- Review: gradient Descent
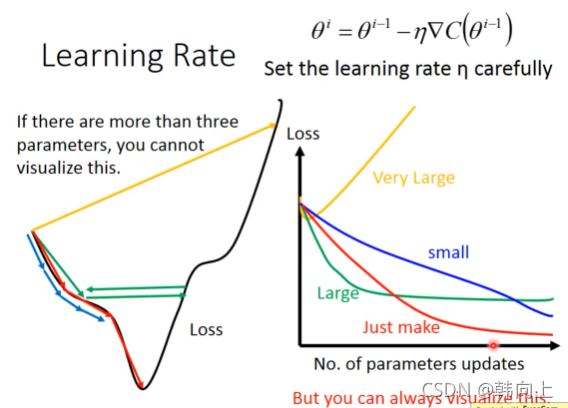
- Learning rates给优化过程中带来的影响
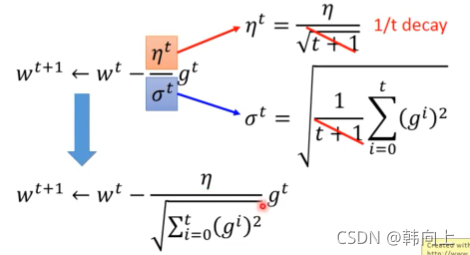
- 自适应调整learning rate 的方法
- 梯度下降法的背后理论基础
Review: gradient Descent
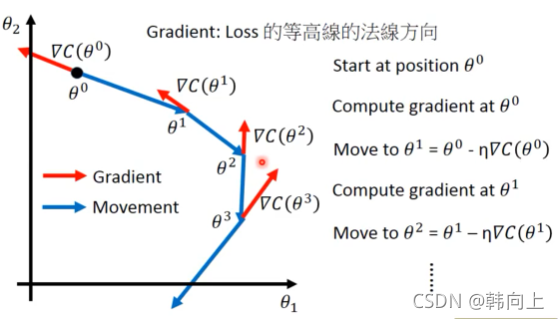
在上一个视频里,已经介绍了使用梯度下降法求解Loss function
θ
?
=
a
r
g
m
i
n
?
L
(
θ
)
\theta^*=argmin\ L(\theta)
θ?=argmin?L(θ)
L:loss function
θ
\theta
θ:参数

梯度下降过程中的可视化
