������
1. ����������������
? ������,����˼��,��������һ����,���,������������ߵ�����(�����Զ�һЩ��������ж�)��
? ��ͨ���������������������������á�(ע:�������ȿ���������Ҳ�������ع�,�˴���Ҫ���۷���ľ�����)ͼ�й��������,����Ҫ������ѡ������ϲ����������ˡ���ô���ǾͿ���ͨ��������Ա�������ָ��ȥ����ѡ��,��һ��ɸѡ������С��15�������,�ڶ���ͨ���Ա�Ϳ�����ѡ������ϲ����������ˡ�[�����������Ա𱻳�Ϊ��������]

? ͨ�����������,���ǿ��ܻ��������Ҳ̫����,�ⲻ����if�������ж���?����ͻ��ˡ���ʵ��Ȼ,���������ֻ�Ǹ������Ǿ�������ʹ��,����������Ĺ���Ӧ�����ھ������Ĵ����ϡ����ǿ�����ϸ������Щ����,�����Ϊʲô����������?Ϊʲô����15��ͱ��ֵ���ϲ���������һ����?ΪʲôŮ���ͱ��ֵ���ϲ���������һ����?ΪʲôҪ�ȶ��������Խ����ж���,���ж��Ա����Կɲ�������?��ʵ��Щ����ͨ����ǰ�Ծ������Ĺ����������ġ����������ܾ������Ĺ��췽����
2. ����������
2.1 ������----��
? ����������Ҫ������һ���˽⡣���л�ѧ����ʵ��������һ������,����ʾ���������ڲ��Ļ��ҳ̶�,����˵��ʾ���������ȷ���ԵĶ�������Խ��,��ʾ�����ڲ�Խ����,�������Խ��ȷ��,�����������ȷ����Խ��
? ����H(X)��ʾ�¼�X�IJ�ȷ����,��
? P(����Խ��) --> H(X)ֵԽС ����������ȷ������ʺܴ�,��ô���IJ�ȷ����(H(X)�ͺ�С)��
? P(����ԽС) --> H(X)ֵԽ�� ���綬����ȷ������ʺ�С,��ô���IJ�ȷ����(H(X)�ͺܴ�)��
? ����Ϊ�صĹ�ʽ:
��
=
?
��
i
=
1
n
P
i
I
n
(
P
i
)
�� = - \sum\nolimits_{i = 1}^n {{P_i}} In({P_i})
��=?��i=1n?Pi?In(Pi?)
? ���ǿ��ԴӺ��������������ع�ʽ:

��ͼ��1>,2>��Ӧ���ر�ʾ�¼��IJ�ȷ����,��һ���¼������ĸ��ʴ�,�䲻ȷ����H(x)ԽС,��ԽС��
����ΪGiniϵ��Gini��Ĺ�ʽ,���ʾ�ĺ����������ơ�
G
i
n
i
(
p
)
=
��
k
=
1
k
P
k
(
1
?
P
k
)
=
1
?
��
k
=
1
k
P
k
2
?
Gini(p) = \sum\limits_{k = 1}^k {{P_k}(1 - {P_k})} = 1 - \sum\limits_{k = 1}^k {P_k^2} \
Gini(p)=k=1��k?Pk?(1?Pk?)=1?k=1��k?Pk2??
