����ѧϰ����:���Իع� �� Softmax �ع�;����֪����Ƿ��Ϻ���ϡ�Dropout����ֵ�ȶ��Եȡ�
Ŀ¼
һ�����Իع�
�ع�:Ϊһ�������Ա����������֮���ϵ��ģ�ķ������ع鳣������ʾ�������֮��Ĺ�ϵ��
���Իع����ڼ����ļ���:����,�����Ա���x�������y֮��Ĺ�ϵ�����Ե�,��y���Ա�ʾΪx��Ԫ�صļ�Ȩ��,����ͨ�����������۲�ֵ��һЩ����;���,���Ǽ����κ��������Ƚ�����,��������ѭ��̬�ֲ���

����ģ�Ϳ��Կ�������������
��ʧ����:����Ԥ������,�ܹ�����Ŀ���ʵ��ֵ��Ԥ��ֵ֮��IJ�ࡣͨ�����ǻ�ѡ��Ǹ�����Ϊ��ʧ,����ֵԽС��ʾ��ʧԽС,����Ԥ��ʱ����ʧΪ0���ع���������õ���ʧ������ƽ��������������i��Ԥ��ֵΪ(i),����Ӧ����ʵ��ǩΪy(i)ʱ,ƽ�������Զ���Ϊ:
![]()
��������������ʵIJ��,����������ʽ������һЩ,����Ϊ�����Ƕ���ʧ��������ϵ��Ϊ1.

��ʽ��(������):
�����Իع������ļ�������ڽ�����,�����������е����ⶼ���ڽ����⡣��������Խ��кܺõ���ѧ����,������������ƺ��ϸ�,��������Ӧ�������ѧϰ�
�ܽ�:
1.���Իع��Ƕ�Nά����ļ�Ȩ,���ƫ��
2.ʹ��ƽ����ʧ������Ԥ��ֵ����ʵֵ�IJ���
3.���Իع�����ʽ��
4.���Իع���Կ����ǵ���������
ע:iterator:������
���������Ż�����
1.С��������ݶ��½�
�ݶ��½�:ͨ�����ϵ�����ʧ�����ݼ��ķ����ϸ��²�����������
�ݶ��½�����÷��Ǽ�����ʧ����(���ݼ���������������ʧ��ֵ)����ģ�Ͳ����ĵ���(������Ҳ���Գ�Ϊ�ݶ�)����ʵ���е�ִ�п��ܺ���:��Ϊ��ÿһ�θ��²���֮ǰ,��������������ݼ������,ͨ������ÿ����Ҫ������µ�ʱ�������ȡһС������,���ֱ������С��������ݶ��½���
��ÿ�ε�����,�������һ��С����B,�ɹ̶�������ѵ��������ɡ�Ȼ��,���Ǽ���С������ƽ����ʧ����ģ�Ͳ����ĵ���(Ҳ���Գ�Ϊ�ݶ�)�����,���ǽ��ݶȳ���һ��Ԥ��ȷ����������,���ӵ�ǰ������ֵ�м�����
�������ѧ��ʽ��ʾ��һ���¹���(?��ʾƫ����):
![]()
�ܽ�һ��,�㷨�IJ�������:(1)��ʼ��ģ�Ͳ�����ֵ,�������ʼ��;(2)�����ݼ��������ȡС�����������ڸ��ݶȵķ����ϸ��²���,�����ϵ�����һ���衣
|B|��ʾÿ��С�����е�������,��Ϊ������С����Ϊѧϰ����������С��ѧϰ�ʵ�ֵͨ�����ֶ�Ԥ��ָ��,������ͨ��ģ��ѵ���õ��ġ���Щ���Ե���������ѵ�������и��µIJ�����Ϊ��������������ѡ�����Ĺ��̡�������ͨ�������Ǹ���ѵ�����������������,��ѵ������������ڶ�������֤���ݼ��������õ��ġ�
�ܽ�:

����softmax�ع�
�ع����һ������ֵ,������Ԥ��һ����ɢ���?
�����Իع�һ��,softmax�ع�Ҳ��һ�����������硣���ڼ���ÿ�����ȡ������������,����softmax�ع�������Ҳ��ȫ���Ӳ㡣

