ЙизЂЙЋжкКХ,ЗЂЯжCVММЪѕжЎУР
БОЮФЗжЯэICML 2021 ЪеТМТлЮФЁКScaling Up Visual and Vision-Language Representation Learning With Noisy Text SupervisionЁЛЁЃгЩЙШИшбЇепЬсГіЁЖALIGNЁЗФмЙЛНјааПчФЃЬЌМьЫї,адФмгХгк SOTAЁЃ
ЯъЯИаХЯЂШчЯТ:

ТлЮФСДНг:https://arxiv.org/abs/2102.05918
ЯюФПСДНг:ЩаЮДПЊдД
ЕМбд:

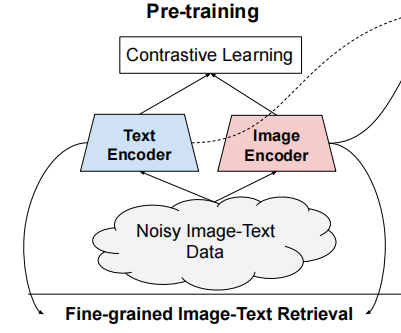
? ??бЇЯАСМКУЕФЪгОѕКЭЪгОѕгябдБэеїЖдгкНтОіМЦЫуЛњЪгОѕЮЪЬт(ЭМЯёМьЫїЁЂЭМЯёЗжРрЁЂЪгЦЕРэНт)ЪЧжСЙиживЊЕФ,ФПЧА,дЄбЕСЗЕФЬиеїдкаэЖрNLPШЮЮёжавбОеЙЯжСЫЗЧГЃДѓЕФЧБСІЁЃЫфШЛNLPжаЕФБэЪОбЇЯАвбОПЩвдгУУЛгаШЫЙЄзЂЪЭЕФдЪМЮФБОбЕСЗ,ЕЋЪгОѕКЭЪгОѕгябдБэЪОШдШЛбЯживРРЕгкАКЙѓЛђашвЊзЈМвжЊЪЖЕФбЕСЗЪ§ОнМЏЁЃ
ЖдгкЪгОѕШЮЮё,ЬиеїБэЪОЕФбЇЯАжївЊвРРЕОпгаЯдЪНЕФclassБъЧЉЕФЪ§ОнМЏ,ШчImageNetЛђOpenImagesЁЃЖдгкЪгОѕгябдШЮЮё,вЛаЉЪЙгУЙуЗКЕФЪ§ОнМЏЯёConceptual CaptionsЁЂMS COCOвдМАCLIPЖМЩцМАЕНСЫЪ§ОнЪеМЏКЭЧхЯДЕФЙ§ГЬЁЃетРрЪ§ОндЄДІРэЕФЙЄзїбЯжизшАСЫЛёЕУИќДѓЙцФЃЕФЪ§ОнМЏЁЃдкБОЮФжа,зїепРћгУСЫГЌЙ§10вкЕФЭМЯёЮФБОЖдЕФдыЩљЪ§ОнМЏ,УЛгаНјааЪ§ОнЙ§ТЫЛђКѓДІРэВНжш ЁЃ
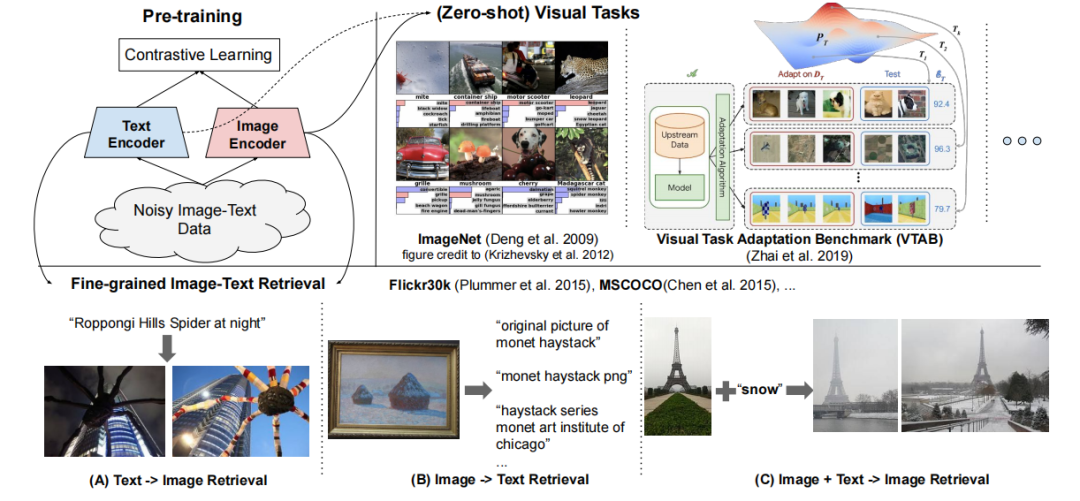
