ВЮПМСДНг:
https://blog.csdn.net/u013733326/article/details/80028921
https://zhuanlan.zhihu.com/p/30393923
Ек2жмВтбщ - здЖЏМнЪЛ(АИР§баОП)
ЮЪЬтГТЪі
ЮЊСЫАяжњФуСЗЯАЛњЦїбЇЯАВпТд,БОжмЮвУЧНЋНщЩмСэвЛжжГЁОАВЂбЏЮЪФуНЋШчКЮзіЁЃЮвУЧШЯЮЊетИідкЛњЦїбЇЯАЯюФПжаЙЄзїЕФЁАФЃФтЦїЁБНЋИјГівЛИів§ЕМЛњЦїбЇЯАЯюФПЕФШЮЮёЁЃ
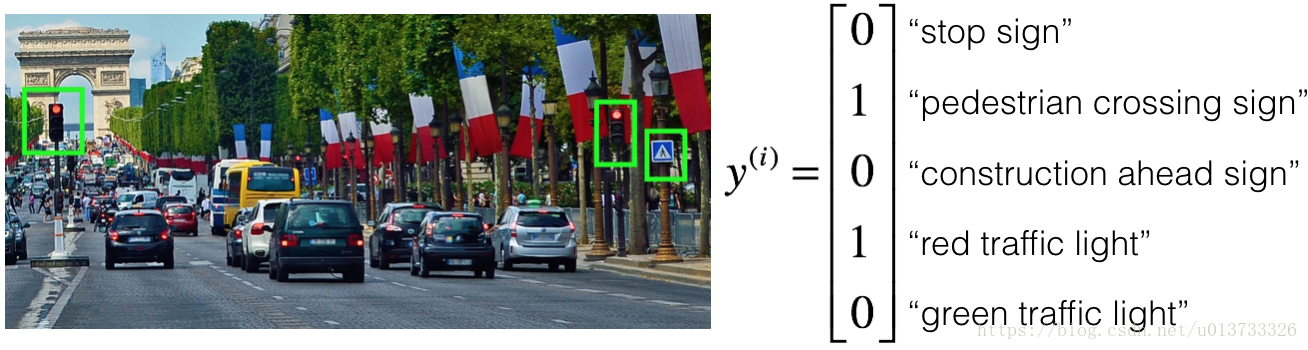
ФуЪмЙЭгквЛМвДДвЕЕФздЖЏМнЪЛЕФДДвЕЙЋЫОЁЃФњИКд№МьВтЭМЦЌжаЕФТЗБъ(ЭЃГЕБъжО,ааШЫЙ§ТЗБъжО,ЧАЗНЪЉЙЄБъжО)КЭНЛЭЈаХКХБъжО(КьЕЦКЭТЬЕЦ),ФПБъЪЧЪЖБ№ФФаЉЖдЯѓГіЯждкУПИіЭМЦЌжаЁЃР§Шч,ЩЯУцЕФЭМЦЌАќКЌвЛИіааШЫЙ§ТЗБъжОКЭКьЩЋНЛЭЈаХКХЕЦБъжОЁЃ
1.ФњЕФ100,000еХДјБъЧЉЕФЭМЦЌЪЧЪЙгУФњЦћГЕЕФЧАжУЩуЯёЭЗХФЩуЕФ,етвВЪЧФузюЙиаФЕФЪ§ОнЗжВМ,ФњШЯЮЊФњПЩвдДгЛЅСЊЭјЩЯЛёЕУИќДѓЕФЪ§ОнМЏ,МДЪЙЛЅСЊЭјЪ§ОнЕФЗжВМВЛЯрЭЌ,етвВПЩФмЖдбЕСЗгаЫљАяжњЁЃФуИеИеПЊЪМзХЪжетИіЯюФП,ФузіЕФЕквЛМўЪТЪЧЪВУД?МйЩшЯТУцЕФУПИіВНжшНЋЛЈЗбДѓдМЯрЕШЕФЪБМф(ДѓдММИЬь)ЁЃ
A. ЛЈМИЬьЪБМфШЅЛёШЁЛЅСЊЭјЕФЪ§Он,етбљФуОЭФмИќКУЕиСЫНтФФаЉЪ§ОнЪЧПЩгУЕФЁЃ
B. ЛЈМИЬьЕФЪБМфМьВщетаЉШЮЮёЕФШЫРрБэЯж,вдБуФмЙЛЕУЕНБДвЖЫЙЮѓВюЕФзМШЗЙРМЦЁЃ
C. ЛЈМИЬьЕФЪБМфЪЙгУЦћГЕЧАжУЩуЯёЭЗВЩМЏИќЖрЪ§Он,вдИќКУЕиСЫНтУПЕЅЮЛЪБМфПЩЪеМЏЖрЩйЪ§ОнЁЃ
D. ЛЈМИЬьЪБМфбЕСЗвЛИіЛљБОФЃаЭ,ПДПДЫќЛсЗИЪВУДДэЮѓЁЃ
Нт:D
дкЙЙНЈФЃаЭГѕЦк,ЮвУЧВЛБивЊНЈСЂИДдгЕФФЃаЭ,ПЩвдНЈСЂвЛИіЛљБОФЃаЭРДЙлВьПЩФмГіЯжЕФЮЪЬтЁЃ
As seen in the lecture multiple times , Machine Learning is a highly iterative process. We need to create, code, and experiment on a basic model, and then iterate in order to find out the model that works best for the given problem.ЁЃ
е§ШчдкЪгЦЕжаЖрДЮПДЕНЕФ,ЛњЦїбЇЯАЪЧвЛИіИпЖШЕќДњЕФЙ§ГЬЁЃЮвУЧашвЊдкЛљБОФЃаЭЩЯДДНЈЁЂБрТыКЭЪЕбщ,ШЛКѓЕќДњвдевГіЖдИјЖЈЮЪЬтзюгааЇЕФФЃаЭЁЃ
2.ФњЕФФПБъЪЧМьВтЕРТЗБъжО(ЭЃГЕБъжОЁЂааШЫЙ§ТЗБъжОЁЂЧАЗНЪЉЙЄБъжО)КЭНЛЭЈаХКХ(КьЕЦКЭТЬЕЦ)ЕФЭМЦЌ,ФПБъЪЧЪЖБ№етаЉЭМЦЌжаЕФФФвЛИіБъжОГіЯждкУПИіЭМЦЌжаЁЃ ФњМЦЛЎдквўВиВужаЪЙгУДјгаReLUЕЅЮЛЕФЩюВуЩёОЭјТчЁЃ
ЖдгкЪфГіВу,ЪЙгУSoftmaxМЄЛюНЋЪЧЪфГіВуЕФвЛИіБШНЯКУЕФбЁдё,вђЮЊетЪЧвЛИіЖрШЮЮёбЇЯАЮЪЬт,ЖдТ№?
