����Ŀ¼
0x00 ժҪ
DIEN�ǰ��������Ȥ��������(Deep Interest Evolution Network)����д��
���Ľ�����DIENԴ������˼·����ΪDIEN����DIN�������ݻ�,���Դ����д��ظ���
���IJ��õ��� https://github.com/mouna99/dien �е�ʵ�֡�
0x01 �ļ����
�����ļ���Ҫ����:
- uid_voc.pkl:�û��ֵ�,�û�����Ӧ��id;
- mid_voc.pkl:movie�ֵ�,item��Ӧ��id;
- cat_voc.pkl:�����ֵ�,category��Ӧ��id;
- item-info:item��Ӧ��category��Ϣ;
- reviews-info:review Ԫ����,��ʽΪ:userID,itemID,����,ʱ���,���ڽ��и�����������;
- local_train_splitByUser:ѵ������,һ�и�ʽΪ:label���û�����Ŀ��item�� Ŀ��item�����ʷitem����ʷitem��Ӧ���;
- local_test_splitByUser:��������,��ʽͬѵ������;
������Ҫ����:
- rnn.py:��tensorflow��ԭʼ��rnn������,Ŀ���ǽ�attentionͬrnn���н��
- vecAttGruCell.py: ��GRUԴ�������,��attention��������,���AUGRU�ṹ
- data_iterator.py: ���ݵ�����,�������ݵIJ�������
- utils.py:һЩ��������,��dice�������attention score�����
- model.py:DIENģ���ļ�
- train.py:ģ�͵����,����ѵ�����ݡ�����ģ�ͺͲ�������
0x02 ����ܹ�
���Ȼ���Ҫ��������ժȡ�ܹ�ͼ����˵����

�����Ȥ���������Ϊ����,���µ���������:
- ��Ϊ���в�(Behavior Layer):��Ҫ�����ǽ��û����������Ʒת���ɶ�Ӧ��embedding,���Ұ������ʱ��������,����ԭʼ��id����Ϊ��������ת����Embedding��Ϊ����;
- ��Ȥ��ȡ��(Interest Extractor Layer):��Ҫ������ͨ��ģ���û�����ȤǨ�ƹ���,������Ϊ������ȡ�û���Ȥ����;
- ��Ȥ������(Interest Evolving Layer):��Ҫ������ͨ������Ȥ��ȡ������ϼ���Attention����,ģ���뵱ǰĿ������ص���Ȥ��������,����Ŀ����Ʒ��ص���Ȥ�ݻ����̽��н�ģ;
- ����Ȥ��ʾ��ad��user profile��context��embedding��������ƴ�ӡ����ʹ��MLP�������Ԥ��;
0x03 �������
DIEN�����Ǵ�train.py��ʼ��train.py ���ó�ʼģ������һ����Լ�,Ȼ����� train:
- ��ȡ ѵ������ �� ��������,�������������ݵ�����,�������ݵIJ�������
- ���� model_type ������Ӧ��model
- ����batchѵ��,ÿ1000���������Լ���
��������:
def train(
train_file = "local_train_splitByUser",
test_file = "local_test_splitByUser",
uid_voc = "uid_voc.pkl",
mid_voc = "mid_voc.pkl",
cat_voc = "cat_voc.pkl",
batch_size = 128,
maxlen = 100,
test_iter = 100,
save_iter = 100,
model_type = 'DNN',
seed = 2,
):
with tf.Session(config=tf.ConfigProto(gpu_options=gpu_options)) as sess:
## ѵ������
train_data = DataIterator(train_file, uid_voc, mid_voc, cat_voc, batch_size, maxlen, shuffle_each_epoch=False)
## ��������
test_data = DataIterator(test_file, uid_voc, mid_voc, cat_voc, batch_size, maxlen)
n_uid, n_mid, n_cat = train_data.get_n()
......
elif model_type == 'DIEN':
model = Model_DIN_V2_Gru_Vec_attGru_Neg(n_uid, n_mid, n_cat, EMBEDDING_DIM, HIDDEN_SIZE, ATTENTION_SIZE)
......
sess.run(tf.global_variables_initializer())
sess.run(tf.local_variables_initializer())
iter = 0
lr = 0.001
for itr in range(3):
loss_sum = 0.0
accuracy_sum = 0.
aux_loss_sum = 0.
for src, tgt in train_data:
uids, mids, cats, mid_his, cat_his, mid_mask, target, sl, noclk_mids, noclk_cats = prepare_data(src, tgt, maxlen, return_neg=True)
loss, acc, aux_loss = model.train(sess, [uids, mids, cats, mid_his, cat_his, mid_mask, target, sl, lr, noclk_mids, noclk_cats])
loss_sum += loss
accuracy_sum += acc
aux_loss_sum += aux_loss
iter += 1
if (iter % test_iter) == 0:
eval(sess, test_data, model, best_model_path)
loss_sum = 0.0
accuracy_sum = 0.0
aux_loss_sum = 0.0
if (iter % save_iter) == 0:
model.save(sess, model_path+"--"+str(iter))
lr *= 0.5
0x04 ģ�ͻ���
ģ�͵Ļ����� Model,�乹�캯��__init__��������Ϊ ��Ϊ���в�(Behavior Layer):��Ҫ�����ǽ��û����������Ʒת���ɶ�Ӧ��embedding,���Ұ������ʱ��������,����ԭʼ��id����Ϊ��������ת����Embedding��Ϊ���С�
4.1 ������
����������:
- �� ��Inputs�� scope��,�������� placeholder ����;
- �� ��Embedding_layer�� scope��,����user, item��embedding lookup table,����������ת��Ϊ��Ӧ��embedding;
- �� ���� embedding vector �������,���罫item��id��Ӧ��embedding �Լ� item��Ӧ��cateid��embedding����ƴ��,��ͬ��Ϊitem��embedding;
4.2 ģ�����
����� B �� batch size,T �����г���,H ��hidden size,�����г�ʼ����������:
EMBEDDING_DIM = 18
HIDDEN_SIZE = 18 * 2
ATTENTION_SIZE = 18 * 2
best_auc = 0.0
4.2.1 ��������
�����ǹ���placeholder������
with tf.name_scope('Inputs'):
# shape: [B, T] #�û���Ϊ����(User Behavior)�е� movie id ��ʷ��Ϊ���С�TΪ���г���
self.mid_his_batch_ph = tf.placeholder(tf.int32, [None, None], name='mid_his_batch_ph')
# shape: [B, T] #�û���Ϊ����(User Behavior)�е� category id ��ʷ��Ϊ���С�TΪ���г���
self.cat_his_batch_ph = tf.placeholder(tf.int32, [None, None], name='cat_his_batch_ph')
# shape: [B], user id ���� (B:batch size)
self.uid_batch_ph = tf.placeholder(tf.int32, [None, ], name='uid_batch_ph')
# shape: [B], movie id ���� (B:batch size)
self.mid_batch_ph = tf.placeholder(tf.int32, [None, ], name='mid_batch_ph')
# shape: [B], category id ���� (B:batch size)
self.cat_batch_ph = tf.placeholder(tf.int32, [None, ], name='cat_batch_ph')
self.mask = tf.placeholder(tf.float32, [None, None], name='mask')
# shape: [B]; sl:sequence length,User Behavior�����е���ʵ���г���(?)
self.seq_len_ph = tf.placeholder(tf.int32, [None], name='seq_len_ph')
# shape: [B, T], y: Ŀ��ڵ��Ӧ�� label ����, ��������Ӧ 1, ��������Ӧ 0
self.target_ph = tf.placeholder(tf.float32, [None, None], name='target_ph')
# ѧϰ����
self.lr = tf.placeholder(tf.float64, [])
self.use_negsampling =use_negsampling
if use_negsampling:
self.noclk_mid_batch_ph = tf.placeholder(tf.int32, [None, None, None], name='noclk_mid_batch_ph') #generate 3 item IDs from negative sampling.
