�������һ�����ݷ���ʦ,Ҫ����Ϊ���ǹ�˾��ij���ƷѰ���г�������,�����ô����?
��ͼ������xmind������һ���������:

������Ŀ�������ݴ�ҿ��Դ�1.1С�ڵ���Ŀ������ʼ�����˽�,��ǰ����һ�����������ʱ����ѧϰ���ݷ�����һ����֪ʶ�Ĺ��������������ܽ������,���κδ������Ҳ��ߴͽ̡�
Ŀ¼
ǰ��:���ݷ���˼ά��ҵ������
ǰ����һ�����������ʱ����ѧϰ���ݷ�����һ����֪ʶ�Ĺ��������������ܽ������,���κδ������Ҳ��ߴͽ̡�
�������̸���

��ͼ��һЩ����ƽ̨�����ݷ�������,��ҿ��Կ��¡�
����������ݲɼ����ڵĻ���С��˾�õıȽ϶�һ��,����˾�����Լ��ĻҶȷ���ϵͳ��(�Ѿ���õ���)��
����,ͨ����ģ�ȷ����������������֮��,ҲҪ�ٺͲ�Ʒ����������ͨȷ�����ۡ�
- ÿ�����ڶ��о����Ҫ��,���������ĵ�Ҫ�����:Ŀ�ġ�����˼·��Ԥ��Ч����
- ҵ���ų����������,�Լ����㷨&���ݲ����������������Ӧ�á�
�����
�����г���Ʒ�Ƶķ�չ���ƺ��������,�Ӻ�۵���,�Ӵ��г���ϸ���г�:
- ��������Ʒ�ɹ�ע�û��������û�����,�жϲ�Ʒ���г����û��������Ǵ���,ֻ��Ҫ�ж����µ�������ּ���:
?�� �����г�(�ֽ������г�):������,��ǰ��ע��Щ����û�б�����,���ٵ�����ռ�г�,�������IJ����û����顣
??����=�����ͻ�������:�����ֻ�����ʼʱ���г�,С����Ե���������
?�� �����г�(�ֽк캣�г�):���е���,���ڹ�ע��θ��õ���������,���Ǹ�������û�����(��ƴ�����ǴӺ캣�г�ɱ������)��
??��Ʒ��ֵ=������-������-�滻�ɱ�,������û��ͻ���Դ������,��Ʒ��ֵ����ʵ�֡�
??����=�û�ʱ��(ͣ��ʱ��Խ��,�����ֵԽ��)��
??����:��������һ̨�����ֻ�,С����Դ����г�,�������Ҫ���ֻ����û�����С��,���е��š� - ����:��Ҫ�ò�Ʒ��ֵ�˶�һ���û�,ͬγ�Ⱦ�����ҵ��ȷ������ż�̫��,�����������ܴ�,�������Է�����
���¿��ܾ���ʣ�µĻ�·,����Ի������ĸ��ٷ�չ,�����������������������,�������ܾ�ת�Ƶ�ϸ���г���
����:��QQ���罻����İ���,İİ̽̽��İ�����罻��Ҳ����һ����,��Щ�Ѵ��ڵ�����,û�б����ʵ��,Ҳ�������г���
��Ʒ��������

�� �ͻ���������

- ������������(�����İ�����֧�����Ļ���)���ͻ���ֵԤ������÷����㷨ȥʵ��(���ҳ������Ĵ�����ɱ���������,���ǻ��ڷ���Ľ��������������,�������ı��˵�,��ͷ)
- �ͻ�ϸ�ֿ����þ����㷨ʵ��,�������ۿ����ù�������,��Ʒ��Ӫ�����Կ����û�����(����),��Ϊ��������Ҳ�����÷����ʵ��,��թ���(�ȷ�˵��ֹ�������ë)�������쳣ֵ����;
- �ͻ���ϵ������ʧ�ͻ�ʱ���жϡ���ʧ�ͻ������ж���ЩҲ�����÷����㷨ʵ��(��ʧ�ͻ�ʱ���ж�������漰ʱ������)
������Ҳ���Է���,����ܶ��ҵ���ǿ����÷�����㷨��ʵ�ֵġ�
��Ʒ�ṹ-��ʿ�پ���(BCG Matrix)

������������ͼ�IJ�ʿ�پ���
���������г��ݶ����ǿ�������Ϊ���۶
���ǿ��Ѳ�Ʒ���ֳ���������:������(�ɳ���)��������(������)����ţ��(�ȶ���)���ݹ���(˥����)��
�����õ���Ʒ�����ݺ����ǾͿ����жϲ�Ʒ��������һ���,�ж��Dz����������ռ䡣
����Ѷ���µ�����������ҫ��������ţ���Ʒ,������ҪһЩ�ȶ����ֽ����Ļ�,�Ϳ��Գ����,�൱�ڼ�����,�������ţ���Ʒ��
������Ŀ����Ļ���˼·
�������Ǽ��˽�һ�¾Ϳ����ˡ�
- �˽���Ŀ��˾�ı����ͶԽ���Ա�����
?�� ��˾�IJ�Ʒ�ṹ,�г�����,�Խ��˵Ľ�ɫ��Ȩ���ȼ��ȡ� - ��ͨ��ȷʵ�ʵ���Ŀ����
?�� �Ŷ��ڲ�������Ŀ����
?�� ��ҵ��ͨ����:��ҵ��ĽǶ�����������ܵĽ��������
?�� �Ż���Ŀ����
?�� ��ҵ��˶���Ŀ���� - ������Ŀ������������˼·:ÿһ��������Ŀ��,��Ҫ������֧��,�����Ż���
- ȷ���������ߺ���Ա����,�������ݷ�����
- д�������ۺͷ���
��Ŀ��������
����:���۶��½�,��ô��?
���������ʵ�ܴ�,�ȷ�˵������IJ�Ʒ������:�Ż��Ͽͻ����������������ת���ʵȵȡ���������Ҳ����Ҫ����һ��������ֵġ����������������:
- �˽��漰��Ŀ��ص����е�ҵ���ŵ�����,��,�����
- ���:���۶�=����ת�����͵���
- ����ͨ����:Ӫ������(�),�ƹ㲿��(����),�ͷ�,�ۺ�,��Ӧ��
�� Ӫ��:��Ӫ��(�ҵ���ֵ�ͻ�),�ͻ���Ϊ����(��ӦЧ��),���Ӫ��(������)
�� �ƹ�:��������,����λ,�������(��Ҫ��ǿ�ľ���)
�� �˿�����۷���:�Ż���Ʒ,�Ż��������� - ��֮ͨǰ���뷨,��֮ͨ���Ż�,ȷ����Ŀ����
- �����ռ�:ȷ��ÿһ�����������(�����õ�����)��
�������ᵽ������,�����Խ���ϸ�ֳ�վ��������վ������,��վ�����������Էֳ�ȫ��������ÿ����Ʒ����(����ҳ�ķ���),������Ҫ���ϵIJ������,ֱ�����ܲ��Ϊֹ��
1 ҵ��
���������ǿ�ʼ��ʽ�������Ǵ˴���Ŀ�ı�������
1.1 ��Ŀ����&��Ʒ�ܹ�
�����ҽ���һ�±�����Ŀ�ı��������Ʒ�ܹ���
- �ͻ�����: �ݶ��ٷ��콢��(�ݶ���˾,�ܲ�λ�ڵ¹������ֿ�ɭ,��������200���ص㽨��750��������;ӵ��120,000��Ա����350�ҷ�֧����,�����鲼����������߷���ҽҩ����,�����Լ�ũҵ�ǹ�˾���Ĵ�֧����ҵ.��˾�IJ�Ʒ���೬��10000��)��
- �ͻ�����:Ѱ���г������㡣
- ��Ʒ�ܹ�:

��ʵ��ͼҲ�����ֳ���������˼��,���ǿ����м��������һ���г�,������7���г����ɶ����г�,���½ǵĿ��Կ��������г���
1.2 ����˵��

������Ŀ���е�����ʮ����ȫ��
2 �������DZ������
�Ϲ��,�ȵ���,����һ�����ı��롣
import glob #���ļ�
import os #���ù���·��
import pandas as pd
import re #�������ʽ
import numpy as np
import datetime as dt #ʱ���
from sklearn.linear_model import LinearRegression
import seaborn as sns
from matplotlib import pyplot as plt
import jieba #�ִ�
import jieba.analyse
import imageio #��������Ƶ�
from wordcloud import WordCloud #����
# ���ı���
plt.rcParams['font.sans-serif']='simhei'
plt.rcParams['axes.unicode_minus']=False
sns.set_style("darkgrid",{"font.sans-serif":['simhei','Droid Sans Fallback']})
os.chdir('E:\Data-analysis-project\�����ı��ھ�\data/') # ����·��
os.chdir('./������г�')
2.1 ����Ŀ��&��������
2.1.1 ����Ŀ��
- ����Ŀ��:��Ը�������Ŀ�г�������Ľ�������,�Լ�top100Ʒ������(2017��11�µ�2018��10��),ͨ�������Է���,����仯��ά����:
?�� �������������������
?�� ����������Ŀ�г�ռ�ȼ��仯����
?�� �����г����ж�,���Ƿ����¢�� - ��������:
?�� ��ȡ������Ŀ�г������꽻������
?�� ��ʱ����ܳɸ�����Ŀ��ʱ�����ϵĽ��������
2.1.2 ��������
- ��ȡ�����ཻ�����ݲ��ϲ�
filenames = glob.glob('*�г������꽻��.xlsx')
filenames
������:
['����ɱ����г������꽻��.xlsx',
'��������װ�г������꽻��.xlsx',
'����������������г������꽻��.xlsx',
'����������г������꽻��.xlsx',
'����Һ�г������꽻��.xlsx',
'����Ƭ�г������꽻��.xlsx',
'��ù����Ƭ�г������꽻��.xlsx']
- �Զ��庯����ȡ����xlsx�ļ�:��ȡ�ļ���,��Ϊ����,��ʱ���ʽ
re.search(r'.*(?=�г�)',"����������������г������꽻��.xlsx",).group() # ƥ���г�֮ǰ��wenb
����������������̡�
def load_xlsx(filename):
#��ȡ����Ŀ������
colname = re.search(r'.*(?=�г�)',filename).group()
#��ȡ�ļ�
df = pd.read_excel(filename)
#�����ڵĸ�ʽ(ԭ�����ı���ʽ)
if df['ʱ��'].dtypes == 'int64':
df['ʱ��'] = pd.to_datetime(df['ʱ��'],unit='D',origin=pd.Timestamp('1899-12-30')) # ϵͳĬ�ϵ�ʱ���ʽ
#����������Ϊ����Ŀ��
df.rename(columns={df.columns[1]:colname},inplace=True)
#����ʱ������Ϊ����
df = df.set_index('ʱ��')
return df
dfs = [load_xlsx(i) for i in filenames]
df = pd.concat(dfs,axis=1).reset_index() # ƴ��һ������
df.head()

2.2 ��ϴ&��ȫ����
- �������е�ʱ�����Ǵ�2015��11�µ�2018��10��,��������Ҫ����2016-2018��ÿ������������(�������仯�ĽǶȷ�����Ʒ)
- �������Ǽ���:
?�� ÿ�����֮��û�����Թ��ɵ������Ա仯(������Ϊ�º���֮�������Բ���)
?�� ÿ���Ӧ�·ݵ����������Ա仯��(һ����Ϊ������,������Ϊ������ݵ�����,�����ڴ������Ȳ��仯��) - ���������ǿ��Լ������Իع�Ԥ��
������ÿ������Ŀ�г�,��15��16��17���11/12�����۽��Ԥ��18��Ķ�Ӧ�·�
��ȡ�·ݷ��㽨ģ����:
month = df['ʱ��'].dt.month
month
����������:
0 10
1 9
2 8
3 7
4 6
5 5
6 4
7 3
8 2
9 1
10 12
11 11
12 10
13 9
14 8
15 7
16 6
17 5
18 4
19 3
20 2
21 1
22 12
23 11
24 10
25 9
26 8
27 7
28 6
29 5
30 4
31 3
32 2
33 1
34 12
35 11
Name: ʱ��, dtype: int64
- ѭ��Ԥ��2018��11�º�12�µ����۶�
for i in [11,12]:
# ��ȡ���·ݵ�����
dm = df[month == i] #2015.11 2016.11 2017.11
# ѵ��x�����
xtrain = np.array(dm['ʱ��'].dt.year).reshape(-1,1)
# ����y����������,��Ӧ������
ytest = [pd.datetime(2018,i,1)]
for j in range(1,len(dm.columns)):
# ѵ��y��ָ������
ytrain = np.array(dm.iloc[:,j]).reshape(-1,1)
# �ع齨ģ
lm = LinearRegression().fit(xtrain,ytrain)
# Ԥ�����xΪ2018ʱ���۶� yhat
yhat = lm.predict(np.array([2018]).reshape(-1,1))
ytest.append(round(yhat[0][0],2))
#��Ԥ������ֵ��Ӧ������
newrow = pd.DataFrame([dict(zip(df.columns,ytest))])
#Ԥ�����м�������ǰ,����˵��newrow��append,����df��append
df = newrow.append(df)
df.head()

- ȥ��ԭʼ����
df.reset_index(drop=True,inplace=True)
# ��ͼ�е�������0 0 1 ,��drop=Trueȥ��,��inplace=True�������Dz������µĶ���,ֱ�Ӷ�ԭʼ���������;
- ȥ��15�������
df = df[df['ʱ��'].dt.year != 2015]
df.tail()
���������ǿ��Խ������²���:
- �������������������
- �����������г����۶�ռ�ȼ��仯����
- �����г����ж�,�Ƿ����¢��
2.3 �г��仯��������
- ÿ�������г��Ľ�����ܺ���������
- ��ȡ�����������
df['colsums'] = df.sum(1) #������ܺ���
df.head()

df.insert(1,'year',df['ʱ��'].dt.year) #�����
df.head()

byyear = df.groupby('year').sum().reset_index()
byyear

sns.relplot('year','colsums',kind='line',marker='o',data=byyear,height=4)
plt.title('������������')
plt.xticks(byyear.year,rotation=45) # rotation����ת�Ƕ�
plt.xlabel('���')
plt.ylabel('�ܽ���')
plt.show()
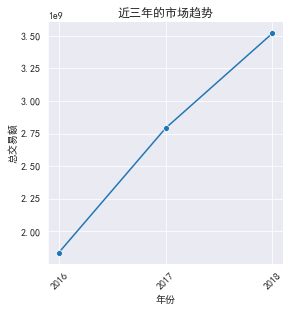
���Կ���:���������������,�����г������ڳɳ��ںͳ����ڡ�
2.4 ���г��仯����
�鿴����Ŀ�г����������۶��ܺ͵ı仯����:
# ͼ�δ�С
f,ax = plt.subplots(figsize=(10,6)) # f��������ͼ��,ax����������ͻ���ͼ,����ͼ��ʱ��Ҫ�õ�fig
#dashes=False ����������
sns.lineplot(data=byyear.set_index('year').iloc[:,:-1],dashes=False,marker='^')
plt.title('������������������')
plt.xticks(byyear.year,rotation=45)
#��ָ��λ�ü��ı�
for a,b in zip(byyear.year,byyear['����ɱ���']):
plt.text(a,b,'%.3e'% b, ha='center',va='bottom',size=12)
plt.xlabel('���')
plt.ylabel('�ܽ���')
plt.show()

ֱ�۵Ŀ�����ɱ���������Һ���нϴ�Ļ��ᡣ
- �鿴����ɱ������������������
g = sns.FacetGrid(byyear,height=5)
g.map(sns.barplot,'year','����ɱ���',color='wheat')
g.map(sns.pointplot,'year','����ɱ���')
for a,b in zip(range(len(byyear)),byyear['����ɱ���']):
plt.text(a,b,'%.3e'% b, ha='center',va='bottom',size=12)
plt.xlabel('���')
plt.ylabel('����ɱ������������������')
plt.xticks(rotation=45)
plt.show()

2.5 ���г�ռ��
�鿴����Ŀ�г����������۶��ܺ͵�ռ��:
#����ÿ��ÿ�����г��ı���
byyear_per = byyear.iloc[:,1:-1].div(byyear.colsums,axis=0)
byyear_per.index = byyear.year
byyear_per
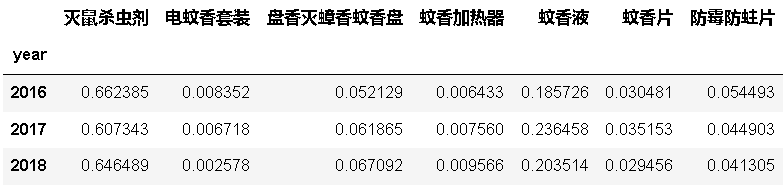
#stacked=True
byyear_per.plot(kind='bar',stacked=True,figsize=(10,8),colormap='tab10')
for a,b in zip(range(len(byyear_per)),byyear_per['����ɱ���']):
plt.text(a,b/2,f'{b*100:.2f}%', ha='center',va='bottom',size=12,color='white')
plt.xlabel('���')
plt.ylabel('�ܽ���ռ��')
plt.title('������������г�����ռ��')
plt.show()