�ٸ����ӽ�һ������һ����:������������������A = [1,2],B = [1,1]
�ȷֱ��������������Ԫ�ص��ء�
A:�� = - [1/2*In(1/2)+1/2*In(1/2)] = 0.693
B:�� = - [1*In(1)+1*In(1)] = 0
ͨ��������Է�����A>��B,��A�Ƚϻ���,��ֱ��������Ҳ���Կ�������A�ȼ���B����,���һ����֤������Ľ��ۡ�
2.2 ���������
? ����,������Ҫ֪�������������Ļ���˼��,����������ȵ�����,�ڵ����Ѹ�ٵĽ��͡��ؽ��͵��ٶ�Խ��,�������Ǿ������õ�һ�Ÿ߶���ľ�������
? �������˼��,���Ǿ�һ��ʵ����˵�����±�Ϊ����outlook,temperature,humidity,
windy���������������Ƿ�����ͳ�Ʊ���(���й���14������,ÿ������4����������)
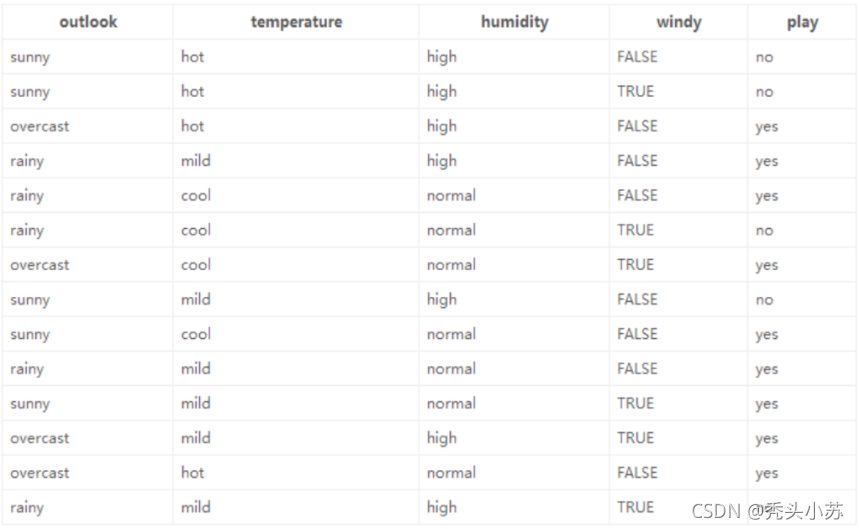
? ��û�и����κ�������Ϣʱ,������ʷ����,���ǵ�֪�µ�һ���д���ĸ���Ϊ9/14,����ĸ���Ϊ5/14,��ʱ����Ϊ:
?
9
14
log
?
2
9
14
?
5
14
log
?
2
5
14
=
0.940
- \frac{9}{{14}}{\log _2}\frac{9}{{14}} - \frac{5}{{14}}{\log _2}\frac{5}{{14}} = 0.940
?149?log2?149??145?log2?145?=0.940
? 0.94�������dz�ʼʱ�̵���ֵ,ǰ��˵�������������Ļ���˼�����ʹ�ڵ����Ѹ�ٵ��½�����ô������4������(outlook, temperature, humidity,windy),ÿ�����Զ����Գ䵱��һ���ڵ�,�����ڵ㡣��ʱ���Ǿ���Ҫ�ֱ�����4�����Գ䵱���ڵ�ʱ����ֵ,Ȼ��ѡ����ֵ�½�����������Ϊ��ǰ�ڵ㡣
? ����,����ѡ���outlook���Կ�ʼ����,�ӱ��п��Կ���,outlook = sunny ����5������(play��ǩ����2��yes , 3��no); outlook = overcast ����4������(play��ǩ��ȫΪyes );outlook = rainy����5������(play��ǩ����3��yes , 2��no);��ʾ��ͼ����:
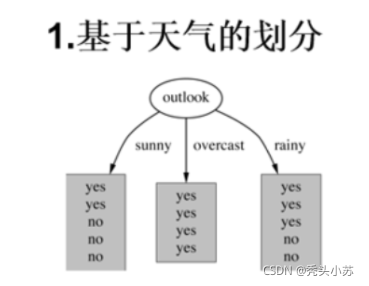
? �����������ֵ(Entropy):
? ��outlook = sunny ʱ,Entropy = -2/5*log(2/5) - 3/5*log(3/5) = 0.971
? ��outlook = overcast ʱ,Entropy = -1*log(1) - 0*log(0) = 0
? ��outlook = rainy ʱ,Entropy = -3/5*log(3/5) - 2/5*log(2/5) = 0.971
?