self.noclk_cat_batch_ph = tf.placeholder(tf.int32, [None, None, None], name='noclk_cat_batch_ph')
�������shape���Բμ���������ʱ����
self = {Model_DIN_V2_Gru_Vec_attGru_Neg}
cat_batch_ph = {Tensor} Tensor("Inputs/cat_batch_ph:0", shape=(?,), dtype=int32)
uid_batch_ph = {Tensor} Tensor("Inputs/uid_batch_ph:0", shape=(?,), dtype=int32)
mid_batch_ph = {Tensor} Tensor("Inputs/mid_batch_ph:0", shape=(?,), dtype=int32)
cat_his_batch_ph = {Tensor} Tensor("Inputs/cat_his_batch_ph:0", shape=(?, ?), dtype=int32)
mid_his_batch_ph = {Tensor} Tensor("Inputs/mid_his_batch_ph:0", shape=(?, ?), dtype=int32)
lr = {Tensor} Tensor("Inputs/Placeholder:0", shape=(), dtype=float64)
mask = {Tensor} Tensor("Inputs/mask:0", shape=(?, ?), dtype=float32)
seq_len_ph = {Tensor} Tensor("Inputs/seq_len_ph:0", shape=(?,), dtype=int32)
target_ph = {Tensor} Tensor("Inputs/target_ph:0", shape=(?, ?), dtype=float32)
noclk_cat_batch_ph = {Tensor} Tensor("Inputs/noclk_cat_batch_ph:0", shape=(?, ?, ?), dtype=int32)
noclk_mid_batch_ph = {Tensor} Tensor("Inputs/noclk_mid_batch_ph:0", shape=(?, ?, ?), dtype=int32)
use_negsampling = {bool} True
4.2.2 ����embedding
Ȼ���ǹ���user, item��embedding lookup table,����������ת��Ϊ��Ӧ��embedding,���ǰ�ϡ������ת��Ϊ�������������� embedding ���ԭ���ʹ������,��ϵ�л���ר�Ľ��⡣
������ U ��user_id��hash bucket size,I ��item_id��hash bucket size,C ��cat_id��hash bucket size��
ע�� self.mid_his_batch_ph�����ı��� �����û�����ʷ��Ϊ����, ��СΪ [B, T],�����ڽ��� embedding_lookup ʱ,�����СΪ [B, T, H/2];
# Embedding layer
with tf.name_scope('Embedding_layer'):
# shape: [U, H/2], user_id��embedding weight. U��user_id��hash bucket size,��user count
self.uid_embeddings_var = tf.get_variable("uid_embedding_var", [n_uid, EMBEDDING_DIM])
# ��uid embedding weight ��ȡ�� uid embedding vector
self.uid_batch_embedded = tf.nn.embedding_lookup(self.uid_embeddings_var, self.uid_batch_ph)
# shape: [I, H/2], item_id��embedding weight. I��item_id��hash bucket size,��movie count
self.mid_embeddings_var = tf.get_variable("mid_embedding_var", [n_mid, EMBEDDING_DIM])
# ��mid embedding weight ��ȡ�� uid embedding vector
self.mid_batch_embedded = tf.nn.embedding_lookup(self.mid_embeddings_var, self.mid_batch_ph)
# ��mid embedding weight ��ȡ�� mid history embedding vector,��������
# ע�� self.mid_his_batch_ph�����ı��� �����û�����ʷ��Ϊ����, ��СΪ [B, T],�����ڽ��� embedding_lookup ʱ,�����СΪ [B, T, H/2];
self.mid_his_batch_embedded = tf.nn.embedding_lookup(self.mid_embeddings_var, self.mid_his_batch_ph)
# ��mid embedding weight ��ȡ�� mid history embedding vector,�Ǹ�����
if self.use_negsampling:
self.noclk_mid_his_batch_embedded = tf.nn.embedding_lookup(self.mid_embeddings_var, self.noclk_mid_batch_ph)
# shape: [C, H/2], cate_id��embedding weight. C��cat_id��hash bucket size
self.cat_embeddings_var = tf.get_variable("cat_embedding_var", [n_cat, EMBEDDING_DIM])
# �� cid embedding weight ��ȡ�� cid history embedding vector,��������
self.cat_batch_embedded = tf.nn.embedding_lookup(self.cat_embeddings_var, self.cat_batch_ph)
# �� cid embedding weight ��ȡ�� cid embedding vector,��������
self.cat_his_batch_embedded = tf.nn.embedding_lookup(self.cat_embeddings_var, self.cat_his_batch_ph)
