���ر�Ҷ˹������
��Ҷ˹��������һ������㷨���ܳ�,�����㷨���Ա�Ҷ˹������Ϊ������
��ѧԭ��
��Ҷ˹����������Ӣ����ʦ����˹����Ҷ˹�ڡ����йػ����������⡷�����һ�ֹ�������������,��ʱ��û�б���ѧ���ձ���ܡ�����20������Ҷ,�ڴ�ͳͳ��ѧ�������ѵ�ʱ��,��Ҷ˹�������������,����չ��Ϊһ���µ�ͳ��ѧ���б��ڴ�ͳͳ��ѧ,��Ҷ˹ͳ��ѧ������������ʷֲ���һ����,��ͳ��ѧģ���и���ע���˵������жϡ�����,����һ��ÿ�춼ҪƷ���Ůʿ��˵,���ֱܷ���������ȼӵ�ţ�̻����ȼӵIJ�Ҷ�ĸ���Ҫ�Ȳ��Ȳ����Ҫ�ߵöࡣ��ͳ��ģ���м���������ʷֲ�,�ڴ���С��������ʱ�������и��õı��֡�
��Ҷ˹����������ѧ����Ҫ�ǻ��ڱ�Ҷ˹��ʽ����Ҷ˹��ʽ���Ƶ�����:
���ϸ���:
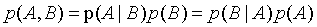
���Ǿ���:
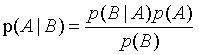
����Ҷ˹��ʽ���ڷ�������,������
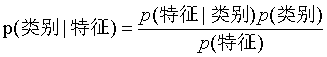
��������������û��ڸ�����������,Ŀ����������ijһ���ĸ���p(���|����)��Ȼ��,���DZȽ������ڸ������ʵĴ�С,��Ϊ��Ӧ���ൽ����������𡣿��Կ���,��Ҷ˹�������ı��ʾ�����������ʹ��ơ�
��ʵ�ʼ�����,��Ϊ���е�p(����)����һ����,������ʵ�ʼ���������ֻ��Ҫ�������ϸ�����p(����|���)p(���)�Ĵ�С��
�����ǻ���һ���������з����ԭ��,ͬ�����ڻ��ڶ���������з����ʱ��������
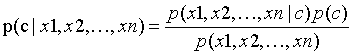
����,c��ʾ���,x1��x2������xn��ʾ�����ṩ��n��������
������ʽ���з�ĸ�Ķ�һ��,ֻ��Ҫ�ȽϷ��ӵĴ�С����ʵ����p(x1,x2,��,xn)�ԾɱȽ���ֱ����������������ر�Ҷ˹��������һ����ǿ�ļ���,�������е�����x1��x2������xn�����������������
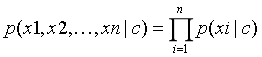
���ر�Ҷ˹�������������мලѧϰ�ķ������⡣�ŵ��Ǽ�����ѧϰЧ�ʸ�,��ijЩ��������������ܳ��ֺܺõĽ����ȱ�����Ա���֮��Ķ����Լ�������ʵ�к�������;������������̬�Լ���Ҳ��Խ���ľ��Ȳ���Ӱ�졣
pythonʵ��
�������������ѧ����,����������python����дһ�����ر�Ҷ˹��������
#-*- coding:utf-8 -*-
import numpy as np
def NaiveBayes(traindata, trainlabel):
classes = 10 #�����
features = 784 #������
sampleNum = trainlabel.shape[0]
#����p(c)
Pc = np.zeros((classes, 1))
for c in range(classes):
c_i = (trainlabel == c) #ͳ�Ʊ�ǩ�����c����������
c_i_num = np.sum(c_i)
Pc[c] = (c_i_num+1)/sampleNum #laplaceУ
Pc = np.log(Pc)
#����p(x|c)
y_num = 2 #ÿ���������ܵ�ȡֵ����
c_f_y_count = np.zeros((classes, feature, y_num)) #ͳ��ÿ�����ÿ��������ÿ�ֿ��ܳ��ִ���
for k in range(sampleNum):
c = trainlabel[k]
data = traindata[k]
for f in range(featrues):
y = data[f]
c_f_y_count[c][f][y] += 1
Px_c = np.zeros((classes, featrues, y_num)) #ͳ��ÿ�����ÿ��������ÿ�ֿ���ȡֵ�ĸ���
for c in range(classes):
for f in range(features):
c_f_y_num = np.sum(c_f_y_count[c][f])
for y in range(y_num):
Px_c[c][f][y] = np.log((c_f_y_count[c][f][y]+1)/c_f_y_num)
return Pc, Px_c
def predict(Pc, Px_c, x):
classes = 10
features = 784
Pc_x = [0]*classes #��¼ÿ�����ĺ������
for c in range(classes):
Px_c_sum = 0
for f in range(features):
Px_c_sum += Px_c[c][f][x[f]] #�Ը���ֵȡlog ���˱�����������
Pc_x[c] = Px_c_sum + Pc[c]
pre_c = Pc_x.index(max(Pc_x)) #�ҵ�ÿ�����ĺ�������е����ֵ��Ӧ�����
return pre_c
def test(Pc, Px_c, testdata, testlabel):
sampleNum = testlabel.shape[0]
count = 0.0
for i in range(sampleNum):
data = testdata[i]
label = testlabel[i]
pre_label = predict(Pc, Px_c, data)
if(pre_label == label):
count += 1
acc = count/sampleNum
return acc
if __name__ == '__main__':
traindata,trainlabel = loadData('../Mnist/mnist_train.csv')
evaldata,evallabel = loadData('../Mnist/mnist_test.csv')
Pc,Px_c = NaiveBayes(traindata,trainlabel)
accuracy = test(Pc, Px_c, evaldata, evallabel)
print('accuracy rate is:',accuracy)
ʵ��(����scikit-learn)
kaggle�ϵ�̩̹����Ҵ���Ԥ��
kaggle.comĿǰ��̩̹��˺�ML������Ϊ��Ϥ Kaggle ƽ̨����ԭ����������𡣴�������ͣ���ؿ�,�Ա����������Ϥkaggleƽ̨,ͬʱ̩̹��˺��Ҵ���Ԥ��Ҳһ������Ļ���ѧϰ�����Ӧ�ó�����
������Ŀ�ĺܼ�:ʹ�û���ѧϰ����һ��ģ��,Ԥ����Щ�˿���̩̹��˺ų����¼������Ҵ����������ݼ������ص�ַ:
https://www.kaggle.com/c/titanic/data
ʹ�ñ�Ҷ˹������Ԥ���������:
# -*- coding:utf-8 -*-
import numpy as np
import pandas as pd
import matplotlib.pylab as plt
from sklearn.preprocessing import StandardScaler
from sklearn.naive_bayes import BernoulliNB #��Ŭ��ģ��
#��������
datatrain = pd.read_csv('train.csv')
datatest = pd.read_csv('test.csv')
#ȥ��������������
datatrain = datatrain.drop(labels=['PassengerId', 'Name', 'Ticket', 'Cabin'], axis=1)
datatest = datatest.drop(labels=['PassengerId', 'Name', 'Ticket', 'Cabin'], axis=1)
#ȥ��ȱʧֵ
datatrain = datatrain.dropna()
#����Լ���ȱʧֵ
datatest = datatest.fillna(datatest.mean()['Age':'Fare'])
#����ת��Ϊ��ֵ��
datatrain_dummy = pd.get_dummies(datatrain[['Sex', 'Embarked']])
datatest_dummy = pd.get_dummies(datatest[['Sex', 'Embarked']])
#����������ƴ��
datatrain_conti = pd.DataFrame(datatrain, columns=['Survived', 'Pclass', 'Age', 'SibSp', 'Parch','Fare'], index=datatrain.index)
datatrain = datatrain_conti.join(datatrain_dummy)
datatest_conti = pd.DataFrame(datatrain, columns=['Survived', 'Pclass', 'Age', 'SibSp', 'Parch','Fare'], index=datatest.index)
datatest = datatest_conti.join(datatest_dummy)
X_train = datatrain.iloc[:,1:]
y_train = datatrain.iloc[:,0]
X_test = datatest
#����
stdsc = StandardScaler()
X_train_conti_std = stdsc.fit_transform(X_train[['Age''SibSp','Parch','Fare']])
X_test_conti_std = stdsc.fit_transform(X_test[['Age''SibSp','Parch','Fare']])
#��ndarrayתΪdatatrainframe
X_train_conti_std = pd.DataFrame(data=X_train_conti_std,columns=['Age''SibSp','Parch','Fare'],index=X_train.index)
X_test_conti_std = pd.DataFrame(data=X_test_conti_std,columns=['Age''SibSp','Parch','Fare'],index=X_test.index)
#����������Pclass
X_train_cat = X_train[['Pclass']]
X_test_cat = X_test[['Pclass']]
#�����ѱ���ķ������
X_train_dummy = X_train[['Sex_female','Sex_male','Embarked_Q','Embarked_S']]
X_test_dummy = X_test[['Sex_female','Sex_male','Embarked_Q','Embarked_S']]
#ƴ��Ϊdatatrainframe
X_train_set = [X_train_cat, X_train_conti_std, X_train_dummy]
X_test_set = [X_test_cat, X_test_conti_std, X_test_dummy]
X_train = pd.concat(X_train_set, axis=1)
X_test = pd.concat(X_test_set, axis=1)
clf = BernoulliNB()
clf.fit(X_train,y_train)
predicted = clf.predict(X_test)
datatest['Survived'] = predicted.astype(int)
datatest[['PassengerId','Survived']].to_csv('submission.csv', sep=',', index=False)
�����������
�ı�����ָ��������һ�����������ʹ�������ھ������Ļ�����,����ѵ�����ʾ��ģ��,���ı�Ƭ�Ρ�������ļ����з�����ࡣ
����ʵ������ʹ��sklearn�е�fetch_20newsgroups��
20 newsgroups���ݼ�18000��ƪ��������,һ���漰��20�ֻ���,��Ϊѵ�����Ͳ��Լ�,ͨ���������ı�����,���ȷ�Ϊ20����ͬ����������鼯�ϡ�fetch_20newsgroups���ݼ��DZ������ı����ࡢ�ı��ھݺ���Ϣ�����о��Ĺ��ʱ����ݼ�֮һ��
��������:
# -*- coding:utf-8 -*-
from sklearn.datasets import fetch_20newsgroups
from sklearn.cross_validation import train_test_split
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.naive_bayes import MultinomialNB
#�ӻ�������������
news = fetch_20newsgroups(subset='all')
#�����ȡ25%������������Ϊ���Լ�
X_train, X_test, y_train, y_test = train_test_split(news.data, news.target, test_size=0.25, random_state=33)
#�ı���������ת��
vec = CountVectorizer()
X_train = vec.fit_transform(X_train)
X_test = vec.fit_transform(X_test)
#������Ҷ˹������
mnb = MultinomialNB()
mnb.fit(X_train, y_train)
y_predict = mnb.predict(X_test)