? ��������ͳ��, outlookȡֵ�ֱ�Ϊsunny,overcast,rainy�ĸ��ʷֱ�Ϊ:5/14 , 4/14 , 5/14 ��������ֵΪ5/14*0.971 + 4/14*0 + 5/14*0.971 = 0.693��
? ����֪��������Ҫ�Ľڵ���Ҫʹ��Ѹ���½���,��ô���Dz��������½��ķ��ȶ���Ϊһ���µIJ���:��Ϣ����gain���������ǾͿ���ͨ���Ƚ���Ϣ����Ĵ�С���ж�ѡ��ʲô�ڵ���Ϊ��ǰ�ڵ㡣��ô��ѡ��outlook����ʱ����Ϣ������dz�ʼ�� - �仯��:gain(outlook) = 0.940 - 0.693 = 0.247��
? ͬ�����ǿ��Եõ��������Ե���Ϣ����:
? gain(temperature) = 0.029 ; gain(humidity) = 0.152 ; gain(windy) = 0.048
? ���Ƿ�������outlook����Ϣ�������,��˴�ʱ��ѡ��outlook��Ϊ��ǰ�ڵ㡣ȷ����outlook��Ϊ���ڵ��,���ǾͿ��Զ�14�����ݽ���һЩ����,Ȼ���ڻ��ֵ��������ٲ�����ͬ�ķ���ѡ��һ������(��ȥoutlook)��Ϊ��λ��ֵĽڵ�,�Դ�����,�Ϳ��Եõ�һ�ž�������
3. C4.5�㷨
? ����ͨ����Ϣ������������ǰ�ڵ�ѡ����㷨��ΪID3�㷨���������㷨�Ǵ���ȱ�ݵ�,���Ǿٸ����� ,���ڽ�ǰ���������һ��ID����,��ͼ:
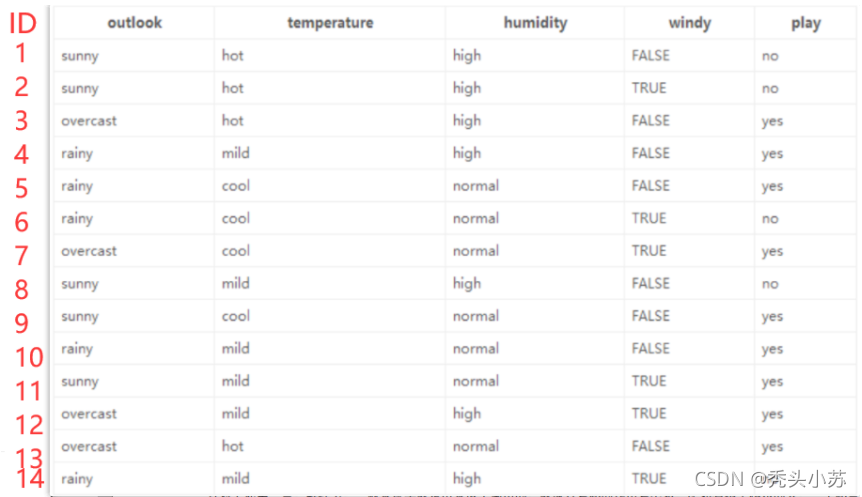
? ���ڼ���ID���Ե���Ϣ�������Ƿ�������Ϣ����Ϊ9.40,��Ϊÿ��ID��play��ǩֻ��һ��,����ȷ����,���ض�Ϊ0����Ȼ��Ϣ�������,�Ƿ����˵����ѡ��ID���������л��������ŵ���?��Ȼ���Dz����ʵ�,��ΪID���Ժ�play��ǩ����ȫû���κι�ϵ�ġ����ʹ����Ϣ�����ID3�㷨����һ��ȱ�ݵġ���������ѡ��Ľ���C4.5�㷨,����ͨ����Ϣ������GainRatio��ʵ�ֵġ���Ϣ�����ʹ�ʽ����:
G
a
i
n
R
a
t
i
o
(
S
,
A
)
=
g
a
i
n
(
S
,
A
)
S
p
l
i
t
I
n
f
o
r
m
a
t
i
o
n
(
S
,
A
)
?
