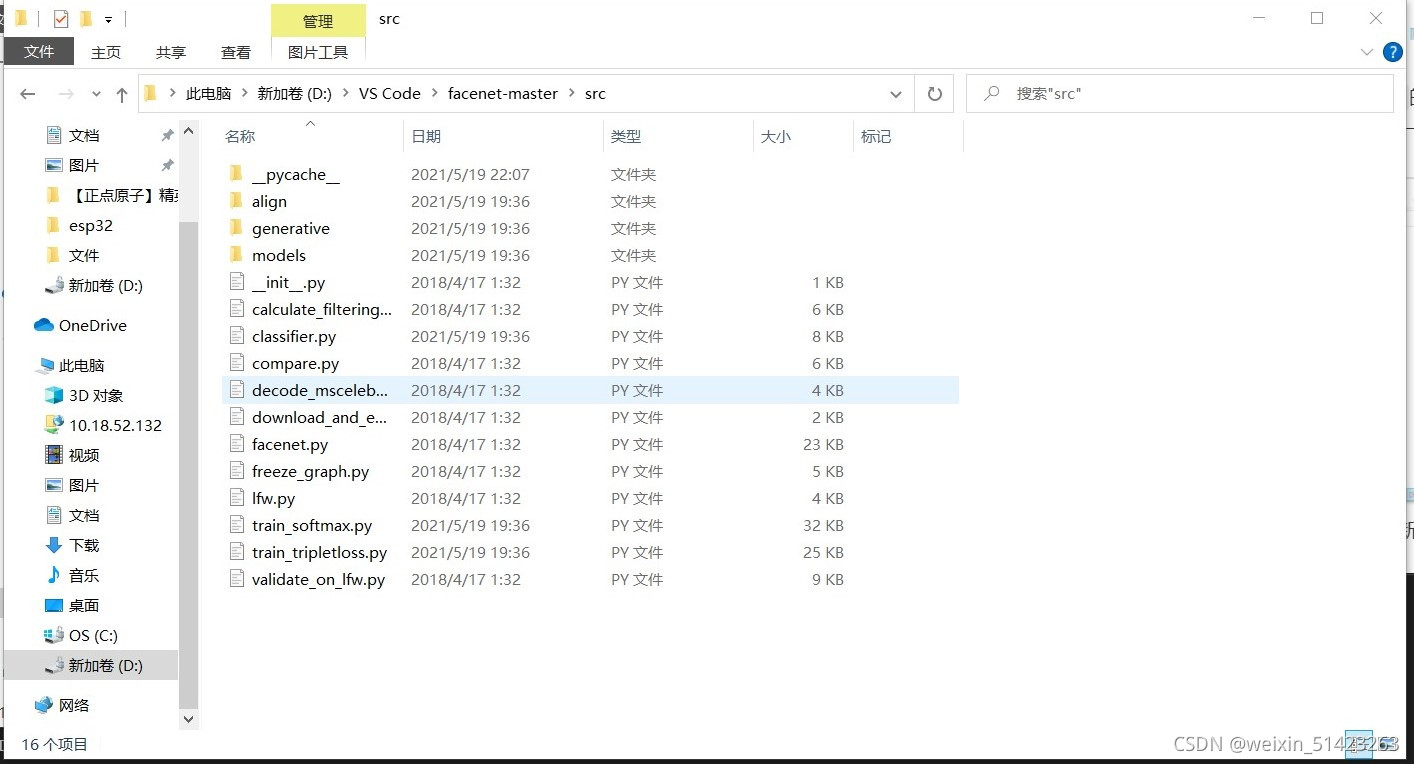
-
Ȼ��,��facenet�ļ�������Ϊ
align���ļ����Ƶ�site-packages�ļ����¡� -
���濪ʼ���û�������,�����èC>ϵͳ�C>���ڨC>��ϵͳ������
��������,���û��������½�һ����Ϊ
PYTHONPATH�ı���,����֮ǰ��facenet�ļ��е�·�������������
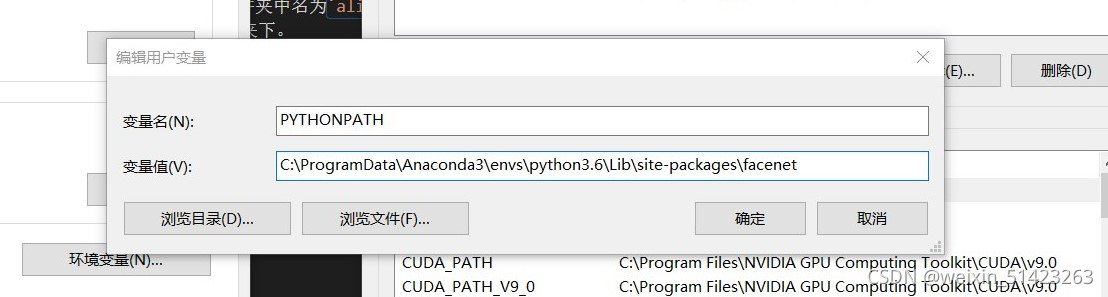
- ��
cmd������set�鿴���������

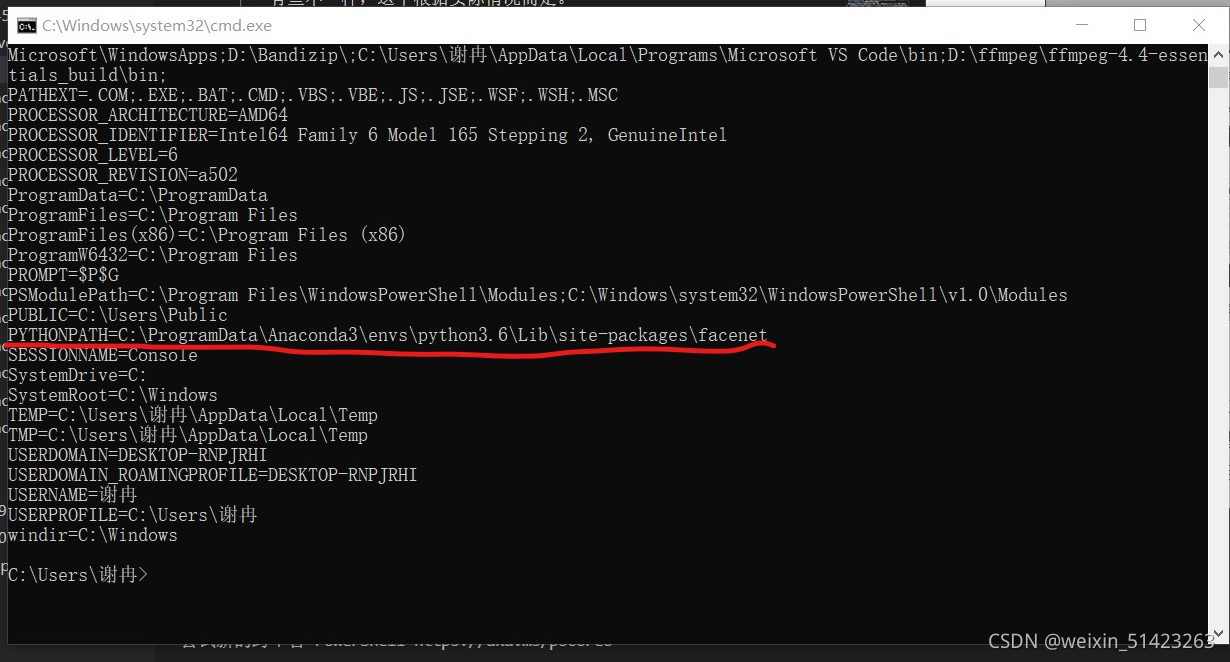
-
-
����LFW���ݼ�
-
LFW���ݼ�������������������ѧ��ķ˹�ط�У������Ӿ�ʵ��������������������ݼ�,����������ʶ���㷨Ч���Ĺ����������ݼ�,ȫ��Ϊ����ǩ����Ȼ�������ݿ�(Labeled Faces in the Wild)��
-
LFW���ݿ���ÿ��ͼƬ������ʽΪ��lfw/name/name_xxxx.jpg��,���xxxx����ǰ�油�����λͼƬ��š�����,ǰ������ͳ����?W?��ʲ�ĵ�10��ͼƬΪ��lfw/George_W_Bush/George_W_Bush_0010.jpg����
-
LFW���ݿ� �ܹ��� 13233 �� JPEG ��ʽͼƬ,���� 5749 ����ͬ�ˡ�ÿ��ͼƬ�ߴ綼�� 250x250��
-
���ݿ����ص�ַ:http://vis-www.cs.umass.edu/lfw/lfw.tgz
-
�ٶ�����ַ,��ȡ��
rzm5�� -
���������ݼ�����
facenet-master\data�ļ������½�һ����Ϊlfw���ļ���,�����ݼ���ѹ��lfw�ļ�����,����lfw�ļ��������½�һ����Ϊlfw_160���ļ��С�

-
-
��LFW���ݼ�����Ԥ����
-
LFW���ݼ�������ͼƬ�Ĵ�С��Ϊ
250*250,������Ҫ�����е����ݼ�������Ԥѵ��ģ����ʹ�õ�160*160�Ĵ�С�����浽lfw_160�ļ����¡� -
��
Anconda Prompt��λ��facenet-master�ļ�����,���������������У:python src\align\align_dataset_mtcnn.py --help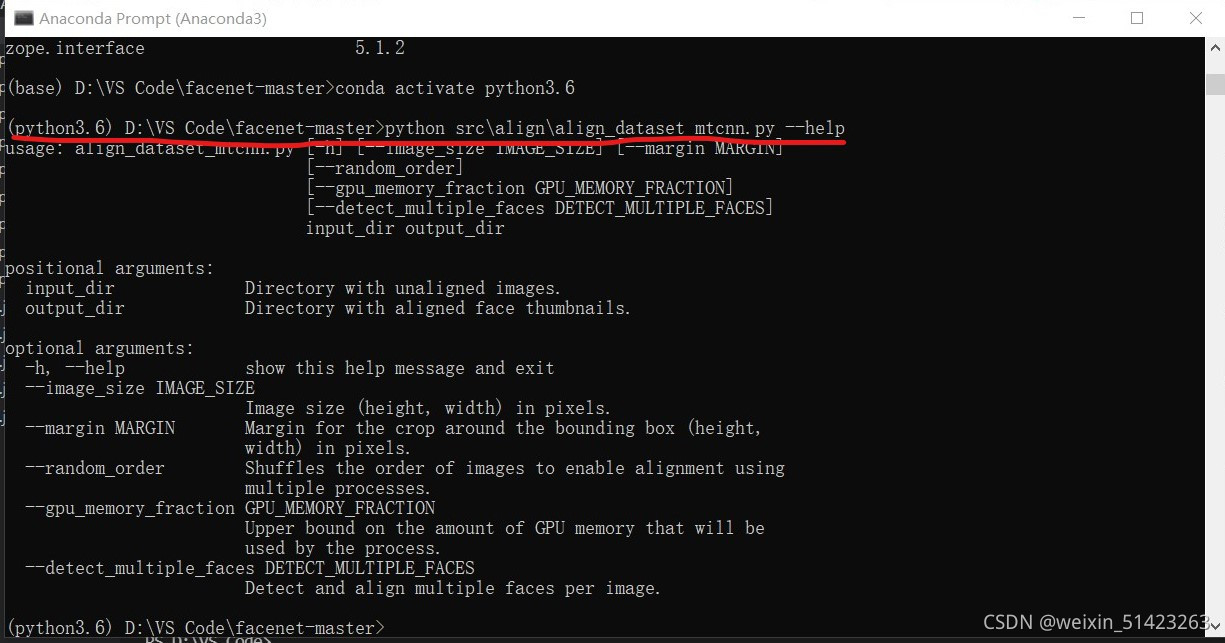
-
��������������:
python src\align\align_dataset_mtcnn.py data/lfw/lfw data/lfw/lfw_160 --image_size 160 --margin 32 --random_order --gpu_memory_fraction 0.25�����������Ҫ�������·����Ϊ����,��һ��·��Ϊԭ���ݼ���
lfw�ļ���,�ڶ���·��Ϊ���洦��������ݼ���lfw_160�ļ���,������Լ���ʵ�������д��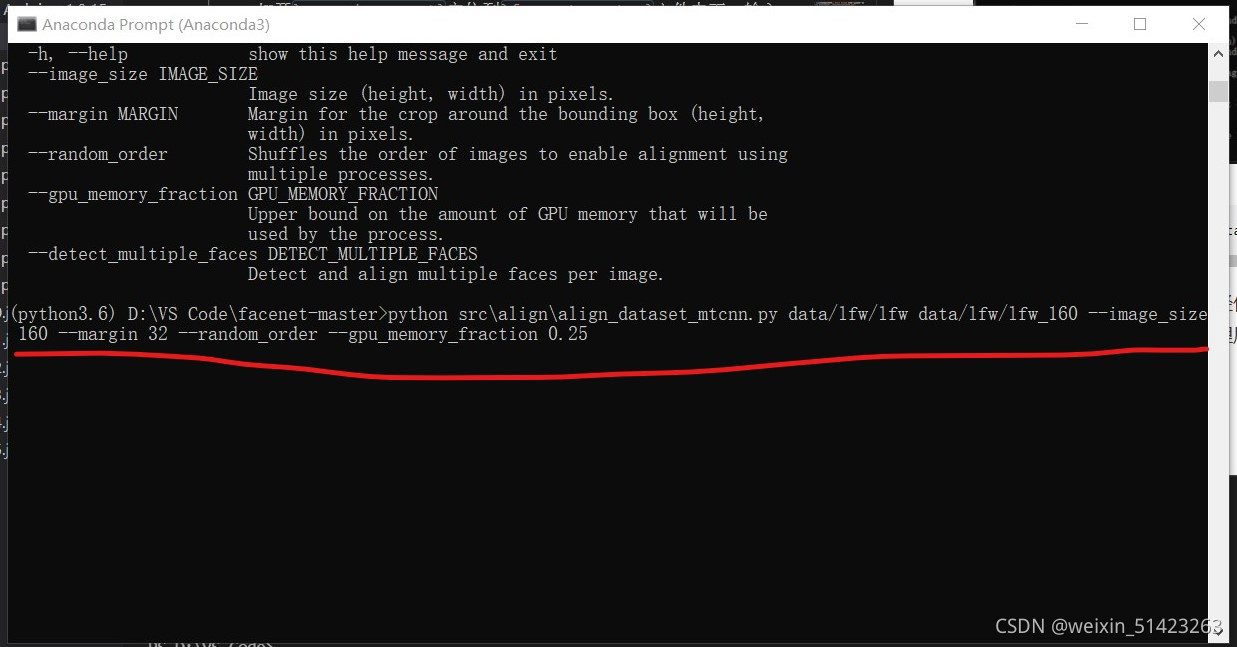
-
�������гɹ��������:
-
-
����ѵ���õ�����ģ��
-
facenet�ṩ������Ԥѵ��ģ��,�ֱ��ǻ���CASIA-WebFace��MS-Celeb-1M������ѵ����,����:
Model name LFW accuracy Training dataset Architecture 20180408-102900 0.9905 CASIA-WebFace Inception ResNet v1 20180402-114759 0.9965 VGGFace2 Inception ResNet v1 -
�ȸ����̵������ٶȺ���,�����аٶ��Ƶĵ�ַ:
ģ�� ��ȡ�� 20180408-102900 o6m0 20180402-114759 lu9c -
������ģ����ѡ��һ����,���õ��ǻ������ݼ�CASIA-WebFace����Inception ResNet v1������ṹѵ���õ�ģ�͡�
-
ģ��������֮��,�����ѹ��
facenet-master\src\models�ļ����¡�
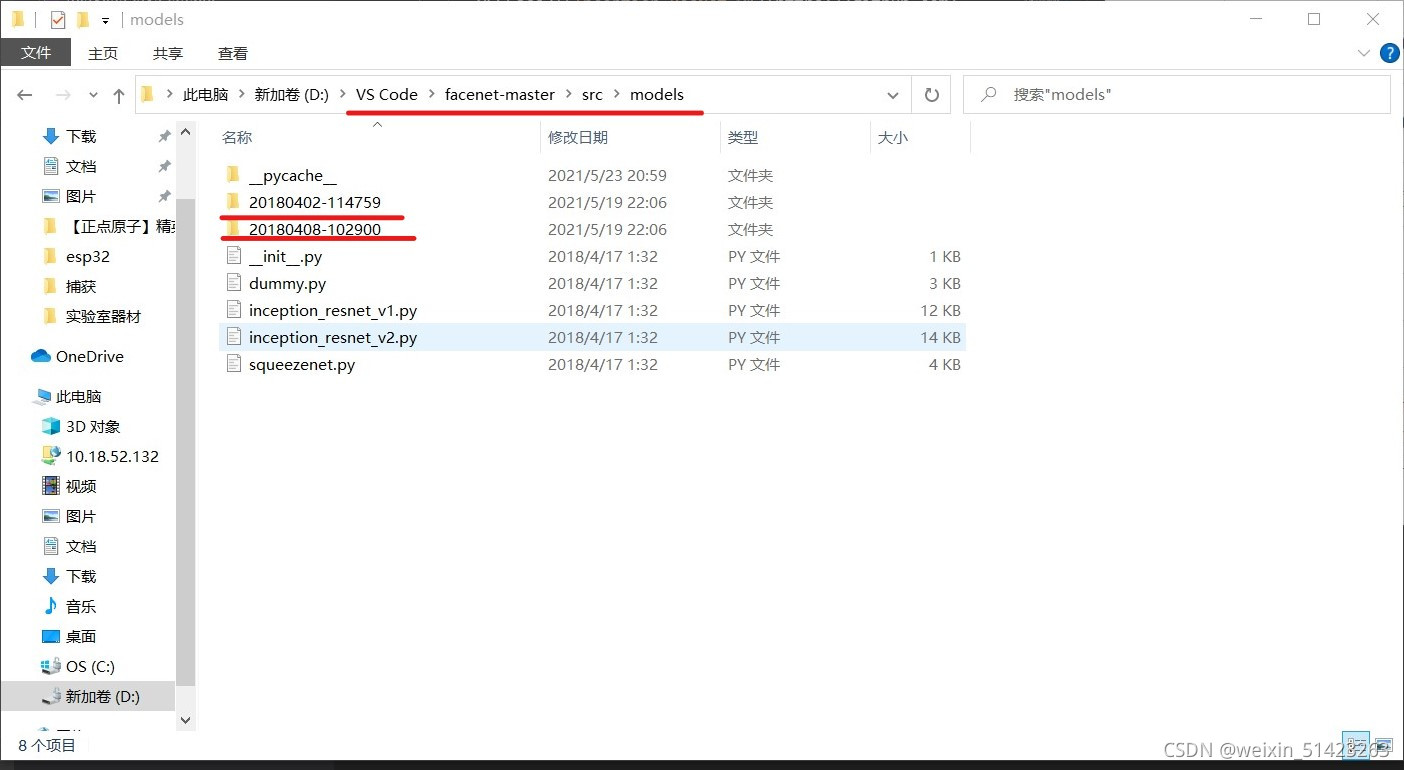
-
��ʵ����Ҳ����ȥѵ���Լ���ģ��,���ǻ�Ƚ���,�����������Ǿ�ֱ��ʹ����ЩԤѵ��ģ�͡�
-
-
����Ԥѵ��ģ�͵�ȷ��
-
��Anaconda Propmt�¶�λ��facenet-master�ļ����¡�
-
������������:
python src\validate_on_lfw.py data\lfw\lfw_160 src\models\20180408-102900������Ȼ��Ҫ��������·����Ϊ����,��һ���Ǵ�Ŵ���������ݼ���
lfw_160�ļ���,�ڶ�����Ԥѵ��ģ�͵�·��,�����ʵ�������д�� -
�����ͼ:

-
-
�����Ա�
-
facenet����ֱ�ӶԱ���������������������ӳ��֮���ŷ�Ͼ���,�Դ����ж������������Ƿ�Ϊͬһ���ˡ�
-
��
facenet-master\src�ļ��´����������ͼƬ��
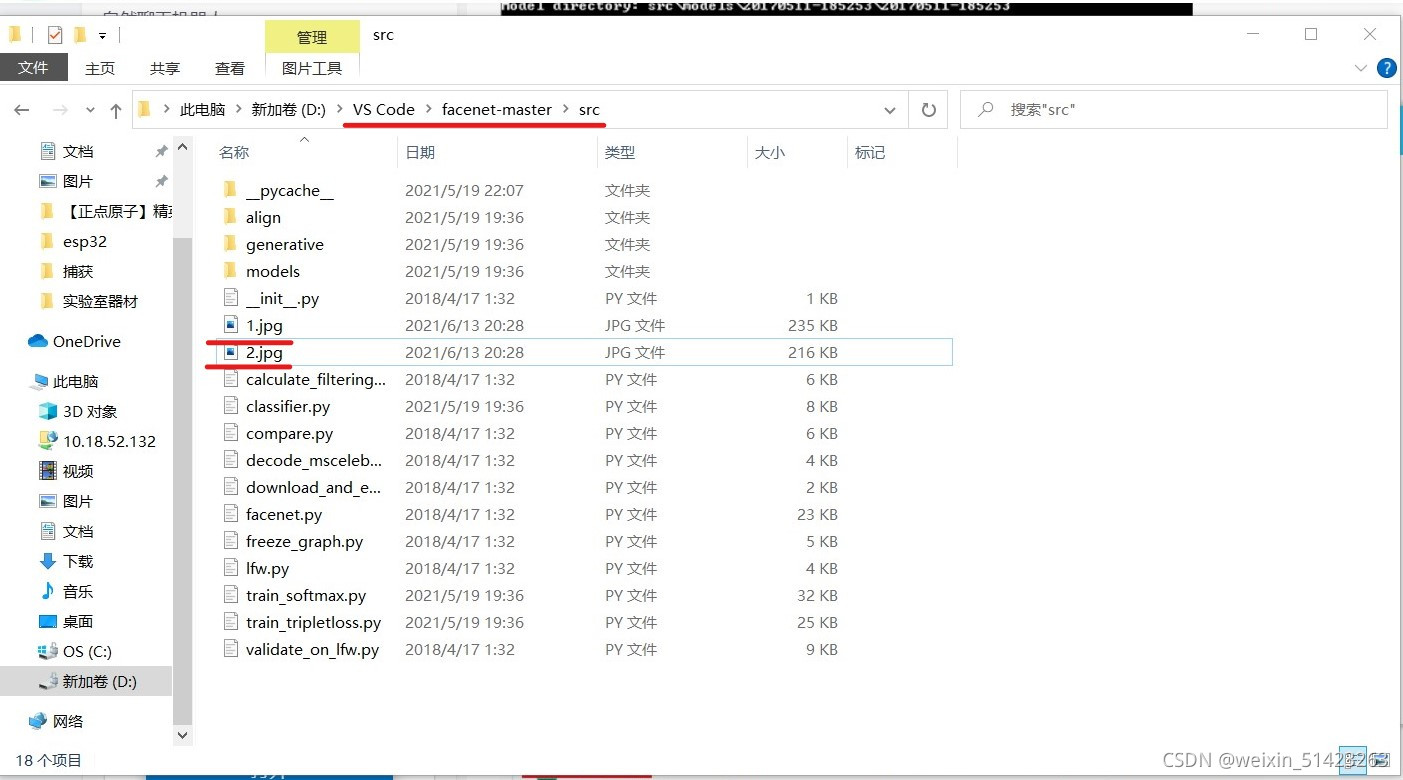
-
��Anaconda Propmt�ж�λ��
facenet-master\src�ļ�����,������������:python compare.py models\20180408-102900 1.jpg 2.jpg������Ҫ��������·����Ϊ����,��һ����Ԥѵ��ģ�͵�·��,ʣ������������ͼƬ��·����
-
��������:
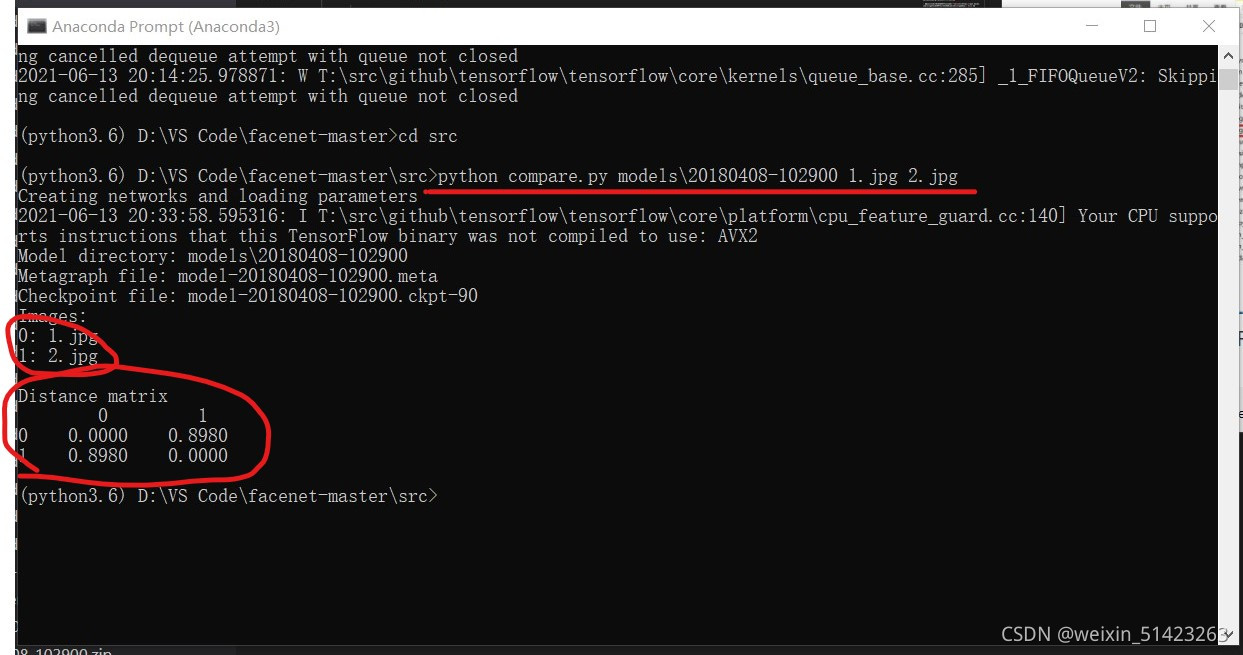
-
�ɹ�������ϲ����,�����������ص�facenetԴ���Ѿ��������,���Խ�������ʶ��,����������Ҫ������Ƶ��������ʶ��
-
-
�ռ��Լ������ݼ�
-
��
facenet-master\src�ļ������½�һ����Ϊmy_lfw���ļ���,����������ǵ����ݼ������½�һ����Ϊmy_lfw_160���ļ���������Ŵ���������ݼ���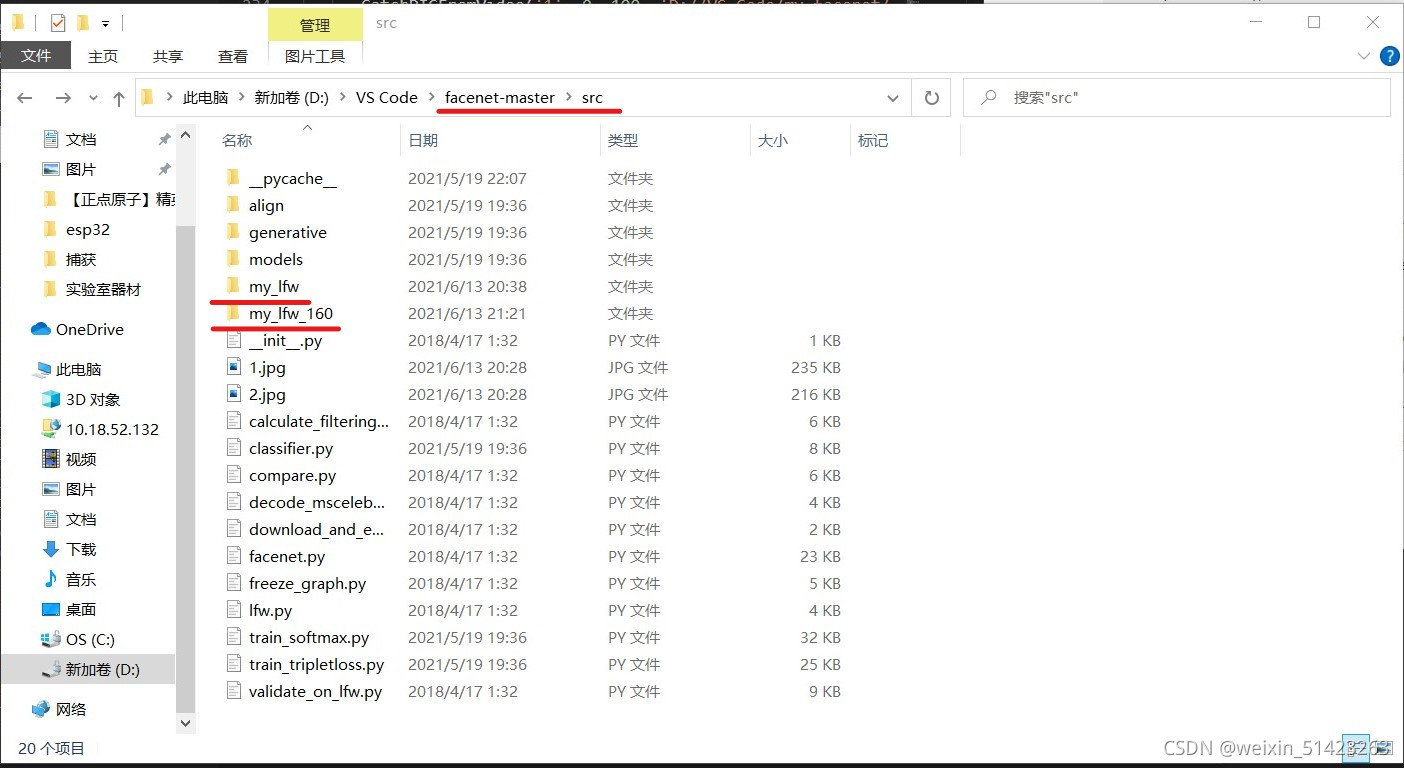
-
Ȼ����
my_lfw�ļ������½������ļ���,�ļ��е����־������ռ�������������,�ļ��е������������������� -
�ռ������Ĵ����кܶ�,�Ҵ�csdn���������һ��:
import cv2 def CatchPICFromVideo(window_name, camera_idx, catch_pic_num, path_name): cv2.namedWindow(window_name) # ��Ƶ��Դ,��������һ���Ѵ�õ���Ƶ,Ҳ����ֱ������USB����ͷ cap = cv2.VideoCapture(camera_idx) # ����OpenCVʹ������ʶ������� data_path = "C:\ProgramData\Anaconda3\pkgs\libopencv-3.4.2-h20b85fd_0\Library\etc\haarcascades\haarcascade_frontalface_default.xml" classfier = cv2.CascadeClassifier(data_path) # ʶ���������Ҫ���ı߿����ɫ,RGB��ʽ color = (0, 255, 0) num = 0 while cap.isOpened(): ok, frame = cap.read() # ��ȡһ֡���� if not ok: break grey = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY) # ����ǰ��ͼ��ת���ɻҶ�ͼ�� # �������,1.2��2�ֱ�ΪͼƬ���ű�������Ҫ������Ч���� faceRects = classfier.detectMultiScale(grey, scaleFactor=1.2, minNeighbors=3, minSize=(32, 32)) if len(faceRects) > 0: # ����0������� for faceRect in faceRects: # �������ÿһ������ x, y, w, h = faceRect # ����ǰ֡����ΪͼƬ img_name = '%s/%d.jpg ' %(path_name, num) image = frame[y - 10: y + h + 10, x - 10: x + w + 10] cv2.imwrite(img_name, image) num += 1 if num > catch_pic_num: # �������ָ����������˳�ѭ�� break # �������ο� cv2.rectangle(frame, (x - 10, y - 10), (x + w + 10, y + h + 10), color, 2) # ��ʾ��ǰ�����˶�������ͼƬ��,����վ�����ﱻ����ʱ�����и���,��������һĨ��ɵ���� font = cv2.FONT_HERSHEY_SIMPLEX cv2.putText(frame ,'num:%d' % (num) ,(x + 30, y + 30), font, 1, (255 ,0 ,255) ,4) # ����ָ����������������� if num > catch_pic_num: break # ��ʾͼ�� cv2.imshow(window_name, frame) c = cv2.waitKey(10) if c & 0xFF == ord('q'): break # �ͷ�����ͷ���������д��� cap.release() cv2.destroyAllWindows() CatchPICFromVideo('1', 0, 100, 'D://VS Code/my_facenet/my_faces/CJL')��δ����еĺ���һ�����ĸ�����,�ֱ�Ϊ:�������ơ�����ͷ��Ż���Ƶ·����ͼƬ������ͼƬ����·����
-
Ȼ������Ҫ����Щ���ݼ�ͬ��������
160*160�Ĵ�С�� -
��Anaconda Propmt�ж�λ��
facenet-master\src�ļ�����,������������:python align\align_dataset_mtcnn.py my_lfw my_lfw_160 --image_size 160 --margin 32 --random_order --gpu_memory_fraction 0.25
-
-
ѵ��������
-
�����Լ����������ݼ���,���ǾͿ��Կ�ʼѵ���Լ��ķ������ˡ�
-
��Anaconda Propmt�ж�λ��
facenet-master�ļ�����,������������:python classifier.py TRAIN my_lfw models\20180408-102900 my_classifier.pkl���������Ҫ�ĸ�����:
TRAIN�����ô���Ϊѵ��ģʽ�����ݼ�·����Ԥѵ��ģ��·����ѵ�����ķ�������·���� -
�������:
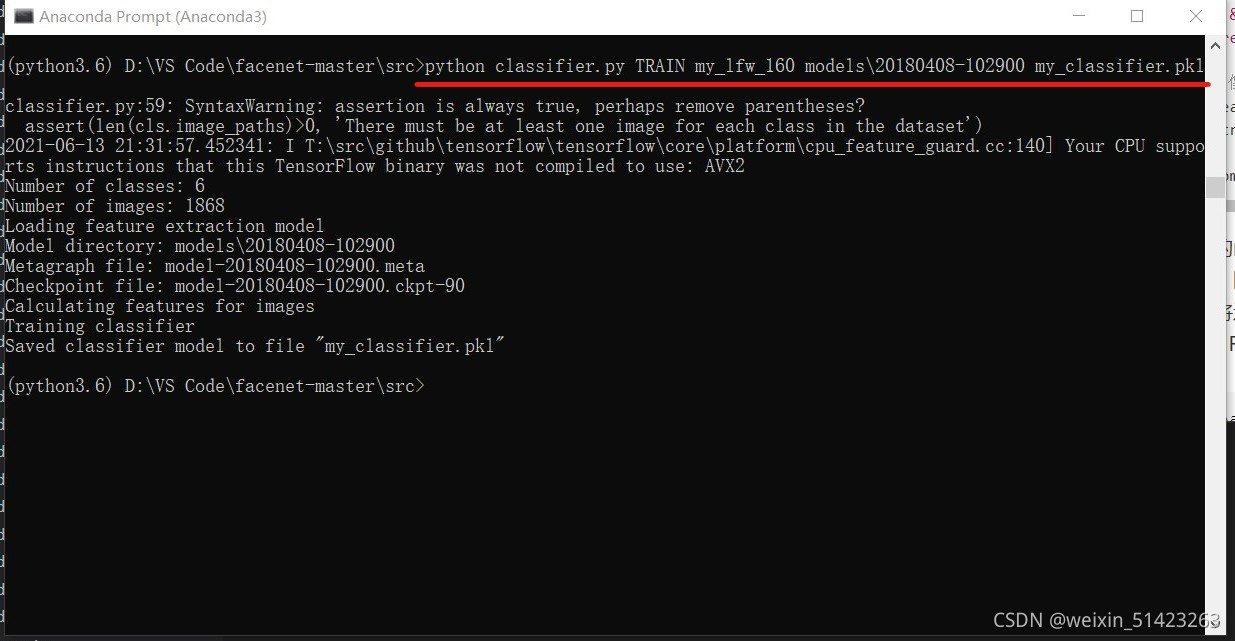

-
-
��Ƶ��������ʶ��
-
facenet��Դ��������Ƶ������ʶ���demo,����
facenet-master\contributed\real_time_recognition.py,����ֱ������ʹ�þͺá� -
��������Ҫ�����demo����һЩ�ġ�
-
���ȴ�
facenet-master\contributed\face.py,����ͼ��Ԥѵ��ģ�ͺͷ�������·���������Լ���·��,������·��������,���þ���·����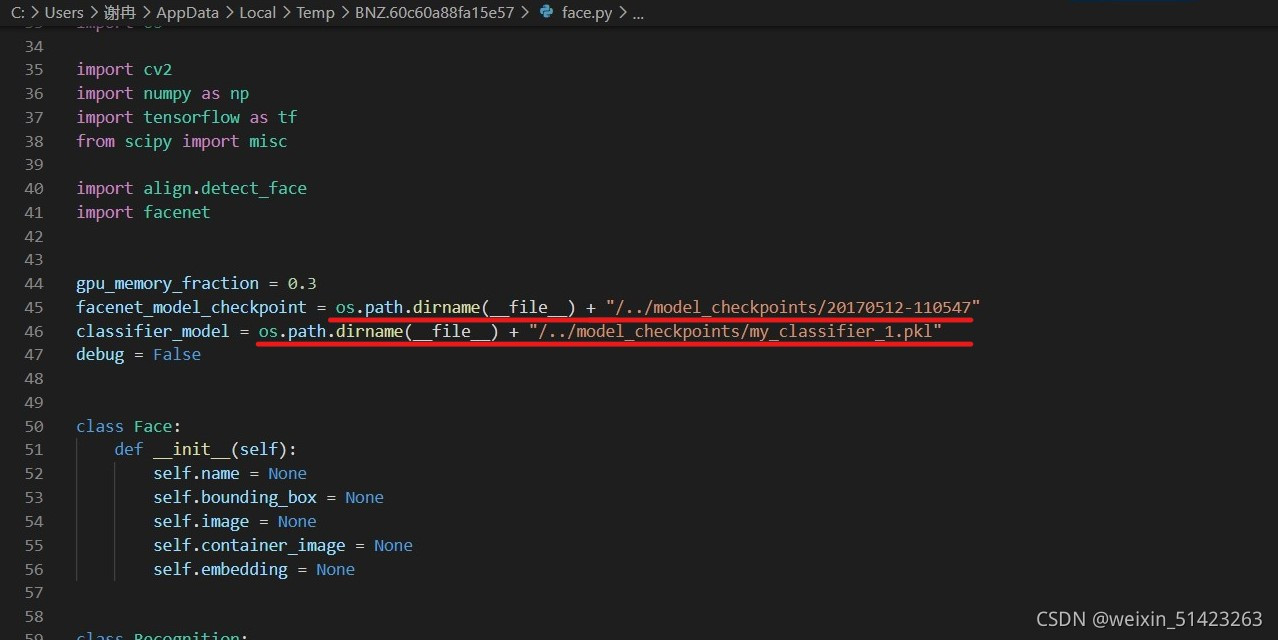
-
�����������ĺ�,����
real_time_recognition.py�Ϳ��Խ�������ʶ����,�������demo��һ��ȱ��,�Ǿ��ǵ��������ݼ���û�е���ʱ,��Ȼ�������ע���ݼ��е��˵�����,�����עOther������������Ҫ����ʵ�������ʶ���ȷ�Ƚ��е���,�������������Ĵ��롣 -
��
face.py,�������������:��ǰ:
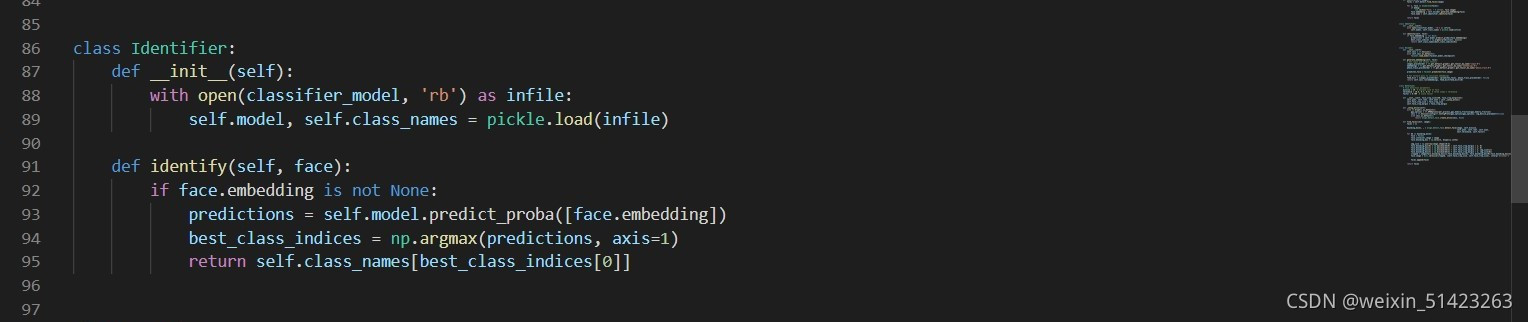
�ĺ�:
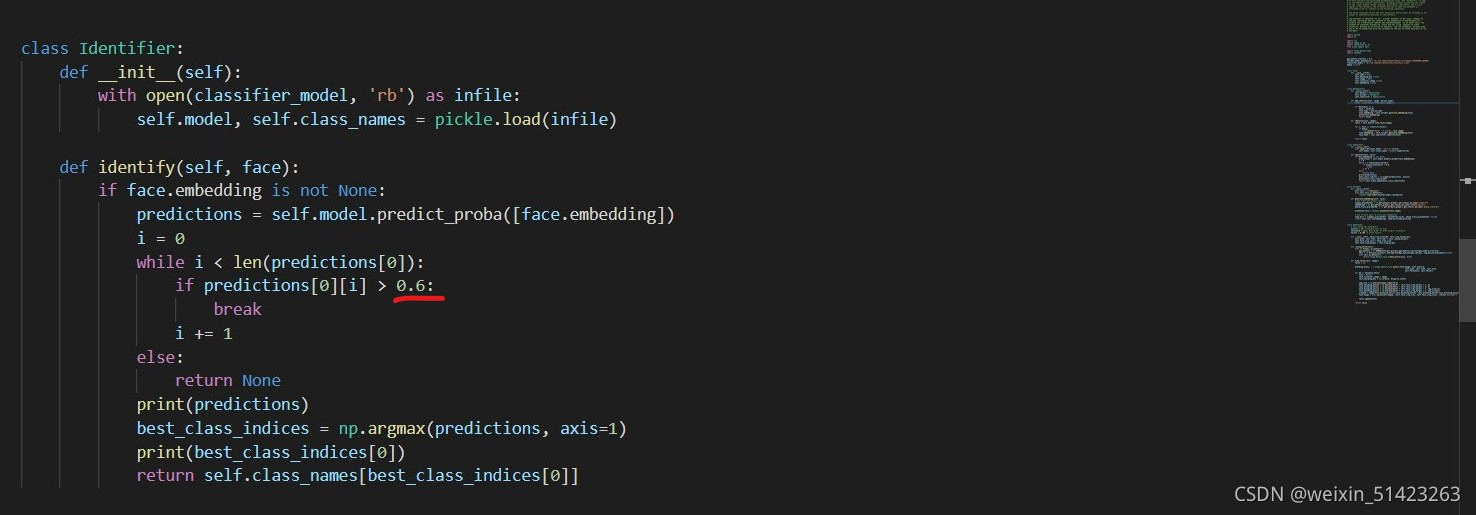
����,��ע��������ֵ����ʵ��������о������С��
�ĺ�ò��ֵĴ���:class Identifier: def __init__(self): with open(classifier_model, 'rb') as infile: self.model, self.class_names = pickle.load(infile) def identify(self, face): if face.embedding is not None: predictions = self.model.predict_proba([face.embedding]) i = 0 while i < len(predictions[0]): if predictions[0][i] > 0.6: break i += 1 else: return None print(predictions) best_class_indices = np.argmax(predictions, axis=1) print(best_class_indices[0]) return self.class_names[best_class_indices[0]] -
Ȼ���
real_time_recognition.py,��ͼ��λ���������´���:else: cv2.putText(frame, 'Others', (face_bb[0], face_bb[3]), cv2.FONT_HERSHEY_SIMPLEX, 1, (0, 255, 0), thickness=2, lineType=2)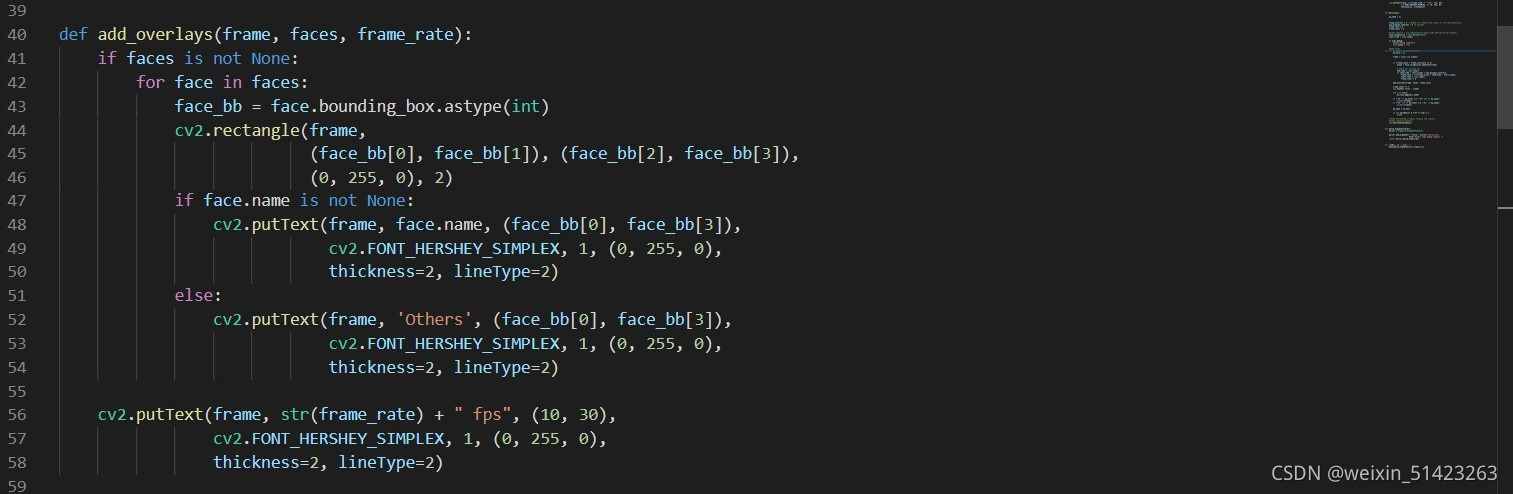
-
�����֮��,�Ϳ���������������ʶ���ˡ�
-

������esp32���������Ե���Ƶ������ʶ�� {#3}
-
opencv��ȡesp32�������Ƶ��
-
esp32���������Ե���Ƶ��ʱ������һ����ҳ�ϵ�,�������ǽ�������ʶ��ʱ��Ҫ����Ƶ����ȡ��python,�����Ҫ�õ�opencv�е�
VideoCapture()������ -
һ�����������ʹ��
VideoCapture()ֻ��Ҫ������ͷ��ź���Ƶ·��������������ѡһ��,��ʵVideoCapture()�����Խ���Ƶ����url��Ϊ��������ȡ��Ƶ���� -
��������Ҫ��ȡesp32�������Ƶ����url,��esp32���ɵ���ҳ��,����Ƶ�����ڲ��ŵ�״̬��,�һ���Ƶ�IJ��Ŵ���,ѡ����ͼƬ��ַ,��ʱ�õ��ľ�����Ƶ����url��

-
�ڻ�ȡ��Ƶ��url֮��,�������ȳ���һ��opencv�ܷ�ɹ���ȡ��Ƶ�����½�һ��python�ļ�,�������´���:
import cv2 cv2.namedWindow('esp32') cap = cv2.VideoCapture('http://192.168.137.81:81/stream') while cap.isOpened(): ok, frame = cap.read() if not ok: break cv2.imshow('esp32', frame) c = cv2.waitKey(10) if c & 0xFF == ord('q'): break cap.release() cv2.destroyAllWindows()����ֻ��Ҫ��
VideoCapture()�����еIJ����ij��Լ���url���ɡ� -
���д����ʱ����Ҫ����ҳ�ϵ���Ƶ����ͣ���߹ر���ҳ,��������ȡ��Ƶ����
-
��Ƶ�����Գɹ�����֮��,��opencv���Գɹ���ȡ��Ƶ����
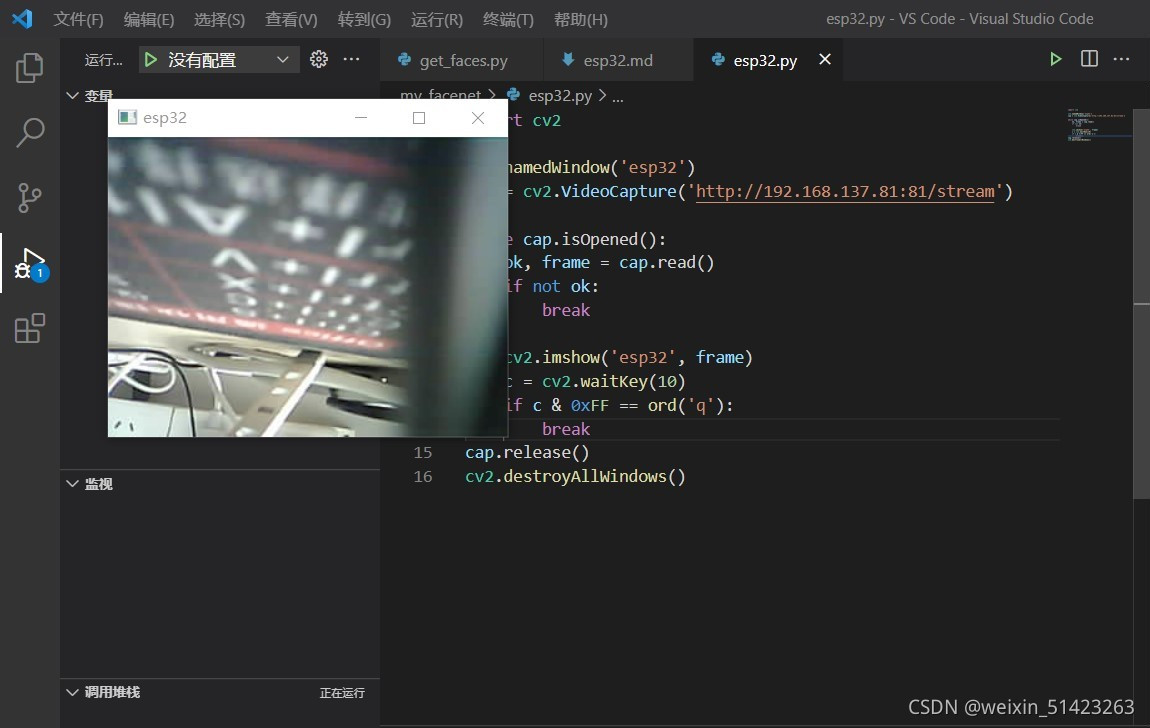
-
-
�Զ�ȡ����Ƶ������ʶ��
-
���������ǿ��Գɹ���ȡ��Ƶ��֮��,ֻ��ֱ�ӽ�
real_time_recognition.py�е�VideoCapture(0)��ΪVideoCapture(url)���ɡ���������esp32������ͷ��Ƶ�ı����ʽ��facenet���Դ�������Ƶ�������ʽ��ͬ,ֱ�������������ڶ�ȡ��һ֡ͼƬ���ֱ�ӱ���,���³���ֱ��ֹͣ����,��������Ҫ���������⡣ -
��õĽ������ʱ����Ƶ���ı����ʽ,�����Ҳ�û���ҵ��й��ⷽ��ĺܺõĽ���취,������ʹ����һ�ֺܱ��ķ���:��Ȼ����ֻ�ܶ�ȡ��Ƶ���ĵ�һ֡ͼƬ,��ô���Ǿ��ڶ�ȡ���һ��ͼƬ��,��
release()�ͷ���Ƶ��,Ȼ����ͨ��VideoCapture()��ȡ��Ƶ��,�ڶ�ȡ��һ֡ͼƬ���ٴ��ͷ���Ƶ��,�Դ�ѭ��,ͬ�����Եõ���������Ƶ����������Ȼ�ᵼ��֡���½�,���Dz���Ӱ��������ʹ�á� -
��
facenet-master\contributed�ļ������½�һ��python�ļ�,ȡ��Ϊesp32_cam.py,�������������´���:import cv2 def video(): cap = cv2.VideoCapture("http://192.168.137.81:81/stream") #��ȡ��Ƶ�� while cap.isOpened(): ok, frame = cap.read() #��ȡһ֡ if not ok: break break cap.release() #�ͷ���Ƶ�� return frame #���ض�ȡ��һ֡ͼƬ -
��
real_time_recognition.py,�����ڴ��뿪ʼ����import esp32_cam,Ȼ��ע�ʹ�������¼���: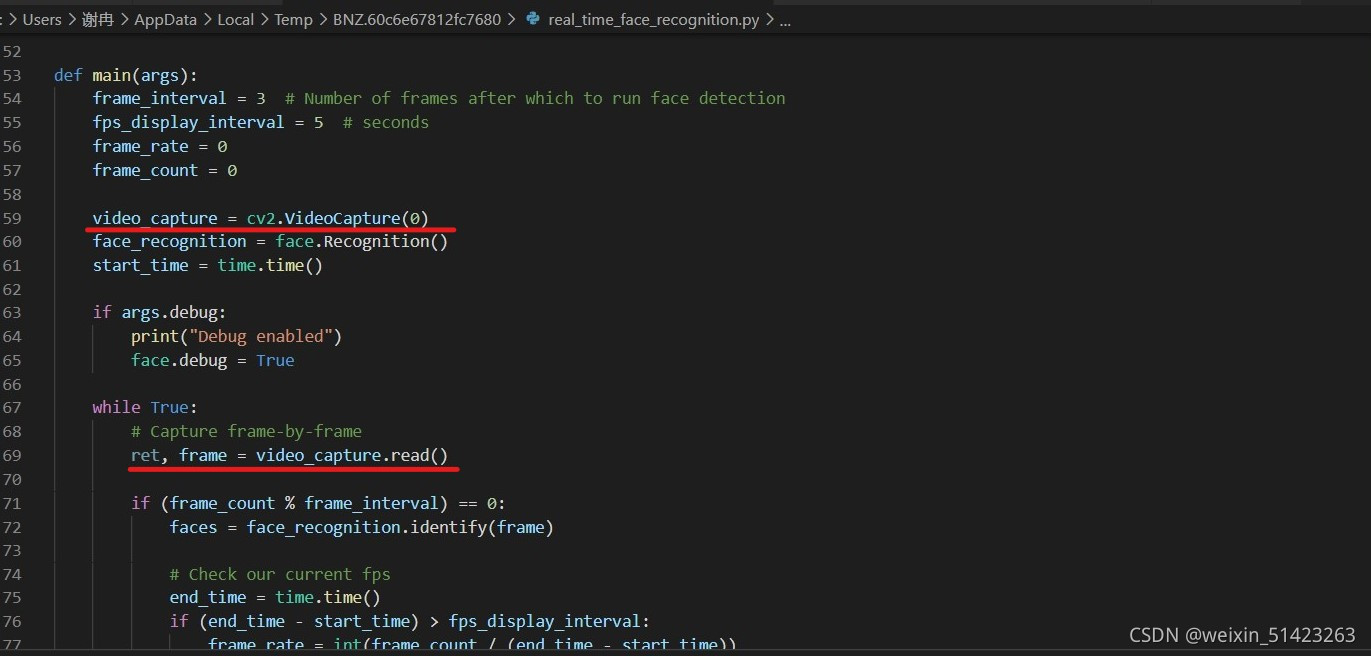
֮����ͼ�е�λ������
frame = esp32_cam.video()��
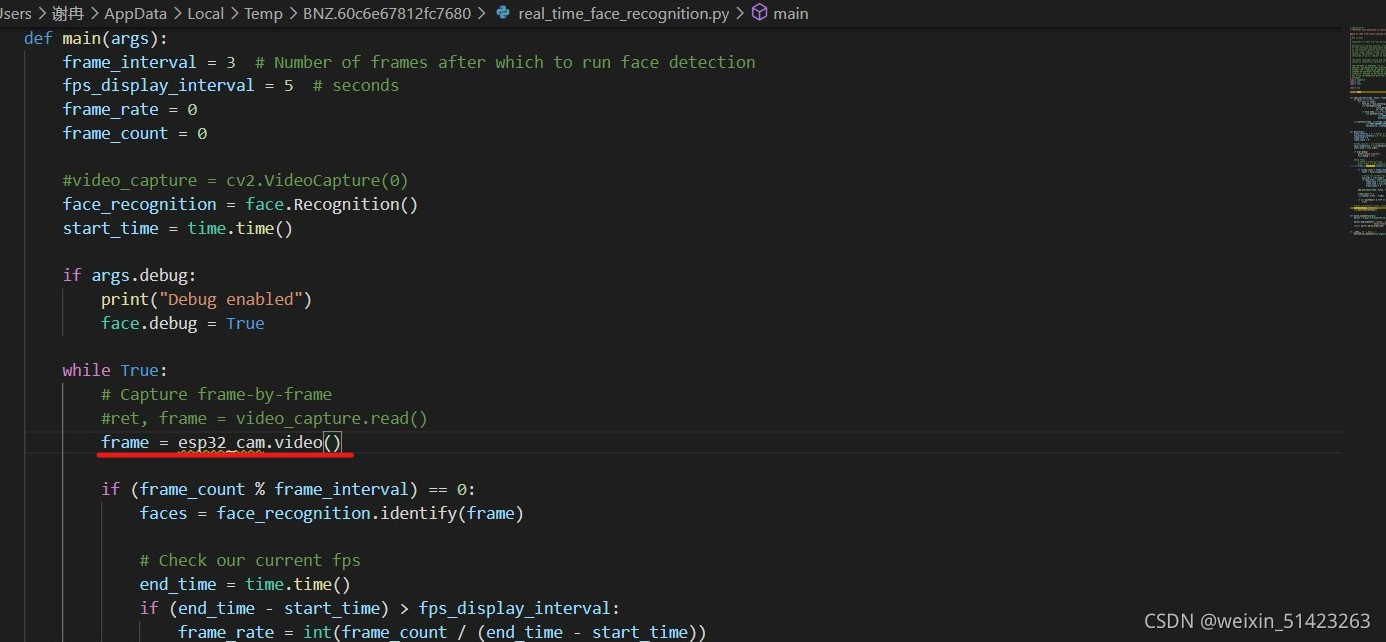
-
���֮��Ϳ���������ʹ���ˡ�
-
�ġ�ʶ���ָ�������,�������� {4}
- ��������
- pyautogui
- ����ʵ��
-
��
facenet-master\contributed�ļ������½�һ����Ϊscreen.py��python�ļ�,�������´���:import pyautogui def screen(): pyautogui.keyDown('alt') #����alt�� pyautogui.press('tab') #������tab�� pyautogui.keyUp('alt') #�ɿ�alt�� if __name__ == '__main__': screen() -
��
real_time_recognition.py,�ڴ��뿪ͷ����import screen��import pyautogui,Ȼ����ͼʾλ������my_name = []��
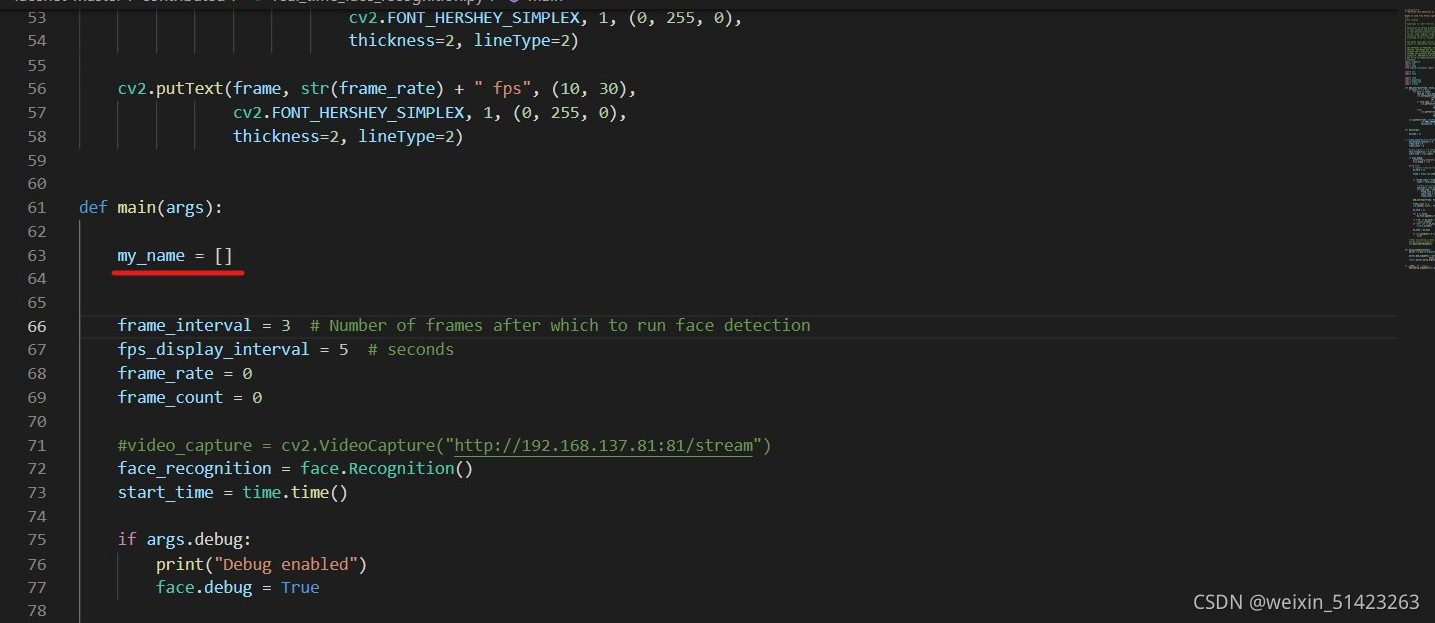
����ͼʾλ���������´���:
my_face = [] for i in faces: my_face.append(i.name) if ('XR' in my_face) and ('XR' not in my_name): #��ָ���������ֺ�,����һ������ screen.screen() if ('XR' not in my_face) and ('XR' in my_name): #��ָ��������ʧ��,����һ������ screen.screen() my_name = my_face -
���������Ŀ���������,��Ϊ�������õ���
alt + tab�Ŀ�ݼ���������,����������ȱ��,��ҿ���ȥ���Ը��õķ�����
-
�塢��Ҫ���� {#5}
����������Ҫ�õ����ĺõ�python���롣
- get_faces.py