# �� cid embedding weight ��ȡ�� cid history embedding vector,�Ǹ�����
if self.use_negsampling:
self.noclk_cat_his_batch_embedded = tf.nn.embedding_lookup(self.cat_embeddings_var, self.noclk_cat_batch_ph)
�������shape���Բμ���������ʱ����
self = {Model_DIN_V2_Gru_Vec_attGru_Neg}
cat_embeddings_var = {Variable} <tf.Variable 'cat_embedding_var:0' shape=(1601, 18) dtype=float32_ref>
uid_embeddings_var = {Variable} <tf.Variable 'uid_embedding_var:0' shape=(543060, 18) dtype=float32_ref>
mid_embeddings_var = {Variable} <tf.Variable 'mid_embedding_var:0' shape=(367983, 18) dtype=float32_ref>
cat_batch_embedded = {Tensor} Tensor("Embedding_layer/embedding_lookup_4:0", shape=(?, 18), dtype=float32)
mid_batch_embedded = {Tensor} Tensor("Embedding_layer/embedding_lookup_1:0", shape=(?, 18), dtype=float32)
uid_batch_embedded = {Tensor} Tensor("Embedding_layer/embedding_lookup:0", shape=(?, 18), dtype=float32)
cat_his_batch_embedded = {Tensor} Tensor("Embedding_layer/embedding_lookup_5:0", shape=(?, ?, 18), dtype=float32)
mid_his_batch_embedded = {Tensor} Tensor("Embedding_layer/embedding_lookup_2:0", shape=(?, ?, 18), dtype=float32)
noclk_cat_his_batch_embedded = {Tensor} Tensor("Embedding_layer/embedding_lookup_6:0", shape=(?, ?, ?, 18), dtype=float32)
noclk_mid_his_batch_embedded = {Tensor} Tensor("Embedding_layer/embedding_lookup_3:0", shape=(?, ?, ?, 18), dtype=float32)
4.2.3 ƴ��embedding
�ⲿ���ǰ� ���� embedding vector �������,���罫 item��id��Ӧ��embedding �Լ� item��Ӧ��cateid��embedding ����ƴ��,��ͬ��Ϊitem��embedding;
����shape��˵��:
- ע����һ����,self.mid_his_batch_ph�����ı��� �����û�����ʷ��Ϊ����, ��СΪ [B, T],�����ڽ��� embedding_lookup ʱ,�����СΪ [B, T, H/2]��
- ���ォ Goods �� Cate �� embedding ���� concat, �õ� [B, T, H] ��С. ע� tf.concat �е� axis ����ֵΪ 2��
��������˵��:
��һ���� self.item_eb = tf.concat([self.mid_batch_embedded, self.cat_batch_embedded], 1) ����ȡһ�� Batch ��Ŀ��ڵ��Ӧ�� embedding, ������ i_emb ��, ������Ʒ (Goods) ����Ŀ (Cate) embedding ���� concatenation����Ӧ�˼ܹ�ͼ��:
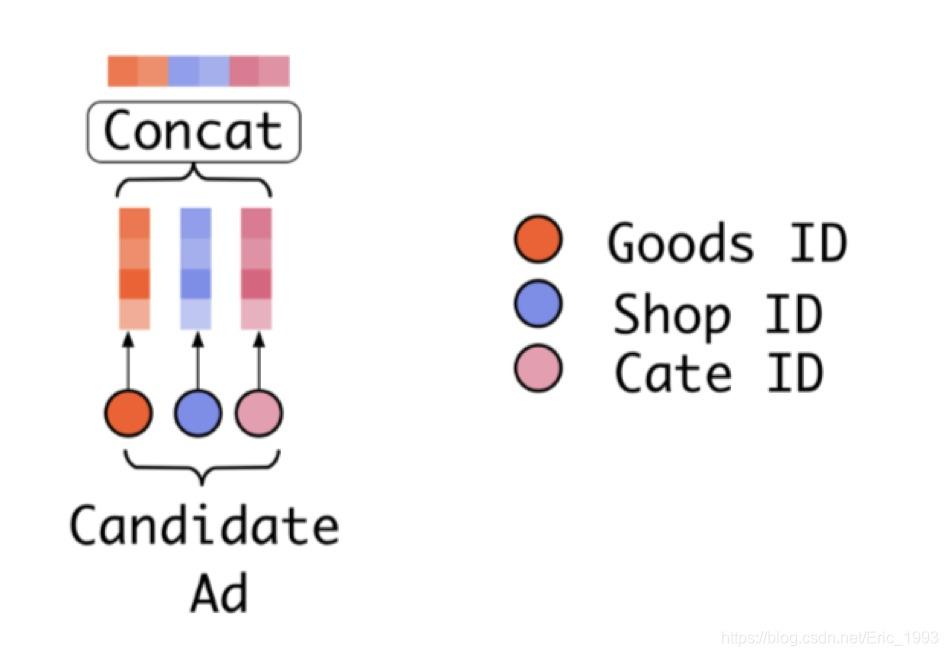
�ڶ����� self.item_his_eb = tf.concat([self.mid_his_batch_embedded, self.cat_his_batch_embedded], 2) ������ �� ������ʷ���� ���д���, ��������ʷ�������û�����ʷ��Ϊ����, ��СΪ [B, T],�����ڽ��� embedding_lookup ʱ, �����СΪ [B, T, H/2]��֮�� Goods �� Cate �� embedding ���� concat, �õ� [B, T, H] ��С. ע� tf.concat �е� axis ����ֵΪ 2����Ӧ�˼ܹ�ͼ��:

�����������:
# ��������embeddingƴ��,����������item��cate������Ŀ��ڵ��Ӧ����Ʒ embedding ����Ŀ embedding ���� concatenation
self.item_eb = tf.concat([self.mid_batch_embedded, self.cat_batch_embedded], 1)
# �� Goods �� Cate �� embedding ���� concat, �õ� [B, T, H] ��С. ע� tf.concat �е� axis ����ֵΪ 2
self.item_his_eb = tf.concat([self.mid_his_batch_embedded, self.cat_his_batch_embedded], 2)
self.item_his_eb_sum = tf.reduce_sum(self.item_his_eb, 1)
# ��������embeddingƴ��,����������item��cate������Ŀ��ڵ��Ӧ����Ʒ embedding ����Ŀ embedding ���� concatenation
if self.use_negsampling:
# 0 means only using the first negative item ID. 3 item IDs are inputed in the line 24.
self.noclk_item_his_eb = tf.concat(
[self.noclk_mid_his_batch_embedded[:, :, 0, :], self.noclk_cat_his_batch_embedded[:, :, 0, :]], -1)
