аЁУзгІгУЩЬЕъЕФХРШЁ
ашЧѓ
ХРШЁФПБъurl: https://app.mi.com/category/6,ХРШЁЩугАЩуЯёгІгУаХЯЂ,УћГЦ,ЗжРр,ЯъЧщНчУцЕФurlЁЃзюКѓЛЙвЊЪЕЯжЗвГЕФХРШЁ
ЯШгУе§ГЃЕФЗНЗЈХРШЁ,ШЛКѓдйИФаДГЩЖрЯпГЬЕФЗНЗЈ,ЖдБШСНжжЗНЗЈЕФХРШЁЫйЖШЁЃ
вГУцЗжЮі
ЫбЫївЊХРШЁЕФгІгУЕФУћГЦ,ЭЈЙ§гвМќЁЂЭјвГдДТыВщПД,ЗЂЯжвЊЫбЫїЕФФкШнВЛдкЭјвГдДТыжа,ЭЈЙ§NetworkЕФXHRжаВщПДЁЃ

ИДжЦheadersРяЕФurl дкфЏРРЦїжаПЩвдПДЕН,гІгУЕФаХЯЂЪЧвдзжЕфЕФаЮЪНДцЗХдкЭјвГжаЁЃ
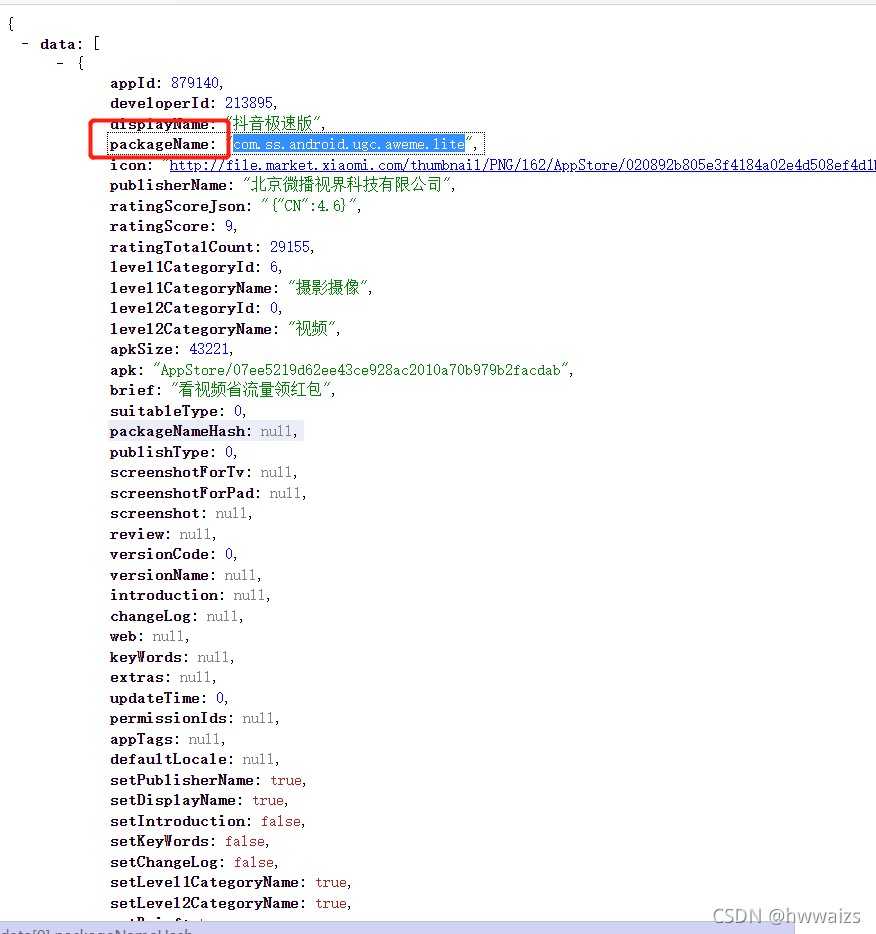
ЕуЛїФГИігІгУ,НјШыИУгІгУЕФЯъЧщвГ,дкЬјзЊЕФurlРяПЩвдЗЂЯжurlРяАќКЌЕФФкШнИњpackageNameРяЕФФкШнвЛжТ

дйЕуЛїМИИігІгУ,ЗЂЯжгІгУЯъЧщРяЕФurl,ЧАУцЖМвЛбљ,Дг"id=",КѓУцЕФФкШнВЛвЛбљЁЃЭЈЙ§ЗжЮі,ЮвУЧХРШЁЕФЪБКђПЩвдЖЏЬЌИќаТЕШКХКѓУцЕФФкШнРДЧаЛЛЕНВЛЭЌгІгУЕФВЛЭЌНчУц,ВЛЭЌгІгУГЬађidЕФжЕЪЧдкЪ§ОнНгПкжаЕФ,ПЩвдДгurlЕФзжЕфжаШЁГігІгУЕФУћГЦ,ЗжРр,гІгУЕФurlЕижЗЁЃ
ДњТыЪЕЯж
КЏЪ§ЗНЪНЪЕЯж
1.КЏЪ§ЪЕЯж
import requests
import csv
import time
def get_url(url):
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/93.0.4577.63 Safari/537.36 Edg/93.0.961.47'
}
res = requests.get(url, headers=headers)
result = res.json()['data']
return result
def parse_url(html):
app_data = []
for app in html:
item = {}
item['name'] = app['displayName']
item['itemize'] = app['level1CategoryName']
item['url'] = 'https://app.mi.com/details?id=' + app['packageName']
app_data.append(item)
return app_data
def save_data(lis_data):
header = ['name', 'itemize', 'url']
with open('xiaomi_data.csv', 'a', encoding='utf-8', newline="") as f:
writ = csv.DictWriter(f, header)
if i == 0:
writ.writeheader()
writ.writerows(lis_data)
if __name__ == '__main__':
global i
for i in range(3):
url = f'https://app.mi.com/categotyAllListApi?page={i}&categoryId=6&pageSize=30'
html = get_url(url)
lis_data = parse_url(html)
save_data(lis_data)
time.sleep(2)
УцЯђЖдЯѓЗНЪНХРШЁЕквЛвГ
2.1 УцЯђЖдЯѓЖСШЁвЛвГ
import requests
import csv
import time
class XiaomoShop():
def __init__(self):
self.url = 'https://app.mi.com/categotyAllListApi?page=0&categoryId=6&pageSize=30'
self.headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/93.0.4577.63 Safari/537.36 Edg/93.0.961.47'
}
