前言
??deepsort之所以可以大量避免IDSwitch,是因为deepsort算法中特征提取网络可以将目标检测框中的特征提取出来并保存,在目标被遮挡后又从新出现后,利用前后的特征对比可以将遮挡的后又出现的目标和遮挡之前的追踪的目标从新找到,大大减少了目标在遮挡后,追踪失败的可能。
一、特征提取网络
? ? ? ? 首先上特征提取模型的代码。特征提取的模型有很多,可以替换特征提取模型网络。
import torch
import torch.nn as nn
import torch.nn.functional as F
class BasicBlock(nn.Module):
def __init__(self, c_in, c_out,is_downsample=False):
super(BasicBlock,self).__init__()
self.is_downsample = is_downsample
if is_downsample:
self.conv1 = nn.Conv2d(c_in, c_out, 3, stride=2, padding=1, bias=False)
else:
self.conv1 = nn.Conv2d(c_in, c_out, 3, stride=1, padding=1, bias=False)
self.bn1 = nn.BatchNorm2d(c_out)
self.relu = nn.ReLU(True)
self.conv2 = nn.Conv2d(c_out,c_out,3,stride=1,padding=1, bias=False)
self.bn2 = nn.BatchNorm2d(c_out)
if is_downsample:
self.downsample = nn.Sequential(
nn.Conv2d(c_in, c_out, 1, stride=2, bias=False),
nn.BatchNorm2d(c_out)
)
elif c_in != c_out:
self.downsample = nn.Sequential(
nn.Conv2d(c_in, c_out, 1, stride=1, bias=False),
nn.BatchNorm2d(c_out)
)
self.is_downsample = True
def forward(self,x):
y = self.conv1(x)
y = self.bn1(y)
y = self.relu(y)
y = self.conv2(y)
y = self.bn2(y)
if self.is_downsample:
x = self.downsample(x)
return F.relu(x.add(y),True)
def make_layers(c_in,c_out,repeat_times, is_downsample=False):
blocks = []
for i in range(repeat_times):
if i ==0:
blocks += [BasicBlock(c_in,c_out, is_downsample=is_downsample),]
else:
blocks += [BasicBlock(c_out,c_out),]
return nn.Sequential(*blocks)
class Net(nn.Module):
def __init__(self, num_classes=751, reid=False):
super(Net,self).__init__()
# 3 128 64
self.conv = nn.Sequential(
nn.Conv2d(3,64,3,stride=1,padding=1),
nn.BatchNorm2d(64),
nn.ReLU(inplace=True),
# nn.Conv2d(32,32,3,stride=1,padding=1),
# nn.BatchNorm2d(32),
# nn.ReLU(inplace=True),
nn.MaxPool2d(3,2,padding=1),
)
# 32 64 32
self.layer1 = make_layers(64,64,2,False)
# 32 64 32
self.layer2 = make_layers(64,128,2,True)
# 64 32 16
self.layer3 = make_layers(128,256,2,True)
# 128 16 8
self.layer4 = make_layers(256,512,2,True)
# 256 8 4
self.avgpool = nn.AvgPool2d((8,4),1)
# 256 1 1
self.reid = reid
self.classifier = nn.Sequential(
nn.Linear(512, 256),
nn.BatchNorm1d(256),
nn.ReLU(inplace=True),
nn.Dropout(),
nn.Linear(256, num_classes),
)
def forward(self, x):
x = self.conv(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
x = self.avgpool(x)
x = x.view(x.size(0),-1)
# B x 128
if self.reid:
x = x.div(x.norm(p=2,dim=1,keepdim=True))
return x
# classifier
x = self.classifier(x)
return x
if __name__ == '__main__':
net = Net()
x = torch.randn(4,3,128,64)
y = net(x)
import ipdb; ipdb.set_trace()
二、数据集的准备
????????Market-1501 数据集是在清华大学校园中采集于2015年构建并公开。它包括由6个摄像头(其中5个高清 摄像头和1个低分辨率摄像头)拍摄到的1501个行人、32668个检测到的行人矩形框。每个行人至少有2 个摄像头捕捉到,并且在一个摄像头中可能具有多张图像。训练集有751人,包含12936张图像,平均 每个人有17.2张训练数据;测试集有750人,包含19732张图像,平均每个人有26.3张测试数据。
bounding_box_test : 测试集
bounding_box_train : 训练集
query : 共有750个身份。每个摄像机随机选择一个查询图像
gt_query : 包含实际标注
gt_bbox : 手绘边框,主要用于判断自动检测器 DPM 边界框是否良好
? ? ? ? 数据集如下图所示:
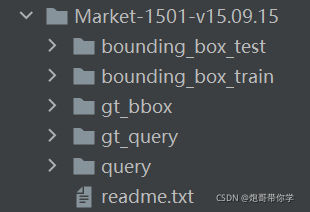

? ? ? ? ?可以利用如下代码将数据集划分为训练集和测试集:
import os
from shutil import copyfile
# You only need to change this line to your dataset download path
download_path = './Market-1501-v15.09.15'
if not os.path.isdir(download_path):