�ɼ�����ɱ���������Һ�ɽ�һ����չ,����Ҫ���ҵ����Ա��һ����ͨ��
�������Ǽ��蹵ͨ�������ص��ע��������ɱ�����
2.6 ���������
byyear

#�õ��м�7��
byyear0 = byyear.iloc[:,1:-1]
byyear0.diff()#һ�ײ�� 17-16 18-17

#����������
byyear0 = byyear.iloc[:,1:-1]
byyear_diff = byyear0.diff().iloc[1:,:].reset_index(drop=True)/byyear0.iloc[:2,:]
byyear_diff.index = ['16-17','17-18']
byyear_diff

#��ͼ�鿴
f,ax = plt.subplots(figsize=(10,8))
sns.lineplot(data=byyear_diff,dashes=False)
plt.title('����������������������')
plt.xlabel('���')
plt.ylabel('�ܽ���������')
plt.show()

�ɼ���������ɱ���������Һ�����Ƚ��ȶ�,���������½������为��
2.7 �г����ж�����(¢��)
���������Ƚ���һ��ʲô��¢��,�Լ�����������ָ������Щ:
- ¢�ϳ̶�,����˵�г���������Ҫ����ָ������ҵ���жȡ�
- ������ָ������ҵ������:CRnָ��,�շҴ��ָ��(Herfindahl-Hirschman Index,��дHHI)��
- ��ʽ:
H
=
��
i
=
1
N
s
i
2
)
i
H=\sum^N_{i=1}s^2_i)i
H=��i=1N?si2?)i(��Щ�ط�sǰ��100������10000),N:��˾����; ��i����˾���г��ݶ
����:�������Ĺ�˾�г�������90%����Ʒ,ʣ���10%��10����ģ��ȵ������߷���,���ҹ�˾��,���Ĺ�˾����80%,�����2%�� H H I = 0. 8 2 + 5 ? 0.0 2 2 + 10 ? 0.0 1 2 = 0.643 ( 64.2 HHI=0.8^2+5*0.02^2+10*0.01^2=0.643(64.2%) HHI=0.82+5?0.022+10?0.012=0.643(64.2 - ָ����Χ��1/N��1,ָ���ĵ�����ʾ����ҵ�С���Ч���Ĺ�˾����,�������г��ṹ��ͬ��ӵ��1.55521����ͬ��ģ�Ĺ�˾��
��Χ:[1/N,���߶Ⱦ�����ҵ��,0.01],(0.01,�������е���ҵ��,0.15],(0.15,���еȼ��С�,0.25], (0.25,���߶ȼ��С�,1] - HHI�ľ�����:
?�� ��ҵϸ��:���ڲ�Ʒ����ϸ��,�������,���������ݾͲ�һ����ȷ�ж���ҵ���жȡ�(����ij������ҵ�и���˾�г��ݶ���ͬ,��ҵ��ͬ,�Կ������¢��)��
?�� ������Χ:���ܵ��г��ݶ�����ռ��һ��,���Ǹ�����˾�����ڵ������¢�ϡ�
?�� ��β����:����С���г�������г�(��������ҵ)�� - ��������:ʹ��top100Ʒ������,ͨ������ָ����ӳ���۶�Ӷ��õ��г�ռ����,������Ʒ���г��ݶ�,����HHIָ�ꡣ
�ǽ��������Ǿ���ʵ��һ�¡�
df1 = pd.read_excel('top100Ʒ������.xlsx')
df1.isna().mean()
����������:
Ʒ�� 0.0
��ҵ���� 0.0
����ָ�� 0.0
������������ 0.0
֧��ת��ָ�� 0.0
���� 0.0
dtype: float64
df1.head()

df1.describe(include='all')

- ���ɽ���ָ��ռ��,���������г��ݶ�
df1['����ָ��ռ��'] = df1['����ָ��']/df1['����ָ��'].sum()
df1['����ָ��ռ��']
����������:
0 0.035998
1 0.032237
2 0.027311
3 0.024488
4 0.023530
...
95 0.004603
96 0.004492
97 0.004465
98 0.004447
99 0.004425
Name: ����ָ��ռ��, Length: 100, dtype: float64
df1.plot(x='Ʒ��',y='����ָ��ռ��',kind='bar',figsize=(15,5))
plt.show()

## HHI
HHI = sum(df1['����ָ��ռ��']**2)
HHI
0.013546334007208914
����õ�:�����г�HHIָ��:0.013546(��135.46),��Ч��˾��:73.82��
2.8 ���DZ������-����
os.chdir('..')#���ص���һ��Ŀ¼
os.chdir('./����ɱ���ϸ���г�')#��������ɱ���ϸ���г��ļ���
2.8.1 ��������&��ϴ����
filename1 = glob.glob('*.xlsx')
dfs1 = [pd.read_excel(i) for i in filename1]
df2 = pd.concat(dfs1,sort=False)
df2.info()
����������:
<class 'pandas.core.frame.DataFrame'>
Int64Index: 6556 entries, 0 to 1742
Columns: 229 entries, ��� to ��Ʒ��
dtypes: float64(129), int64(5), object(95)
memory usage: 11.7+ MB
#�鿴ȱʧֵ
df2.isna().mean()
����������:
��� 0.0
ʱ�� 0.0
ҳ�� 0.0
���� 0.0
���� 0.0
...
�����ɷ� 1.0
���: 1.0
���� 1.0
��װ 1.0
��Ʒ�� 1.0
Length: 229, dtype: float64
- ���һ������ȱʧֵռ�ȳ���98% ���������ݽǶ�����û��������ɾ��
ind1 = df2.isna().mean()> 0.98
sum(ind1)
191
df20 = df2.loc[:,~ind1] #ɾ��ȱʧֵ> 0.98��
df20.isna().mean()
����������:
��� 0.000000
ʱ�� 0.000000
ҳ�� 0.000000
���� 0.000000
���� 0.000000
��ͼ���� 0.000000
��ͼ��Ƶ���� 0.746797
�������� 0.000000
����ID 0.000000
����(����) 0.000000
�ۼ� 0.000000
Ԥ�����۶� 0.005491
�˷� 0.000000
�������� 0.022880
�ղ����� 0.000000
�¼�ʱ�� 0.000000
��Ŀ 0.000000
���� 0.406955
���� 0.000000
�������� 0.000000
Ʒ�� 0.095333
�ͺ� 0.423276
������ 0.421599
���ö��� 0.279896
������̬ 0.286303
ҩƷ�ǼǺ� 0.927090
��Ʒ���� 0.796980
ũҩ�Ǽ�֤�� 0.873093
������ҵ 0.888957
ũҩ��������֤/���ĺ� 0.889262
ũҩ��Ʒ��֤�� 0.889262
ũҩ���� 0.889262
���� 0.882093
ũҩ�ɷ� 0.885754
��Ч�ɷ��ܺ��� 0.889262
���� 0.873093
����� 0.889262
ũҩ���� 0.973612
dtype: float64
- ����ֵ��ȫһ�µĽ���ɾ��
ind2 = np.array([len(df20[i].unique()) == 1 for i in df20.columns])
df21 = df20.loc[:,~ind2]
df21.isna().mean()
����������:
��� 0.000000
ʱ�� 0.000000
ҳ�� 0.000000
���� 0.000000
���� 0.000000
��ͼ���� 0.000000
��ͼ��Ƶ���� 0.746797
�������� 0.000000
����ID 0.000000
����(����) 0.000000
�ۼ� 0.000000
Ԥ�����۶� 0.005491
�˷� 0.000000
�������� 0.022880
�ղ����� 0.000000
�¼�ʱ�� 0.000000
���� 0.406955
���� 0.000000
�������� 0.000000
Ʒ�� 0.095333
�ͺ� 0.423276
������ 0.421599
���ö��� 0.279896
������̬ 0.286303
ҩƷ�ǼǺ� 0.927090
��Ʒ���� 0.796980
ũҩ�Ǽ�֤�� 0.873093
������ҵ 0.888957
ũҩ��������֤/���ĺ� 0.889262
ũҩ��Ʒ��֤�� 0.889262
ũҩ���� 0.889262
���� 0.882093
ũҩ�ɷ� 0.885754
��Ч�ɷ��ܺ��� 0.889262
���� 0.873093
����� 0.889262
ũҩ���� 0.973612
dtype: float64
#ɾ��ҩƷ�ǼǺ� ֮�������
ind3 = df21.columns.get_loc('ҩƷ�ǼǺ�')
df22 = df21.iloc[:,:ind3]
df22.isna().mean()
����������:
��� 0.000000
ʱ�� 0.000000
ҳ�� 0.000000
���� 0.000000
���� 0.000000
��ͼ���� 0.000000
��ͼ��Ƶ���� 0.746797
�������� 0.000000
����ID 0.000000
����(����) 0.000000
�ۼ� 0.000000
Ԥ�����۶� 0.005491
�˷� 0.000000
�������� 0.022880
�ղ����� 0.000000
�¼�ʱ�� 0.000000
���� 0.406955
���� 0.000000
�������� 0.000000
Ʒ�� 0.095333
�ͺ� 0.423276
������ 0.421599
���ö��� 0.279896
������̬ 0.286303
dtype: float64
unless = ["ʱ��","����","��ͼ����","��ͼ��Ƶ����","��������","�˷�" ,"�¼�ʱ��","����" ,"ҳ��","����"]
unless
[��ʱ�䡯, �����ӡ�, ����ͼ���ӡ�, ����ͼ��Ƶ���ӡ�, ���������⡯, ���˷ѡ�, ���¼�ʱ�䡯, ��������, ��ҳ�롯, ��������]
df23 = df22.drop(columns=unless)
df23.isna().mean()
����������:
��� 0.000000
����ID 0.000000
����(����) 0.000000
�ۼ� 0.000000
Ԥ�����۶� 0.005491
�������� 0.022880
�ղ����� 0.000000
���� 0.406955
�������� 0.000000
Ʒ�� 0.095333
�ͺ� 0.423276
������ 0.421599
���ö��� 0.279896
������̬ 0.286303
dtype: float64
df23.dtypes
����������:
��� object
����ID int64
����(����) int64
�ۼ� float64
Ԥ�����۶� float64
�������� float64
�ղ����� int64
���� object
�������� object
Ʒ�� object
�ͺ� object
������ object
���ö��� object
������̬ object
dtype: object
df23 = df23.astype({'����ID':'object'}) #������IDת��object
df23.reset_index(drop=True,inplace=True)
df23.describe()

