1 什么是语言模型
1.1 自编码(auto-encoder)语言模型
自编码语言模型的优缺点:
- 优点:自然地融入双向语言模型,同时看到被预测单词的上文和下文
- 缺点:训练和预测不一致。训练的时候输入引入了[Mask]标记,但是在预测阶段往往没有这个[Mask]标记,导致预训练阶段和Fine-tuning阶段不一致。
自回归(auto-regressive)语言模型:语言模型根据输入句子的一部分文本来预测下一个词。日常生活中最常见的语言模型就是输入法提示,它可以根据你输入的内容,提示下一个单词。
1.2 自回归(auto-regressive)语言模型
自回归语言模型的优点和缺点:
- 优点:对于生成类的NLP任务,比如文本摘要,机器翻译等,从左向右的生成内容,天然和自回归语言模型契合。
- 缺点:由于一般是从左到右(当然也可能从右到左),所以只能利用上文或者下文的信息,不能同时利用上文和下文的信息。
2 基于Transformer的语言模型
Transformer:Encoder+Decoder。它们都是由多层transformer堆叠而成。
Transformer的seq2seq适用于机器翻译。即将一个文本序列翻译为另一种文本的文本序列。
3 Transformer的语言模型
在解决语言模型任务中,并不需要完整的Encoder部分和Decoder。于是在原始Transformer之后的许多研究工作中,人们尝试只使用Transformer Encoder或者Decoder,并且将它们堆得层数尽可能高。
比如BERT只使用了Encoder部分进行masked language model(自编码)训练,GPT-2便是只使用了Decoder部分进行自回归(auto regressive)语言模型训练。
4 Transformer进化
Transformer的Encoder进化成了BERT,Decoder进化成了GPT2。
Encoder:部分接受特定长度的输入,如果输入序列比这个限制短,可以使用pad填充序列的其余部分。
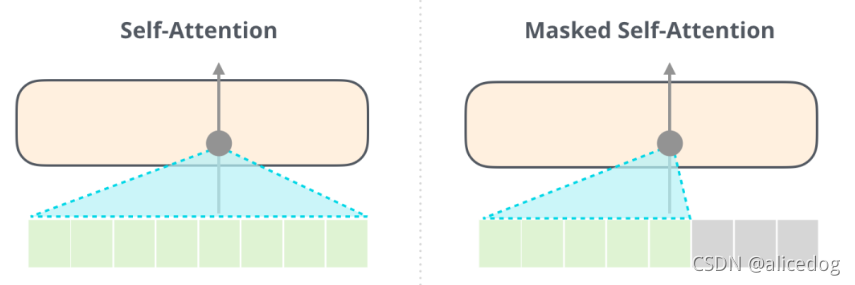
Decoder:多了一个Encoder-Decoder self-attention层,使Decoder可以attention到Encoder编码的特定信息。使Decoder可以attention到Encoder编码的特定的信息。其中的Masked Self-Attention会屏蔽未来的token。他并非直接将输入单词随意改为mask,而是通过改变Self-Attention的计算,来屏蔽未来的单词信息。
GPT2基于Decoder构建。
GPT2与BERT重要区别:BERT基于Encoder构建,故使用Self Attention层。GPT2基于Decoder构建,使用masked Self Attention。一个正常的 Self Attention允许一个位置关注到它两边的信息,而masked Self Attention只让模型看到左边的信息。
5 GPT2概述
GPT-2由多层Decoder组成,能够处理1024 个token。每个token沿着自己的路径经过所有的Decoder层。
试用一个训练好的GPT-2模型的最简单方法是让它自己生成文本,即生成无条件文本。
由于模型只有一个输入,因此只有一条活跃路径。<s> token在所有Decoder层中依次被处理,然后沿着该路径生成一个向量。根据这个向量和模型的词汇表给所有可能的词计算出一个分数。在下图的例子中,我们选择了概率最高的 the。下一步,我们把第一步的输出添加到我们的输入序列,然后让模型做下一个预测。
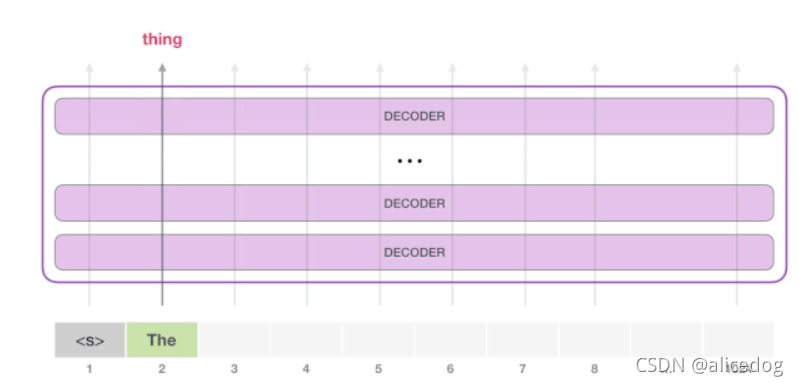
请注意,第二条路径是此计算中唯一活动的路径。GPT-2 的每一层都保留了它对第一个 token所编码的信息,而且会在处理第二个 token 时直接使用它:GPT-2 不会根据第2个 token 重新计算第一个 token。
6 GPT2详解
6.1 输入编码
输入:在嵌入矩阵中查找输入的单词对应的embedding向量。
每一行都是词的 embedding:这是一个数值向量,可以表示一个词并捕获一些含义。最小的模型使用的embedding大小是768。
在开始时,我们会在嵌入矩阵查找第一个 token <s> 的 embedding。在把这个 embedding 传给模型的第一个模块之前,我们还需要融入位置编码,这个位置编码能够指示单词在序列中的顺序。
输入的处理:得到词向量+位置编码
6.2 多层Decoder
第一层Decoder现在可以处理 <s> token所对应的向量了:首先通过 Self Attention 层,然后通过全连接神经网络。一旦Transformer 的第1个Decoder处理了<s> token,依旧可以得到一个向量,这个结果向量发送到下一层Decoder。
6.3 Decoder中的Self-Attention
Decoder中包含了Masked Self-Attention。
self-attention:语言严重依赖于上下文。
self-attention所做的事情是:它通过对句子片段中每个词的相关性打分,并将这些词的表示向量根据相关性加权求和,从而让模型能够将词和其他相关词向量的信息融合起来。
self-attention所做的事情是:它通过对句子片段中每个词的相关性打分,并将这些词的表示向量根据相关性加权求和,从而让模型能够将词和其他相关词向量的信息融合起来。
6.4 Self-Attention 过程
Self-Attention 沿着句子中每个 token 进行处理,主要组成部分包括 3 个向量。
- Query:Query 向量是由当前词的向量表示获得,用于对其他所有单词(使用这些单词的 key 向量)进行评分。
- Key:Key 向量由句子中的所有单词的向量表示获得,可以看作一个标识向量。
- Value:Value 向量在self-attention中与Key向量其实是相同的。
Masked self attention:将mask位置对应的的attention score变成一个非常小的数字或者0,让其他单词再self attention的时候(加权求和的时候)不考虑这些单词。
6.5 模型输出
当模型顶部的Decoder层产生输出向量时,模型会将这个向量乘以一个巨大的嵌入矩阵,来计算该向量和所有单词embedding向量的相关得分。这个相乘的结果,被解释为模型词汇表中每个词的分数,经过softmax之后被转换成概率。
我们可以选择最高分数的 token(top_k=1),也可以同时考虑其他词(top k)。假设每个位置输出k个token,假设总共输出n个token,那么基于n个单词的联合概率选择的输出序列会更好。
这样,模型就完成了一次迭代,输出一个单词。模型会继续迭代,直到所有的单词都已经生成,或者直到输出了表示句子末尾的 token。
7 详解Self-Attention
7.1 可视化Self-Attention
it的attention:

假设一个一次只能处理4个token的Transformer。
- 为每个路径创建 Query、Key、Value 矩阵。
- 对于每个输入的 token,使用它的 Query 向量为所有其他的 Key 向量进行打分。
- 将 Value 向量乘以它们对应的分数后求和。

(1) 创建 Query、Key 和 Value 向量:我们会使用它的Query向量,并比较所有的Key向量。这会为每个 Key 向量产生一个分数。Self Attention 的第一步是为每个 token 的路径计算 3 个向量。
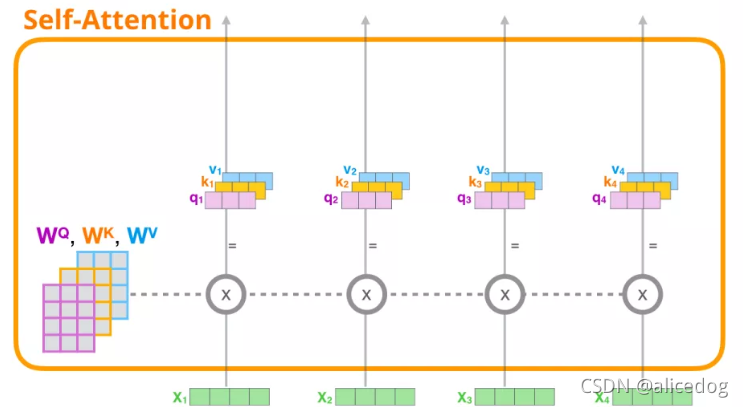
(2) 计算分数:我们关注的是第一个 token 的向量,我们将第一个 token 的 Query 向量和其他所有的 token 的 Key 向量相乘,得到 4 个 token 的分数。
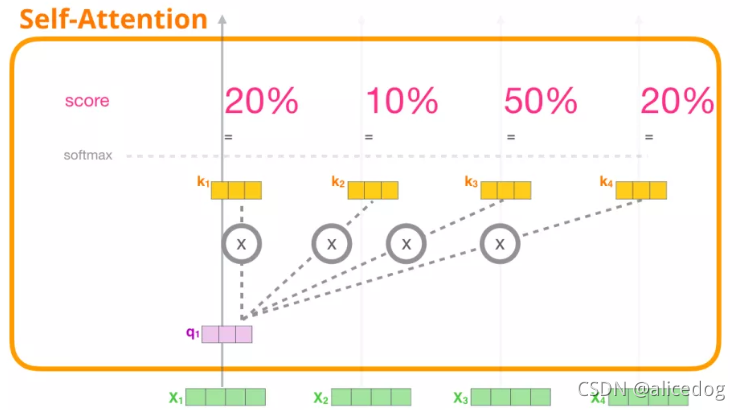
(3)计算和:我们现在可以将这些分数和 Value 向量相乘。在我们将它们相加后,一个具有高分数的 Value 向量会占据结果向量的很大一部分。

分数越低,Value 向量就越透明。这是为了说明,乘以一个小的数值会稀释 Value 向量。
如果我们对每个路径都执行相同的操作,我们会得到一个向量,可以表示每个 token,其中包含每个 token 合适的上下文信息。这些向量会输入到 Transformer 模块的下一个子层(前馈神经网络)。