ЛљгкЖдБШбЇЯАЫ№ЪЇ,ЪЙгУвЛИіМђЕЅЕФЫЋБрТыЦїНсЙЙРДбЇЯАЖдЦыЭМЯёКЭЮФБОЖдЕФЪгОѕКЭгябдБэЪО ЁЃзїепжЄУїСЫ,гяСЯПтЙцФЃЕФОоДѓЬсЩ§ПЩвдУжВЙЪ§ОнФкВПДцдкЕФдыЩљ,вђДЫМДЪЙЪЙгУМђЕЅЕФбЇЯАЗНЪН,ФЃаЭвВФмДяЕНSOTAЕФЬиеїБэЪОЁЃЕББОЮФФЃаЭЕФЪгОѕБэЪОзЊвЦЕНImageNetКЭVTABЕШЗжРрШЮЮёЪБ,вВФмШЁЕУКмЧПЕФадФмЁЃЖдЦыЕФЪгОѕКЭгябдБэЪОжЇГжzero-shotЕФЭМЯёЗжРр,ВЂдкFlickr30KКЭMSCOCOЭМЯё-ЮФБОМьЫїЛљзМЪ§ОнМЏЩЯДяЕНСЫSOTAЕФНсЙћЁЃ
? ? ??01??? ??
Motivation
дкЯжгаЙЄзїжа,ЪгОѕКЭЪгОѕгябдБэЪОбЇЯАДѓЖрЪЧЗжБ№ЪЙгУВЛЭЌЕФбЕСЗЪ§ОндДНјаабаОПЕФЁЃдкЪгОѕСьгђ,ЖдДѓЙцФЃМрЖНЪ§Он(ШчImageNetЁЂOpenImagesКЭJFT-300M)НјаадЄбЕСЗЖдЬсИпЯТгЮШЮЮёЕФадФмЪЧжСЙиживЊЕФЁЃЛёЕУетжждЄбЕСЗЕФЪ§ОнМЏашвЊдкЪ§ОнЪеМЏЁЂВЩбљКЭШЫЙЄБъзЂЗНУцНјааДѓСПЕФЙЄзї,Ъ§ОнЛёШЁГЩБОЗЧГЃДѓ,вђДЫФбвдРЉеЙЁЃ
дЄбЕСЗвВЪЧЪгОѕгябдНЈФЃЕФЗНЗЈЁЃШЛЖј,ЪгОѕгябдЕФдЄбЕСЗЪ§ОнМЏ,ШчConceptual CaptionsЁЂVisual Genome Dense CaptionsКЭ ImageBERT,ашвЊдкШЫРрБъзЂЁЂгявхНтЮіЁЂЧхРэКЭЦНКтЗНУцНјааИќжиЕФЙЄзїЁЃвђДЫ,етаЉЪ§ОнМЏЕФЙцФЃНідк10MИібљБОзѓгвЁЃетжСЩйБШЪгОѕСьгђЕФЪ§ОнМЏаЁвЛИіЪ§СПМЖ,ЖјЧвБШдЄбЕСЗЕФNLPЪ§ОнМЏвВаЁЕУЖрЁЃ
дкетЯюЙЄзїжа,зїепРћгУСЫГЌЙ§10вкИігадыЩљЕФЭМЯёЮФБОЖдЕФЪ§ОнМЏРДРЉеЙЪгОѕКЭЪгОѕгябдБэЪОбЇЯАЁЃзїепВЩгУСЫConceptual CaptionsЕФЗНЪНРДЛёШЁвЛИіДѓЕФдыЩљЪ§ОнМЏЁЃгыЦфВЛЭЌЕФЪЧ,зїепУЛгагУИДдгЕФЪ§ОнТЫВЈКЭКѓДІРэВНжшРДЧхРэЪ§ОнМЏ,ЖјЪЧжЛгІгУМђЕЅЕФЛљгкЪ§ОнЦЕТЪЕФЙ§ТЫЁЃЫфШЛЕУЕНЕФЪ§ОнМЏгадыЩљ,ЕЋБШConceptual