# cat embedding 18 concate item embedding 18.
self.noclk_item_his_eb = tf.reshape(self.noclk_item_his_eb,
[-1, tf.shape(self.noclk_mid_his_batch_embedded)[1], 36])
self.noclk_his_eb = tf.concat([self.noclk_mid_his_batch_embedded, self.noclk_cat_his_batch_embedded], -1)
self.noclk_his_eb_sum_1 = tf.reduce_sum(self.noclk_his_eb, 2)
self.noclk_his_eb_sum = tf.reduce_sum(self.noclk_his_eb_sum_1, 1)
�������shape���Բμ���������ʱ����
self = {Model_DIN_V2_Gru_Vec_attGru_Neg}
item_eb = {Tensor} Tensor("concat:0", shape=(?, 36), dtype=float32)
item_his_eb = {Tensor} Tensor("concat_1:0", shape=(?, ?, 36), dtype=float32)
item_his_eb_sum = {Tensor} Tensor("Sum:0", shape=(?, 36), dtype=float32)
noclk_item_his_eb = {Tensor} Tensor("Reshape:0", shape=(?, ?, 36), dtype=float32)
noclk_his_eb = {Tensor} Tensor("concat_3:0", shape=(?, ?, ?, 36), dtype=float32)
noclk_his_eb_sum = {Tensor} Tensor("Sum_2:0", shape=(?, 36), dtype=float32)
noclk_his_eb_sum_1 = {Tensor} Tensor("Sum_1:0", shape=(?, ?, 36), dtype=float32)
0x05 Model_DIN_V2_Gru_Vec_attGru_Neg
Model_DIN_V2_Gru_Vec_attGru_Neg �� DIEN ��Ӧ��ģ��,�û���ʷ�϶���һ��ʱ������,����ι��RNN,�����һ��״̬������Ϊ������������ʷ��Ϣ�����,������һ��˫���GRU����ģ�û���Ȥ��
Model_DIN_V2_Gru_Vec_attGru_Neg ��__init__�������������˫��GRU,���������:
- ��һ�� ��rnn_1�� ��Ӧ�ܹ�ͼ�л�ɫ����,����Ȥ��ȡ��(Interest Extractor Layer)��
- �ڶ��� ��Attention_layer_1�� ��Ӧ�ܹ�ͼ�еĺ�ɫ���ֵ���Ȥ������(Interest Evolving Layer),��Ҫ����� AUGRU��
5.1 ��һ�� ��rnn_1��
��һ���Ӧ�ܹ�ͼ�л�ɫ����,����Ȥ��ȡ��(Interest Extractor Layer),��Ҫ����� GRU��
��Ҫ������ͨ��ģ���û�����ȤǨ�ƹ���,������Ϊ������ȡ�û���Ȥ���С������û���Ϊ��ʷ��item embedding���뵽dynamic rnn(��һ��GRU)��,ͬʱ���㸨��loss,����ľ����û���ʱ�̵���Ȥ��
# RNN layer(-s)
with tf.name_scope('rnn_1'):
rnn_outputs, _ = dynamic_rnn(GRUCell(HIDDEN_SIZE), inputs=self.item_his_eb,
sequence_length=self.seq_len_ph, dtype=tf.float32,
scope="gru1")
aux_loss_1 = self.auxiliary_loss(rnn_outputs[:, :-1, :], self.item_his_eb[:, 1:, :],
self.noclk_item_his_eb[:, 1:, :],
self.mask[:, 1:], stag="gru")
self.aux_loss = aux_loss_1
5.1.1 GRU
GRU����,�������ǻ����Ľ���RNN��
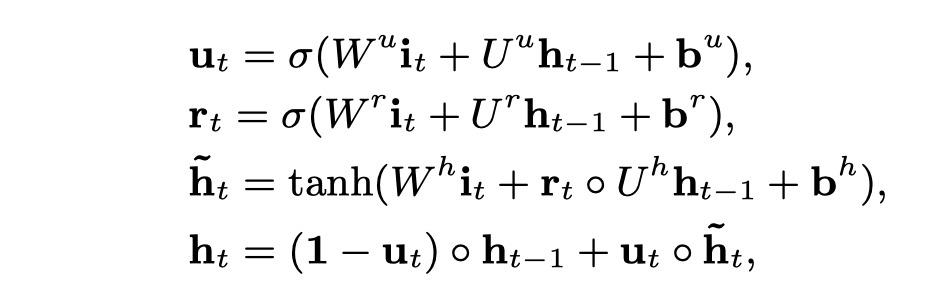
5.1.2 ������ʧ
����loss�ļ�����ʵ��һ��������ģ��,��Ӧ������:
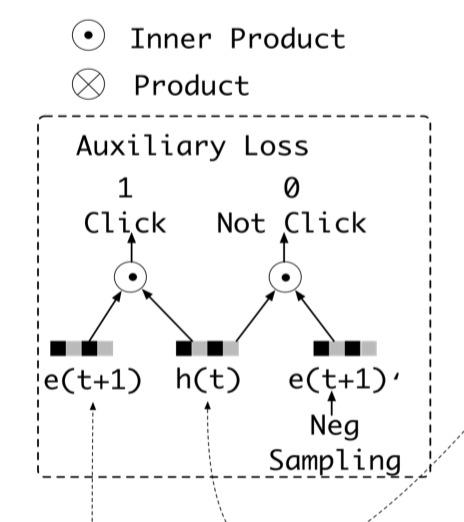
��������,�������� t ʱ�̵���Ϊ b(t+1) ��Ϊ�ලȥѧϰ���������� ht�����������ֱ�������û� ���/δ��� �ĵ� t ����Ʒembedding������
- ������ʵ����һ����Ϊ��Ϊ������;
- ������ѡ����Ǵ��û�δ����������Ʒ�������ȡ,���Ǵ���չʾ���û����û�û�е������Ʒ�������ȡ;
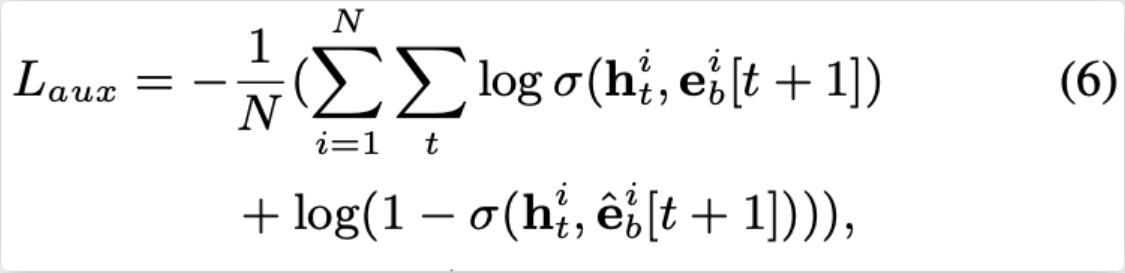
�������õ��� tf.concat([h_states, click_seq], -1),����-1����˼�ǵ�����һά������,����䡣
���� (3,2,4) + (3,2,4) ������� -1 ����,��shape���һά����,��� (3,2,8),�����Ͱ�����tensor�ϲ������ˡ�
�����������:
def auxiliary_loss(self, h_states, click_seq, noclick_seq, mask, stag = None):
mask = tf.cast(mask, tf.float32)
# ������һά��concat,�����
click_input_ = tf.concat([h_states, click_seq], -1)
# ������һά��concat,�����
noclick_input_ = tf.concat([h_states, noclick_seq], -1)
# ��ȡ���������һ��y_hat
click_prop_ = self.auxiliary_net(click_input_, stag = stag)[:, :, 0]
# ��ȡ���������һ��y_hat
noclick_prop_ = self.auxiliary_net(noclick_input_, stag = stag)[:, :, 0]
# ������ʧ,����mask����ʵ��ʷ��Ϊ
click_loss_ = - tf.reshape(tf.log(click_prop_), [-1, tf.shape(click_seq)[1]]) * mask
noclick_loss_ = - tf.reshape(tf.log(1.0 - noclick_prop_), [-1, tf.shape(noclick_seq)[1]]) * mask
loss_ = tf.reduce_mean(click_loss_ + noclick_loss_)
return loss_
def auxiliary_net(self, in_, stag='auxiliary_net'):
bn1 = tf.layers.batch_normalization(inputs=in_, name='bn1' + stag, reuse=tf.AUTO_REUSE)