df23.head()

2.8.2 ����
ͨ����������,���ǿ��Եõ����½���:
- ���������г����ڿ���������,�����ڳɳ��ڵ�������;
- ����ɱ����г��ݶ�ϴ�(����60%),Լ�ǵڶ�������Һ�Ķ���,�г������ʽӽ�40%,������Ϊ�����Dz�Ʒ��Ŀ,��Ҫ����Ͷ�ʺ��ص��ע;
- �����г�������¢��,�ṹ������,������Լ���,��û�����Ե����Դ�˾��ѹ����
3 ������
3.1 ҵ����
- ����Ŀ�г�ȷ����(����ɱ����г�),ȷ���г������ܻ�ӭ�IJ�Ʒ���C>ϸ�ּ۸�ΨC>���Խ�һ������:
ʲô���ļ۸���Ϊ���г�,ʲô������Ʒ���ϴ��ڿ�ζ�� - ��ͬ��;����Ʒ��λ:
?�� ������Ʒ:�۸��,����ռ伸��û��,Ŀ����Ϊ��������
???�� ��ȡ�����ķ�ʽ����Ѻ�������,���������Ե��(lian),���Ƹ��������ɱ������Ƕ��������ȵ�Ҫ��,����Ӫ��������Ʒ:�۸����,ֻҪ��ӯ����Դ��
?�� ������Ʒ:�۸����,��Ҫ��ӯ����Դ��
?�� Ʒ����Ʒ:�۸�ƫ��,������Ʒ���ݳ�Ʒ�� - ��Ʒ����ʱҪ���ǵ�����:�۸�Ʒ�������û�ϲ�öȡ���Ʒ����ȡ�
3.2 ��Ʒ���
- ʹ������ɱ���ϸ���г�����(��ֹ��2018��11��22��30��Ľ�������):
?�� ��ȡ����ļ����Һϲ�
?�� ��ϴ:ȥ������ȱʧֵ����,ȥ����һֵ����,ȥ�����ϲ����õ���,��:��ʱ�䡱,�����ӡ�,����ͼ���ӡ�,����ͼ��Ƶ���ӡ�,��ҳ�롱,��������,���������⡱,���˷ѡ�,���¼�ʱ�䡱,�������� �� - �鿴����Ʒ������ܵġ�Ԥ�����۶�ķֲ�,�Դ˱�ʾ�г��ֲ������
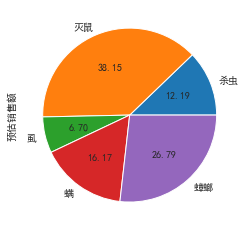
byclass = df23['Ԥ�����۶�'].groupby(df23['���']).sum()
byclass
���
ɱ�� 8207628.10
���� 25686011.99
ʭ 4512886.01
�� 10886752.88
��� 18037223.68
Name: Ԥ�����۶�, dtype: float64
byclass.plot.barh()

byclass.plot.pie(autopct='%.2f')
import plotly.graph_objects as go #����ͼ�� ������PowerBI
fig = go.Figure(data=[go.Pie(labels=byclass.index,values=byclass.values)])
fig.show()

- ���Կ����ص���Ҫ�о����г�����������,��������ѡ��������
3.3 ������
- ѡ���������ݽ�һ�������C>���ݡ��ۼۡ����м۸�,�õ����ɵļ۸����䡣
df24 = df23[df23['���']== '����']
df24

df24['�ۼ�'].describe()
����������:
count 1523.000000
mean 49.018910
std 69.762057
min 0.010000
25% 15.800000
50% 27.700000
75% 52.600000
max 498.000000
Name: �ۼ�, dtype: float64
df24['�ۼ�'].plot.hist()

#�Զ������ ���۶� �������ͱ���ת�ɷ����ͱ���
bins = [0,50,100,150,200,250,300,500] #�ֽ���
labels = ['0_50','50_100','100_150','150_200','200_250','250_300','300_500']#���ӵı���
#pd.cut (0,50] ---> [0,50]
df24['�۸�����'] = pd.cut(df24['�ۼ�'],bins,labels=labels,include_lowest=True)
df24['�۸�����'].value_counts()
����������:
0_50 1138
50_100 242
100_150 62
150_200 35
300_500 28
250_300 9
200_250 9
Name: �۸�����, dtype: int64
df24

- ÿ���۸��������:Ԥ�����۶�(�ܺ�),���۶�ռ��,������(��ͬ������ID����),������ռ��,������ƽ�����۶�(��ͬ������ƽ��Ԥ�����۶�,��������Ϊ�����ķ���,������ƽ �����۶�Խ��,����Խ��,���������۶�߲��еķ�),��Ծ�����(��ǰһ���������Ա任 �õ�0��ʾ��Ŀ����С����,1��ʾ���)��
#���������----�۸�����
by = '�۸�����'
df = df24
#���ݼ۸��������
df.groupby(by).sum()

#��Ԥ�����۶��г����
byc = pd.DataFrame(df.groupby(by).sum().loc[:,['Ԥ�����۶�']])
byc
#���۶�ռ�ȡ�����������������ռ�ȡ�����������ƽ�����۶�
byc['���۶�ռ��'] = byc['Ԥ�����۶�'] / byc['Ԥ�����۶�'].sum()
byc['������'] = df.groupby(by).nunique()['����ID']
byc['������ռ��'] = byc['������'] / byc['������'].sum()
byc['������ƽ�����۶�'] = byc['Ԥ�����۶�']/byc['������']
byc

- ������(������ƽ�����۶�ķ���)
- ������ƽ�����۶�Խ��,����Խ��,ԽС,����Խ��
byc['��Ծ�����'] = 1- (byc['������ƽ�����۶�']-byc['������ƽ�����۶�'].min())/(
byc['������ƽ�����۶�'].max()-byc['������ƽ�����۶�'].min())
byc

# �Զ��庯��
def byfun(df,by,sort='������ƽ�����۶�'):
byc = pd.DataFrame(df.groupby(by).sum().loc[:,['Ԥ�����۶�']])
#���۶�ռ�ȡ�����������������ռ�ȡ�����������ƽ�����۶�
byc['���۶�ռ��'] = byc['Ԥ�����۶�'] / byc['Ԥ�����۶�'].sum()
byc['������'] = df.groupby(by).nunique()['����ID']
byc['������ռ��'] = byc['������'] / byc['������'].sum()
byc['������ƽ�����۶�'] = byc['Ԥ�����۶�']/byc['������']
byc['��Ծ�����'] = 1- (byc['������ƽ�����۶�']-byc['������ƽ�����۶�'].min())/(
byc['������ƽ�����۶�'].max()-byc['������ƽ�����۶�'].min())
if sort:
byc.sort_values(sort,ascending=False,inplace=True)
return byc
byprices = byfun(df24,'�۸�����')
byprices

def mcplot(bydf,figsize=(10,4)):
ax = bydf.plot(y='��Ծ�����',linestyle='-',marker='o',figsize=figsize)
bydf.plot(y='���۶�ռ��',kind='bar',alpha=0.8,color='wheat',ax=ax)
plt.show()
mcplot(byprices)

