����Ŀ¼
һ��Ŀ�����������

??һ�Ƿ���(Classification),���ǽ�ͼ��ṹ��Ϊijһ������Ϣ,������ȷ���õ����(string)��ʵ��ID������ͼƬ����һ����������������ͼ����������,Ҳ�����ѧϰģ������ȡ��ͻ�ƺ�ʵ�ִ��ģӦ�õ���������,ImageNet����Ȩ�������⼯,ÿ���ILSVRC�����˴����������������ṹ,Ϊ���������ṩ�˻�������Ӧ������,������������ʶ��ȶ����Թ�Ϊ��������
??���Ǽ��(Detection)�����������������,������������ͼƬ����������,��������ע�ض�������Ŀ��,Ҫ��ͬʱ�����һĿ��������Ϣ��λ����Ϣ����ȷ���,���������Ƕ�ͼƬǰ���ͱ���������,������Ҫ�ӱ����з��������Ȥ��Ŀ��,��ȷ����һĿ�������(����λ��),���,���ģ�͵������һ���б�,�б���ÿһ��ʹ��һ��������������Ŀ�������λ��(���þ��μ���������ʾ)��
??���Ƿָ�(Segmentation)���ָ��������ָ�(semantic segmentation)��ʵ���ָ�(instance segmentation),ǰ���Ƕ�ǰ�����������չ,Ҫ����뿪���в�ͬ�����ͼ��,�������Ǽ���������չ,Ҫ��������Ŀ�������(��ȼ����Ϊ��ϸ)���ָ��Ƕ�ͼ������ؼ�����,������ÿ���������(ʵ��)����,����������Ҫ��ϸߵij���,�����˼�ʻ�жԵ�·�ͷǵ�·�ķָ
�ο�:https://zhuanlan.zhihu.com/p/34142321
����Ŀ����ͱ߽��
2.1 ê���弰��ػ���֪ʶ
Hightly comments:https://zhuanlan.zhihu.com/p/63024247
ֱ�۵��ô�����ͺ�չ��һ��ʲô��ê��:
%matplotlib inline
import torch
from d2l import torch as d2l
import matplotlib.pyplot as plt
import matplotlib.image as mpimg
����һ��ͼƬ���в���
# ����ʾ��ͼ��
img_path = "./data/Coco/catdog.jpg"
img_data = mpimg.imread(img_path)
plt.figure()
# plt.axis('off')
plt.imshow(img_data)
plt.title("Cat and Dog")
plt.show()

�������������������ֲ�ͬ�߿��ʾ������ת��
def box_corner_to_center(boxes):
"""��(����,����)ת����(�м�,����,�߶�)"""
x1,y1,x2,y2 = boxes[:,0],boxes[:,1],boxes[:,2],boxes[:,3]
cx = (x1+x2)/2
cy = (y1+y2)/2
w = x2 - x1
h = y2 - y1
boxes = torch.stack((cx,cy,w,h),axis=-1)
return boxes
def box_center_to_corner(boxes):
"""��(�м�,����,�߶�)ת����(����,����)"""
cx,cy,w,h = boxes[:,0],boxes[:,1],boxes[:,2],boxes[:,3]
x1 = cx-0.5*w
y1 = cy-0.5*h
x2 = cx+0.5*w
y2 = cy+0.5*h
boxes = torch.stack((x1,y1,x2,y2),axis=-1)
return boxes
# ����ͼ����è���ı߽�
# bbox�DZ߽���Ӣ����д
dog_bbox, cat_bbox = [60.0, 45.0, 378.0, 516.0], [400.0, 112.0, 655.0, 493.0]
# ���߽����Ƴ���
def bbox_to_rect(bbox,color):
return plt.Rectangle((bbox[0],bbox[1]),bbox[2]-bbox[0],bbox[3]-bbox[1],fill=False,edgecolor=color,linewidth=2)
fig = d2l.plt.imshow(img_data)
fig.axes.add_patch(bbox_to_rect(dog_bbox,'blue'))
fig.axes.add_patch(bbox_to_rect(cat_bbox,'red'))

���������ͺ����������ֶ����ӵ�����ê����,���ǽ�������Ŀ�ľ����Զ����Ӹ��ͬ�߶ȴ�С��ê��,������������feature map�еIJ�ͬ������
2.2 ����ê���Ŀ�����㷨
2.2.1 ��ôȥ����Ŀ����?
