目录
一 .本周任务
- 从三个横向课题中选择一个,横向课题可以变化,但纵向课题最好一直不变
- 运行上线的代码,结合论文与代码,了解上线的研究内容与思路,帮助上线修改其论文
- 根据张钹教授的论文,了解跟踪他的成果,并写一个简单的综述,综述的排版方式可根据国内外的人工智能安全团队来排版
- 讲述你所读的大佬的文献,并给出自己有哪些修改论文的想法
二.已完成的任务
1.横向课题
选择网安方面的那个课题
2.上线代码与论文
2.1 代码
代码能正常运行,但是运行4、5个小时以后,出现了一些错误,初步推断是运行结果的保存路径有一些错误.
2.2 论文
论文的思路大概是:在联邦学习中,在客户端训练带有被攻击的图片,使得客户端模型中毒,当服务器端模型集合客户端模型时,使得服务端模型也中毒,再分散到各个客户端,使得各个客户端模型都中毒.
2.3 修改论文
只找到师兄文本中的table Ⅰ与表上的table 1符号不一致的错误
2.4 论文与代码理解
论文只了解了大概的思路,对于具体的代码实现和理论方面还需要进一步思考,对于tensorflow框架还需要学习才能看懂大部分代码.
3.跟踪张钹团队成果
找到一些团队的相关成果,但未来得及阅读
- understanding adversarial attacks on observations in deep reinforcement learning
- Boosting Adversarial Attacks with Momentum
- Triple Generative Adversarial Networks
4.大概了解人工智能安全方向
(以下是根据李宏毅机器学习的视频所做的笔记)
4.1 Attack
原理:在原有的图片
x
x
x上加上特殊的噪音
x
′
=
x
+
Δ
x
x^{\prime}=x+\Delta x
x′=x+Δx,使得判别器识别出其他东西.

- 未加入噪音的图片:benign image;加入噪音后的图片:attack image.
- 有目标的攻击:希望输出为特定其他事物;无目标攻击:希望识别错误.
- 不知道模型参数的攻击为黑箱攻击,反之为白箱攻击.
- d ( x 0 , x ′ ) d(x^0,x^{\prime}) d(x0,x′)可以计算其2范数和无穷范数,可以根据不同的范例运用不同的距离.对于图片,一般使用无穷范数,因为同样的2-范数距离下,每个像素点都有所改变与只有一个特定的像素点改变巨大是不一样的效果,后者更容易被发现,所以采用无穷范数限制,避免被人眼感知.
4.1.1 Attack approach
- 一般做法

- FGSM(一击必杀,只更新一次)