dnn1 = tf.layers.dense(bn1, 100, activation=None, name='f1' + stag, reuse=tf.AUTO_REUSE)
dnn1 = tf.nn.sigmoid(dnn1)
dnn2 = tf.layers.dense(dnn1, 50, activation=None, name='f2' + stag, reuse=tf.AUTO_REUSE)
dnn2 = tf.nn.sigmoid(dnn2)
dnn3 = tf.layers.dense(dnn2, 2, activation=None, name='f3' + stag, reuse=tf.AUTO_REUSE)
y_hat = tf.nn.softmax(dnn3) + 0.00000001
return y_hat
5.1.3 mask������
����mask������,������ Transformer ��˵һ��:
mask ��ʾ����,����ijЩֵ�����ڸ�,ʹ���ڲ�������ʱ������Ч����Transformer ģ�������漰���� mask,�ֱ��� padding mask �� sequence mask������,padding mask �����е� scaled dot-product attention ���涼��Ҫ�õ�,�� sequence mask ֻ���� decoder �� self-attention �����õ���
Padding Mask
ʲô�� padding mask ��?��Ϊÿ�������������г����Dz�һ����Ҳ����˵,����Ҫ���������н��ж��롣������˵,���Ǹ��ڽ϶̵����к������ 0������������������̫��,���ǽ�ȡ��ߵ�����,�Ѷ����ֱ����������Ϊ��Щ����λ��,��ʵ��ûʲô�����,����attention���Ʋ�Ӧ�ð�ע����������Щλ����,��Ҫ����һЩ������
�����������,����Щλ�õ�ֵ����һ���dz���ĸ���(������),�����Ļ�,���� softmax,��Щλ�õĸ��ʾͻ�ӽ�0!�����ǵ� padding mask ʵ������һ������,ÿ��ֵ����һ��Boolean,ֵΪ false �ĵط���������Ҫ���д����ĵط���
Sequence mask
sequence mask ��Ϊ��ʹ�� decoder ���ܿ���δ������Ϣ��Ҳ���Ƕ���һ������,�� time_step Ϊ t ��ʱ��,���ǵĽ������Ӧ��ֻ�������� t ʱ��֮ǰ�����,���������� t ֮�����������������Ҫ��һ���취,�� t ֮�����Ϣ������������
��ô������ô����?Ҳ�ܼ�:����һ�������Ǿ���,�����ǵ�ֵȫΪ0�����������������ÿһ��������,�Ϳ��Դﵽ���ǵ�Ŀ�ġ�
���� decoder �� self-attention,����ʹ�õ��� scaled dot-product attention,ͬʱ��Ҫpadding mask �� sequence mask ��Ϊ attn_mask,����ʵ�־�������mask�����Ϊattn_mask��
�������,attn_mask һ�ɵ��� padding mask��
DIN����ʹ�õ���padding mask��
5.2 �ڶ��� ��Attention_layer_1��
�ڶ��� ��Attention_layer_1�� ��Ӧ�ܹ�ͼ�еĺ�ɫ���ֵ���Ȥ������(Interest Evolving Layer),��Ҫ����� AUGRU��
5.2.1 Attention����
Attention������ :��Source�еĹ���Ԫ�����������һϵ�е�< Key,Value >���ݶԹ���,��ʱ����Target�е�ij��Ԫ��Query,ͨ������Query����Key�������Ի��������,�õ�ÿ��Key��ӦValue��Ȩ��ϵ��,Ȼ���Value���м�Ȩ���,���õ������յ�Attention��ֵ�����Ա�����Attention�����Ƕ�Source��Ԫ�ص�Valueֵ���м�Ȩ���,��Query��Key���������ӦValue��Ȩ��ϵ���������Խ��䱾��˼���дΪ���¹�ʽ:
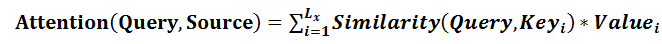
��Ȼ,�Ӹ���������,��Attention��Ȼ����Ϊ�Ӵ�����Ϣ����ѡ���ɸѡ��������Ҫ��Ϣ���۽�����Щ��Ҫ��Ϣ��,���Դ���Ҫ����Ϣ,����˼·��Ȼ�������۽��Ĺ���������Ȩ��ϵ���ļ�����,Ȩ��Խ��Խ�۽������Ӧ��Valueֵ��,��Ȩ�ش�������Ϣ����Ҫ��,��Value�����Ӧ����Ϣ��
����һ��������:Ҳ���Խ�Attention���ƿ���һ����Ѱַ(Soft Addressing):Source���Կ����洢���ڴ洢������,Ԫ���ɵ�ַKey��ֵValue���,��ǰ�и�Key=Query�IJ�ѯ,Ŀ����ȡ���洢���ж�Ӧ��Valueֵ,��Attention��ֵ��ͨ��Query�ʹ洢����Ԫ��Key�ĵ�ַ���������ԱȽ���Ѱַ,֮����˵����Ѱַ,ָ�IJ���һ��Ѱַֻ�Ӵ洢���������ҳ�һ������,���ǿ��ܴ�ÿ��Key��ַ����ȡ������,ȡ�����ݵ���Ҫ�Ը���Query��Key��������������,֮���Value���м�Ȩ���,�����Ϳ���ȡ�����յ�Valueֵ,Ҳ��Attentionֵ�����Բ����о���Ա��Attention���ƿ�����Ѱַ��һ������,��Ҳ�Ƿdz��е����ġ�
����Attention���Ƶľ���������,�����Ŀǰ������������г���Ļ�,���Խ������Ϊ��������:
- ��һ�������Ǹ���Query��Key����Ȩ��ϵ��;
- �ڶ������̸���Ȩ��ϵ����Value���м�Ȩ��͡�
����һ�������ֿ���ϸ��Ϊ������:
- ��һ��С�θ���Query��Key�������ߵ������Ի��������;
- �ڶ���С�ζԵ�һ�ε�ԭʼ��ֵ���й�һ������;
����,���Խ�Attention�ļ�����̳���Ϊ��ͼչʾ�������Ρ�
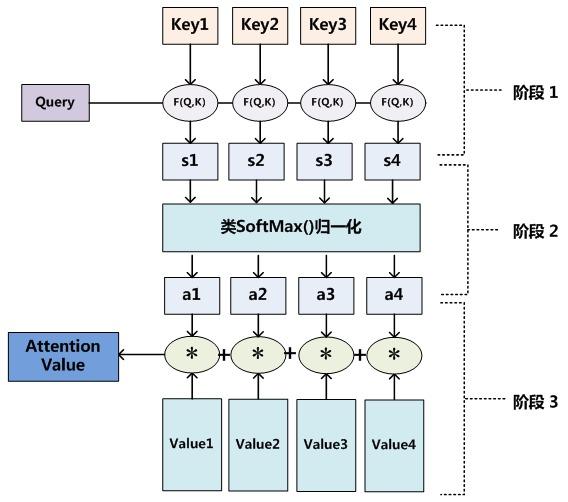
�ڵ�һ����,�������벻ͬ�ĺ����ͼ������,����Query��ij��Keyi,�������ߵ������Ի�������ԡ�����ķ�������:�����ߵ���������������ߵ�����Cosine�����Ի���ͨ����������������������ֵ,�����·�ʽ:

��һ�β����ķ�ֵ���ݾ�������ķ�����ͬ����ֵȡֵ��ΧҲ��һ����
�ڶ�����������SoftMax�ļ��㷽ʽ�Ե�һ�εĵ÷ֽ�����ֵת��,һ������Խ��й�һ��,��ԭʼ�����ֵ����������Ԫ��Ȩ��֮��Ϊ1�ĸ��ʷֲ�;��һ����Ҳ����ͨ��SoftMax�����ڻ��Ƹ���ͻ����ҪԪ�ص�Ȩ�ء���һ��������¹�ʽ����:
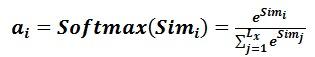
�ڶ��εļ�����ai��ΪValuei��Ӧ��Ȩ��ϵ��,Ȼ����м�Ȩ��ͼ��ɵõ�Attention��ֵ:

ͨ�����������εļ���,����������Query��Attention��ֵ,Ŀǰ������������ע�������Ƽ��㷽�����������������γ��������̡�
5.2.2 Attention layer
DIEN ��,��Attention_layer_1�� ���������:ͨ������Ȥ��ȡ������ϼ���Attention����,ģ���뵱ǰĿ������ص���Ȥ��������,����Ŀ����Ʒ��ص���Ȥ�ݻ����̽��н�ģ��������һ������,ι���ڶ���GRU,����attention score(���ڵ�һ�������������ѡ���ϼ���ó�)�����Ƶڶ����GRU��update gate��
����������Ҫ����attention��score,�����Ὣ����ΪGRU��һ�������롣
�˴���Ӧ������
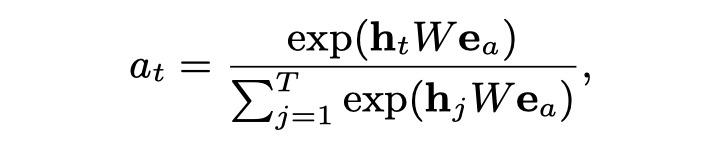
��������:
# Attention layer
with tf.name_scope('Attention_layer_1'):
att_outputs, alphas = din_fcn_attention(self.item_eb, rnn_outputs, ATTENTION_SIZE, self.mask,
softmax_stag=1, stag='1_1', mode='LIST', return_alphas=True)
���뾭�����¼�������õ��û�����Ȥ�ֲ�,��������Ϊ,һ��query������,�ȸ��ݴ�query��һϵ�к�ѡ���key(fact) �������ƶ�,Ȼ��������ƶȼ����ѡ��ľ���value:
-
���time_major,������ת��:(T,B,D) => (B,T,D);
-
ת��mask��
- ʹ�� tf.ones_like(mask) ����һ����maskά��һ��,Ԫ�ض��� 1 ������;
- ʹ�� tf.equal ��mask�� int ����ת�� bool ���͡�tf.equal�������ж����������Ƿ����,�����True,���Ⱦ���False;
-
ת��queryά��,��query��Ϊ�� facts ͬ������״B * T * H;���� T ����ÿ������ѵ�����ݲ�ͬ����ͬ,����ijһ���û���ijһ��ʱ�����г�����5,��һ��ʱ��������15;
- query��[B, H],ת���� queries ά��Ϊ(B, T, H)��Ϊ����pos_item���û���Ϊ������ÿ��Ԫ�ؼ���Ȩ�ء�����������
tf.tile(query, [1, tf.shape(facts)[1]])��tf.shape(keys)[1] ������� T,query��[B, H],���� tile,���ǰѵ�һά���� T չ��,�õ�[B, T * H] ; - �� queries ���� reshape ,ת���ɺ� facts ��ͬ�Ĵ�С: [B, T, H];
- query��[B, H],ת���� queries ά��Ϊ(B, T, H)��Ϊ����pos_item���û���Ϊ������ÿ��Ԫ�ؼ���Ȩ�ء�����������
-
��MLP֮ǰ����һЩ������Ϊitem�ͺ�ѡitem֮���ϵ�IJ���:�Ӽ��˳��ȡ�Ȼ��õ���Local Activation Unit �����롣�� ��ѡ��� queries ��Ӧ�� emb,�û���ʷ��Ϊ���� facts ��Ӧ�� embed,�ټ�������֮��Ľ�������, ���� concat ��Ľ��;
-
attention����,Ŀ���Ǽ���query��key����س̶ȡ�ͨ������������õ�queries��facts ��ÿ��key��Ȩ��,���DNN ���������ڵ�Ϊ 1;
- ���һ�� d_layer_3_all �� shape Ϊ [B, T, 1];
- Ȼ�� reshape Ϊ [B, 1, T], axis=2 ��һά��ʾ T ���û���Ϊ���зֱ��Ӧ��Ȩ�ز���;
- attention�����, [B, 1, T];
-
�õ�����ʵ�����score;
- ʹ��
key_masks = tf.expand_dims(mask, 1)��mask��չά��,�� [B, T] ��չ�� [B, 1, T]; - ʹ�� tf.ones_like(scores) ����һ����scoresά��һ��,Ԫ�ض��� 1 ������;
- padding��mask��һ����С�ĸ���,����������� softmax ʱ, e^{x} �����Լ���� 0;
- ���� [B, 1, T] padding������Ϊ�˺�����padding�������Ӱ��,����������tf.where��padding������(ÿ�����������п�ȱ����Ʒ)Ȩ����Ϊ��Сֵ(-2 ** 32 + 1),������0;
- ����
tf.where(key_masks, scores, paddings)���õ������������score;
- ʹ��
-
Scale �� attention�ı�����,����scaled��������softmax�õ����յ�Ȩ�ء����Ǵ�����û�����ⲿ��,ע������;
-
����softmax���б���,�õ���һ�����Ȩ��;
-
�����Ѿ��õ�����ȷ��Ȩ�� scores �Լ��û���ʷ��Ϊ���� facts,����ͨ��weighted sum�õ������û�����Ȥ����;
-
����� SUM mode,����о�����˵õ��û�����Ȥ����;������scores �Ĵ�СΪ [B, 1, T], ��ʾÿ����ʷ��Ϊ��Ȩ��,facts Ϊ��ʷ��Ϊ����, ��СΪ [B, T, H],�����þ���˷���, �õ��Ľ�� output ���� [B, 1, H]��
-
���� ����
���������
��
- ���Ȱ� scores ����reshape,�� [B, 1, H] �仯�� Batch * Time;
- ������expand_dims����scores���������һά;
- Ȼ����й������,[B, T, H] x [B, T, 1] = [B, T, H];
- ��� reshape �� Batch * Time * Hidden Size;
-
�����������:
def din_fcn_attention(query, facts, attention_size, mask, stag='null', mode='SUM', softmax_stag=1, time_major=False, return_alphas=False, forCnn=False):
'''
query :��ѡ���,shape: [B, H], ��i_emb;
facts :�û���ʷ��Ϊ,shape: [B, T, H], ��h_emb,T��padding��ij���,ÿ����H��emb����һ��item;
mask : Batch��ÿ����Ϊ����ʵ����,shape: [B, H];
'''
if isinstance(facts, tuple):