import cv2 def CatchPICFromVideo(window_name, camera_idx, catch_pic_num, path_name): cv2.namedWindow(window_name) # ��Ƶ��Դ,��������һ���Ѵ�õ���Ƶ,Ҳ����ֱ������USB����ͷ cap = cv2.VideoCapture(camera_idx) # ����OpenCVʹ������ʶ������� data_path = "C:\ProgramData\Anaconda3\pkgs\libopencv-3.4.2-h20b85fd_0\Library\etc\haarcascades\haarcascade_frontalface_default.xml" classfier = cv2.CascadeClassifier(data_path) # ʶ���������Ҫ���ı߿����ɫ,RGB��ʽ color = (0, 255, 0) num = 0 while cap.isOpened(): ok, frame = cap.read() # ��ȡһ֡���� if not ok: break grey = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY) # ����ǰ��ͼ��ת���ɻҶ�ͼ�� # �������,1.2��2�ֱ�ΪͼƬ���ű�������Ҫ������Ч���� faceRects = classfier.detectMultiScale(grey, scaleFactor=1.2, minNeighbors=3, minSize=(32, 32)) if len(faceRects) > 0: # ����0������� for faceRect in faceRects: # �������ÿһ������ x, y, w, h = faceRect # ����ǰ֡����ΪͼƬ img_name = '%s/%d.jpg ' %(path_name, num) image = frame[y - 10: y + h + 10, x - 10: x + w + 10] cv2.imwrite(img_name, image) num += 1 if num > catch_pic_num: # �������ָ����������˳�ѭ�� break # �������ο� cv2.rectangle(frame, (x - 10, y - 10), (x + w + 10, y + h + 10), color, 2) # ��ʾ��ǰ�����˶�������ͼƬ��,����վ�����ﱻ����ʱ�����и���,��������һĨ��ɵ���� font = cv2.FONT_HERSHEY_SIMPLEX cv2.putText(frame ,'num:%d' % (num) ,(x + 30, y + 30), font, 1, (255 ,0 ,255) ,4) # ����ָ����������������� if num > catch_pic_num: break # ��ʾͼ�� cv2.imshow(window_name, frame) c = cv2.waitKey(10) if c & 0xFF == ord('q'): break # �ͷ�����ͷ���������д��� cap.release() cv2.destroyAllWindows() CatchPICFromVideo('1', 0, 100, 'D://VS Code/my_facenet/my_faces/CJL') - real_time_recognition.py
# coding=utf-8 """Performs face detection in realtime. Based on code from https://github.com/shanren7/real_time_face_recognition """ # MIT License # # Copyright (c) 2017 Fran?ois Gervais # # Permission is hereby granted, free of charge, to any person obtaining a copy # of this software and associated documentation files (the "Software"), to deal # in the Software without restriction, including without limitation the rights # to use, copy, modify, merge, publish, distribute, sublicense, and/or sell # copies of the Software, and to permit persons to whom the Software is # furnished to do so, subject to the following conditions: # # The above copyright notice and this permission notice shall be included in all # copies or substantial portions of the Software. # # THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR # IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, # FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE # AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER # LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, # OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE # SOFTWARE. import argparse