- ����������Ϊê�������(��Ե��)
- Ԥ��ÿ��ê�����Ƿ��й�ע������
- ���Ŀ��������ê��֮��,Ԥ������ê����ʵ��Ե��ƫ��
2.2.2 ����ѵ��ê��+�����ȱȽ�ê�����ƶ�
IoU-������:�����Ƚ�������֮������ƶ�
- 0 ��ʾ���ص�,1��ʾ�غ�
- ��Jacquardָ�����������ʽ��ʾ
J ( A , B ) = �O A ? B �O �O A ? B �O J(A,B) = \frac{|A \bigcap B|}{|A \bigcup B|} J(A,B)=�OA?B�O�OA?B�O?
2.2.3 ��ôȥ����ê����?
- ÿ��ê����һ��ѵ������
- ��ÿ��ê��,Ҫô��עΪ����,Ҫô������һ����ʵ��Ե��
- ���ǽ������ɴ�����ê��(�ᵼ�´����ĸ�������)
��Ե������ʵ�Ŀ�,��ê�������Ǽٶ��Ŀ�,��������֮���IoUֵ���,��ʾ�������ǿ��

���������ȡ����ѵĽ��
2.2.4 ʹ�÷Ǽ���ֵ����(NMS)���(ÿ�������һ����)
ÿ��ê��Ԥ��һ����Ե��
NMS���Ժϲ����Ƶ�Ԥ��
- ѡ���ǷDZ���������Ԥ��ֵ
- ȥ��������������IoUֵ���� �� \theta ����Ԥ��
- �ظ�����IJ���ֱ�����е�Ԥ��Ҫô��ѡ��Ҫô��ȥ��
2.3 ���ִ���ʵ��ê��
%matplotlib inline
import torch
from d2l import torch as d2l
torch.set_printoptions(2) # �����ӡ����
??��������ͼ��ĸ߶�Ϊ
h
h
h,����Ϊ
w
w
w��������ͼ���ÿ������Ϊ�������ɲ�ͬ��״��ê��:���� Ϊ
s
��
(
0
,
1
]
s\in (0, 1]
s��(0,1],���߱�(���߱�)Ϊ
r
>
0
r > 0
r>0����ôê��Ŀ��Ⱥ߶ȷֱ���
w
s
r
ws\sqrt{r}
wsr? ��
h
s
/
r
hs/\sqrt{r}
hs/r?�� ��ע��,������λ�ø���ʱ,��֪���ߵ�ê����ȷ���ġ� (��ʵ���Լ������Ƶ������Ŀ��ߺ������Ƶ��Ļ���̫��ͬ,�������ﻹ�ǰ���������Ľ�����еĴ����д!)
??Ҫ���ɶ����ͬ��״��ê��,����������һϵ�п̶�
s
1
,
��
,
s
n
s_1,\ldots, s_n
s1?,��,sn? ��һϵ�п��߱�
r
1
,
��
,
r
m
r_1,\ldots, r_m
r1?,��,rm?����ʹ����Щ�����ͳ����ȵ����������ÿ������Ϊ����ʱ,����ͼ���ܹ���
w
h
n
m
whnm
whnm ��ê������Щê����ܻḲ�����е�����ʵ�߽��,�����㸴���Ժ������ߡ�
��ʵ����,(����ֻ����)����
s
1
s_1
s1? ��
r
1
r_1
r1? ��(���:)
(
s
1
,
r
1
)
,
(
s
1
,
r
2
)
,
��
,
(
s
1
,
r
m
)
,
(
s
2
,
r
1
)
,
(
s
3
,
r
1
)
,
��
,
(
s
n
,
r
1
)
.