print('please change the download_path')
save_path = download_path + '/pytorch'
if not os.path.isdir(save_path):
os.mkdir(save_path)
#-----------------------------------------
#query
query_path = download_path + '/query'
query_save_path = download_path + '/pytorch/query'
if not os.path.isdir(query_save_path):
os.mkdir(query_save_path)
for root, dirs, files in os.walk(query_path, topdown=True):
for name in files:
if not name[-3:]=='jpg':
continue
ID = name.split('_')
src_path = query_path + '/' + name
dst_path = query_save_path + '/' + ID[0]
if not os.path.isdir(dst_path):
os.mkdir(dst_path)
copyfile(src_path, dst_path + '/' + name)
#-----------------------------------------
#multi-query
query_path = download_path + '/gt_bbox'
# for dukemtmc-reid, we do not need multi-query
if os.path.isdir(query_path):
query_save_path = download_path + '/pytorch/multi-query'
if not os.path.isdir(query_save_path):
os.mkdir(query_save_path)
for root, dirs, files in os.walk(query_path, topdown=True):
for name in files:
if not name[-3:]=='jpg':
continue
ID = name.split('_')
src_path = query_path + '/' + name
dst_path = query_save_path + '/' + ID[0]
if not os.path.isdir(dst_path):
os.mkdir(dst_path)
copyfile(src_path, dst_path + '/' + name)
#-----------------------------------------
#gallery
gallery_path = download_path + '/bounding_box_test'
gallery_save_path = download_path + '/pytorch/gallery'
if not os.path.isdir(gallery_save_path):
os.mkdir(gallery_save_path)
for root, dirs, files in os.walk(gallery_path, topdown=True):
for name in files:
if not name[-3:]=='jpg':
continue
ID = name.split('_')
src_path = gallery_path + '/' + name
dst_path = gallery_save_path + '/' + ID[0]
if not os.path.isdir(dst_path):
os.mkdir(dst_path)
copyfile(src_path, dst_path + '/' + name)
#---------------------------------------
#train_all
train_path = download_path + '/bounding_box_train'
train_save_path = download_path + '/pytorch/train_all'
if not os.path.isdir(train_save_path):
os.mkdir(train_save_path)
for root, dirs, files in os.walk(train_path, topdown=True):
for name in files:
if not name[-3:]=='jpg':
continue
ID = name.split('_')
src_path = train_path + '/' + name
dst_path = train_save_path + '/' + ID[0]
if not os.path.isdir(dst_path):
os.mkdir(dst_path)
copyfile(src_path, dst_path + '/' + name)
#---------------------------------------
#train_val
train_path = download_path + '/bounding_box_train'
train_save_path = download_path + '/pytorch/train'
val_save_path = download_path + '/pytorch/test'
if not os.path.isdir(train_save_path):
os.mkdir(train_save_path)
os.mkdir(val_save_path)
for root, dirs, files in os.walk(train_path, topdown=True):
for name in files:
if not name[-3:]=='jpg':
continue
ID = name.split('_')
src_path = train_path + '/' + name
dst_path = train_save_path + '/' + ID[0]
if not os.path.isdir(dst_path):
os.mkdir(dst_path)
dst_path = val_save_path + '/' + ID[0] #first image is used as val image
os.mkdir(dst_path)
copyfile(src_path, dst_path + '/' + name)????????运行如代码以后会生成一个名为pytorch的文件,其中文件下生成train文件和test文件。如下图所示:
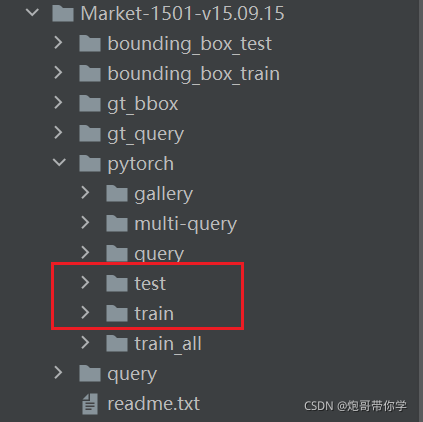
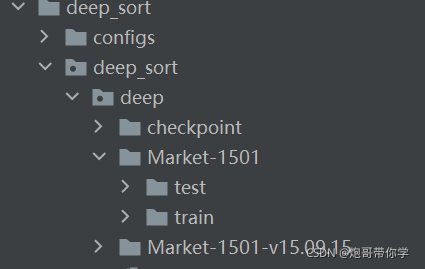
? ? ? ? ?在deep_sort/deep_sort/deep目录下新建一个Market-1501文件夹,将训练集和测试集放到该目录下。如下图所示:
三、特征提取模型训练? ? ? ?