Нт:ДэЮѓ
ПЩФмвЛеХЭМЦЌжаГіЯжЖрИіБъжО,softmaxжЛФмЪфГівЛжжПЩФмадЁЃ
Softmax would have been a good choice if one and only one of the possibilities (stop sign, speed bump, pedestrian crossing, green light and red light) was present in each image. Since it is not the case , softmax activation cannot be used.
ШчЙћУПИіЭМЦЌжажЛгавЛИіПЩФмад:ЭЃжЙБъжОЁЂМѕЫйДјЁЂШЫааКсЕРЁЂКьТЬЕЦ, ФЧУДSoftMaxНЋЪЧвЛИіКмКУЕФбЁдёЁЃгЩгкВЛЪЧетжжЧщПі,ЫљвдВЛФмЪЙгУSoftmax МЄЛюКЏЪ§ЁЃ
3.Фуе§дкзіЮѓВюЗжЮіВЂМЦЫуДэЮѓТЪ,дкетаЉЪ§ОнМЏжа,ФуШЯЮЊФугІИУЪжЖЏзаЯИЕиМьВщФФаЉЭМЦЌ(УПеХЭМЦЌЖМзіМьВщ)?
A. ЫцЛњбЁдё10,000ЭМЦЌ
B. ЫцЛњбЁдё500ЭМЦЌ
C. 500еХЫуЗЈЗжРрДэЮѓЕФЭМЦЌЁЃ
D.10,000еХЫуЗЈЗжРрДэЮѓЕФЭМЦЌЁЃ
Нт:C
ЮвУЧашвЊзіЮѓВюЗжЮі,вђДЫЮвУЧгІИУЪеМЏДэЮѓбљР§,Ъ§СПЬЋЖрЕФЭМЦЌВЛЗНБуЮвУЧНјааЗжЮі,ЮвУЧгІИУбЁдёЪЪСПЕФЭМЦЌЁЃ
It is of prime importance to look at those images on which the algorithm has made a mistake. Since it is not practical to look at every image the algorithm has made a mistake on , we need to randomly choose 500 such images and analyse the reason for such errors.
ВщПДЫуЗЈЗжРрГіДэЕФФЧаЉЭМЦЌЪЧЗЧГЃживЊЕФ,гЩгкВщПДЫуЗЈЗжРрДэЮѓдьГЩЕФУПИіЭМЦЌЖМВЛЬЋЪЕМЪ,ЫљвдЮвУЧашвЊЫцЛњбЁдё500ИіетбљЕФЭМЦЌВЂЗжЮіГіЯжетжжДэЮѓЕФдвђЁЃ
4.дкДІРэСЫЪ§ОнМИжмКѓ,ФуЕФЭХЖгЕУЕНвдЯТЪ§Он:
- 100,000 еХЪЙгУЦћГЕЧАЩуЯёЭЗХФЩуЕФБъМЧСЫЕФЭМЦЌЁЃ
- 900,000 еХДгЛЅСЊЭјЯТдиЕФБъМЧСЫЕРТЗЕФЭМЦЌЁЃ
УПеХЭМЦЌЕФБъЧЉЖМОЋШЗЕиБэЪОШЮКЮЕФЬиЖЈТЗБъКЭНЛЭЈаХКХЕФзщКЯЁЃ Р§Шч, y ( i ) = 1 0 0 1 1 \begin{aligned} y_{(i)}= \begin{array} {|c|} 1 \\ 0\\ 0\\ 1\\1\\ \end{array} \end{aligned} y(i)?=10011??БэЪОЭМЦЌАќКЌСЫЭЃГЕБъжОКЭКьЩЋНЛЭЈаХКХЕЦЁЃ
вђЮЊетЪЧвЛИіЖрШЮЮёбЇЯАЮЪЬт,ФуашвЊШУЫљгаy(i)y(i)ЯђСПБЛЭъШЋБъМЧЁЃ ШчЙћвЛИібљБОЕШгк 0 ? 1 1 ? \begin{aligned} \begin{array} {|c|} 0\\ ?\\ 1\\ 1\\?\\ \end{array} \end{aligned} 0?11???,ФЧУДбЇЯАЫуЗЈНЋЮоЗЈЪЙгУИУбљБО,ЪЧе§ШЗЕФТ№?