% MathType!MTEF!2!1!+- % feaagKart1ev2aaatCvAUfeBSjuyZL2yd9gzLbvyNv2CaerbuLwBLn % hiov2DGi1BTfMBaeXatLxBI9gBaerbd9wDYLwzYbItLDharqqtubsr % 4rNCHbWexLMBbXgBd9gzLbvyNv2CaeHbl7mZLdGeaGqiVu0Je9sqqr % pepC0xbbL8F4rqqrFfpeea0xe9Lq-Jc9vqaqpepm0xbba9pwe9Q8fs % 0-yqaqpepae9pg0FirpepeKkFr0xfr-xfr-xb9adbaqaaeGaciGaai % aabeqaamaabaabauaakeaacaqGhbGaamyyaiaadMgacaWGUbGaamOu % aiaadggacaWG0bGaamyAaiaad+gacaGGOaGaam4uaiaacYcacaWGbb % Gaaiykaiabg2da9maalaaabaGaam4zaiaadggacaWGPbGaamOBaiaa % cIcacaWGtbGaaiilaiaadgeacaGGPaaabaGaam4uaiaadchacaWGSb % GaamyAaiaadshacaWGjbGaamOBaiaadAgacaWGVbGaamOCaiaad2ga % caWGHbGaamiDaiaadMgacaWGVbGaamOBaiaacIcacaWGtbGaaiilai % aadgeacaGGPaaaaaaa!65EA! {\rm{G}}ainRatio(S,A) = \frac{{gain(S,A)}}{{SplitInformation(S,A)}}\
GainRatio(S,A)=SplitInformation(S,A)gain(S,A)??
? ����SplitInformation(S,A)Ϊ������Ϣ����,�䶨������:
S
p
l
i
t
I
n
f
o
r
m
a
t
i
o
n
(
S
,
A
)
=
?
��
i
=
1
c
�O
S
i
�O
�O
S
�O
log
?
2
�O
S
i
�O
�O
S
�O
?
% MathType!MTEF!2!1!+- % feaagKart1ev2aaatCvAUfeBSjuyZL2yd9gzLbvyNv2CaerbuLwBLn % hiov2DGi1BTfMBaeXatLxBI9gBaerbd9wDYLwzYbItLDharqqtubsr % 4rNCHbWexLMBbXgBd9gzLbvyNv2CaeHbl7mZLdGeaGqiVu0Je9sqqr % pepC0xbbL8F4rqqrFfpeea0xe9Lq-Jc9vqaqpepm0xbba9pwe9Q8fs % 0-yqaqpepae9pg0FirpepeKkFr0xfr-xfr-xb9adbaqaaeGaciGaai % aabeqaamaabaabauaakeaacaWGtbGaamiCaiaadYgacaWGPbGaamiD % aiaadMeacaWGUbGaamOzaiaad+gacaWGYbGaamyBaiaadggacaWG0b % GaamyAaiaad+gacaWGUbGaaiikaiaadofacaGGSaGaamyqaiaacMca % cqGH9aqpcqGHsisldaaeWbqaamaalaaabaGaaiiFaiaadofacaWGPb % GaaiiFaaqaaiaacYhacaWGtbGaaiiFaaaaaSqaaiaadMgacqGH9aqp % caaIXaaabaGaam4yaaqdcqGHris5aOGaciiBaiaac+gacaGGNbWaaS % baaSqaaiaaikdaaeqaaOWaaSaaaeaacaGG8bGaam4uaiaadMgacaGG % 8baabaGaaiiFaiaadofacaGG8baaaaaa!6A9E! SplitInformation(S,A) = - \sum\limits_{i = 1}^c {\frac{{|Si|}}{{|S|}}} {\log _2}\frac{{|Si|}}{{|S|}}\
SplitInformation(S,A)=?i=1��c?�OS�O�OSi�O?log2?�OS�O�OSi�O??