CaptionsЪ§ОнМЏДѓСНИіЪ§СПМЖЁЃзїепЗЂЯж,дкетбљЕФДѓЙцФЃдыЩљЪ§ОнМЏЩЯдЄбЕСЗЕФЪгОѕКЭЪгОѕгябдБэЪОдкЙуЗКЕФШЮЮёЩЯШЁЕУСЫЗЧГЃЧПЕФадФмЁЃ
зїепЛљгкдквЛИіЙВЯэЕФembeddingПеМфжаЖдЦыЪгОѕКЭгябдБэЪОЕФбЕСЗФПБъ,ЪЙгУвЛИіМђЕЅЕФЫЋБрТыЦїЬхЯЕНсЙЙРДбЕСЗФЃаЭЁЃзїепНЋетИіФЃаЭУќУћЮЊALIGN(A ?L arge-scale I maG e and N oisy-text embedding),ЭМЯёКЭЮФБОБрТыЦїЪЧЭЈЙ§ЖдБШЫ№ЪЇКЏЪ§бЇЯАЕФ,НЋЦЅХфЕФЭМЯёЮФБОЖдЕФembeddingЭЦдквЛЦ№,ЭЌЪБНЋВЛЦЅХфЕФЭМЯёЮФБОЖдЕФembeddingЗжПЊЁЃетвВЪЧздМрЖНКЭМрЖНБэЪОбЇЯАЕФзюгааЇЕФЫ№ЪЇКЏЪ§жЎвЛЁЃ
ПМТЧЕНALIGNгУЮФБОзїЮЊЭМЯёЕФЯИСЃЖШБъЧЉ,вђДЫЭМЯёЖдЮФБОЕФЖдБШЫ№ЪЇРрЫЦгкДЋЭГЕФЛљгкБъЧЉЕФЗжРрФПБъ;ЙиМќЕФЧјБ№дкгкетРяЕФlabelЪЧгЩЮФБОБрТыЦїЩњГЩЁАБъЧЉЁБШЈжи,ЖјВЛЪЧЯёImageNetФЧбљРыЩЂЕФБъЧЉЁЃ(ALIGNЕФФЃаЭНсЙЙШчЩЯЭМЫљЪО)

ЖдЦыЕФЭМЯёКЭЮФБОБэЪОздШЛЪЪгУгкПчФЃЬЌЦЅХф/МьЫїШЮЮё,ВЂдкЯргІЕФЛљзМЪ§ОнМЏВтЪджаЪЕЯжСЫSOTAНсЙћЁЃДЫЭт,етжжПчФЃЬЌЦЅХфвВЪЪгУгкzero-shotЭМЯёЗжРр,дкВЛЪЙгУШЮКЮбЕСЗбљБОЕФЧщПіЯТ,дкImageNetжаЛёЕУСЫ76.4%ЕФTop-1зМШЗТЪ ЁЃДЫЭт,ЭМЯёБэЪОдкИїжжЯТгЮЪгОѕШЮЮёжавВШЁЕУСЫВЛДэЕФадФмЁЃР§Шч,ALIGNдкImageNetжаДяЕНСЫ88.64%ЕФTop-1зМШЗТЪ ЁЃ(ЩЯЭМеЙЪОСЫПчФЃЬЌМьЫїЕФЪОР§)
? ? ??02??? ??