Нт:ДэЮѓ
ЩюЖШбЇЯАЫуЗЈЖдбЕСЗМЏжаЕФЫцЛњЮѓВюОпгаЯрЕБЕФТГАєадЁЃ
жЛвЊЮвУЧБъМЧГіДэЕФР§згЗћКЯЫцЛњЮѓВю,Шч:зіБъМЧЕФШЫВЛаЁаФДэЮѓ,ЛђАДДэЗжРрМќЁЃФЧУДЯёетжжЫцЛњЮѓВюЕМжТЕФБъМЧДэЮѓ,вЛАуРДЫЕВЛЙметаЉЮѓВюПЩФмвВУЛгаЮЪЬтЁЃ
In the lecture on multi-task learning, you have seen that you can compute the cost even if some entries havenЁЏt been labeled. The algorithm wonЁЏt be influenced by the fact that some entries in the data werenЁЏt labeled.
дкЖрШЮЮёбЇЯАЕФЪгЦЕжа,ФњвбОПДЕН,МДЪЙФГаЉЬѕФПУЛгаБЛБъМЧ,ФњвВПЩвдМЦЫуГЩБОЁЃИУЫуЗЈВЛЛсЪмЕНЪ§ОнжаФГаЉЬѕФПЮДБъМЧЕФбљБОЕФгАЯьЁЃ
5.ФуЫљЙиаФЕФЪ§ОнЕФЗжВМАќКЌСЫФуЦћГЕЕФЧАжУЩуЯёЭЗЕФЭМЦЌ,етгыФудкЭјЩЯевЕНВЂЯТдиЕФЭМЦЌВЛЭЌЁЃШчКЮНЋЪ§ОнМЏЗжИюЮЊбЕСЗ/ПЊЗЂ/ВтЪдМЏ?
A. НЋ10ЭђеХЧАЩуЯёЭЗЕФЭМЦЌгыдкЭјЩЯевЕНЕФ90ЭђеХЭМЦЌЫцЛњЛьКЯ,ЪЙЕУЫљгаЪ§ОнЖМЫцЛњЗжВМЁЃ НЋга100ЭђеХЭМЦЌЕФЪ§ОнМЏЗжИюЮЊ:га60ЭђеХЭМЦЌЕФбЕСЗМЏЁЂга20ЭђеХЭМЦЌЕФПЊЗЂМЏКЭга20ЭђеХЭМЦЌЕФВтЪдМЏЁЃ
B. НЋ10ЭђеХЧАЩуЯёЭЗЕФЭМЦЌгыдкЭјЩЯевЕНЕФ90ЭђеХЭМЦЌЫцЛњЛьКЯ,ЪЙЕУЫљгаЪ§ОнЖМЫцЛњЗжВМЁЃНЋга100ЭђеХЭМЦЌЕФЪ§ОнМЏЗжИюЮЊ:га98ЭђеХЭМЦЌЕФбЕСЗМЏЁЂга1ЭђеХЭМЦЌЕФПЊЗЂМЏКЭга1ЭђеХЭМЦЌЕФВтЪдМЏЁЃ
C. бЁдёДгЛЅСЊЭјЩЯЕФ90ЭђеХЭМЦЌКЭЦћГЕЧАжУЩуЯёЭЗЕФ8ЭђеХЭМЦЌзїЮЊбЕСЗМЏ,ЪЃгрЕФ2ЭђеХЭМЦЌдкПЊЗЂМЏКЭВтЪдМЏжаЦНОљЗжХфЁЃ
D. бЁдёДгЛЅСЊЭјЩЯЕФ90ЭђеХЭМЦЌКЭЦћГЕЧАжУЩуЯёЭЗЕФ2ЭђеХЭМЦЌзїЮЊбЕСЗМЏ,ЪЃгрЕФ8ЭђеХЭМЦЌдкПЊЗЂМЏКЭВтЪдМЏжаЦНОљЗжХфЁЃ
Нт:C
КУДІ:ПЊЗЂМЏШЋВПРДздЦћГЕЧАжУЩуЯёЭЗ,УщзМФПБъ;
ЛЕДІ:бЕСЗМЏКЭПЊЗЂЁЂВтЪдМЏРДздВЛЭЌЕФЗжВМЁЃ
ДгГЄЦкРДПД,етбљЕФЗжВМФмЙЛИјЮвУЧДјРДИќКУЕФЯЕЭГадФмЁЃ
As seen in lecture, it is important to distribute your data in such a manner that your training and dev set have a distribution that resembles the ЁАreal lifeЁБ data. Also , the test set should contain adeqate amount of ЁАreal-lifeЁБ data you actually care about.
е§ШчдкПЮЬУЩЯПДЕНЕФФЧбљ,ЗжХфЪ§ОнЕФЗНЪНЗЧГЃживЊ,ФњЕФбЕСЗКЭПЊЗЂМЏЕФЗжВМРрЫЦгкЁАЯжЪЕЩњЛюЁБЪ§ОнЁЃДЫЭт,ВтЪдМЏгІАќКЌФњЪЕМЪЙиаФЕФзуЙЛЪ§СПЕФЁАЯжЪЕЩњЛюЁБЪ§ОнЁЃ
6.МйЩшФњзюжебЁдёСЫвдЯТВ№ЗжЪ§ОнМЏЕФЗНЪН:
| Ъ§ОнМЏ | ЭМЦЌЪ§СП | ЫуЗЈВњЩњЕФДэЮѓ |
|---|---|---|
| бЕСЗМЏ | ЫцЛњГщШЁ94ЭђеХЭМЦЌ(Дг90ЭђеХЛЅСЊЭјЭМЦЌ + 6ЭђеХЦћГЕЧАЩуЯёЭЗХФЩуЕФЭМЦЌжаГщШЁ) | 8.8% |
| бЕСЗ-ПЊЗЂМЏ | ЫцЛњГщШЁ2ЭђеХЭМЦЌ(Дг90ЭђеХЛЅСЊЭјЭМЦЌ + 6ЭђеХЦћГЕЧАЩуЯёЭЗХФЩуЕФЭМЦЌжаГщШЁ) | 9.1% |
| ПЊЗЂМЏ | 2ЭђеХЦћГЕЧАЩуЯёЭЗХФЩуЕФЭМЦЌ | 14.3% |
| ВтЪдМЏ | 2ЭђеХЦћГЕЧАЩуЯёЭЗХФЩуЕФЭМЦЌ | 14.8% |
ФњЛЙжЊЕРЕРТЗБъжОКЭНЛЭЈаХКХЗжРрЕФШЫЮЊДэЮѓТЪДѓдМЮЊ0.5%ЁЃвдЯТФФЯюЪЧецЕФ(МьВщЫљгабЁЯю)?
