摘要
神经网络由对数据执行操作的层/模块组成。 torch.nn 命名空间提供了构建自己的神经网络所需的所有构建块。 PyTorch 中的每个模块都是 nn.Module 的子类。 神经网络是一个模块本身,由其他模块(层)组成。 这种嵌套结构允许轻松构建和管理复杂的架构。
在以下部分中,我们将构建一个神经网络来对 FashionMNIST 数据集中的图像进行分类。
import os
import torch
from torch import nn
from torch.utils.data import DataLoader
from torchvision import datasets, transforms
获取用于训练的设备
我们希望能够在 GPU 等硬件加速器上训练我们的模型(如果可用)。 让我们检查一下 torch.cuda 是否可用,否则我们继续使用 CPU。
device = 'cuda' if torch.cuda.is_available() else 'cpu'
print('Using {} device'.format(device))
输出:
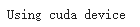
定义类
我们通过继承 nn.Module 来定义我们的神经网络,并在_init_ 中初始化神经网络层。 每个 nn.Module 子类都在 forward 方法中实现对输入数据的操作。
class NeuralNetwork(nn.Module):
def __init__(self):
super(NeuralNetwork, self).__init__()
self.flatten = nn.Flatten()
self.linear_relu_stack = nn.Sequential(
nn.Linear(28*28, 512),
nn.ReLU(),
nn.Linear(512, 512),
nn.ReLU(),
nn.Linear(512, 10),
)
def forward(self, x):
x = self.flatten(x)
logits = self.linear_relu_stack(x)
return logits
我们创建一个 NeuralNetwork 的实例,并将其移动到设备上,并打印其结构。
model = NeuralNetwork().to(device)
print(model)

为了使用模型,我们将输入数据传递给它。 这将执行模型的转发,以及一些后台操作。 不要直接调用model.forward()!
在输入上调用模型会返回一个 10 维张量,其中包含每个类的原始预测值。 我们通过将其传递给 nn.Softmax 模块的实例来获得预测概率。
X = torch.rand(1, 28, 28, device=device)
logits = model(X)
pred_probab = nn.Softmax(dim=1)(logits)
y_pred = pred_probab.argmax(1)
print(f"Predicted class: {y_pred}")
输出:
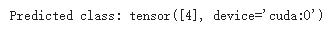
模型层
让我们分解 FashionMNIST 模型中的层。 为了说明这一点,我们将取一个由 3 张大小为 28x28 的图像组成的小批量样本,看看当我们通过网络传递它时会发生什么。
input_image = torch.rand(3,28,28)
print(input_image.size())
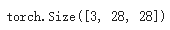
nn.Flatten
我们初始化 nn.Flatten 层以将每个 2D 28x28 图像转换为 784 个像素值的连续数组(保持小批量维度(dim=0))。
flatten = nn.Flatten()
flat_image = flatten(input_image)
print(flat_image.size())
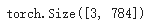
nn.Linear
线性层是一个模块,它使用其存储的权重和偏差对输入应用线性变换。
layer1 = nn.Linear(in_features=28*28, out_features=20)
hidden1 = layer1(flat_image)
print(hidden1.size())
nn.ReLU
非线性激活是在模型的输入和输出之间创建复杂映射的原因。 它们在线性变换之后应用以引入非线性,帮助神经网络学习各种各样的现象。
在这个模型中,我们在线性层之间使用了 nn.ReLU,但还有其他激活函数可以在模型中引入非线性。
print(f"Before ReLU: {hidden1}\n\n")
hidden1 = nn.ReLU()(hidden1)
print(f"After ReLU: {hidden1}")

nn.Sequential
nn.Sequential 是一个有序的模块容器。 数据按照定义的相同顺序通过所有模块。 您可以使用顺序容器来组合一个像 seq_modules 这样的快速网络。
seq_modules = nn.Sequential(
flatten,
layer1,
nn.ReLU(),
nn.Linear(20, 10)
)
input_image = torch.rand(3,28,28)
logits = seq_modules(input_image)
nn.Softmax
神经网络的最后一个线性层返回 logits - [-infty, infty] 中的原始值 - 传递给 nn.Softmax 模块。 logits 被缩放到值 [0, 1],代表模型对每个类别的预测概率。 dim 参数指示值的总和必须为 1 的维度。
softmax = nn.Softmax(dim=1)
pred_probab = softmax(logits)
模型参数
神经网络内的许多层都是参数化的,即具有在训练期间优化的相关权重和偏差。 子类 nn.Module 会自动跟踪模型对象中定义的所有字段,并使用模型的 parameters() 或 named_pa??rameters() 方法使所有参数都可以访问。
在这个例子中,我们迭代每个参数,并打印它的大小和它的值的预览。
print("Model structure: ", model, "\n\n")
for name, param in model.named_parameters():
print(f"Layer: {name} | Size: {param.size()} | Values : {param[:2]} \n")
Model structure: NeuralNetwork(
(flatten): Flatten(start_dim=1, end_dim=-1)
(linear_relu_stack): Sequential(
(0): Linear(in_features=784, out_features=512, bias=True)
(1): ReLU()
(2): Linear(in_features=512, out_features=512, bias=True)
(3): ReLU()
(4): Linear(in_features=512, out_features=10, bias=True)
)
)
Layer: linear_relu_stack.0.weight | Size: torch.Size([512, 784]) | Values : tensor([[-0.0302, -0.0320, 0.0341, ..., -0.0228, -0.0337, -0.0105],
[-0.0206, 0.0327, 0.0078, ..., 0.0270, 0.0267, 0.0206]],
device='cuda:0', grad_fn=<SliceBackward>)
Layer: linear_relu_stack.0.bias | Size: torch.Size([512]) | Values : tensor([-0.0042, 0.0142], device='cuda:0', grad_fn=<SliceBackward>)
Layer: linear_relu_stack.2.weight | Size: torch.Size([512, 512]) | Values : tensor([[ 3.0393e-05, 1.5742e-02, 1.5932e-02, ..., 2.2430e-02,
5.0596e-04, 2.0169e-02],
[ 3.1222e-02, -5.3052e-03, -8.3699e-03, ..., -5.5455e-03,
-2.8178e-03, 7.5235e-03]], device='cuda:0', grad_fn=<SliceBackward>)
Layer: linear_relu_stack.2.bias | Size: torch.Size([512]) | Values : tensor([0.0293, 0.0213], device='cuda:0', grad_fn=<SliceBackward>)
Layer: linear_relu_stack.4.weight | Size: torch.Size([10, 512]) | Values : tensor([[ 0.0160, 0.0135, -0.0226, ..., 0.0341, -0.0118, -0.0081],
[-0.0136, -0.0039, -0.0421, ..., -0.0386, 0.0155, -0.0322]],
device='cuda:0', grad_fn=<SliceBackward>)
Layer: linear_relu_stack.4.bias | Size: torch.Size([10]) | Values : tensor([-0.0071, 0.0143], device='cuda:0', grad_fn=<SliceBackward>)