ЗНЗЈ
2.1. A Large-Scale Noisy Image-Text Dataset

БОЮФЕФжиЕуЪЧРЉДѓЪгОѕКЭгябдБэЪОбЇЯАЕФЙцФЃЁЃЮЊДЫ,зїепДДНЈСЫвЛИіБШЯжгаЪ§ОнМЏДѓЕУЖрЕФЪ§ОнМЏЁЃОпЬхРДЫЕ,зїепзёбЙЙНЈConceptual CaptionsЪ§ОнМЏЕФЗНЗЈ,вдЛёЕУИќДѓЙцФЃЕФЭМЯё-ЮФБОЪ§ОнМЏЁЃ
ЕЋЪЧ,Conceptual CaptionsЪ§ОнМЏЛЙНјааСЫДѓСПЕФЪ§ОнЙ§ТЫКЭКѓДІРэЙЄзї,ЮЊСЫЛёШЁИќДѓЙцФЃЕФЪ§Он,зїепЭЈЙ§МѕЧсConceptual CaptionsЙЄзїжаЕФДѓВПЗжЪ§ОнЧхЯДЙЄзїРДМѕЩйЪ§ОнДІРэЕФЙЄзїСП(зїепНіИљОнЪ§ОнЕФЦЕТЪзіСЫЗЧГЃМђЕЅЕФЪ§ОнЙ§ТЫ)ЁЃвђДЫ,зїепЛёЕУСЫвЛИіИќДѓЙцФЃЕФЪ§ОнМЏ(18вкЕФЭМЯёЮФБОЖд)ЁЃЩЯЭМеЙЪОСЫЪ§ОнМЏжаЕФвЛаЉЫцЛњВЩбљЕФР§згЁЃ
2.2. дЄбЕСЗгыШЮЮёЧЈвЦ
ALIGNЕФДѓжТПђМмШчЩЯЭМЫљЪОЁЃ
2.2.1. дЄбЕСЗ
зїепЪЙгУЫЋБрТыЦїНсЙЙгУгкбЕСЗЖдЦыЬиеї,ИУФЃаЭгЩвЛЖдЭМЯёБрТыЦїКЭЮФБОБрТыЦїзщГЩЁЃзїепЪЙгУОпгаШЋОжГиЛЏЕФEfficientNetзїЮЊЭМЯёБрТыЦї,ЪЙгУДјга[CLS] token embeddingЕФBERTзїЮЊЮФБОБрТыЦїЁЃдкBERTБрТыЦїЕФЖЅВП,зїепЬэМгСЫвЛИіДјМЄЛюКЏЪ§ЕФШЋСЌНгВу,вдЦЅХфЭМЯёЕФЮЌЖШЁЃ
ЭМЯёКЭЮФБОБрТыЦїЖМЪЧЭЈЙ§normalized softmaxЫ№ЪЇКЏЪ§НјаагХЛЏЁЃдкбЕСЗжа,НЋЦЅХфЕФЭМЯё-ЮФБОЖдЪгЮЊе§бљБО,ВЂНЋЕБЧАбЕСЗbatchжаЕФЦфЫћЫцЛњЭМЯё-ЮФБОЖдЪгЮЊИКбљБОЁЃдкбЕСЗЙ§ГЬжа,гХЛЏвдЯТСНИіЫ№ЪЇКЏЪ§:
image-to-textЕФЖдБШЫ№ЪЇ:
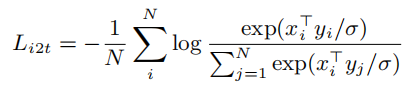
text-to-imageЕФЖдБШЫ№ЪЇ:
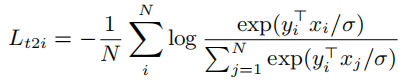
Цфжа,
?
?2.2.2. ШЮЮёЧЈвЦжЎImage-Text Matching & Retrieval