A. гЩгкПЊЗЂМЏКЭВтЪдМЏЕФДэЮѓТЪЗЧГЃНгНќ,ЫљвдФуЙ§ФтКЯСЫПЊЗЂМЏЁЃ
B. ФугавЛИіКмДѓЕФЪ§ОнВЛЦЅХфЮЪЬт,вђЮЊФуЕФФЃаЭдкбЕСЗ-ПЊЗЂМЏЩЯБШдкПЊЗЂМЏЩЯзіЕУКУЕУЖрЁЃ
C. ФугавЛИіКмДѓЕФПЩБмУтЦЋВюЮЪЬт,вђЮЊФуЕФбЕСЗМЏЩЯЕФДэЮѓТЪБШШЫЮЊДэЮѓТЪИпКмЖрЁЃ
D. ФугаКмДѓЕФЗНВюЕФЮЪЬт,вђЮЊФуЕФбЕСЗМЏЩЯЕФДэЮѓТЪБШШЫЮЊДэЮѓТЪвЊИпЕУЖрЁЃ
E. ФугаКмДѓЕФЗНВюЕФЮЪЬт,вђЮЊФуЕФФЃаЭВЛФмКмКУЕиЪЪгІРДздЭЌвЛбЕСЗМЏЩЯЕФЗжВМЕФЪ§Он,МДЪЙЪЧЫќДгРДУЛгаМћЙ§ЕФЪ§ОнЁЃ
Нт:B C
Й§ФтКЯЕФБъзМВЛЪЧвђЮЊПЊЗЂМЏКЭВтЪдМЏЕФЮѓВюТЪНгНќЁЃ
ЮвУЧПЩвдШЯЮЊгаКмДѓЕФЦЋВюЮЪЬт,вђЮЊбЕСЗМЏЕФДэЮѓТЪБШШЯЮЊДэЮѓТЪИпКмЖрЁЃЫЕУїФЃаЭДІгкЧЗФтКЯЕФзДЬЌ,вђДЫЮвУЧашвЊЬсИпФЃаЭЕФИДдгЖШЁЃ
УЛабУЛгаКмДѓЕФЗНВюЮЪЬтЁЃ
7.ИљОнЩЯвЛИіЮЪЬтЕФБэИё,вЛЮЛХѓгбШЯЮЊбЕСЗЪ§ОнЗжВМБШПЊЗЂ/ВтЪдЗжВМвЊШнвзЕУЖрЁЃФудѕУДПД?
A. ФуЕФХѓгбЪЧЖдЕФЁЃ (МДбЕСЗЪ§ОнЗжВМЕФБДвЖЫЙЮѓВюПЩФмЕЭгкПЊЗЂ/ВтЪдЗжВМ)ЁЃ
B. ФуЕФХѓгбДэСЫЁЃ(МДбЕСЗЪ§ОнЗжВМЕФБДвЖЫЙЮѓВюПЩФмБШПЊЗЂ/ВтЪдЗжВМИќИп)ЁЃ
C. УЛгазуЙЛЕФаХЯЂРДХаЖЯФуЕФХѓгбЪЧЖдЛЙЪЧДэЁЃ
D. ЮоТлФуЕФХѓгбЪЧЖдЛЙЪЧДэ,етаЉаХЯЂЖМЖдФуУЛгагУЁЃ
Нт:C
гЩгкШЫЕФдкХФЩуЪ§ОнКЭЭјТчЪ§ОнЩЯИїздЕФЪЖБ№ЫЎЦНЛЙВЛЧхГў,ЫљвдЮоЗЈКтСПЫуЗЈЪЧЗёдкХФЩуЪ§ОнЗжВМЩЯБШЭјТчЪ§ОнЗжВМЩЯИќКУ
To get an idea of this, we will have to measure human-level error separately on both distributions.The algorithm does better on the distribution data it is trained on. But we do not know for certain that it was because it was trained on that data or if it was really easier than the dev/test distribution.