? ? ? ? 数据集准备好了以后,此时可以利用deepsort代码中,train.py来训练模型。训练代码如下,将训练集和测试集的路径填入到第14行default中(一定要填写绝对路径,否则找不到路径)可以通过代码的第182行修改训练的轮数,默认训练轮数为40。
import argparse
import os
import time
import numpy as np
import matplotlib.pyplot as plt
import torch
import torch.backends.cudnn as cudnn
import torchvision
from model import Net
parser = argparse.ArgumentParser(description="Train on market1501")
parser.add_argument("--data-dir",default='data',type=str)
parser.add_argument("--no-cuda",action="store_true")
parser.add_argument("--gpu-id",default=0,type=int)
parser.add_argument("--lr",default=0.1, type=float)
parser.add_argument("--interval",'-i',default=20,type=int)
parser.add_argument('--resume', '-r',action='store_true')
args = parser.parse_args()
# device
device = "cuda:{}".format(args.gpu_id) if torch.cuda.is_available() and not args.no_cuda else "cpu"
if torch.cuda.is_available() and not args.no_cuda:
cudnn.benchmark = True
# data loading
root = args.data_dir
train_dir = os.path.join(root,"train")
test_dir = os.path.join(root,"test")
transform_train = torchvision.transforms.Compose([
torchvision.transforms.RandomCrop((128,64),padding=4),
torchvision.transforms.RandomHorizontalFlip(),
torchvision.transforms.ToTensor(),
torchvision.transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
])
transform_test = torchvision.transforms.Compose([
torchvision.transforms.Resize((128,64)),
torchvision.transforms.ToTensor(),
torchvision.transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
])
trainloader = torch.utils.data.DataLoader(
torchvision.datasets.ImageFolder(train_dir, transform=transform_train),
batch_size=64,shuffle=True
)
testloader = torch.utils.data.DataLoader(
torchvision.datasets.ImageFolder(test_dir, transform=transform_test),
batch_size=64,shuffle=True
)
num_classes = max(len(trainloader.dataset.classes), len(testloader.dataset.classes))
print("num_classes = %s" %num_classes)
# net definition
start_epoch = 0
net = Net(num_classes=num_classes)
if args.resume:
assert os.path.isfile("./checkpoint/ckpt.t7"), "Error: no checkpoint file found!"
print('Loading from checkpoint/ckpt.t7')
checkpoint = torch.load("./checkpoint/ckpt.t7")
# import ipdb; ipdb.set_trace()
net_dict = checkpoint['net_dict']
net.load_state_dict(net_dict)
best_acc = checkpoint['acc']
start_epoch = checkpoint['epoch']
net.to(device)
# loss and optimizer
criterion = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(net.parameters(), args.lr, momentum=0.9, weight_decay=5e-4)
best_acc = 0.