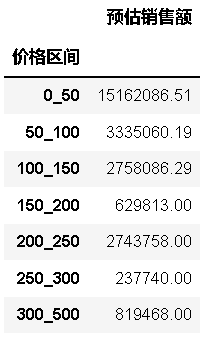
��������������۶��,��������������,�������۶�ռ�ȿ�������Ϊ�г��ݶ
�ɼ�0-50������,������,�������г�(�Աȵ���50-100,����С,������С)
200-250,����С,�����г�������ѡ��,���ڻ���㡣
�ɼ�����ϲ������Ŀ��:�г��ݶ��(��ʾ���ʺϴ���),��Ծ����ȵ�(û����)��Ҳ�����ҵ���������Ƶ���Щ������ȥ�ֵ��⡣
3.4 0_50-ϸ�ּ۸��г�
- ��������ѡ����������0-50ϸ���г���һ������
df25 = df24[df24['�۸�����']=='0_50']
df25['�ۼ�'].plot.hist()

- ��һ��ϸ�ֵõ��µĸ�С�ļ۸�����,����ÿ�������ָ��
#�Զ������ ���۶� �������ͱ���ת�ɷ����ͱ���
bins_01 = [0,10,20,30,40,50] #�ֽ���
labels_01 = ['0_10','10_20','20_30','30_40','40_25']#���ӵı���
#pd.cut (0,50] ---> [0,50]
df25['�۸�������'] = pd.cut(df25['�ۼ�'],bins_01,labels=labels_01,include_lowest=True)
byprices_01 = byfun(df25,'�۸�������')
byprices_01

mcplot(byprices_01)

�ɼ�10-20�����ȵ�,������,��ѡ,20-30Ҳ������
200-250ϸ���г�Ҳ��ͬ���ķ���˼·��
3.5 �������Է���
df25.head()

- ��������
bystore = byfun(df25,'��������')
bystore
mcplot(bystore)

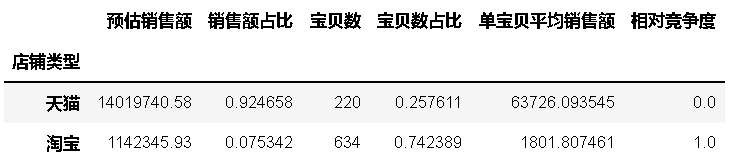
�ɼ���è�������涼�����Ա���
- �ͺ�
bytype = byfun(df25,'�ͺ�')
#Ԥ�����۶� ǰ5%���ͺ�
bytype1 = bytype[bytype['Ԥ�����۶�']>=bytype['Ԥ�����۶�'].quantile(0.95)]
bytype1

mcplot(bytype1)

�ɼ���Ȼճ����г��ݶ��ձ�ϸ�,����0005��MT007�ھ������������Ե����ơ�
- ������̬
byshape = byfun(df25,'������̬')
byshape

mcplot(byshape)

�ɼ��г��ݶ���ߵ��ǹ���,������Ҳƫ��,����ˮ��Ȼ�����ȵ�,�����г��ݶ�ϵ�,����������Ϊ������������̬���ǹ��塣
3.6 ������-����
ͨ�������������ǿ��Եó����½���:
- ����ɱ����г���,��Ҫ�ص��ע�IJ�Ʒ�����:��������;
- ������:
?�� �����г�������0-50�ļ۸��,����۸�ξ���Ҳ�ܼ���;
?�� 200-250����۸���г��ݶ�ռ10%����,�����Ⱥܵ�,��ֵ���ھ�ĸ��г�. - ����0-50�۸�εIJ�Ʒ�г���:
?�� 10-20�۸���г�������,�����ȵ�,ֵ�ý�һ������,20-30Ҳ����;
?�� �������ͷ�����è���������Ա�;
?�� �г��ݶ�ߵ��ͺ���ճ���,Ȼ���ͺ�0005�г��ݶ��,�����Ƚϵ�,ֵ�ÿ���;
?�� ��Ʒ��������̬�������ǹ���,Ҳ�DZ������Ͽɵ���̬;
?�� ��������̬Ϊ����,������Ϊ1ʱ,�г��ݶ�߾����ȵ�,ֵ�ÿ�����
4 ��������
����֮ǰ��top100Ʒ������,�����г��ݶ�ǰ�����̼�:�ݶ�,������,���١�
4.1 ��������
- ��Ⱥ�������:����Ʒ�Ƶ���Ⱥ��������һ��(����ʡ��)��
- Ʒ��ֲ�:���ݸ����̼Ҳ�Ʒ�������ö���ķֲ�,����ÿ��Ʒ�ƵIJ�Ʒ�ֲ����(����չ��������չ)��
- ��Ʒ�ṹ:���ݲ�ʿ�پ���,������Ʒ�Ʋ�ͬ��Ʒ�Ľṹ����,Ϊ��Ʒ��չ�����ṩ���ݡ�
- �����ṹ:ͨ�������ṹ������Ч���ĶԱ�,�ƶ��ƹ���ԡ�
- ��Ʒ����:���ʲ�Ʒά�ȡ�
4.2 Ʒ��ֲ�-��Ʒ���
ʹ����Ʒ�������ݷ������ҵIJ�Ʒ���ķֲ�:
os.chdir('./��Ʒ��������/')
filename2 = glob.glob('*.xlsx')
filename2
[�����ټҾӽ�30����������.xlsx��, ���ݶ���30����������.xlsx��, ���������콢���30����������.xlsx��]
df3 = pd.read_excel(filename2[2])
df3.head(1)

# ɾ����������
def load_xlsx_title(filename):
df = pd.read_excel(filename)
unless = ['���','��������','��Ʒ����','��ͼ����','��Ʒ����']
df.drop(columns=unless,inplace=True)
return df
df3bai = load_xlsx_title(filename2[1])
df3bai.head()

df3an = load_xlsx_title(filename2[0])
df3an.head()

df3kl = load_xlsx_title(filename2[2])
df3kl.head()

bai31 = df3bai.groupby('��Ŀ').sum()
bai31

an31 = df3an.groupby('��Ŀ').sum()
an31

kl31 = df3kl.groupby('��Ŀ').sum()
kl31

#��ͼ [0,1,2]
fig,axes = plt.subplots(1,3,figsize=(10,6))
ax = axes[0] #��һ���ݶ�
bai31['���۶�'].plot.pie(autopct='%.f',title='�ݶ�',startangle=30,ax=ax)
ax.set_ylabel('')
ax = axes[1] #�ڶ�������
an31['30�����۶�'].plot.pie(autopct='%.f',title='����',startangle=60,ax=ax)
ax.set_ylabel('')
ax = axes[2] #������������
kl31['30�����۶�'].plot.pie(autopct='%.f',title='������',startangle=90,ax=ax)
ax.set_ylabel('')
plt.show()
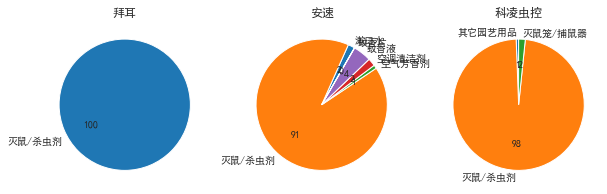
�ɼ��ݶ�ֻ��һ���г�,�������в�ͬ�г�,����Ҫ�г���������ɱ�����
4.3 Ʒ��ֲ�-���ö���
�������ҵ����ö���ķֲ�:
bai32 = df3bai.groupby('ʹ�ö���').sum()
bai32

an32 = df3an.groupby('���ö���').sum()
an32

kl32 = df3kl.groupby('���ö���').sum()
kl32

#��ͼ [0,1,2]
fig,axes = plt.subplots(1,3,figsize=(10,6))
ax = axes[0] #��һ���ݶ�
bai32['���۶�'].plot.pie(autopct='%.f',title='�ݶ�',startangle=30,ax=ax)
ax.set_ylabel('')
ax = axes[1] #�ڶ�������
an32['30�����۶�'].plot.pie(autopct='%.f',title='����',startangle=60,ax=ax)
ax.set_ylabel('')
ax = axes[2] #������������
kl32['30�����۶�'].plot.pie(autopct='%.f',title='������',startangle=90,ax=ax)
ax.set_ylabel('')
plt.show()
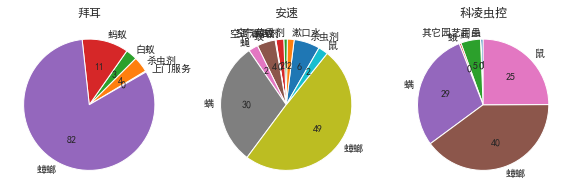
�ݶ�����Ҫ���������,���������ҳ���֮�����,��;
����֮ǰ�ķ�������������������г��ݶ��;Ӧ�ÿ������г�,����������,Ҳ�����������Ҷ����ص����г���
4.4 ��Ʒ�ṹ����-�ݶ�
os.chdir('..')
os.chdir('./��Ʒ��������')
filename3 = glob.glob('*.xlsx')
filename3
[������ȫ����Ʒ��������.xlsx��, ���ݶ�ȫ����Ʒ��������.xlsx��, ��������ȫ����Ʒ��������.xlsx��]
4.4.1 �ݶ�����
ʹ����Ʒ��������,ÿ�������߷ֿ�����,�ȷ����ݶ������ݡ�
df4bai = pd.read_excel(filename3[1])
df4bai.head()