ЮЊСЫСЫНтетвЛЕу,ЮвУЧБиаыдкСНИіЗжВМЩЯЗжБ№ВтСПШЫЕФЫЎЦНЮѓВю,ИУЫуЗЈЖдбЕСЗЕФЗжВМЪ§ОнгаИќКУЕФаЇЙћЁЃЕЋЮвУЧВЛШЗЖЈетЪЧвђЮЊЫќБЛбЕСЗдкЪ§ОнЩЯ,ЛђепЫќБШПЊЗЂ/ВтЪдЗжВМИќШнвзЁЃ
ВЉжїзЂ:ВЉжїЮДФмРэНтЦфвтЫМ,гаФмСІЕФЖСепПЩвдПДвЛЯТгЂЮФАЩЁЃ
8.ФњОіЖЈНЋжиЕуЗХдкПЊЗЂМЏЩЯ, ВЂЪжЖЏМьВщЪЧЪВУДдвђЕМжТЕФДэЮѓЁЃЯТУцЪЧвЛИіБэ, змНсСЫФњЕФЗЂЯж:
| ПЊЗЂМЏзмЮѓВю | 14.3% |
|---|---|
| гЩгкЪ§ОнБъМЧВЛе§ШЗЖјЕМжТЕФДэЮѓ | 4.1% |
| гЩгкЮэЬьЕФЭМЦЌв§Ц№ЕФДэЮѓ | 8.0% |
| гЩгкгъЕЮТфдкЦћГЕЧАЩуЯёЭЗЩЯдьГЩЕФДэЮѓ | 2.2% |
| ЦфЫћдвђв§Ц№ЕФДэЮѓ | 1.0% |
дкетИіБэИёжа,4.1%ЁЂ8.0%етаЉБШР§ЪЧзмПЊЗЂМЏЕФвЛаЁВПЗж(ВЛНіНіЪЧФњЕФЫуЗЈДэЮѓБъМЧЕФбљБО),МДДѓдМ8.0 / 14.3 = 56%ЕФДэЮѓЪЧгЩгкЮэЬьЕФЭМЦЌдьГЩЕФЁЃ
ДгетИіЗжЮіЕФНсЙћвтЮЖзХЭХЖгзюЯШзіЕФгІИУЪЧАбИќЖрЮэЬьЕФЭМЦЌФЩШыбЕСЗМЏ,вдБуНтОіИУРрБ№жаЕФ8%ЕФДэЮѓ,ЖдТ№?
A. ДэЮѓ,вђЮЊетШЁОігкЬэМгетаЉЪ§ОнЕФШнвзГЬЖШвдМАФњвЊПМТЧЭХЖгШЯЮЊЫќЛсгаЖрДѓАяжњЁЃ
B. ЪЧЕФ,вђЮЊЫќЪЧДэЮѓТЪзюДѓЕФРрБ№ЁЃе§ШчЪгЦЕжаЫљЬжТлЕФ,ЮвУЧгІИУЖдДэЮѓТЪНјааАДДѓаЁХХађ,вдБмУтРЫЗбЭХЖгЕФЪБМфЁЃ
C. ЪЧЕФ,вђЮЊЫќБШЦфЫћЕФДэЮѓРрБ№ДэЮѓТЪМгдквЛЦ№ЖМДѓ(8.0 > 4.1+2.2+1.0)ЁЃ
D. ДэЮѓ,вђЮЊЪ§ОндіЧП(ЭЈЙ§ЧхЮњЕФЭМЯё+ЮэЕФаЇЙћКЯГЩЮэЬьЕФЭМЯё)ИќгааЇЁЃ
Нт:A
ПЩФмЕФдвђАќРЈСЫЮэЬьЕФЭМЦЌЪ§ОнВЛЙЛ,ЭЛШЛМгШыИќЖрЕФЮэЬьЭМЦЌПЩФмЛсЕМжТФЃаЭЕФЙ§ФтКЯ,ЗДЖјНЕЕЭСЫЦфЫћЭМЦЌЕФЗжРрзМШЗТЪЁЃ
9.ФуПЩвдТђвЛИізЈУХЩшМЦЕФгъЙЮ,АяжњВСЕєе§УцЯрЛњЩЯЕФвЛаЉгъЕЮЁЃ ИљОнЩЯвЛИіЮЪЬтЕФБэИё,ФњЭЌвтвдЯТФФаЉГТЪі?
A. ЖдгкЕВЗчВЃСЇгъЫЂПЩвдИФЩЦФЃаЭЕФадФмЖјбд,2.2%ЪЧИФЩЦЕФзюДѓжЕЁЃ
B. ЖдгкЕВЗчВЃСЇгъЫЂПЩвдИФЩЦФЃаЭЕФадФмЖјбд,2.2%ЪЧИФЩЦзюаЁжЕЁЃ
C. ЖдгкЕВЗчВЃСЇгъЫЂПЩвдИФЩЦФЃаЭЕФадФмЖјбд,ИФЩЦЕФадФмОЭЪЧ2.2%ЁЃ
D. дкзюЛЕЕФЧщПіЯТ,2.2%НЋЪЧвЛИіКЯРэЕФЙРМЦ,вђЮЊЕВЗчВЃСЇЙЮЫЎЦїЛсЫ№ЛЕФЃаЭЕФадФмЁЃ
Нт:A
You will probably not improve performance by more than 2.2% by solving the raindrops problem. If your dataset was infinitely big, 2.2% would be a perfect estimate of the improvement you can achieve by purchasing a specially designed windshield wiper that removes the raindrops.