# In case of Bi-RNN, concatenate the forward and the backward RNN outputs.
facts = tf.concat(facts, 2)
if len(facts.get_shape().as_list()) == 2:
facts = tf.expand_dims(facts, 1)
if time_major:
# (T,B,D) => (B,T,D)
facts = tf.array_ops.transpose(facts, [1, 0, 2])
# Trainable parameters
mask = tf.equal(mask, tf.ones_like(mask))
facts_size = facts.get_shape().as_list()[-1] # D value - hidden size of the RNN layer
querry_size = query.get_shape().as_list()[-1] # H,������36
# ��DIN attention��ͬ
query = tf.layers.dense(query, facts_size, activation=None, name='f1' + stag)
query = prelu(query)
# 1. ת��queryά��,�����ʷά��T
# query��[B, H],ת���� queries ά��Ϊ(B, T, H),Ϊ����pos_item���û���Ϊ������ÿ��Ԫ�ؼ���Ȩ��
# ��ʱquery�� Tensor("concat:0", shape=(?, 36), dtype=float32)
# tf.shape(keys)[1] ������� T,query��[B, H],����tile,���ǰѵ�һά���� T չ��,�õ�[B, T * H]
queries = tf.tile(query, [1, tf.shape(facts)[1]]) # [B, T * H], ���������ש
# ��ʱ queries �� Tensor("Attention_layer/Tile:0", shape=(?, ?), dtype=float32)
# queries ��Ҫ reshape �ɺ� facts ��ͬ�Ĵ�С: [B, T, H]
queries = tf.reshape(queries, tf.shape(facts)) # [B, T * H] -> [B, T, H]
# ��ʱ queries �� Tensor("Attention_layer/Reshape:0", shape=(?, ?, 36), dtype=float32)
# 2. �ⲿ��Ŀ�ľ���Ϊ����MLP֮ǰ����һЩ������Ϊitem�ͺ�ѡitem֮���ϵ�IJ���:�Ӽ��˳��ȡ�
# �õ� Local Activation Unit �����롣�� ��ѡ��� queries ��Ӧ�� emb,�û���ʷ��Ϊ���� facts
# ��Ӧ�� embed, �ټ�������֮��Ľ�������, ���� concat ��Ľ��
din_all = tf.concat([queries, facts, queries-facts, queries*facts], axis=-1) # T*[B,H] ->[B, T, H]
# 3. attention����,ͨ������MLP��ȡȨ��,���DNN ���������ڵ�Ϊ 1
d_layer_1_all = tf.layers.dense(din_all, 80, activation=tf.nn.sigmoid, name='f1_att' + stag)
d_layer_2_all = tf.layers.dense(d_layer_1_all, 40, activation=tf.nn.sigmoid, name='f2_att' + stag)
d_layer_3_all = tf.layers.dense(d_layer_2_all, 1, activation=None, name='f3_att' + stag)
# ��һ�� d_layer_3_all �� shape Ϊ [B, T, 1]
# ��һ�� reshape Ϊ [B, 1, T], axis=2 ��һά��ʾ T ���û���Ϊ���зֱ��Ӧ��Ȩ�ز���
d_layer_3_all = tf.reshape(d_layer_3_all, [-1, 1, tf.shape(facts)[1]])
scores = d_layer_3_all # attention�����, [B, 1, T]
# 4. �õ�����ʵ�����score
# key_masks = tf.sequence_mask(facts_length, tf.shape(facts)[1]) # [B, T]
key_masks = tf.expand_dims(mask, 1) # [B, 1, T]
# padding��mask��һ����С�ĸ���,����������� softmax ʱ, e^{x} �����Լ���� 0
paddings = tf.ones_like(scores) * (-2 ** 32 + 1) # ע���ʼ��Ϊ��Сֵ
# [B, 1, T] padding����,Ϊ�˺�����padding�������Ӱ��,����������tf.where��padding������(ÿ�����������п�ȱ����Ʒ)Ȩ����Ϊ��Сֵ(-2 ** 32 + 1),������0
if not forCnn:
scores = tf.where(key_masks, scores, paddings) # [B, 1, T]
# 5. Scale # attention�ı�����,����scaled��������softmax�õ����յ�Ȩ�ء�
# scores = scores / (facts.get_shape().as_list()[-1] ** 0.5)
# 6. Activation,�õ���һ�����Ȩ��
if softmax_stag:
scores = tf.nn.softmax(scores) # [B, 1, T]
# 7. �õ�����ȷ��Ȩ�� scores �Լ��û���ʷ��Ϊ���� facts, �ٽ��о�����˵õ��û�����Ȥ����
# Weighted sum,
if mode == 'SUM':
# scores �Ĵ�СΪ [B, 1, T], ��ʾÿ����ʷ��Ϊ��Ȩ��,
# facts Ϊ��ʷ��Ϊ����, ��СΪ [B, T, H];
# �����þ���˷���, �õ��Ľ�� output ���� [B, 1, H]
# B * 1 * H ��ά�������,��˷����ں���ά,�� B * (( 1 * T ) * ( T * H ))
# �����output��attention���������Ȩ��,�����Ĺ�ʽ(3)���w,
output = tf.matmul(scores, facts) # [B, 1, H]
# output = tf.reshape(output, [-1, tf.shape(facts)[-1]])
else:
# �� [B, 1, H] �仯�� Batch * Time
scores = tf.reshape(scores, [-1, tf.shape(facts)[1]])
# �Ȱ�scores���������һά,Ȼ����й������,[B, T, H] x [B, T, 1] = [B, T, H]
output = facts * tf.expand_dims(scores, -1)
output = tf.reshape(output, tf.shape(facts)) # Batch * Time * Hidden Size
return output
5.2.3 VecAttGRUCell
������,����AUGRU�Ľṹ,�������һ���µ�VecAttGRUCell�ṹ������RNN Cell��ԭ��,��������������
�������ѧϰ���ı�����,ͬ����������ν�һ�λ��еĶ��������ѹ����һ����������ʾ��λ������⡣���õķ���,���ǽ����������ι��RNN,���һ��ʱ��RNN����������ʹ����˶���������ġ��ϲ��������DIEN��������һ˼·,���Ҹ�����GRU�Ĺ���,����attention score�������š�
������������������Ҫ��call����,�ǹ���att_score����:
u = (1.0 - att_score) * u
new_h = u * state + (1 - u) * c
return new_h, new_h
���������:
def call(self, inputs, state, att_score=None):
......