зїепЦРЙРСЫALIGNдкЭМЯёЖдЮФБОКЭЮФБОЖдЭМЯёЕФМьЫїШЮЮёЩЯЕФадФм(гаfinetuningКЭЮоfinetuning)ЁЃВтЪдЕФЪ§ОнМЏАќРЈFlickr30KКЭMSCOCOЁЃДЫЭт,зїепвВдкCrisscrossed Captions (CxC)Ъ§ОнМЏЩЯВтЪдALIGNЕФадФм(Crisscrossed CaptionsЪЧMSCOCOЕФвЛИіРЉеЙЪ§ОнМЏ,ЫќЖдcaption-captionЁЂ image-imageКЭimage-captionЖдНјааСЫЖюЭтЕФгявхЯрЫЦадХаЖЯ)ЁЃ
ЭЈЙ§етаЉРЉеЙЕФБъзЂ,CxCПЩвдЪЕЯжЫФИіФЃЬЌФкКЭФЃЪНФкЕФМьЫїШЮЮё,АќРЈЭМЯёЕНЮФБОМьЫїЁЂЮФБОЕНЭМЯёМьЫїЁЂЮФБОЕНЮФБОМьЫїКЭЭМЯёЕНЭМЯёЕФМьЫїШЮЮё,вдМАШ§ИігявхЮФБОЯрЫЦадШЮЮё,АќРЈгявхЮФБОЯрЫЦад(STS)ЁЂгявхЭМЯёЯрЫЦад(SIS)КЭгявхЭМЯё-ЮФБОЯрЫЦЖШ(SITS)ЁЃ
2.2.3. ШЮЮёЧЈвЦжЎ Visual Classification
зїепЪзЯШНЋALIGNЛљгкzero-shotЗНЪНгІгУЕНЪгОѕЗжРрШЮЮёЩЯ,Ъ§ОнМЏАќРЈImageNet ILSVRC-2012 benchmarkЁЂImageNet-RЁЂImageNet-AЁЂImageNet-V2ЁЃетаЉImageNetЪ§ОнМЏБфжжЖМЪЧImageNetЕФвЛИізгМЏ,ImageNet-RКЭ ImageNet-AЪЧИљОнВЛЭЌЕФЗжВМЖдImageNetВЩбљЕУЕНЕФЁЃ
зїепЛЙНЋЭМЯёБрТыЦїЧЈвЦЕНСЫЯТгЮЕФЪгОѕЗжРрШЮЮёжа,ЮЊДЫ,зїепЪЙгУСЫImageNetвдМАвЛаЉНЯаЁЕФЯИСЃЖШЗжРрЪ§ОнМЏOxford Flowers-102ЁЂ Oxford-IIIT PetsЁЂStanford CarsЁЂ Food101ЁЃЖдгкImageNet,зїепеЙЪОСЫРДздСНИіЩшжУЕФНсЙћ:жЛбЕСЗЖЅМЖЗжРрВу(ЪЙгУЖГНсЕФЖдЦыЭМЯёБрТыЦї)КЭЭъШЋЮЂЕї(ВЛЖГНсЕФЖдЦыЭМЯёБрТыЦї)ЁЃЖдгкЯИСЃЖШЕФЗжРрЛљзМЪ§ОнМЏВтЪд,зїепжЛеЙЪОСЫКѓвЛжжЩшжУЕФНсЙћЁЃДЫЭт,зїепЛЙдкVisual Task Adaptation BenchmarkЪ§ОнМЏ(гЩ19ИіВЛЭЌЕФЪгОѕЗжРрШЮЮёзщГЩ,УПИіШЮЮёга1000ИібЕСЗбљБО)ЩЯВтЪдСЫФЃаЭЕФТГАєадЁЃ
? ? ??03??? ??
ЪЕбщ
3.1. Image-Text Matching & Retrieval
?
?