- 也可以更新多次,但 d ( x 0 , x ) > ε d(x^0,x)>\varepsilon d(x0,x)>ε时 固定 x x x的取值
4.1.2 黑箱攻击
1.原理:用一个proxy network模拟需要攻击的network,然后训练出攻击资料去攻击.也可以采用ensemble attack,即将综合多个攻击成功的proxy network的attacked image去攻击black network.
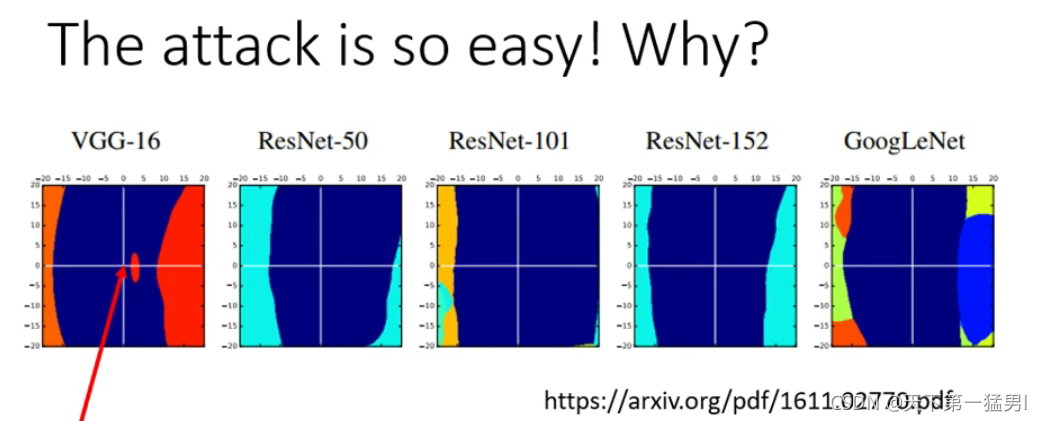
2.问题:为什么在图像识别系统中,一个attacked image能成功攻击一个模型,那么对于其他模型攻击成功的概率也很高?
可能答案:如图所示,假设在
x
x
x轴方向是能被攻击成功的方向,大多数攻击成功的方向相似,在一个模型上能攻击成功大概率能在另一个模型成功.有人认为这不是模型的原因,而是数据图片自身的原因.
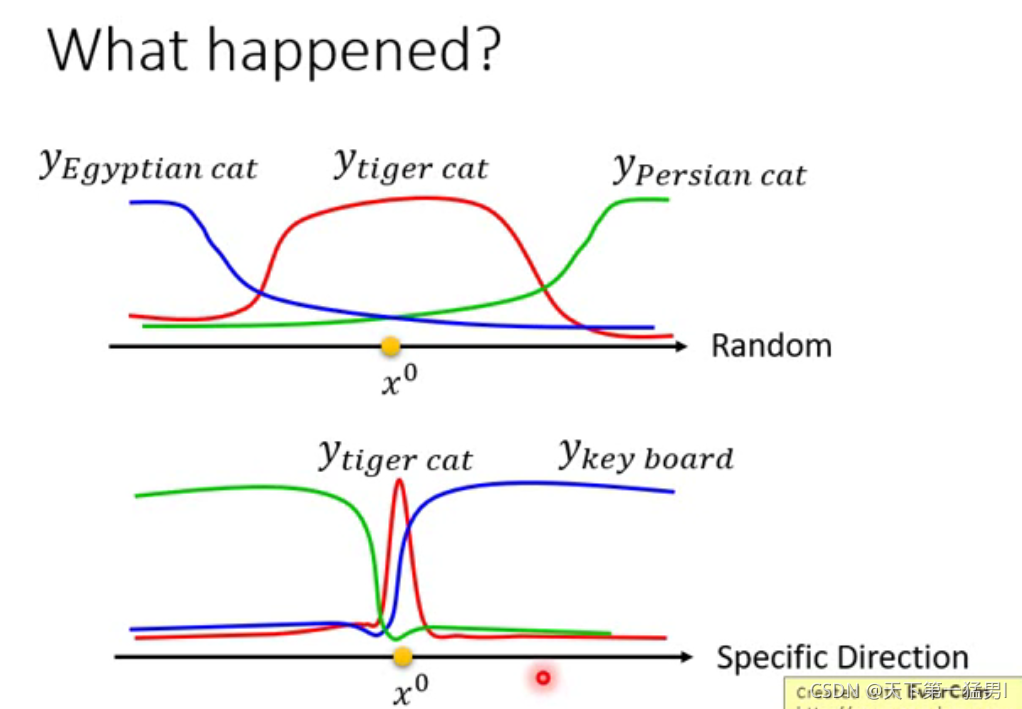
3.为什么会被攻击
在某一个特定的方向是有很大的几率被攻击成功的
4.其他攻击技术:
- one pixel attack:https://arxiv.org/pdf/1710.08864.pdf
- universal adversarial attack:做一个可以让很多图片都被攻击的噪音https://arxiv.org/pdf/1610.08401.pdf
- 攻击语音合成识别系统、NLP
- adversarial reprograming:制作一个类似于病毒一样的东西寄生在别的分类器上,让分类器做它不想做的事https://arxiv.org/abs/1806.11146
- “backdooor” in model:在训练阶段,对训练资料增加一些被攻击的照片,是训练好的模型对于某种属于会辨识成被攻击照片。https://arxiv.org/abs/1804.00792
4.2 Defense
4.2.1 passive defense
-
添加一个 filter:
- smoothing:模糊化操作使被攻击的像素点不一定被发现
- 剪枝
- image compression:压缩再解压缩使得被攻击的像素点丢失https://arxiv.org/abs/1802.06816
- 基于generator ,用generator产生与输入图片非常相似的图片,那么generator产生的图片不具有被攻击的像素点存在:https://arxiv.org/abs/1805.06605
-
randomization:图片输入以后给一个随机的处理(一些filter操作),处理被攻击图片的同时防御对已经防御手段的攻击:https://arxiv.org/abs/1711.01991
4.2.2 proactive defense
(训练一个robust的模型)
- adversarial training:在训练的时候,不仅训练原始数据,将原始数据的attack 数据与相对应的正确的标签进行训练,再迭代的利用被攻击的图片接着被攻击,这样使得即使遇到被攻击的图片,同样也能够免疫攻击 (缺点:只会针对自己设计的攻击算法,无法防御新的攻击算法)
- adversarial training for free:减少计算量 https://arxiv.org/abs/1904.12843
三.未完成的任务
- 阅读张钹团队的论文及一个简单的综述写作
- 师兄的成果还未理解透彻,代码也大多无法理解
- 还未涉及阅读大佬的文献,然后去思考其有可能存在的问题
四.下周计划
- 粗略学习一下tensorflow框架,争取看懂师兄论文的实现方法细节,进一步理解师兄成果
- 阅读并了解张钹团队和国内外团队的研究成果,写一个简单的综述
- 阅读一些大佬的文献,思考可能存在的改进方向