def get_url(self):
res = requests.get(self.url, headers=self.headers)
self.html = res.json()['data']
def parse_url(self):
self.app_data = []
for app in self.html:
item = {}
item['name'] = app['displayName']
item['itemize'] = app['level1CategoryName']
item['url'] = 'https://app.mi.com/details?id=' + app['packageName']
self.app_data.append(item)
def save_data(self):
header = ['name', 'itemize', 'url']
with open('xiaomi_data0.csv', 'a', encoding='utf-8', newline="") as f:
writ = csv.DictWriter(f, header)
writ.writeheader()
writ.writerows(self.app_data)
def main(self):
self.get_url()
self.parse_url()
self.save_data()
time.sleep(2)
if __name__ == '__main__':
X = XiaomoShop()
X.main()
УцЯђЖдЯѓЗНЪНЗвГХРШЁ
2.2 УцЯђЖдЯѓЪЕЯжЪЕЯжЗвГ
import requests
import csv
import time
class XiaomoShop():
def __init__(self):
self.url = 'https://app.mi.com/categotyAllListApi?page={}&categoryId=6&pageSize=30'
self.headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/93.0.4577.63 Safari/537.36 Edg/93.0.961.47'
}
def get_url(self, url):
res = requests.get(url, headers=self.headers)
result = res.json()['data']
return result
def parse_url(self, html):
app_data = []
for app in html:
item = {}
item['name'] = app['displayName']
item['itemize'] = app['level1CategoryName']
item['url'] = 'https://app.mi.com/details?id=' + app['packageName']
app_data.append(item)
return app_data
def save_data(self, lis_data):
header = ['name', 'itemize', 'url']
with open('xiaomi_data2.csv', 'a', encoding='utf-8', newline="") as f:
writ = csv.DictWriter(f, header)
if i == 0:
writ.writeheader()
writ.writerows(lis_data)
def main(self):
global i
for i in range(3):
new_url = self.url.format(i)
html = self.get_url(new_url)
lis_data = self.parse_url(html)
self.save_data(lis_data)
# time.sleep(2)
if __name__ == '__main__':
start_time = time.time()
X = XiaomoShop()
X.main()
end_time = time.time()
print('ГЬађдЫааЪБМф:%s' % (end_time - start_time))
ЖрЯпГЬЗНЪНХРШЁ