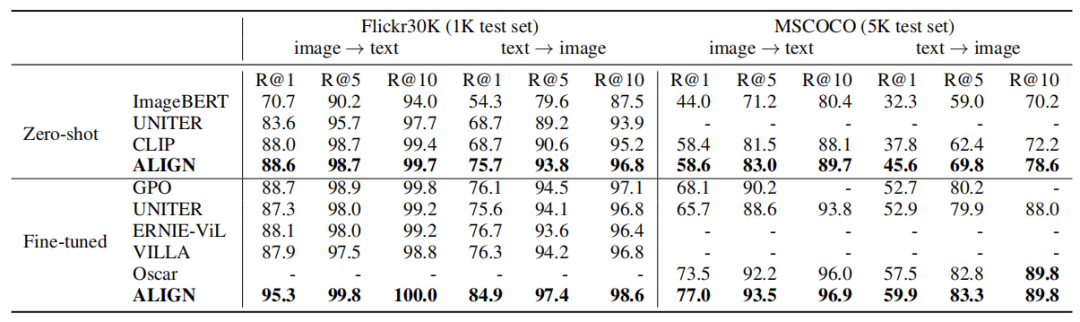
ЩЯБэеЙЪОСЫALIGNдкFlickr30KКЭMSCOCOЪ§ОнМЏЩЯЛљгкZero-shotКЭfine-tuedЩшжУЯТКЭЦфЫћSOTAЗНЗЈЕФЖдБШЁЃПЩвдПДГідкZero-shotЕФЩшжУЯТ,ALIGNдкЭМЯёМьЫїШЮЮёЩЯБШCLIPЛёЕУСЫ7%вдЩЯЕФадФмИФНјЁЃЭЈЙ§ЮЂЕї,ALIGNЕФадФмДѓДѓгХгкЫљгаЯжгаЗНЗЈЁЃ
3.2. Zero-shot Visual Classification

ШчЙћжБНгНЋРрУћЕФЮФБОЪфШыЮФБОБрТыЦї,ALIGNОЭПЩвдЭЈЙ§ЭМЯё-ЮФБОМьЫїШЮЮёЖдЭМЯёНјааЗжРрЁЃЩЯБэеЙЪОСЫALIGNКЭCLIPдкВЛЭЌЗжРрЪ§ОнМЏЩЯZero-ShotЕФНсЙћ,ПЩвдПДГі,ЯрБШгкCLIP,ALIGNдкДѓЖрЪ§Ъ§ОнМЏОпБИадФмЩЯЕФУїЯдгХЪЦЁЃ
3.3. Visual Classification w/ Image Encoder Only

ЩЯБэеЙЪОСЫALIGNКЭЦфЫћЗНЗЈдкImageNetЪ§ОнМЏЩЯЕФБШНЯНсЙћЁЃЭЈЙ§ЖГНсВЮЪ§,ALIGNЕФадФмТдгХгкCLIP,ВЂДяЕН85.5%ЕФSOTAзМШЗТЪЁЃЮЂЕїКѓ,ALIGNБШBiTКЭViTФЃаЭЛёЕУИќИпЕФОЋЖШЁЃ

ЩЯБэеЙЪОСЫдкVTAB(19ИіШЮЮё)ЩЯ,ALIGNКЭBiT-LжЎМфЕФНсЙћБШНЯЁЃНсЙћБэУї,ВЩгУРрЫЦЕФГЌВЮЪ§бЁдёЗНЗЈ,ALIGNЕФадФмгХгкBiT-LЁЃ
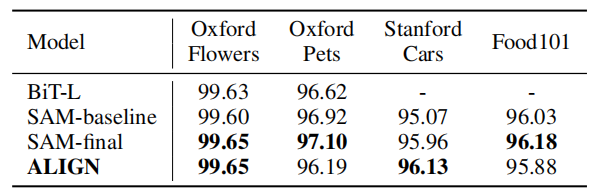
ЩЯБэеЙЪОСЫВЛЭЌФЃаЭдкЯИСЃЖШЗжРрШЮЮёЩЯЕФЧЈвЦбЇЯАНсЙћЁЃ
3.4. Ablation Study
3.4.1. Model Architectures
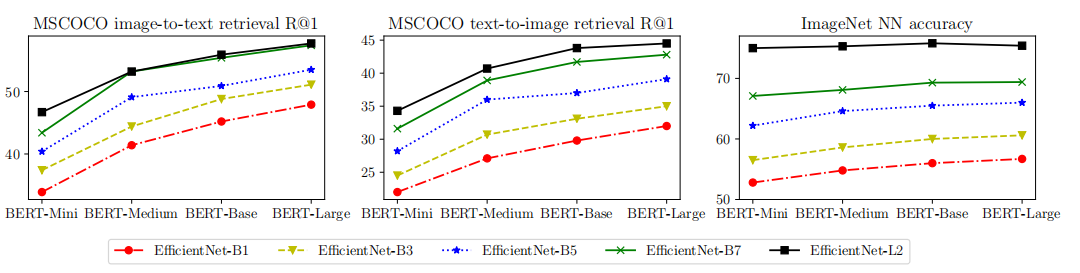
ЩЯЭМЯдЪОСЫВЛЭЌЭМЯёКЭЮФБОBackboneзщКЯЯТЕФMSCOCO zero-shotМьЫїКЭImageNet KNNНсЙћЁЃ
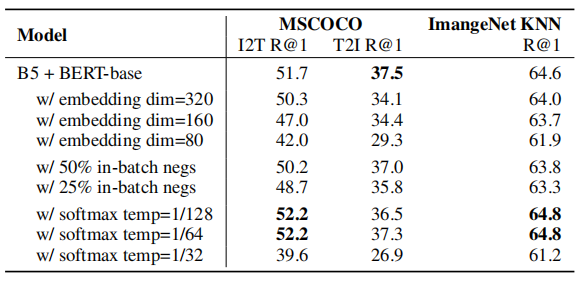
ЩЯБэеЙЪОСЫвЛаЉALIGNФЃаЭБфЬхгыbaselineФЃаЭ(ЕквЛаа)ЕФБШНЯЁЃЕк2-4ааЯдЪО,embeddingЮЌЖШдНИп,ФЃаЭадФмдНИпЁЃЕк5ааКЭЕк6ааЯдЪО,дкsoftmaxЫ№ЪЇжаЪЙгУИќЩйЕФin-batch negatives(50%КЭ25%)ЛсНЕЕЭадФмЁЃЕк7-9аабаОПСЫtemperatureВЮЪ§ЖдsoftmaxЫ№ЪЇЕФгАЯьЁЃ