c = self._activation(self._candidate_linear([inputs, r_state]))
u = (1.0 - att_score) * u # �����������ӵ�
new_h = u * state + (1 - u) * c # �����������ӵ�
return new_h, new_h
5.2.4 ������Ȥ��������
��ƺ����µ�GRU Cell,���Ǿ��ܼ�����Ȥ�Ľ�������,����� ��rnn_2�� ��ɵġ�
with tf.name_scope('rnn_2'):
rnn_outputs2, final_state2 = dynamic_rnn(VecAttGRUCell(HIDDEN_SIZE), inputs=rnn_outputs,
att_scores = tf.expand_dims(alphas, -1),
sequence_length=self.seq_len_ph, dtype=tf.float32,
scope="gru2")
5.2.5 ����ȫ���Ӳ�����
�õ���Ȥ�����Ľ��final_state2֮��,��Ҫ��������embedding����ƴ��,�õ�ȫ���Ӳ������:
inp = tf.concat([self.uid_batch_embedded, self.item_eb, self.item_his_eb_sum, self.item_eb * self.item_his_eb_sum, final_state2], 1)
0x06 ȫ���Ӳ�
�������ǵõ������Ӻ�ij��ܱ�ʾ����,��������������ȫ��ͨ���Զ�ѧϰ����֮��ķ����Թ�ϵ��ϡ�
����ͨ��һ�����������,�õ����յ�ctrԤ��ֵ,�ⲿ�־���һ���������á�
# Fully connected layer
self.build_fcn_net(inp, use_dice=True)
��Ӧ�����е�:
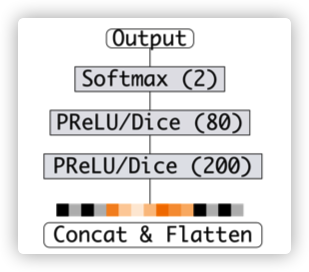
���������� :
- ���Ƚ���Batch Normalization;
- ����һ��ȫ���Ӳ�
tf.layers.dense(bn1, 200, activation=None, name='f1'); - �� dice ���� prelu �����;
- ����һ��ȫ���Ӳ�
tf.layers.dense(dnn1, 80, activation=None, name='f2'); - �� dice ���� prelu �����;
- ����һ��ȫ���Ӳ�
tf.layers.dense(dnn2, 2, activation=None, name='f3'); - �õ����
y_hat = tf.nn.softmax(dnn3) + 0.00000001; - ���н����غ�optimizer��ʼ��;
- �õ�������
- tf.reduce_mean(tf.log(self.y_hat) * self.target_ph); - ����и�����,��Ҫ���ϸ�����ʧ;
- ʹ�� AdamOptimizer;
- �õ�������
- ���� Accuracy;
�����������:
def build_fcn_net(self, inp, use_dice = False):
bn1 = tf.layers.batch_normalization(inputs=inp, name='bn1')
dnn1 = tf.layers.dense(bn1, 200, activation=None, name='f1')
if use_dice:
dnn1 = dice(dnn1, name='dice_1')
else:
dnn1 = prelu(dnn1, 'prelu1')
dnn2 = tf.layers.dense(dnn1, 80, activation=None, name='f2')
if use_dice:
dnn2 = dice(dnn2, name='dice_2')
else:
dnn2 = prelu(dnn2, 'prelu2')
dnn3 = tf.layers.dense(dnn2, 2, activation=None, name='f3')
self.y_hat = tf.nn.softmax(dnn3) + 0.00000001
with tf.name_scope('Metrics'):
# Cross-entropy loss and optimizer initialization
ctr_loss = - tf.reduce_mean(tf.log(self.y_hat) * self.target_ph)
self.loss = ctr_loss
if self.use_negsampling:
self.loss += self.aux_loss
tf.summary.scalar('loss', self.loss)
self.optimizer = tf.train.AdamOptimizer(learning_rate=self.lr).minimize(self.loss)
# Accuracy metric
self.accuracy = tf.reduce_mean(tf.cast(tf.equal(tf.round(self.y_hat), self.target_ph), tf.float32))
tf.summary.scalar('accuracy', self.accuracy)
self.merged = tf.summary.merge_all()
0x07 ѵ��ģ��
ͨ�� model.train ��ѵ��ģ�͡�
model.train ������������:
- �û�id;
- target��item id;
- target item��Ӧ��cateid;
- �û���ʷ��Ϊ��item id list;
- �û���ʷ��Ϊitem��Ӧ��cate id list;
- ��ʷ��Ϊ��mask;
- Ŀ��ֵ;
- ��ʷ��Ϊ�ij���;
- learning rate;
- ������������;
train�����������:
def train(self, sess, inps):
if self.use_negsampling:
loss, accuracy, aux_loss, _ = sess.run([self.loss, self.accuracy, self.aux_loss, self.optimizer], feed_dict={
self.uid_batch_ph: inps[0],
self.mid_batch_ph: inps[1],
self.cat_batch_ph: inps[2],
self.mid_his_batch_ph: inps[3],
self.cat_his_batch_ph: inps[4],
self.mask: inps[5],
self.target_ph: inps[6],
self.seq_len_ph: inps[7],
self.lr: inps[8],
self.noclk_mid_batch_ph: inps[9],
self.noclk_cat_batch_ph: inps[10],
})
return loss, accuracy, aux_loss
else:
loss, accuracy, _ = sess.run([self.loss, self.accuracy, self.optimizer], feed_dict={
self.uid_batch_ph: inps[0],
self.mid_batch_ph: inps[1],
self.cat_batch_ph: inps[2],
self.mid_his_batch_ph: inps[3],
self.cat_his_batch_ph: inps[4],
self.mask: inps[5],
self.target_ph: inps[6],
self.seq_len_ph: inps[7],
self.lr: inps[8],
})
return loss, accuracy, 0
��һƪ���½�����RNN Cell,�����ڴ���
0xFF �ο�
��Google���ʵ��Wide & Deepģ��(1)
Ҳ��Deep Interest Evolution Network
��DIN��DIEN������CTR�㷨�Ľ�������
������ �˹�����,7.6 DNN�����������е�Ӧ��(����:����)
#Paper Reading# Deep Interest Network for Click-Through Rate Prediction
��paper reading��Deep Interest Evolution Network for Click-Through Rate Prediction
Ҳ��Deep Interest Evolution Network
�����Ķ�:��Deep Interest Evolution Network for Click-Through Rate Prediction��
�����ıʼǡ�Deep Interest Evolution Network(AAAI 2019)
������ʼǡ�Deep Interest Evolution Network for Click-Through Rate Prediction
DIN(Deep Interest Network):����˼��+Դ���Ķ�ע��
������CTRԤ��ϵ��(��)�C����Deep Interest Network����
CTRԤ��֮Deep Interest NetWorkģ��ԭ�����
�Ƽ�ϵͳ�������ѧϰ(��ʮ��)�C�����Ȥ��������DIENԭ����ʵս!
from google.protobuf.pyext import _message,ʹ��tensorflow���� ImportError: DLL load failed
CTRԤ�� ���ľ���(��)�CDeep Interest Network for Click-Through Rate Prediction
����CTRԤ��������(1):Deep Interest Network for Click-Through Rate Prediction����
����CTRԤ��������(2):Deep Interest Evolution Network for Click-Through Rate Prediction����
�����Ȥ����(DIN,Deep Interest Network)
����DINԴ��֮��ν�ģ�û�����(1):base����
����DINԴ��֮��ν�ģ�û�����(2):DIN�Լ��������̿���
�Ƽ�ϵͳ�������ѧϰ(��ʮ��)�C�����Ȥ��������DIENԭ����ʵս!
�Ƽ�ϵͳ�������ѧϰ(ʮ��)�C̽�ذ���֮�����Ȥ����(DIN)dz����ʵ��
�����ĵ�����2018����CTRԤ��ģ�͡�DIN(�����Ȥ����),��TF2.0���ִ���