import sys import time from tkinter.constants import NO import cv2 import face import time import pyautogui import esp32_cam import screen def add_overlays(frame, faces, frame_rate): if faces is not None: for face in faces: face_bb = face.bounding_box.astype(int) cv2.rectangle(frame, (face_bb[0], face_bb[1]), (face_bb[2], face_bb[3]), (0, 255, 0), 2) if face.name is not None: cv2.putText(frame, face.name, (face_bb[0], face_bb[3]), cv2.FONT_HERSHEY_SIMPLEX, 1, (0, 255, 0), thickness=2, lineType=2) else: cv2.putText(frame, 'Others', (face_bb[0], face_bb[3]), cv2.FONT_HERSHEY_SIMPLEX, 1, (0, 255, 0), thickness=2, lineType=2) cv2.putText(frame, str(frame_rate) + " fps", (10, 30), cv2.FONT_HERSHEY_SIMPLEX, 1, (0, 255, 0), thickness=2, lineType=2) def main(args): my_name = [] frame_interval = 3 # Number of frames after which to run face detection fps_display_interval = 5 # seconds frame_rate = 0 frame_count = 0 #video_capture = cv2.VideoCapture("http://192.168.137.81:81/stream") face_recognition = face.Recognition() start_time = time.time() if args.debug: print("Debug enabled") face.debug = True while True: # Capture frame-by-frame my_face = [] frame = esp32_cam.video() if (frame_count % frame_interval) == 0: faces = face_recognition.identify(frame) # Check our current fps end_time = time.time() if (end_time - start_time) > fps_display_interval: frame_rate = int(frame_count / (end_time - start_time)) start_time = time.time() frame_count = 0 add_overlays(frame, faces, frame_rate) frame_count += 1 cv2.imshow('Video', frame) my_face = [] for i in faces: my_face.append(i.name) if ('XR' in my_face) and ('XR' not in my_name): screen.screen() if ('XR' not in my_face) and ('XR' in my_name): screen.screen() my_name = my_face if cv2.waitKey(1) & 0xFF == ord('q'): break # When everything is done, release the capture #video_capture.release() cv2.destroyAllWindows() def parse_arguments(argv): parser = argparse.ArgumentParser() parser.add_argument('--debug', action='store_true', help='Enable some debug outputs.') return parser.parse_args(argv) if __name__ == '__main__': main(parse_arguments(sys.argv[1:])) - face.py
# coding=utf-8 """Face Detection and Recognition""" # MIT License # # Copyright (c) 2017 Fran?ois Gervais # # This is the work of David Sandberg and shanren7 remodelled into a # high level container. It's an attempt to simplify the use of such # technology and provide an easy to use facial recognition package. # # https://github.com/davidsandberg/facenet # https://github.com/shanren7/real_time_face_recognition # # Permission is hereby granted, free of charge, to any person obtaining a copy # of this software and associated documentation files (the "Software"), to deal # in the Software without restriction, including without limitation the rights # to use, copy, modify, merge, publish, distribute, sublicense, and/or sell # copies of the Software, and to permit persons to whom the Software is # furnished to do so, subject to the following conditions: # # The above copyright notice and this permission notice shall be included in all # copies or substantial portions of the Software. # # THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR # IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, # FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE # AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER # LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, # OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE # SOFTWARE. import pickle import os import cv2 import numpy as np import tensorflow as tf from scipy import misc import align.detect_face import facenet gpu_memory_fraction = 0.3 facenet_model_checkpoint = "d://VS Code/facenet-master/src/models/20180408-102900" classifier_model = "d://VS Code/my_facenet/my_classifier_2.pkl" debug = False class Face: def __init__(self): self.name = None self.bounding_box = None self.image = None self.container_image = None self.embedding = None class Recognition: def __init__(self): self.detect = Detection() self.encoder = Encoder() self.identifier = Identifier() def add_identity(self, image, person_name): faces = self.detect.find_faces(image) if len(faces) == 1: face = faces[0] face.name = person_name face.embedding = self.encoder.generate_embedding(face) print(face.embedding) return faces def identify(self, image): faces = self.detect.find_faces(image) for i, face in enumerate(faces): if debug: cv2.imshow("Face: " + str(i), face.image) face.embedding = self.encoder.generate_embedding(face) face.name = self.identifier.identify(face) return faces class Identifier: def __init__(self): with open(classifier_model, 'rb') as infile: self.model, self.class_names = pickle.load(infile) def identify(self, face): if face.embedding is not None: predictions = self.model.predict_proba([face.embedding]) i = 0 while i < len(predictions[0]): if predictions[0][i] > 0.6: break i += 1 else: return None print(predictions) best_class_indices = np.argmax(predictions, axis=1) print(best_class_indices[0]) return self.class_names[best_class_indices[0]] class Encoder: def __init__(self): self.sess = tf.Session() with self.sess.as_default(): facenet.load_model(facenet_model_checkpoint) def generate_embedding(self, face): # Get input and output tensors images_placeholder = tf.get_default_graph().get_tensor_by_name("input:0") embeddings = tf.get_default_graph().get_tensor_by_name("embeddings:0") phase_train_placeholder = tf.get_default_graph().get_tensor_by_name("phase_train:0") prewhiten_face = facenet.prewhiten(face.image) # Run forward pass to calculate embeddings feed_dict = {images_placeholder: [prewhiten_face], phase_train_placeholder: False} return self.sess.run(embeddings, feed_dict=feed_dict)[0] class Detection: # face detection parameters minsize = 20 # minimum size of face threshold = [0.6, 0.7, 0.7] # three steps's threshold factor = 0.709 # scale factor def __init__(self, face_crop_size=160, face_crop_margin=32): self.pnet, self.rnet, self.onet = self._setup_mtcnn() self.face_crop_size = face_crop_size self.face_crop_margin = face_crop_margin def _setup_mtcnn(self): with tf.Graph().as_default(): gpu_options = tf.GPUOptions(per_process_gpu_memory_fraction=gpu_memory_fraction) sess = tf.Session(config=tf.ConfigProto(gpu_options=gpu_options, log_device_placement=False)) with sess.as_default(): return align.detect_face.create_mtcnn(sess, None) def find_faces(self, image): faces = [] bounding_boxes, _ = align.detect_face.detect_face(image, self.minsize, self.pnet, self.rnet, self.onet, self.threshold, self.factor) for bb in bounding_boxes: face = Face() face.container_image = image face.bounding_box = np.zeros(4, dtype=np.int32) img_size = np.asarray(image.shape)[0:2] face.bounding_box[0] = np.maximum(bb[0] - self.face_crop_margin / 2, 0) face.bounding_box[1] = np.maximum(bb[1] - self.face_crop_margin / 2, 0) face.bounding_box[2] = np.minimum(bb[2] + self.face_crop_margin / 2, img_size[1]) face.bounding_box[3] = np.minimum(bb[3] + self.face_crop_margin / 2, img_size[0]) cropped = image[face.bounding_box[1]:face.bounding_box[3], face.bounding_box[0]:face.bounding_box[2], :] face.image = misc.imresize(cropped, (self.face_crop_size, self.face_crop_size), interp='bilinear') faces.append(face) return faces - esp32_cam.py
import cv2 def video(): cap = cv2.VideoCapture("http://192.168.137.81:81/stream") while cap.isOpened(): ok, frame = cap.read() if not ok: break break cap.release() return frame if __name__ == '__main__': video() - screen.py
import pyautogui def screen(): pyautogui.keyDown('alt') pyautogui.press('tab') pyautogui.keyUp('alt') if __name__ == '__main__': screen()