���ڸ�����������������x,�������Ȩ���������������о���-�����˷��ټ���ƫ��b�õ��ġ�
��ȡ����Ҫ�����ǽ�ģ�͵��������Ϊ���ʡ��Ż���������۲����ݵĸ��ʡ�Ϊ�˵õ�Ԥ����,����һ����ֵ,��ѡ����������ʵı�ǩ��
ģ�͵����������Ϊ������ j �ĸ��ʡ�Ȼ�����ǿ���ѡ�����������ֵ�����
��ΪԤ�⡣
Ҫ�������Ϊ����,���뱣֤���κ������ϵ�������ǷǸ������ܺ�Ϊ1������,��Ҫһ��ѵ��Ŀ��,������ģ�;��ع��Ƹ��ʡ��ڷ��������0.5������������,��Щ������Ҫ��һ��ʵ��������Ԥ����ࡣ ������Գ�ΪУ��
Ϊ�˽�δ��һ����Ԥ��任Ϊ�Ǹ������ܺ�Ϊ1,ͬʱҪ��ģ�ͱ��ֿɵ������ȶ�ÿ��δ��һ����Ԥ������,��ȷ������Ǹ���Ϊ��ȷ������������ܺ�Ϊ1,�ٶ�ÿ�����ݺ�Ľ���������ǵ��ܺ͡�����ʽ:

���,������Ϊһ����ȷ�ĸ��ʷֲ���softmax���㲻��ı�δ��һ����Ԥ��o֮���˳��,ֻ��ȷ�������ÿ�����ĸ��ʡ����,��Ԥ�������,�Կ�������ʽ��ѡ�����п��ܵ����
![]()
softmax��һ�������Ժ���,��softmax�ع�������Ȼ�����������ķ���任���������,softmax�ع���һ������ģ�͡�
softmax����:
��ʧ����:��ʧ����������Ԥ����ʵ�Ч���������������Ȼ����,������Ϊ���Իع��еľ������Ŀ���ṩ����֤��ʱ�����ĸ�����ȫ��ͬ��
������Ȼ:
��������Ϊ������������x��ÿ����Ĺ����������ʡ������������ݼ�{X,Y}����n������,��������i����������������x(i)�Ͷ��ȱ�ǩ����y(i)��ɡ����Խ�����ֵ��ʵ��ֵ���бȽ�:
?
?���������Ȼ����,���P(Y�OX),�൱����С����������Ȼ:
?
?����,���κα�ǩy��ģ��Ԥ��,��ʧ����Ϊ:
?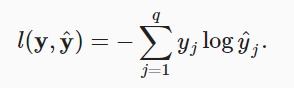
?��ʽ�е���ʧ����ͨ������Ϊ��������ʧ��?
�ܽ�:

�ġ�����֪��
��֪��:��֪����һ��������ģ�͡�
����㷨:��������Ժ��w,b���и���,ֱ�����ҷ�����ȷ,�ȼ���ʹ��������СΪ1���ݶ��½���
ֻ�ܲ������Էָ���,��˲������XOR����,������AI�ĵ�һ�κ�����
���ز�:���ز��С�dz�����,�������á�
�����ز�:

Q:Ϊʲô��Ҫ�����Լ����?
A: ������Ӽ����,����һ��������ģ��,���Ƕ��ṹ��
�������ѡ��:
Sigmoid�����:
![]()
Tanh�����:
![]()
ReLU�����:rectified linear unit
![]()
����֪���������������֮������һ������ȫ���ӵ����ز�,��ͨ�������ת�����ز�������
���õļ��������ReLU������sigmoid������tanh������
�������:softmax+���ز�=����֪��

����:k,��output��һ��softmax��
��������������ز�:
?
������������������,���һ���������Ҫ���������һ��һ�������һ��,һ�㲻����ѹ��������,����ʧ��Ϣ��
�ܽ�:
1. ����֪��ʹ�����ز�ͼ�������õ�������ģ��;
2. ���ü������sigmoid,tanh,ReLU;
3. ʹ��Softmax�������������;
4. ������Ϊ���ز���,�������ز��С��
�塢ģ��ѡ��Ƿ��Ϻ����
ѵ����� vs �������:ģ����ѵ�������ϵ���� vs ģ���������ݵ����
��֤���ݼ� vs �������ݼ�:��������ģ�ͺû�(ע�ⲻҪ��ѵ�����ݻ���һ��) vs ֻ��һ��
K�۽�����֤:��ѵ������ϡȱʱ,�������ṩ�㹻������������һ�����ʵ���֤����ԭʼѵ�����ݱ��ֳ�K�����ص����Ӽ���Ȼ��ִ��K��ģ��ѵ������֤,ÿ����K?1���Ӽ��Ͻ���ѵ��,����ʣ���һ���Ӽ�(�ڸ�����û������ѵ�����Ӽ�)�Ͻ�����֤�����,ͨ����K��ʵ��Ľ��ȡƽ��������ѵ������֤��
Ƿ���or�����:

����������Ӱ��ģ�ͷ���������:
-
�ɵ������������������ɵ��������������ܴ�ʱ,ģ��������������ϡ�
-
�������õ�ֵ����Ȩ�ص�ȡֵ��Χ�ϴ�ʱ,ģ�Ϳ��ܸ�������ϡ�
-
ѵ����������������ʹģ�ͺܼ�,Ҳ���������ֻ����һ�������������ݼ����������һ��������������������ݼ�����Ҫһ����������ģ�͡�
�ܽ�:
-
���ڲ��ܻ���ѵ����������Ʒ������,��˼���С��ѵ������һ����ζ�ŷ������ļ�С������ѧϰģ����Ҫע���ֹ�����,��ʹ�÷��������С��
-
��֤����������ģ��ѡ��,�����ܹ��������ʹ������
-
Ƿ�����ָģ������������ѵ�����������ָѵ�����ԶС����֤��
-
Ӧ��ѡ��һ�����Ӷ��ʵ���ģ��,����ʹ�����������ѵ��������
-
ʵ����һ�㿿�۲�ѵ��������֤��
����Ȩ��˥��
Ȩ��˥���dz����Ĵ�������ϵķ�����
����ģ�ͷ�Χ������:1 ģ�͵IJ�����,2 ÿ������ѡ��ֵ�ķ�ΧС��Ȩ��˥���Ǻ��ߡ�
![]()

?
-
�����Ǵ�������ϵij��÷�������ѵ��������ʧ�����м���ͷ���,�Խ���ѧϰ����ģ�͵ĸ��Ӷȡ�������Ȩ���ǿ���ģ���Ӷȵij�������
-
Ȩ��˥��ͨ��L2������ʹ��ģ�Ͳ����������,�Ӷ�����ģ���Ӷȡ�
�ߡ� Dropout������
һ���õ�ģ����Ҫ���������ݵ��Ŷ�³��![]()
?�����������м��������ȼ�������,���������ڲ�֮�����������ͨ������������ȫ���Ӳ������ϡ�
?
��������һЩ����������0������ģ���Ӷ�,���������ǿ���ģ���Ӷȵij�������
������ֻ��ѵ����ʹ��,��Ϊ����ʱȨ�ز���Ҫ�����仯,ѵ��ʱ����Ҫ��
?�ˡ���ֵ�ȶ��Ժ�ģ�ͳ�ʼ��
-
�ݶ���ʧ�ͱ�ը����������г��������⡣�ڲ�����ʼ��ʱ��Ҫ�dz�С��,��ȷ���ݶȺͲ������Եõ��ܺõĿ��ơ�
-
��Ҫ������ʽ�ij�ʼ��������ȷ����ʼ�ݶȼȲ�̫��Ҳ��̫С��
-
ReLU������������ݶ���ʧ����,�������Լ���������
-
�����ʼ���DZ�֤�ڽ����Ż�ǰ���ƶԳ��ԵĹؼ���
-
Xavier��ʼ������,����ÿһ��,����ķ��������������Ӱ��,�κ��ݶȵķ�������������Ӱ�졣
?�š�kaggle����Ԥ��
�����б���,������ԭ��,��ͨ���ٸ��¡�
����:���ܱ����ܸ����ҵ�ѧϰ��״̬,�ܹ���������ѧϰ,��֪ʶ���϶�,����Ҫ����������䡣