Learning rates给优化过程中带来的影响
自适应调整learning rate 的方法
- Adagrad
以权重 w w w的更新过程为例
w t + 1 ← w t ? η t σ t g t w^{t+1}\leftarrow w^t-\frac{\eta^t}{\sigma^t}g^t wt+1←wt?σtηt?gt
其中 η t = η t + 1 \eta^t=\frac{\eta}{\sqrt{t+1}} ηt=t+1?η?, σ t = 1 t + 1 ∑ i = 0 t ( g i t ) 2 \sigma^t=\sqrt{\frac{1}{t+1}\sum_{i=0}^t(g_i^t)^2} σt=t+11?∑i=0t?(git?)2?.
如何理解Adagrad的物理意义呢?
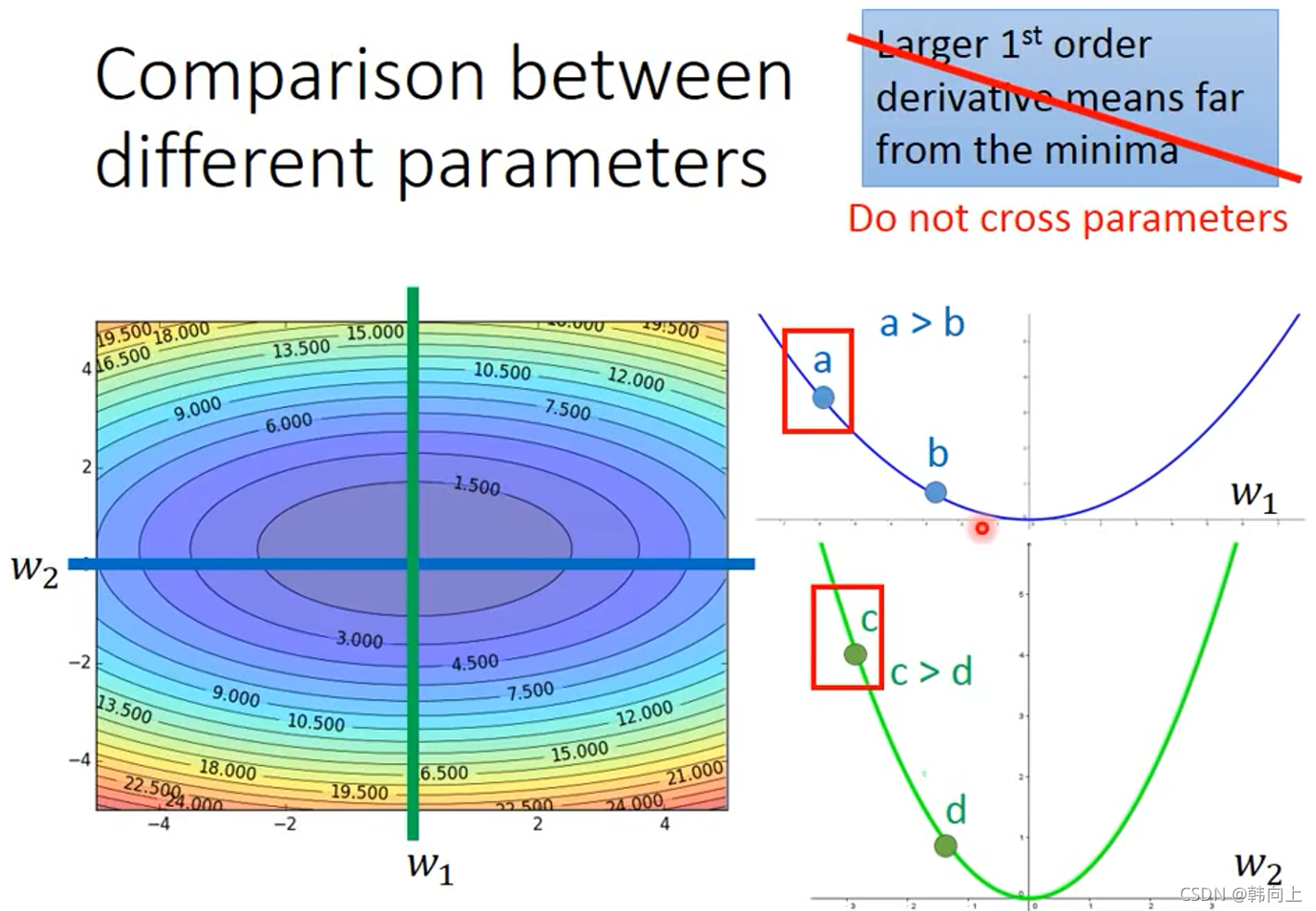
