十二章------支持向量机(SVM)
12.1 优化目标
支持向量机的cost function:

但通常把1/m去除,因为1/m是一个常数;
SVM的总体最优目标:


12.2 最大间隔的直接理解
支持向量机有更高的要求,并不是恰好能正确分类就行,所以θ的转置乘以x不是略大于0就可以,而是将其变换大于等于1.这就相当于在svm中构建了一个安全因子,一个安全间距。

当C取值很大时,为求得最小的min,我们迫切需要方括号内的值趋于0,就有如下所示的情况:

此种情况下可得到一个不同的决定边界,下图中黑色的线为SVM所得到的决定边界,而相比于绿色和紫色的决策边界更加稳健,这两条决策边界挨着样本来分开正样本与负样本,看起来效果都不太好。
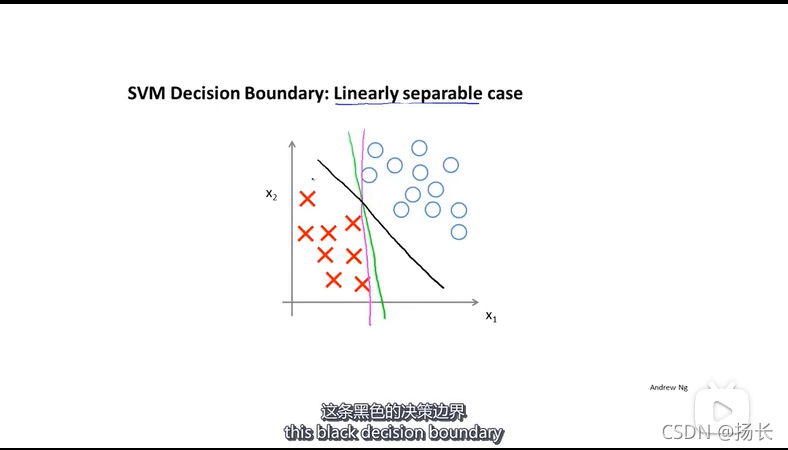
黑色边界有样本之间拥有更大的距离(即间距,支持向量机的间距),这使得SVM具有鲁棒性(鲁棒性:对于异常数据也能保持稳定和可靠的性质),SVM有时也被称为大间距分类器;
12.3 SVM背后的数学知识
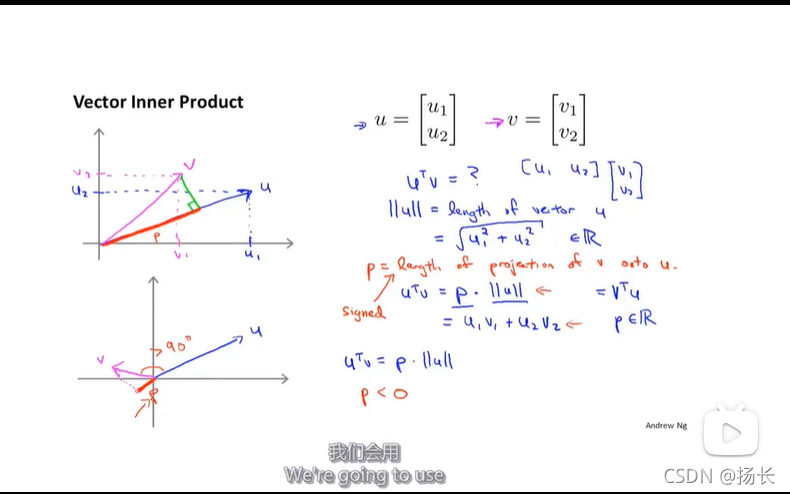
1.向量的内积
p是向量v在向量u上的投影长度,u’v=p.||u||;
p是有符号的,即可能是正值也可能是负值,当u,v的夹角小于90度时,p的值为正值;当u,v的夹角大于90度时,p的值为负值。
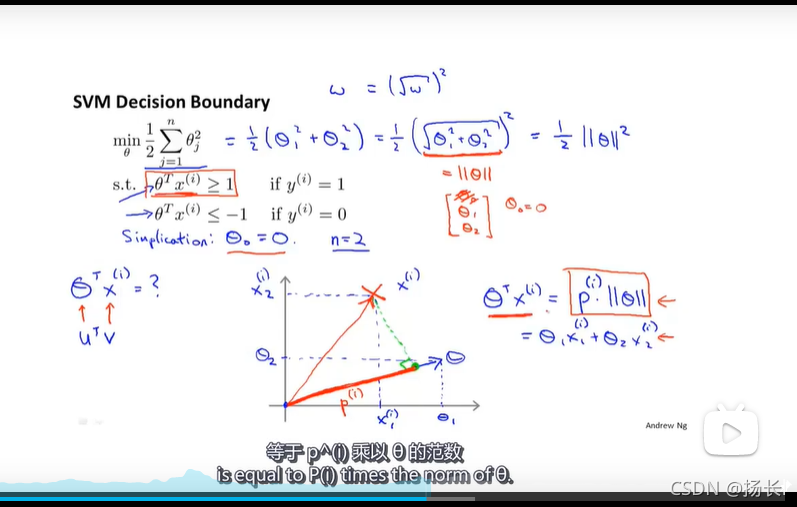
SVM最终会找到最大间距分类器的原因:
SVM的决策边界要使得参数θ的欧氏距离最小,即满足min1/2(||θ||^2),而参数向量θ是垂直与决策边界的,p(i)为样本X到θ的投影,当p(i)很大时,||θ||便可以取更小的值(p(i)θ>=0);它试图最大化这些p(i)范数,也就是训练样本到决策边界的距离。而p(i)即为我们所求得的最大间距(margin),所以这就是SVM会找到最大间距分类器的原因。如下图中右图所示:

θ_0=0,即是令决策边界通过原点;
12.4 核函数
1.定义:
2.给定一个x,我们用f1来表示x与L1的相似度:f1=similaity(x,l^(1));同样f2与f3也是类似定义;
Notice:相似度函数用数学家的术语来说就是一个核函数(kernal function),此处用的核函数为高斯核函数。用标记K(x,l^(i))表示核函数。

2.核函数与相似度
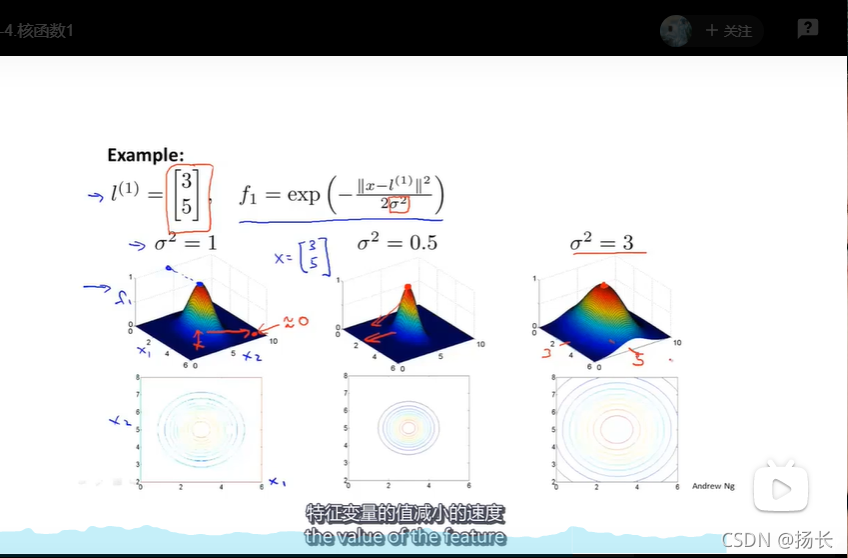
如果x非常接近于l(1),即二者之间距离较近,则||x-l(1)||的值便趋于0,则核函数得到的结果便约等于1;
如果x离l(1)非常远的话,则||x-l(1)||的结果会是一个很大的值,而e的负无穷次方趋于0,则核函数得到的结果便约等于0;

σ参数的作用:该参数的大小会影响特征变量X的值减小的速度;σ越大,特征变量的减小速度越慢;σ越小,特征变量的减小速度越快,如下图所示:

通过核函数来定义新的特征变量,从而训练复杂的非线性边界;
3.选择标记点(Choosing the landmarks)
Wher to get l^(1) , l(2),l(3),…?
实际问题中,我们的想法是:将选取样本点,直接使用我们拥有的每一个样本点,直接将训练样本作为标记点;例如:如果我们有一个训练样本点x1,那么我们将在这个训练样本点完全相同的位置上,选作我的第一个标记点;如果我有另一个训练样本x2,那么第二个标记点则在与第二个样本点一致的位置上;
这种选择标记点的方法说明特征函数基本上是在描述每一个样本距离样本集中其他样本的距离。
4.SVM with Kernels

通过核函数得到的f^(i)就是我们用于描述训练样本的特征向量。

5. SVM parameters
(1)如何选择SVM算法中的正则化参数C(=1/λ)
Large C (small λ):Lower bias, high variance.偏向于过拟合
Small C (large λ):Higer bias, low variance,偏向于欠拟合
(2)σ^2的选择
Large σ^2:Features f_i vary (变化) more smoothly;
Higher bias,lower variance.
Small σ^2:Features f_i vary less smoothly;
Lower bias, higer variance.

-
Use SVM software package to solve for parameters θ.

NOTICE:如果你有大小不一样的特征变量,很重要的一件事就是在使用高斯函数之前将这些特征变量的大小按比例归一化;原因:如果假设在计算x和l之间的范数||x-l||2时,令v=x-l;则||v||2=v1^(2) + v2(2)+(v3)2+…+(vn)^2
=(x1-l1)^2 + (x2-l2)^2 + … + (xn - ln)^2.
现在如果你的特征向量的值的范围很不一样,例如:房价预测x1为房屋面积,x2为卧室个数,则||x-l||^2的值完全是由房屋大小所决定,从而忽略了卧室的数量。为了避免这种情况,使机器学习算法能够得到很好的实现,就需要进一步地缩放比例,这将会保证SVM能考虑到所有不同的特征变量;

-
Other choices of kernal
Many off-the-shelf kernels available:
----Polynomial kernal(多项式核函数):
k(x,l) = (x‘l)^2;
or k=(x’l)^3;
or k=(x’l+1)^3;
or k = (x’l + 5)^4;
多项式核函数实际上有两个参数,一个是常数参数(如上式的1,3),一个是多项式的次数;
多项式核函数的常见形式(x‘l +constant)^degree;
但使用的不多,效果不如高斯核函数

-
Logistic regression vs. SVM(逻辑回归与SVM的使用选择对比)
n:特征数,m:训练样本数
(1) 如果n的值很大(相对于m来说):使用Logistic regression or SVM without a kernel“”(“liner kernel”);
(2) 如果n的值很小,m是一个大小合适的数值:Use SVM with Gaussian kernel;
(3) 如果n的值很小,m的值很大:
创建或者添加更多的特征变量,然后使用Logistic regression or SVM without a kernel