(s_1, r_1), (s_1, r_2), \ldots, (s_1, r_m), (s_2, r_1), (s_3, r_1), \ldots, (s_n, r_1).
(s1?,r1?),(s1?,r2?),��,(s1?,rm?),(s2?,r1?),(s3?,r1?),��,(sn?,r1?).??Ҳ����˵,��ͬһ����Ϊ���ĵ�ê���������
n
+
m
?
1
n+m-1
n+m?1��������������ͼ��,���ǽ�������
w
h
(
n
+
m
?
1
)
wh(n+m-1)
wh(n+m?1) ���
# ���ɶ��ê��
# ����ͼ�ߴ��б��������б�,�������е�ê��
def multibox_prior(data,sizes,ratios):
"""������ÿ������Ϊ���ľ��в�ͬ��״��ê��"""
in_height, in_width = data.shape[-2:]
device, num_sizes, num_ratios = data.device, len(sizes), len(ratios)
boxes_per_pixel = (num_sizes + num_ratios - 1)
size_tensor = torch.tensor(sizes, device=device)
ratio_tensor = torch.tensor(ratios, device=device)
# Ϊ�˽�ê���ƶ������ص�����,��Ҫ����ƫ������
# ��Ϊһ�����صĵĸ�Ϊ1�ҿ�Ϊ1,����ѡ��ƫ�����ǵ�����0.5
offset_h, offset_w = 0.5, 0.5
steps_h = 1.0 / in_height # Scaled steps in y axis
steps_w = 1.0 / in_width # Scaled steps in x axis
# ����ê����������ĵ�,�����˹�һ��
center_h = (torch.arange(in_height, device=device) + offset_h) * steps_h
center_w = (torch.arange(in_width, device=device) + offset_w) * steps_w
shift_y, shift_x = torch.meshgrid(center_h, center_w)
shift_y, shift_x = shift_y.reshape(-1), shift_x.reshape(-1)
# ���ɡ�boxes_per_pixel�����ߺͿ�,
# ֮�����ڴ���ê����Ľ����� (xmin, xmax, ymin, ymax)
w = torch.cat((size_tensor * torch.sqrt(ratio_tensor[0]),
sizes[0] * torch.sqrt(ratio_tensor[1:])))\
* in_height / in_width # Handle rectangular inputs
h = torch.cat((size_tensor / torch.sqrt(ratio_tensor[0]),
sizes[0] / torch.sqrt(ratio_tensor[1:])))
# ����2����ð�ߺͰ��
anchor_manipulations = torch.stack(
(-w, -h, w, h)).T.repeat(in_height * in_width, 1) / 2
# ÿ�����ĵ㶼���С�boxes_per_pixel����ê��,
# �������ɺ�����ê�����ĵ�����,�ظ��ˡ�boxes_per_pixel����
out_grid = torch.stack([shift_x, shift_y, shift_x, shift_y],
dim=1).repeat_interleave(boxes_per_pixel, dim=0)
output = out_grid + anchor_manipulations
return output.unsqueeze(0)
img = d2l.plt.imread('./data/Coco/catdog.jpg')
print("The shape of figure: {}".format(img.shape))
h, w = img.shape[:2]
print("The width of figure {} pixel,and the height of figure:{} pixel".format(w, h))
X = torch.rand(size=(1, 3, h, w))
# ���ǿ��Կ���[**���ص�ê����� `Y` ����״**]��(������С,ê�������,4)��
Y = multibox_prior(X, sizes=[0.75, 0.5, 0.25], ratios=[1, 2, 0.5])
Y.shape
The shape of figure: (561, 728, 3)
The width of figure 728 pixel,and the height of figure:561 pixel
torch.Size([1, 2042040, 4])
??��ê����� Y ����״����Ϊ(ͼ��߶ȡ�ͼ����