如下图所示,当只有一个参数时,微分越大说明当前参数距离最优参数越远
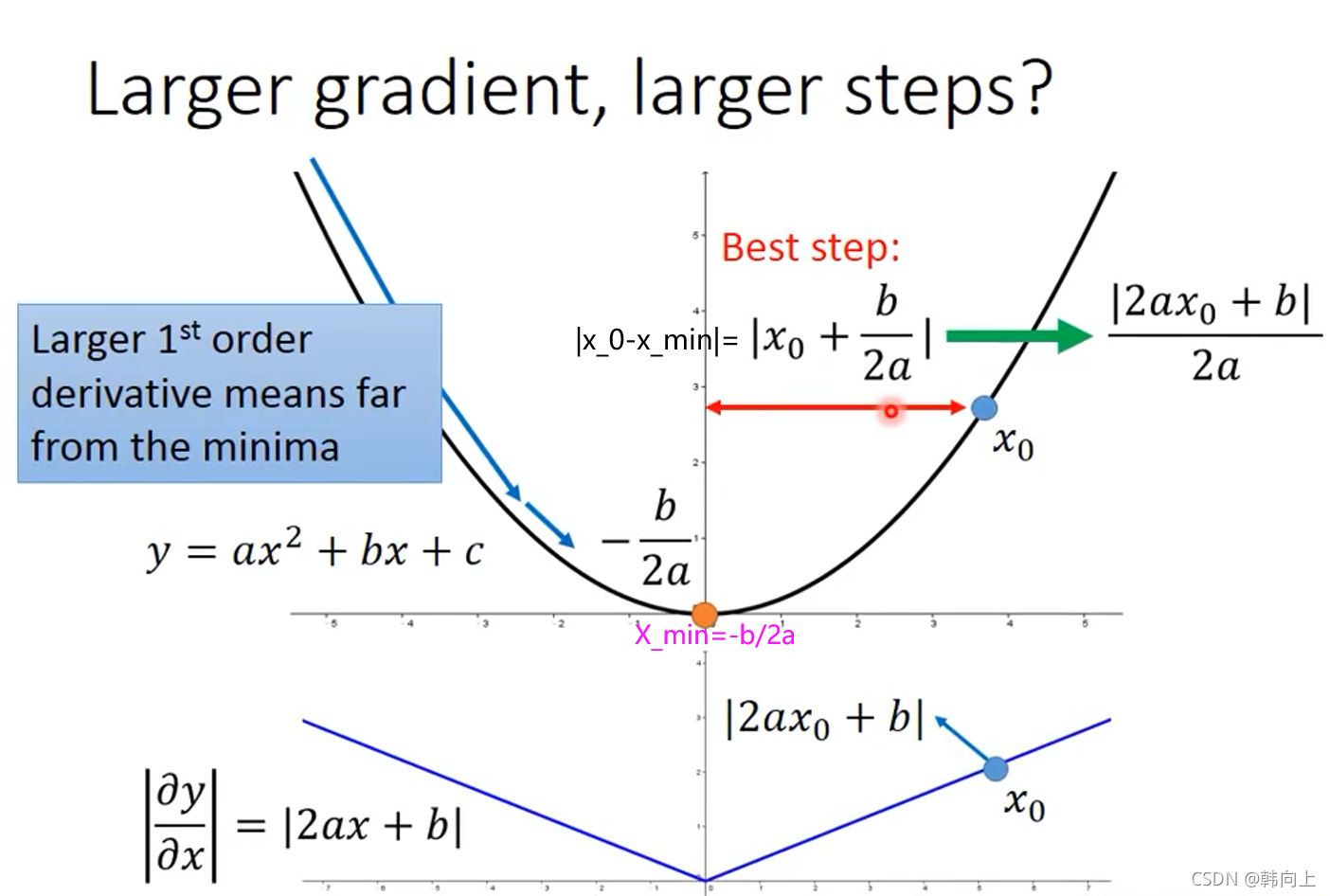
当时当需要同时考虑多个参数时,考虑微分越大当前参数距离最优参数越远是一种不正确的想法,可见绿色的线中 c c c点相比于蓝色的线中 a a a点的微分值大,但 c c c距离最优解比 a a a近。
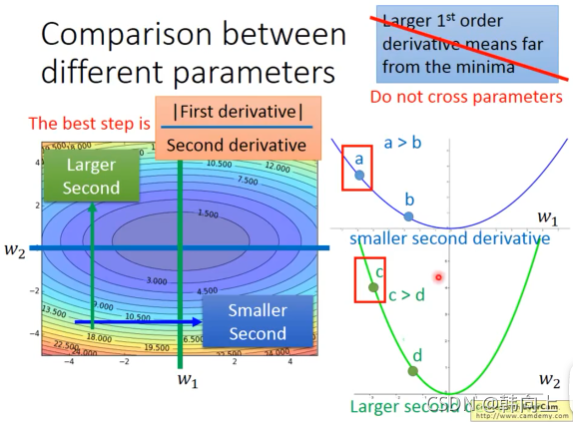
那么为了同时考虑好几个参数时,我们应该将描述一阶微分变化的二次微分也需要考虑进来. f r i s t ? d e r i v a t i v e s e c o n d ? d e r i v a t i v e \frac{frist \ derivative}{second \ derivative} second?derivativefrist?derivative?