вЛАуЖјбд,НтОіСЫгъЕЮЕФЮЪЬтФуЕФДэЮѓТЪПЩФмВЛЛсЭъШЋНЕЕЭ2.2%,ШчЙћФуЕФЪ§ОнМЏЪЧЮоЯоДѓЕФ, ИФЩЦ2.2% НЋЪЧвЛИіРэЯыЕФЙРМЦ, ТђвЛИігъЙЮЪЧгІИУПЩвдИФЩЦадФмЕФЁЃ
10.ФњОіЖЈЪЙгУЪ§ОндіЧПРДНтОіЮэЬьЕФЭМЯё,ФњПЩвддкЛЅСЊЭјЩЯевЕН1,000еХЮэЕФееЦЌ,ШЛКѓФУЧхЮњЕФЭМЦЌКЭЮэРДКЯГЩЮэЬьЭМЦЌ,ШчЯТЫљЪО:

ФуЭЌвтЯТСаФФжжЫЕЗЈ?(МьВщЫљгабЁЯю)
A. жЛвЊФуАбЫќгывЛИіИќДѓ(дЖДѓгк1000)ЕФЧхЮњ/ВЛФЃК§ЕФЭМЯёНсКЯдквЛЦ№,ФЧУДЖдЮэЕФ1000ЗљЭМЦЌОЭУЛгаЬЋДѓЕФЙ§ФтКЯЕФЗчЯеЁЃ
B. НЋКЯГЩЕФПДЦ№РДЯёеце§ЕФЮэЬьЭМЦЌЬэМгЕНДгФуЕФЦћГЕЧАЩуЯёЭЗХФЩуЕНЕФЭМЦЌЕФЪ§ОнМЏЖдгыИФНјФЃаЭВЛЛсгаШЮКЮАяжњ,вђЮЊЫќЛсв§ШыПЩБмУтЕФЦЋВюЁЃ
C. жЛвЊКЯГЩЕФЮэЖдШЫблРДЫЕЪЧецЪЕЕФ,ФуОЭПЩвдШЗаХКЯГЩЕФЪ§ОнКЭецЪЕЕФЮэЬьЭМЯёВюВЛЖр,вђЮЊШЫРрЕФЪгОѕЖдгкФуе§дкНтОіЕФЮЪЬтЪЧЗЧГЃзМШЗЕФЁЃ
Нт:C
ШчЙћШЫРрШЯЮЊКЯГЩЕФЮэЪЧецЪЕЕФ,ФЧУДЮвУЧПЩвдгУБШНЯЩйЕФдыЩљЪ§ОнРДдіЧПЪ§Он,ЕЋЪЧПЩФмЛсдьГЩФЃаЭЖдетРрдыЩљЙ§ФтКЯЁЃ
If the synthesized images look realistic, then the model will just see them as if you had added useful data to identify road signs and traffic signals in a foggy weather.
ШчЙћКЯГЩЕФЭМЯёПДЦ№РДБЦец, ОЭКУЯёФњдкгаЮэЕФЬьЦјжаЬэМгСЫгагУЕФЪ§ОнРДЪЖБ№ЕРТЗБъжОКЭНЛЭЈаХКХвЛбљЁЃ
11.дкНјвЛВНДІРэЮЪЬтжЎКѓ,ФњвбОіЖЈИќе§ПЊЗЂМЏЩЯДэЮѓБъМЧЕФЪ§ОнЁЃ ФњЭЌвтвдЯТФФаЉГТЪі? (МьВщЫљгабЁЯю)ЁЃ
A. ФњВЛгІИќе§бЕСЗМЏжаЕФДэЮѓБъМЧЕФЪ§Он, вдУтЯждкЕФбЕСЗМЏгыПЊЗЂМЏИќВЛЭЌЁЃ
Deep learning algorithms are quite robust to having slightly different train and dev distributions.
ЩюЖШбЇЯАЫуЗЈЖдгкТдгаВЛЭЌЕФбЕСЗМЏКЭПЊЗЂМЏЗжВМЪЧЯрЕБЧПДѓЕФЁЃ(ВЉжїзЂ:втЫМЪЧаЁИФЖЏЛсдьГЩДѓВювь)
B. ФњгІИУИќе§бЕСЗМЏжаЕФДэЮѓБъМЧЪ§Он, вдУтФњЯждкЕФбЕСЗМЏгыПЊЗЂМЏИќВЛЭЌЁЃ
C. ФњВЛгІИУИќе§ВтЪдМЏжаДэЮѓБъМЧЕФЪ§Он,вдБуПЊЗЂКЭВтЪдМЏРДздЭЌвЛЗжВМЁЃ
D. ФњЛЙгІИУИќе§ВтЪдМЏжаДэЮѓБъМЧЕФЪ§Он,вдБуПЊЗЂКЭВтЪдМЏРДздЭЌвЛЗжВМЁЃ
Because you want to make sure that your dev and test data come from the same distribution for your algorithm to make your teamЁЏs iterative development process is efficient.
вђЮЊФуЯыШЗБЃФуЕФПЊЗЂКЭВтЪдЪ§ОнРДздЯрЭЌЕФЗжВМ,вдЪЙФуЕФЭХЖгЕФЕќДњПЊЗЂЙ§ГЬИпаЇЁЃ
ЭЌЪБИФПЊЗЂМЏКЭВтЪдМЏ,етбљВХФмБЃГжбЕСЗ,ПЊЗЂ,ВтЪддкЯрЭЌЕФЗжВМ
Нт:A D
12.ЕНФПЧАЮЊжЙ,ФњЕФЫуЗЈНіФмЪЖБ№КьЩЋКЭТЬЩЋНЛЭЈЕЦ,ИУЙЋЫОЕФвЛЮЛЭЌЪТПЊЪМзХЪжЪЖБ№ЛЦЩЋНЛЭЈЕЦ(вЛаЉЙњМвГЦжЎЮЊГШЩЋЙтЖјВЛЪЧЛЦЩЋЙт,ЮвУЧНЋЪЙгУУРЙњЕФЛЦЩЋБъзМ),КЌгаЛЦЩЋЕЦЕФЭМЯёЗЧГЃКБМћ,ЖјЧвЫ§УЛгазуЙЛЕФЪ§ОнРДНЈСЂвЛИіКУЕФФЃаЭ,Ы§ЯЃЭћФуФмгУзЊвЦбЇЯААяжњЫ§ЁЃ
ФуИцЫпФуЕФЭЌЪТдѕУДзі?