? ���� S1 �� Sc �� c ��ֵ������ A �ָ� S ���γɵ� c �������Ӽ��� ע�������Ϣʵ���Ͼ��� S �������� A �ĸ�ֵ���ء�
? ��ʵ,��Ϣ�������Ϣ�����ʾͺ��ٶȺͼ��ٵĵ��������ơ������������ܲ�����, һ������� 10m/s ���ˡ� �� 10s ��Ϊ 20m/s; ��һ���������� 1m/s�� �� 1s ��Ϊ 2m/s�� ����������ֵ��ô�������ͺܴ���, ���ʹ���ٶ�������(���ٶ�, ������Ϊ 1m/s^2)������, 2 ���˾���һ���ļ��ٶȡ� ���, C4.5 �˷��� ID3 ����Ϣ����ѡ������ʱƫ��ѡ��ȡֵ������ԵIJ��㡣
? ������Ϣ�������������ոյ�ID����,��ȻID���Ե���Ϣ����ܴ�,����Ҫ���Է�����Ϣ��,SplitInformation(S,A)���㹫ʽΪ:
S
p
l
i
t
I
n
f
o
r
m
a
t
i
o
n
(
S
,
A
)
=
?
��
i
=
1
14
�O
1
�O
�O
14
�O
log
?
2
�O
1
�O
�O
14
�O
?
% MathType!MTEF!2!1!+- % feaagKart1ev2aaatCvAUfeBSjuyZL2yd9gzLbvyNv2CaerbuLwBLn % hiov2DGi1BTfMBaeXatLxBI9gBaerbd9wDYLwzYbItLDharqqtubsr % 4rNCHbWexLMBbXgBd9gzLbvyNv2CaeHbl7mZLdGeaGqiVu0Je9sqqr % pepC0xbbL8F4rqqrFfpeea0xe9Lq-Jc9vqaqpepm0xbba9pwe9Q8fs % 0-yqaqpepae9pg0FirpepeKkFr0xfr-xfr-xb9adbaqaaeGaciGaai % aabeqaamaabaabauaakeaacaWGtbGaamiCaiaadYgacaWGPbGaamiD % aiaadMeacaWGUbGaamOzaiaad+gacaWGYbGaamyBaiaadggacaWG0b % GaamyAaiaad+gacaWGUbGaaiikaiaadofacaGGSaGaamyqaiaacMca % cqGH9aqpcqGHsisldaaeWbqaamaalaaabaGaaiiFaiaaigdacaGG8b % aabaGaaiiFaiaaigdacaaI0aGaaiiFaaaaaSqaaiaadMgacqGH9aqp % caaIXaaabaGaaGymaiaaisdaa0GaeyyeIuoakiGacYgacaGGVbGaai % 4zamaaBaaaleaacaaIYaaabeaakmaalaaabaGaaiiFaiaaigdacaGG % 8baabaGaaiiFaiaaigdacaaI0aGaaiiFaaaaaaa!6A5B! SplitInformation(S,A) = - \sum\limits_{i = 1}^{14} {\frac{{|1|}}{{|14|}}} {\log _2}\frac{{|1|}}{{|14|}}\
SplitInformation(S,A)=?i=1��14?�O14�O�O1�O?log2?�O14�O�O1�O??
? ��ʽ�� SplitInformation(S,A)��ֵ�Ƿdz����,������Ϊ��ĸ,��ʹ��Ϣ�����ʱ�ú�С,��ô�Ϳ����ж�ID������Ϊ�ڵ��Ч�����á�
4. ��������֦
? ��������������������,��ͼ:������ͼ��,����ѵ���������ﵽ��Ч������,������ڵ����ݻᱻ��Ϊ��Բ,���������ݻᱻ��Ϊ�ǡ�����ѵ���������?ֻ��˵���ѵ���������֪�����ݻ��ֺ�,���Ƕ�δ֪�����ݻ��ֲ���,����ǹ��������,��ô������ô��Ч��������������,�����Ҫ�Ծ��������м�֦��
? ��������֦��Ҫ�����ַ���,Ԥ��֦�ͺ��֦:
- Ԥ��֦:�ڹ����������Ĺ�����,��ǰֹͣ
- ���֦:�����������ú�,ͨ��һ���ĺ�����,�Ծ��������вü�
? ��������֦��Ҫ�����ַ���,Ԥ��֦�ͺ��֦:
- Ԥ��֦:�ڹ����������Ĺ�����,��ǰֹͣ
- ���֦:�����������ú�,ͨ��һ���ĺ�����,�Ծ��������вü