ИФЮЊЖрЯпГЬЕФЗНЪННјааХРШЁ,ЪзЯШвЊЕМШыЖрЯпГЬ,ЕМШыЖгСа,дкГіЯжзЪдДОКељЕФЮЪЬт,ДДНЈЯпГЬЫј,АбД§ХРШЁЕФurlЖМЗХЕНЖгСажа,КЏЪ§ЪЕЯжЕФЪЧАбurlЗХШыЖгСаЕФВйзї,ВЩгУЖрИіЯпГЬШЅКЏЪ§жаgetГіurl,ЯђЕУЕНЕФurlЗЂЧыЧѓ,ЛёШЁЪ§Он,ДДНЈСЫЯпГЬЕФЪТМўКЏЪ§,етРяжЛга3вГ,ДДНЈ3ИіЯпГЬЖдгІЕФжЛХРШЁСЫ3ДЮ,зюКУаДИіЫРбЛЗ,ШУЯпГЬВЛЖЯЕФШЅХРШЁ,ХРШЁЕУЕНЕФЪ§Он,БЃДцЕНcsvжаЁЃ
import requests
import time
import threading
from queue import Queue
import csv
app_data = []
class XiaomiShop():
def __init__(self):
self.url = 'https://app.mi.com/categotyAllListApi?page={}&categoryId=6&pageSize=30'
# ДДНЈЖгСа
self.q = Queue()
# ДДНЈЯпГЬЫј
self.lock = threading.Lock()
self.app_data = []
# АбФПБъurlЗХЕНЖгСажа
def put_url(self):
for page in range(3):
new_url = self.url.format(page)
self.q.put(new_url) # етРяжЛЪЧДДНЈЖгСа
# ЗЂЦ№ЧыЧѓ,ЛёШЁЯьгІ,НтЮіЪ§Он
# ДДНЈВЂЦєЖЏЖрЯпГЬЕФЪБКђЪЧгУЕФетИіКЏЪ§,ПЩФмГіЯжзЪдДОКељЕФЕиЗНдкетИіКЏЪ§Ря
def parse_url(self):
while True:
# ДДНЈЯпГЬЫј
self.lock.acquire()
if not self.q.empty():
url = self.q.get()
# ШЁГіжЎКѓИњЖгСаЮоЙиСЫ,ОЭвЊНтЫј
self.lock.release()
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/93.0.4577.63 Safari/537.36 Edg/93.0.961.47'
}
html = requests.get(url, headers=headers).json()['data']
for app in html:
item = {}
item['name'] = app['displayName']
item['itemize'] = app['level1CategoryName']
item['url'] = 'https://app.mi.com/details?id=' + app['packageName']
self.app_data.append(item)
header = ['name', 'itemize', 'url']
with open('xiaomi_mian.csv', 'w', encoding='utf-8', newline="")as f:
writ = csv.DictWriter(f, header)
writ.writeheader()
print(self.app_data)
writ.writerows(self.app_data)
else:
self.lock.release() # дкelseДІвВвЊНјааНтЫј,ЗёдђЛсдкЩЯЫјзДЬЌЖТШћ
break
def run(self):
self.put_url()
# ДДНЈ2ИіЖрЯпГЬ,ШчЙћЯпГЬЖрЕФЛА,ПЩвдЗХЕНСаБэРя,ж№ИіШЁГі
t_list = []
for i in range(2):
t = threading.Thread(target=self.parse_url)
t_list.append(t)
t.start()
if __name__ == '__main__':
# ПЊЪМЪТМў
start_time = time.time()
x = XiaomiShop()
x.run()
# НсЪјЪБМф
end_time = time.time()
# ГЬађгУЪБ
print('ГЬађдЫааЪБМф:%s' % (end_time - start_time))
ЭЈЙ§НсЪјЪБМфМѕШЅПЊЪМЪБМфЕУЕНГЬађдЫааЕФЪБМф,БШВЛгУЖрЯпГЬДѓДѓМѕЩйСЫдЫааЪБМф,ЦеЭЈЕФХРШЁДѓИХдк0.69sзѓгв,гУЖрЯпГЬЕФЪБМфЮЊ0.019sЁЃ