A. Ы§гІИУГЂЪдЪЙгУдкФуЕФЪ§ОнМЏЩЯдЄЯШбЕСЗЙ§ЕФШЈжи,ВЂгУЛЦЙтЪ§ОнМЏНјааНјвЛВНЕФЮЂЕїЁЃ
B. ШчЙћЫ§га10,000ИіЛЦЙтЭМЯё,ДгФњЕФЪ§ОнМЏжаЫцЛњГщШЁ10,000еХЭМЯё,ВЂНЋФњКЭЫ§ЕФЪ§ОнЗХдквЛЦ№,етПЩвдЗРжЙФњЕФЪ§ОнМЏЁАбЭУЛЁБЫ§ЕФЛЦЕЦЪ§ОнМЏЁЃ
C. ФуУЛАьЗЈАяжњЫ§,вђЮЊФуЕФЪ§ОнЗжВМгыЫ§ЕФВЛЭЌ,ЖјЧвШБЗІЛЦЕЦБъЧЉЕФЪ§ОнЁЃ
D. НЈвщЫ§ГЂЪдЖрШЮЮёбЇЯА,ЖјВЛЪЧЪЙгУЫљгаЪ§ОнНјааЧЈвЦбЇЯАЁЃ
Нт:A
ЧЈвЦбЇЯАгавтвхЕФЧщПі:
- ШЮЮёAКЭШЮЮёBгазХЯрЭЌЕФЪфШы;
- ШЮЮёAЫљгЕгаЕФЪ§ОнвЊдЖдЖДѓгкШЮЮёB(ЖдгкИќгаМлжЕЕФШЮЮёB,ШЮЮёAЫљгЕгаЕФЪ§ОнвЊБШBДѓКмЖр);
- ШЮЮёAЕФЕЭВуЬиеїбЇЯАЖдШЮЮёBгавЛЖЈЕФАяжњЁЃ
You have trained your model on a huge dataset, and she has a small dataset. Although your labels are different, the parameters of your model have been trained to recognize many characteristics of road and traffic images which will be useful for her problem. This is a perfect case for transfer learning, she can start with a model with the same architecture as yours, change what is after the last hidden layer and initialize it with your trained parameters.
ФувбОдквЛИіХгДѓЕФЪ§ОнМЏЩЯбЕСЗСЫФуЕФФЃаЭ,ВЂЧвЫ§гавЛИіаЁЪ§ОнМЏЁЃ ОЁЙмФњЕФБъЧЉВЛЭЌ,ЕЋФњЕФФЃаЭВЮЪ§вбОЙ§бЕСЗ,ПЩвдЪЖБ№ЕРТЗКЭНЛЭЈЭМЯёЕФаэЖрЬиеї,етаЉЬиеїЖдгкЫ§ЕФЮЪЬтКмгагУЁЃ етЖдгкзЊвЦбЇЯАРДЫЕЪЧвЛИіЭъУРЕФР§зг,Ы§ПЩвдДгвЛИігыФњЕФМмЙЙЯрЭЌЕФФЃаЭПЊЪМ,ИФБфзюКѓвЛИівўВиВужЎКѓЕФФкШн,ВЂЪЙгУФњЕФбЕСЗВЮЪ§ЖдЦфНјааГѕЪМЛЏЁЃ
13.СэвЛЮЛЭЌЪТЯывЊЪЙгУЗХжУдкГЕЭтЕФТѓПЫЗчРДИќКУЕиЬ§ЧхФужмЮЇЪЧЗёгаЦфЫћГЕСОЁЃ Р§Шч,ШчЙћФуЩэКѓгаОЏГЕ,ФуОЭПЩвдЬ§ЕНОЏЕбЩљЁЃ ЕЋЪЧ,ЫћУЧУЛгаЬЋЖрЕФбЕСЗетИівєЦЕЯЕЭГ,ФуФмАяУІТ№?
A. ДгЪгОѕЪ§ОнМЏЧЈвЦбЇЯАПЩвдАяжњФњЕФЭЌЪТМгПьВНЗЅ,ЖрШЮЮёбЇЯАЫЦКѕВЛЬЋгаЯЃЭћЁЃ
B. ДгФњЕФЪгОѕЪ§ОнМЏжаНјааЖрШЮЮёбЇЯАПЩвдАяжњФњЕФЭЌЪТМгПьВНЗЅ,ЧЈвЦбЇЯАЫЦКѕВЛЬЋгаЯЃЭћЁЃ
C. ЧЈвЦбЇЯАЛђЖрШЮЮёбЇЯАПЩвдАяжњЮвУЧЕФЭЌЪТМгПьВНЗЅЁЃ
D. ЧЈвЦбЇЯАКЭЖрШЮЮёбЇЯАЖМВЛЪЧКмгаЯЃЭћЁЃ
Нт:D
ЖрШЮЮёбЇЯАгавтвхЕФЧщПі:
- ШчЙћбЕСЗЕФвЛзщШЮЮёПЩвдЙВгУЕЭВуЬиеї;
- ЭЈГЃ,ЖдгкУПИіШЮЮёДѓСПЕФЪ§ОнОпгаКмДѓЕФЯрЫЦад;(Шч,дкЧЈвЦбЇЯАжагЩШЮЮёAЁА100ЭђЪ§ОнЁБЧЈвЦЕНШЮЮёBЁА1000Ъ§ОнЁБ;ЖрШЮЮёбЇЯАжа,ШЮЮё [ЭтСДЭМЦЌзЊДцЪЇАм,дДеОПЩФмгаЗРЕССДЛњжЦ,НЈвщНЋЭМЦЌБЃДцЯТРДжБНгЩЯДЋ(img-Tq6A0Jkc-1632044988451)(https://www.zhihu.com/equation?tex=A_%7B1%7D%EF%BC%8CЁ%EF%BC%8CA_%7Bn%7D)] ,УПИіШЮЮёОљга1000ИіЪ§Он,КЯЦ№РДОЭга1000nИіЪ§Он,ЙВЭЌАяжњШЮЮёЕФбЕСЗ)
- ПЩвдбЕСЗвЛИізуЙЛДѓЕФЩёОЭјТчВЂЭЌЪБзіКУЫљгаЕФШЮЮёЁЃ
The problem he is trying to solve is quite different from yours. The different dataset structures make it probably impossible to use transfer learning or multi-task learning.