3.4.2. Pre-training Datasets
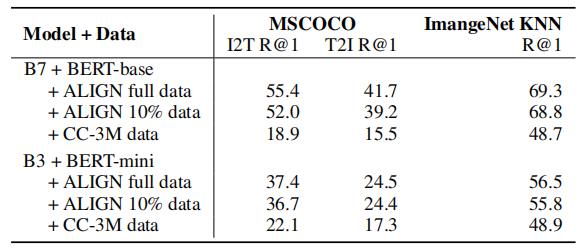
ЩЯБэЕФНсЙћБэУївЛИіДѓЙцФЃЕФбЕСЗМЏЖдгкРЉеЙALIGNФЃаЭКЭЪЕЯжИќКУЕФадФмЪЧжСЙиживЊЕФЁЃ
3.5. Analysis of Learned Embeddings

зїепНЈСЂСЫвЛИіМђЕЅЕФЭМЯёМьЫїЯЕЭГ,РДбаОПЭЈЙ§ALIGNбЕСЗЕФembeddingааЮЊЁЃЩЯЭМЯдЪОСЫгУВЛДцдкгкбЕСЗМЏжа text queriesНјааtext-to-imageМьЫїЕФtop-1НсЙћЁЃ

ЩЯЭМЯдЪОСЫгУЁАЭМЯёЁРЮФБОВщбЏЁБНјааЭМЯёМьЫїЕФНсЙћЁЃ
3.6. Multilingual ALIGN Model

ALIGNЕФвЛИігХЕуЪЧ,ИУФЃаЭЪЧдкгадыЩљЕФЭјТчЭМЯёЮФБОЪ§ОнЩЯНјааЗЧГЃМђЕЅЕФЙ§ТЫжЎКѓбЕСЗЕУЕНЕФ,ВЂЧвУЛгаЖдЬиЖЈгябдНјааЙ§ТЫЁЃвђДЫИУФЃаЭВЛЪмгябдЕФдМЪјЁЃЩЯБэЯдЪОСЫВЛЭЌгябдЯТzero-shotКЭfine-tuningЕФНсЙћЁЃ
? ? ??04??? ??
змНс
дкБОЮФжа,зїепЬсГіСЫвЛжжМђЕЅЕФЗНЗЈ(ALIGN),РћгУДѓЙцФЃдыЩљЭМЯё-ЮФБОЪ§ОнРДРЉДѓЪгОѕКЭЪгОѕгябдЕФБэЪОбЇЯАЁЃзїепБмУтСЫЖдЪ§ОндЄДІРэКЭБъзЂЕФЙЄзїСП,жЛашвЊЛљгкЪ§ОнЦЕТЪЕФМђЕЅЙ§ТЫЁЃдкетИіЪ§ОнМЏЩЯ,зїепЛљгкЖдБШбЇЯАЫ№ЪЇКЏЪ§бЕСЗвЛИіЗЧГЃМђЕЅЕФЫЋБрТыЦїФЃаЭALIGNЁЃ
ALIGNФмЙЛНјааПчФЃЬЌМьЫї,ВЂЯджјгХгкSOTAЕФVSEКЭЛљгкcross-attentionЕФЪгОѕгябдФЃаЭЁЃдкЪгОѕЕФЯТгЮШЮЮёжа,ALIGNвВПЩвдДяЕНгыгУДѓЙцФЃБъзЂЪ§ОнбЕСЗЕФSOTAФЃаЭЯрЫЦЕФадФм,ЩѕжСгХгкSOTAФЃаЭЁЃ
зїепНщЩм
баОПСьгђ:FightingCVЙЋжкКХдЫгЊеп,баОПЗНЯђЮЊЖрФЃЬЌФкШнРэНт,зЈзЂгкНтОіЪгОѕФЃЬЌКЭгябдФЃЬЌЯрНсКЯЕФШЮЮё,ДйНјVision-LanguageФЃаЭЕФЪЕЕигІгУЁЃ
жЊКѕ/ЙЋжкКХ:FightingCV

END
ЛЖгМгШыЁИЪгОѕгябдЁЙНЛСїШК????БИзЂ:VL