df4bai.info()
����������:
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 142 entries, 0 to 141
Data columns (total 9 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 Ʒ�� 142 non-null object
1 ʱ�� 142 non-null datetime64[ns]
2 ��Ʒ 142 non-null object
3 ��ҵ���� 142 non-null int64
4 ����ָ�� 142 non-null int64
5 ������������ 142 non-null float64
6 ֧��ת��ָ�� 142 non-null int64
7 ���� 142 non-null object
8 ����� 142 non-null float64
dtypes: datetime64[ns](1), float64(2), int64(3), object(3)
memory usage: 10.1+ KB
- 5���µ�����,ÿ����Ʒ���5���¶�����,������1����,������Ҫ����Ʒ�������
df4bai['��Ʒ'].value_counts().count()
44
#�Զ��������ܺ���
def byproduct(df):
dfb = df.groupby('��Ʒ').mean().loc[:,['������������']] #����������������ֵ
dfb['�����'] = df.groupby('��Ʒ').sum()['�����']
dfb['�����ռ��'] = dfb['�����']/dfb['�����'].sum()
dfb['��Ʒ����'] = df.groupby('��Ʒ').count()['�����']
dfb.reset_index(inplace= True)
return dfb
bai4 = byproduct(df4bai)
bai4.head()

���н����������ȿɱ�ʾ�г���չ��,�����ռ�ȿɱ�ʾ�г��ݶ
bai4.describe(percentiles=[0.1,0.9,0.99])

def block(x):
qu = x.quantile(.9)
out = x.mask(x>qu,qu) #������90%��λ���Ľ����滻
return(out)
def block2(df):
df1 = df.copy()
df1['������������'] = block(df1['������������']) #ʹ�ø�ñ�������滻������������
df1['�����ռ��'] = block(df1['�����ռ��']) #ʹ�ø�ñ�������滻������������
return df1
bai41 = block2(bai4)
bai41.describe(percentiles=[0.1,0.9,0.99])

�����������Ⱥͽ����ռ��������ָ������ֵ��Զ����3/4��λ��,��Ϊ���쳣ֵ,���������ñ��,������ͼ��
4.4.2 ��Ʒ�ṹ-�ݶ�-BCGͼ
���岨ʿ�پ����ͼ���� ����ʹ�þ�ֵ����λ�����ָ�(0.33 0.33) ��Ϊ��ʿ�پ�����и��ߡ�
# mean True ��ֵ
# mean False ��λ�����ָ�(0.33 0.33)
def plotBOG(df,mean = False,q1=0.5,q2=0.5):
f,ax = plt.subplots(figsize=(10,8))
ax = sns.scatterplot('�����ռ��','������������',hue='��Ʒ����',size='��Ʒ����',
sizes=(20,200),palette='cool',legend='full',data=df)
#�����еĵ��������,���Ӧ����������(��Ӧ��Ʒ),����̽��
for i in range(0,len(df)):
ax.text(df['�����ռ��'][i]+0.001,df['������������'][i],i) #������ע�����x������
if mean:
plt.axvline(df['�����ռ��'].mean())#����
plt.axhline(df['������������'].mean())#ˮƽ��
else:
plt.axvline(df['�����ռ��'].quantile(q1))#����
plt.axhline(df['������������'].quantile(q2))#ˮƽ��
plt.show()
plotBOG(bai41,mean=True)

��Ĵ�СΪ��Ʒ����,����λ����Ϊ��ʿ�پ���ķָ���,�ݶ���BOGͼ����:
plotBOG(bai41,mean=False)

���ǿ��Ը���ʵ�ʵ�ҵ��ѡ������ķָ���,����ҵ����ȷ��(������Ϊ����0.1����ҵ�����,�Ϳ�����Ϊ�ָ���)
��ͼ���Կ���:���Dz�Ʒ����ţ��Ʒ����Ʒ�����ձ�Ƚ϶ࡣ
û��ͻ�������Dz�Ʒ,�����п�������Dz�Ʒ�������Ʒ��
4.4.3 ��Ʒ�ṹ-�ݶ�-����
�鿴������Ʒ�ṹ�IJ�Ʒ(�����ݹ�)
���ֲ�Ʒ����,���ĵ㲻ͬ,�������ݲ�ͬ
- ���Dz�Ʒ:������,��ʲô������,��Ʒһ�㲻��
- ��ţ��Ʒ:�ϱ���,�����г��ݶ�,�������ռ������
�����Ʒ,DZ����,�����г�������,������������������
����Ҫ�鿴ʵ������,��ʹ�ø�ñǰ����,�ݶ����Dz�Ʒ����:
def extractBOG(df,q1=0.5,q2=0.5,by='�����ռ��'):
# ���Dz�Ʒ
star = df.loc[(df['�����ռ��'] >= df['�����ռ��'].quantile(q1))#��������0.5
& (df['������������'] >= df['������������'].quantile(q2)),:] #�����������ȴ���0.5
star = star.sort_values(by,ascending=False)
# �����Ʒ
cow = df.loc[(df['�����ռ��'] >= df['�����ռ��'].quantile(q1))#��������0.5
& (df['������������'] < df['������������'].quantile(q2)),:] #��������������0.5
cow = cow.sort_values(by,ascending=False)
# �����Ʒ
que = df.loc[(df['�����ռ��'] < df['�����ռ��'].quantile(q1))#�����С��0.5
& (df['������������'] >= df['������������'].quantile(q2)),:] #�����������ȴ���0.5
que = que.sort_values(by,ascending=False)
return star,cow,que
bai4star,bai4cow,bai4que = extractBOG(bai4)
bai4star

��Ҫ�dz���ɱ��,����ռ�Ȳ���,����һ�㡣
4.4.4 ��Ʒ�ṹ-�ݶ�-��ţ
bai4cow

�ɼ�ռ����ߵ��dz��,���Ҳռһ����,ռ��һ�㡣
4.4.5 ��Ʒ�ṹ-�ݶ�-����

�ɼ�����Ȼ������ɱ�档
����������������������,��֮ǰ��������������ߵ��г��ݶ�,������Ϊ��һ�������㡣
4.4.6 �ܽ�
�ܽ�:�ݶ��ֲ�Ʒ�����ڳ����,ɱ��Ҳ��һ���Ĺ�ģ,�������Dz�Ʒ�Է���,���Խ�һ����չ�����Ʒ����Ϊ���Dz�Ʒ��
4.5 ��Ʒ�ṹ����-����
4.5.1 ��������
df4an = pd.read_excel(filename3[0])
df4an.head()

df4an['��Ʒ'].value_counts().count()
49
an4 = byproduct(df4an)
an4.head()

an4.describe()

an41 = block2(an4)
an41.describe(percentiles=[0.1,0.9,0.99])

4.5.2 ��Ʒ�ṹ-����-BCGͼ
����������֮ǰһ��,��ֱ�ӿ�ͼ�Ͳ�Ʒ:
plotBOG(an41)

�ɼ���ţ��Ʒ��,���Dz�Ʒ������ǰ;,�����Ʒ������DZ��,�ݹ���Ʒ���ࡣ
4.5.3 ��Ʒ�ṹ-����-����
anstar,ancow,anque = extractBOG(an4)
anstar

ɱ��ͳ����ֶ�������
4.5.4 ��Ʒ�ṹ-����-��ţ
ancow.head()

��Ҫ�dz��,�Ͱݶ�����������
4.5.5 ��Ʒ�ṹ-����-����
anque.head()

ǰ���������,����,ɱ��,���з�չ�ռ䡣
4.5.6 �ܽ�
����û�����Ե������г�;�ݶ��Ͱ��ٱȽ�:�ݶ�ɱ�����ϱ���,������һ��������
4.6 ��Ʒ�ṹ����-������
4.6.1 ����������
df4ke = pd.read_excel(filename3[2])
df4ke.head()

df4ke['��Ʒ'].value_counts().count()
31
ke4 = byproduct(df4ke)
ke4.head()

ke4.describe()

ke41 = block2(ke4)
ke41.describe(percentiles=[0.1,0.9,0.99])