ЫћЪдЭМНтОіЕФЮЪЬтгыФуЕФЮЪЬтЭъШЋВЛЭЌ,ВЛЭЌЕФЪ§ОнМЏНсЙЙПЩФмЮоЗЈЪЙгУЧЈвЦбЇЯАЛђЖрШЮЮёбЇЯАЁЃ
14.вЊЪЖБ№КьЩЋКЭТЬЩЋЕФЕЦЙт,ФувЛжБдкЪЙгУетжжЗНЗЈ:
A:НЋЭМЯё x x xЪфШыЕНЩёОЭјТч,ВЂжБНгбЇЯАгГЩфвддЄВтЪЧЗёДцдкКьЙт(КЭ/Лђ)ТЬЙт y y yЁЃ
вЛИіЖггбЬсГіСЫСэвЛжжСНВНзпЕФЗНЗЈ:
B:дкетИіСНВНЗЈжа,ФњЪзЯШвЊМьВтЭМЯёжаЕФНЛЭЈЕЦ(ШчЙћга),ШЛКѓШЗЖЈНЛЭЈаХКХЕЦжаееУїЕЦЕФбеЩЋЁЃ
дкетСНепжЎМф,ЗНЗЈBИќЖрЕФЪЧЖЫЕНЖЫЕФЗНЗЈ,вђЮЊЫќдкЪфШыЖЫКЭЪфГіЖЫгаВЛЭЌЕФВНжш,етжжЫЕЗЈе§ШЗТ№?
Нт:ДэЮѓ
ЖЫЕНЖЫбЇЯАЕФЖЈвх:
ЯрЖдгкДЋЭГЕФвЛаЉЪ§ОнДІРэЯЕЭГЛђепбЇЯАЯЕЭГ,ЫќУЧАќКЌСЫЖрИіНзЖЮЕФДІРэЙ§ГЬ,ЖјЖЫЕНЖЫЕФЩюЖШбЇЯАдђКіТдСЫетаЉНзЖЮ,гУЕЅИіЩёОЭјТчРДЬцДњЁЃ
(A) is an end-to-end approach as it maps directly the input (x) to the output (y).
AЪЧвЛжжЖЫЕНЖЫЕФЗНЗЈ,вђЮЊЫќжБНгНЋЪфШы(x)гГЩфЕНЪфГі(y)ЁЃ
15.Approach A (in the question above) tends to be more promising than approach B if you have a _____(fill in the blank).ШчЙћФугавЛИі_____,дкЩЯУцЕФЮЪЬтжаЗНЗЈAЭљЭљБШBЗНЗЈИќгааЇ,
A. ДѓбЕСЗМЏ
B. ЖрШЮЮёбЇЯАЕФЮЪЬтЁЃ
C. ЦЋВюБШНЯДѓЕФЮЪЬтЁЃ
D. ИпБДвЖЫЙЮѓВюЕФЮЪЬтЁЃ
Нт:A
дкЩйЪ§ОнМЏЕФЧщПіЯТДЋЭГЕФЬиеїЬсШЁЗНЪНПЩФмЛсШЁЕУКУЕФаЇЙћ;ШчЙћдкгазуЙЛЕФДѓСПЪ§ОнМЏЧщПіЯТ,ЖЫЕНЖЫЕФЩюЖШбЇЯАЛсЗЂЛгОоДѓЕФМлжЕЁЃ
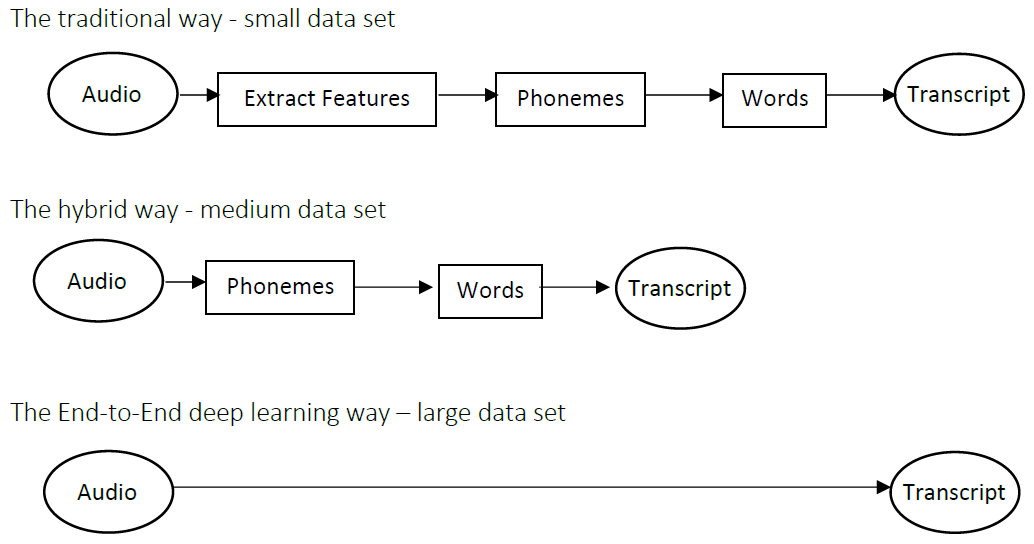
In many fields, it has been observed that end-to-end learning works better in practice, but requires a large amount of data. Without a larger amout of data , the application of End-To-End Deep Learning is futile.
дкаэЖрСьгђ,ОнЙлВь,ЖЫЕНЖЫбЇЯАдкЪЕМљжааЇЙћИќКУ,ЕЋашвЊДѓСПЪ§ОнЁЃ ШчЙћУЛгаДѓСПЕФЪ§Он,ЖЫЕНЖЫЩюЖШбЇЯАЕФгІгУЪЧаЇЙћБШНЯВюЕФЁЃ