# train function for each epoch
def train(epoch):
print("\nEpoch : %d"%(epoch+1))
net.train()
training_loss = 0.
train_loss = 0.
correct = 0
total = 0
interval = args.interval
start = time.time()
for idx, (inputs, labels) in enumerate(trainloader):
# forward
inputs,labels = inputs.to(device),labels.to(device)
outputs = net(inputs)
loss = criterion(outputs, labels)
# backward
optimizer.zero_grad()
loss.backward()
optimizer.step()
# accumurating
training_loss += loss.item()
train_loss += loss.item()
correct += outputs.max(dim=1)[1].eq(labels).sum().item()
total += labels.size(0)
# print
if (idx+1)%interval == 0:
end = time.time()
print("[progress:{:.1f}%]time:{:.2f}s Loss:{:.5f} Correct:{}/{} Acc:{:.3f}%".format(
100.*(idx+1)/len(trainloader), end-start, training_loss/interval, correct, total, 100.*correct/total
))
training_loss = 0.
start = time.time()
return train_loss/len(trainloader), 1.- correct/total
def test(epoch):
global best_acc
net.eval()
test_loss = 0.
correct = 0
total = 0
start = time.time()
with torch.no_grad():
for idx, (inputs, labels) in enumerate(testloader):
inputs, labels = inputs.to(device), labels.to(device)
outputs = net(inputs)
loss = criterion(outputs, labels)
test_loss += loss.item()
correct += outputs.max(dim=1)[1].eq(labels).sum().item()
total += labels.size(0)
print("Testing ...")
end = time.time()
print("[progress:{:.1f}%]time:{:.2f}s Loss:{:.5f} Correct:{}/{} Acc:{:.3f}%".format(
100.*(idx+1)/len(testloader), end-start, test_loss/len(testloader), correct, total, 100.*correct/total
))
# saving checkpoint
acc = 100.*correct/total
if acc > best_acc:
best_acc = acc
print("Saving parameters to checkpoint/ckpt.t7")
checkpoint = {
'net_dict':net.state_dict(),
'acc':acc,
'epoch':epoch,
}
if not os.path.isdir('checkpoint'):
os.mkdir('checkpoint')
torch.save(checkpoint, './checkpoint/ckpt.t7')
return test_loss/len(testloader), 1.- correct/total
# plot figure
x_epoch = []
record = {'train_loss':[], 'train_err':[], 'test_loss':[], 'test_err':[]}
fig = plt.figure()
ax0 = fig.add_subplot(121, title="loss")
ax1 = fig.add_subplot(122, title="top1err")
def draw_curve(epoch, train_loss, train_err, test_loss, test_err):
global record
record['train_loss'].append(train_loss)
record['train_err'].append(train_err)
record['test_loss'].append(test_loss)
record['test_err'].append(test_err)
x_epoch.append(epoch)
ax0.plot(x_epoch, record['train_loss'], 'bo-', label='train')
ax0.plot(x_epoch, record['test_loss'], 'ro-', label='val')
ax1.plot(x_epoch, record['train_err'], 'bo-', label='train')
ax1.plot(x_epoch, record['test_err'], 'ro-', label='val')
if epoch == 0:
ax0.legend()
ax1.legend()
fig.savefig("train.jpg")
# lr decay
def lr_decay():
global optimizer
for params in optimizer.param_groups:
params['lr'] *= 0.1
lr = params['lr']
print("Learning rate adjusted to {}".format(lr))
def main():
total_epoches = 40
for epoch in range(start_epoch, start_epoch+total_epoches):
train_loss, train_err = train(epoch)
test_loss, test_err = test(epoch)
draw_curve(epoch, train_loss, train_err, test_loss, test_err)
if (epoch+1)%(total_epoches//2)==0:
lr_decay()
if __name__ == '__main__':
main()
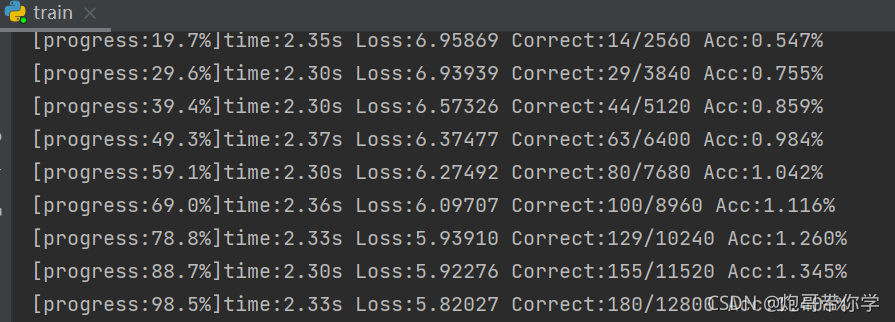
?????????运行如上代码,就可以训练特征提取网络了。特征提取网络训练过程如下图所示:
? ? ? ? ?训练完了以后,就可以在deep_sort/deep_sort/deep/checkpoint目录下获取一个新的特征提取网络。