4.6.2 ��Ʒ�ṹ-������-BCGͼ
plotBOG(ke41)

�ɼ���ţ��Ʒ��,���Dz�Ʒ��,�־�����ǿ,�����Ʒ������DZ��,�ݹ���Ʒ�١�
4.6.3 ��Ʒ�ṹ-������-����
kestar,kecow,keque = extractBOG(ke4)
kestar

��Ҫ������,������ɱ�档
4.6.4 ��Ʒ�ṹ-������-��ţ
kecow.head()

��Ҫ�dz��,�к�С������������
4.6.5 ��Ʒ�ṹ-������-����
keque.head()

�нϴ�DZ�����dz�����
4.6.6 �ܽ�
�����ػ�����չ�����Ʒ,Ȼ��ÿ����Ʒ�ṹ��Զ���(��ţ���,��������,DZ������),û�к�����֧��,������������ôǿ��
4.7 �����ṹ-ҵ����
4.7.1 ����
- Ŀǰ��������Ҫ������鹹��:�������,�����������������ʡ�
?�� һ��ĵ���ռ�ȷֱ���50-60%,30%,10-15%
?�� ���������,��������ռ60%,����������ֻռ��������30%-40% - ��������û���ض��ı���,������ֵ��һ�㲻����40%(��������ʱ��),�������Ŀ�����ʸ߾�������,ռ��80%Ҳ�п��ܡ�
- �����̸������������Ƿ�,Ӧ�ÿ���������ȫ�����۶��ռ�ȡ�һ�������10%���ҡ�(ͬ���Ĺ�����ռ��,����CPC(����ɱ�),��������ռ�Ȼ�����)��
- ���������������������ǰ��:
1)�����������Ƿ��ʺ���ĵ��̺ͱ�����
2)������Ҫ�ﵽһ����������
3)�����ʺ��г��� - �����������:һ������С�������,�����ʱ��С����������,һ�㽨����������������,�������������,���������ƹ�Ԥ��ռ�ȡ�
- �õ������ṹ:
1)�����IJ�Ʒ�ṹ��
2)��������(�������������)�Ĺؼ��ʲ��֡�
3)�ʵ��ĸ��ѹ��ռ�ȡ�
4)�����������������������
5)�ο�ͬ�е������ṹ��
- �����ṹ-��������
���������½���,��ô����:
- �ȿ���ҵ����,���Dz���ȫ��ҵ���
- �鿴�����Ƿ��쳣�������ҵ����ݶ����Ե�����,��ͬ�н������Ƿ�Ҳ����ͬ����
- ��̨���������Ʊ��������»�����ȫ�걦��ͬ���»�
?�� �����»�:�鿴���ۻ���,��û����������,�鿴�����������:
???�� ��������»�:��������ڲ���,����������������������,�����Ƿ���ǿ��ľ�������;
???�� ������������»�:����������ÿһ�������(�ղ���,�ӹ���,ת����,ͣ��ʱ����),�жϿͻ������Ƿ����仯,�������˺�֮ǰ��ͬ����Ⱥ,����Ч�����Ӷ�Ӱ�챦��Ȩ�ء�
?�� ���б����»�:��ע��̬����,�������ۺ�����,���ܵ�ԭ����:����,��������,�ٷ� ������������,���쳣����:�ѿ�����ÿһ�����ݵı仯����,����Ӱ�����Ȩ�ص����ط��ơ�
�������������,����������ʽ������������һ�¡�
4.7.2 �����ṹ-�ݶ�
os.chdir('..')
os.chdir('./������������')
filename4 = glob.glob('*.xlsx')
filename4
[�����ټҾ��콢����������.xlsx��, ���ݶ��ٷ��콢����������.xlsx��, ���������콢����������.xlsx��]
df5bai = pd.read_excel(filename4[1])
df5bai.head(10)

# ֻȡ����ָ������ǰʮ����������
df0 = df5bai
top10 = df0.sort_values('����ָ��',ascending=False).reset_index(drop=True).iloc[:10,:]
#���㽻��ָ��ռ��,����ָ�������۶�ķ�ӳ
top10['����ָ��ռ��'] = top10['����ָ��']/top10['����ָ��'].sum()
top10.set_index('������Դ',inplace=True)
top10

#�Ѹ��ѵ����� ���б��
paid = ['��������','ֱͨ��','�Ա���']
ind = np.any([top10.index == i for i in paid],axis=0) #true Ϊ���ѵ�
ind
array([False, False, False, False, True, False, False, True, False, True])
�Զ��庯��-�����ṹ˵��:
def flow(df):
# ֻȡ����ָ������ǰʮ����������
df0 = df.copy()
top10 = df0.sort_values('����ָ��',ascending=False).reset_index(drop=True).iloc[:10,:]
#���㽻��ָ��ռ��
top10['����ָ��ռ��'] = top10['����ָ��']/top10['����ָ��'].sum()
top10.set_index('������Դ',inplace=True)
#�Ѹ��ѵ����� ���б��
paid = ['��������','ֱͨ��','�Ա���']
ind = np.any([top10.index == i for i in paid],axis=0) #true Ϊ���ѵ�
explode = ind * 0.1 #�൱�����ⱬ0.1�ľ���
ax = top10['����ָ��ռ��'].plot.pie(autopct='%.1f%%',
figsize=(8,8),colormap='cool',explode = explode)
ax.set_ylabel('')
plt.show()
#���ռ��:�ܽ���ָ������������ռ�ȡ��������������Ľ���ָ��
salesum = top10['����ָ��'].sum() #�ܽ���ָ��
paidsum = top10['����ָ��ռ��'][ind].sum() #��������ռ��
paidsale = salesum * paidsum #�������������Ľ���ָ��
print(f'ǰʮ������:�ܽ���ָ��:{salesum:.0f};��������ռ��:{paidsum*100:.2f}%;�������������Ľ���ָ��:{paidsale:.0f}')
return top10
bai5 = flow(df5bai)

ǰ10������:�ܽ���ָ��:2334051;��������ռ��:21.85%;����������������ָ��:509959��
4.7.3 �����ṹ-����
df5an = pd.read_excel(filename4[0])
df5an.head(10)

# ֻȡ����ָ������ǰʮ����������
df0 = df5an
top10 = df0.sort_values('����ָ��',ascending=False).reset_index(drop=True).iloc[:10,:]
#���㽻��ָ��ռ��
top10['����ָ��ռ��'] = top10['����ָ��']/top10['����ָ��'].sum()
top10.set_index('������Դ',inplace=True)
top10

#�Ѹ��ѵ����� ���б��
paid = ['��������','ֱͨ��','�Ա���']
ind = np.any([top10.index == i for i in paid],axis=0) #true Ϊ���ѵ�
ind
array([False, False, False, True, False, False, False, True, False, False])
an5 = flow(df5an)

ǰ10������:�ܽ���ָ��:748539;��������ռ��:18.58%;����������������ָ��:139048��
�ɼ��ݶ��Ͱ��ٵ���������Dz���,���ٵ���������С�ܶ�,������Ч���ݶ��������ڰ��١�
4.7.4 �����ṹ-������
df5ke = pd.read_excel(filename4[2])
df5ke.head(10)

# ֻȡ����ָ������ǰʮ����������
df0 = df5ke
top10 = df0.sort_values('����ָ��',ascending=False).reset_index(drop=True).iloc[:10,:]
#���㽻��ָ��ռ��
top10['����ָ��ռ��'] = top10['����ָ��']/top10['����ָ��'].sum()
top10.set_index('������Դ',inplace=True)
top10

#�Ѹ��ѵ����� ���б��
paid = ['��������','ֱͨ��','�Ա���']
ind = np.any([top10.index == i for i in paid],axis=0) #true Ϊ���ѵ�
ind
array([False, False, False, True, False, False, False, True, True, False])
ke5 = flow(df5ke)