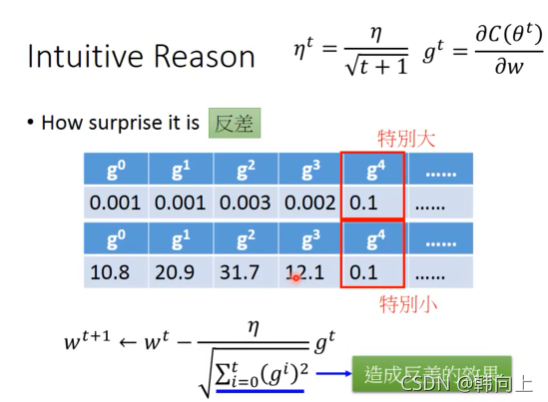
在Adagrad中, σ t = 1 t + 1 ∑ i = 0 t ( g i t ) 2 \sigma^t=\sqrt{\frac{1} {t+1}\sum_{i=0}^t(g_i^t)^2} σt=t+11?∑i=0t?(git?)2?, 具有体现反差的效果。
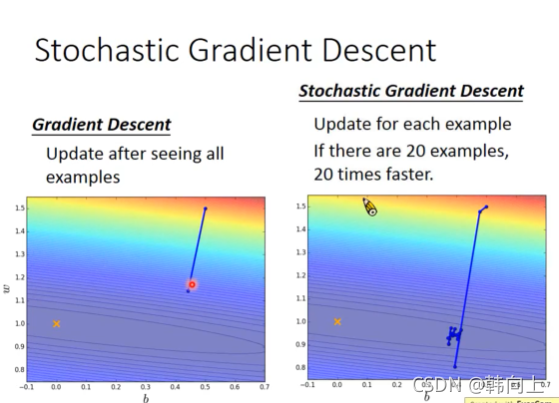
我认为Adagrad具有这样的作用:损失函数在最优解处的微分值为0,在最优解附近的邻域内其他点处微分也应该较缓。Adagrad让一直陡峭突然变缓时,让函数快点走走,避免陷入局部最优解。一直平缓突然陡峭时让函数变慢点,别跨越最优解了。 - Stochastic Gradient Descent

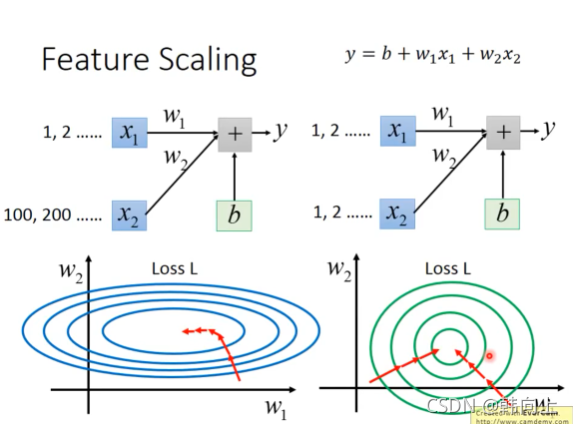
- Feature Scaling
归一化不同数据的分布,可以看出没有归一化是找最优解是需要拐弯才能到,但是绿色线直走就能到。
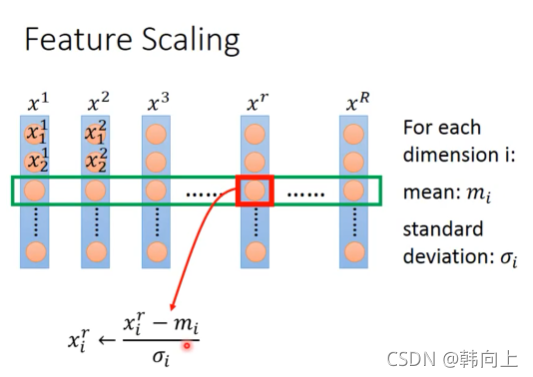
归一化的方法:
梯度下降法的背后理论基础
假设在损失函数中,我们需要更新两个参数 θ 1 , θ 2 \theta_1,\theta_2 θ1?,θ2?.
对于一个二阶可微函数 L ( θ 1 , θ 2 ) L(\theta_1,\theta_2) L(θ1?,θ2?),在 ( a , b ) (a,b) (a,b)附近的一个邻域内, L ( θ 1 , θ 2 ) L(\theta_1,\theta_2) L(θ1?,θ2?)可以被表述如下
L ( θ 1 , θ 2 ) ≈ = s + u ( θ 1 ? a ) + v ( θ 2 ? b ) L(\theta_1,\theta_2)\approx=s+u(\theta_1-a)+v(\theta_2-b) L(θ1?,θ2?)≈=s+u(θ1??a)+v(θ2??b)
其中 s = L ( a , b ) s=L(a,b) s=L(a,b), u = ? L ( a , b ) ? θ 1 u=\frac{\partial L(a,b)}{\partial\theta_1} u=?θ1??L(a,b)?, v = ? L ( a , b ) ? θ 2 v=\frac{\partial L(a,b)}{\partial\theta_2} v=?θ2??L(a,b)?。

那么为了使得整体的L最小,我们就需要
把向量
(
(
θ
1
?
a
)
,
(
θ
2
?
b
)
)
((\theta_1-a) ,(\theta_2-b))
((θ1??a),(θ2??b))置于与
(
u
,
v
)
(u,v)
(u,v)相反。


红色圈的半径就是学习率
η
\eta
η。当红色圈过大时,
L
(
θ
1
,
θ
2
)
≈
=
s
+
u
(
θ
1
?
a
)
+
v
(
θ
2
?
b
)
L(\theta_1,\theta_2)\approx=s+u(\theta_1-a)+v(\theta_2-b)
L(θ1?,θ2?)≈=s+u(θ1??a)+v(θ2??b)就会误差过大。
图源:李宏毅机器学