ǰ10������:�ܽ���ָ��:1918111;��������ռ��:25.51%;����������������ָ��:489263��
- �Ͱݶ��������ϲ��,�����ظ���ռ�Ƚϸ�
- �ɼ��ݶ��������ṹ���������Ƶ�,Ҫ�����������
5 �������
5.1 �ı��ھ��������
- ʹ�õ���������������,���ı����ݡ�
- �ı����ݵķ���������Ҫ��:��ϴ,����,������������ı���
?�� ��ϴ��������:
???�� �滻����Ӣ���ַ�Ϊ�ո�;
???�� �ִ�(���jieba);
???�� ȥ��ͣ�ô�(�������ͽ�ģ������Ĵ�);
???�� ɸѡ��Ƶ��;��������Ҫ�������ԶԱ�Ч���� - ���ӻ�:һ�㶼�Ǵ���,������Ϲؼ�������ȡ�
- ��ģ:��ģǰ��Ҫ������ת���ĵ��ʾ���(dtm);�мල�Ļ����õ��DZ�Ҷ˹,����ƫ���ȵ��㷨Ҳ����,Ҫע����������;�ල���õ�������ģ��LDA,���������Ⱥ,��з���Ҳ���ԡ�
- ��ϴ������,�����ǿ��ﻯ��ǿ������,������������,��Ҫȥ���ظ����,�Լ���������ij����ֵ�����ۡ�
- �����������ݵõ��Ĵ��ơ�
���濪ʼ��ʽ�����������̡�
os.chdir('..')
os.chdir('./������������')
filename = glob.glob('*.xlsx')
filename
[������.xlsx��, ���¹��ݶ�.xlsx��, �����ֳ��.xlsx��]
df6bai = pd.read_excel(filename[1])
df6bai

bai6 = list(df6bai['����'])
bai6[:5] # ��ȡ5����һ��

�ɼ�,������Ҫһ����������ϴ:����Ӣ���ַ��IJ�Ҫ���ڷִ�ǰ���š���Ų�Ҫ��
bai61 = [re.sub(r'[^a-z\u4E00-\u9Fa5]+',' ',i,
flags=re.I) for i in bai6]#�����ַ� \u4E00-\u9Fa5 flags=re.I �����ִ�Сд
��ϴ��������һ��:
bai61[:5]

����������ȥ��ͣ�ô�(�ٶȵ�ͣ�ôʿ�)�������ڴ�֮ǰ,���ǵ��ȷ�һ�´�,���������õķִʹ�����jieba�ִʡ�������һ��jieba��ʹ��:
jieba.lcut('���Ŀ��˰� ��û�� Сʱ�������� Сǿ��Ȼ��Ծ')
����������:
['����',
'����',
'��',
' ',
'��',
'û��',
' ',
'Сʱ',
'��',
'����',
'��',
' ',
'Сǿ',
'��Ȼ',
'��Ծ']
��������ʽ���зִ�:
# �ȶ�ȡͣ�ô�
stopwords = list(pd.read_csv('E:\Data-analysis-project\�����ı��ھ�\data/�ٶ�ͣ�ôʱ�.txt',
names=['stopwords'])['stopwords']) #ָ������ת��Ϊ�б�
stopwords.extend([' ', '���']) #�ѿո�Ҳȥ�� ���
bai62 = []
for i in bai61:
#��ÿ�����۷���
seg1 = pd.Series(jieba.lcut(i))
ind1 = pd.Series([len(j) for j in seg1])>1 #���ȴ���1�ı���
seg2 = seg1[ind1]
#ȥ��ͣ�ô� isin
ind2 = ~seg2.isin(pd.Series(stopwords))
seg3 = list(seg2[ind2].unique())#ȥ��һ��
if len(seg3)>0:
bai62.append(seg3)
bai62[0] #�õ����Ǵ��б���С�б�
����������:
['�յ�',
'����',
'����',
'Сǿ',
'����',
'����',
'�Ͻ�',
'����',
'����',
'����',
'��',
'��',
'���',
'����',
'����',
'�ɾ�',
'û��',
'����',
'��ȥ',
'����',
'�ӷ�',
'�ܶ�',
'����']
��϶���б���һ���б�:
bai63 = [y for x in bai62 for y in x]
bai63[:5]
[���յ���, �����, ��������, ��Сǿ��, �����ۡ�]
#��Ƶͳ��
baifreq = pd.Series(bai63).value_counts()
baifreq[:10] # ����ǰ10����
����������:
�� 541
��� 409
˫ʮ 145
���� 144
���� 138
Сǿ 114
�յ� 106
�û� 100
��д 100
���� 95
dtype: int64
������һ����������Ҫ������ һ�����ַ��� (�ÿո�ָ��Ĵ�):
bai64 = ' '.join(bai63)
���һ������,����WordCloudģ�����ɴ���:
#��ȡ��Ƭ
mask = imageio.imread(r'E:\Data-analysis-project\�����ı��ھ�\data/leaf.jpg')
#��������ĵĴ���---����
font = r'E:\Data-analysis-project\�����ı��ھ�\data/SimHei.ttf'
wc = WordCloud(background_color='white',mask=mask,
font_path=font).generate(bai64)
plt.figure(figsize=(8,8))
plt.imshow(wc)
plt.axis('off')#��Ҫ������
plt.show()

5.2 �ؼ�����ȡ
���� TF-IDF �㷨�Ĺؼ��ʳ�ȡ:
jieba.analyse.extract_tags(bai64,20,True)
����������:
[('��', 0.29875695025833393),
('˫ʮ', 0.13410500058357974),
('����', 0.08641902343506376),
('ʪ��', 0.08395512199412308),
('��д', 0.08239762548761781),
('����', 0.0823420504295694),
('����', 0.07553937079103677),
('��', 0.07069905010031417),
('û��', 0.06662667991833673),
('�յ�', 0.06542549350413418),
('�û�', 0.06304136086139346),
('����', 0.06195551748124191),
('ʬ��', 0.05744312738244686),
('����', 0.057198916923431896),
('ʪֽ��', 0.05523277943411569),
('����', 0.04893045405589909),
('����', 0.04800798233693402),
('�ڴ�', 0.0452573579284439),
('ϣ��', 0.04377063232686934),
('hellip', 0.04308223365487895)]
5.3 �ܽ�
- ���ܴӴ��ƻ��ǹؼ�������,����ƫ����,û������������
- ������ͣ�ô������Ӻ���,�����ٿ�Ч����
6 ��Ŀ�ܽ�
�������ǿ��������ܽ����һ��:
| �����Ƕ� | ���� |
|---|---|
| DZ������ | 1.���������г����ڿ���������,�����ڳɳ��ڵ�������; 2.����ɱ����г��ݶ�ϴ�(����60%),Լ�ǵڶ�������Һ�Ķ���,�г������ʽӽ�40%,������Ϊ�����Dz�Ʒ��Ŀ,��Ҫ����Ͷ�ʺ��ص��ע; 3.�����г�������¢��,�ṹ������,������Լ���,��û�����Ե����Դ�˾��ѹ���� |
| �г������ | 1.����ɱ����г���,��Ҫ�ص��ע�IJ�Ʒ�����:���������; 2.�����Ʒ: ?�� �����г�������0-50�ļ۸��,����۸�ξ���Ҳ�ܼ���; ?�� 200-250����۸���г��ݶ�ռ10%����,�����Ⱥܵ�,��ֵ���ھ�ĸ��г�; 3.����0-50�۸�εIJ�Ʒ�г���: ?�� 10-20�۸���г�������,�����ȵ�,ֵ�ý�һ������,20-30Ҳ����; ?�� �������ͷ�����è���������Ա�; ?�� �г��ݶ�ߵ��ͺ���ճ���,Ȼ���ͺ�0005�г��ݶ��,�����Ƚϵ�,ֵ�ÿ���; ?�� ��Ʒ��������̬�������ǹ���,Ҳ�DZ������Ͽɵ���̬; ?�� ��������̬Ϊ����,������Ϊ1ʱ,�г��ݶ�߾����ȵ�,ֵ�ÿ����� |
| Ʒ��ֲ�-��Ʒ��� | �ݶ�ֻ��һ���г�,�������в�ͬ�г�,����Ҫ�г���������ɱ����� |
| Ʒ��ֲ�-���ö��� | �ݶ�����Ҫ���������,���������ҳ���֮�����,��; ����֮ǰ�ķ�������������������г��ݶ��;Ӧ�ÿ������г�,����������,Ҳ�����������Ҷ����ص����г��� |
| ��Ʒ�ṹ | �ݶ��ֲ�Ʒ�����ڳ����,ɱ��Ҳ��һ���Ĺ�ģ,�������Dz�Ʒ�Է���,���Խ�һ����չ�����Ʒ����Ϊ���Dz�Ʒ�� ����û�����Ե������г�;�ݶ��Ͱ��ٱȽ�:�ݶ�ɱ�����ϱ���,������һ�������� �����ػ�����չ�����Ʒ,Ȼ��ÿ����Ʒ�ṹ��Զ���(��ţ���,��������,DZ������),û�к�����֧��,������������ôǿ�� |
| �����ṹ | �ݶ��Ͱ��ٵ���������Dz���,�������ٵ���������С�ܶ�; �����غͰݶ��������ϲ��,�����ظ���ռ�Ƚϸ�,�ɼ��ݶ��������ṹ���������Ƶ�,Ҫ����������ơ� |
| ������� | ���ܴӴ��ƻ��ǹؼ�������,����ƫ����,û������������ |
������,������һ����ĿҲ��������,ϣ����ƪ���¶�������������!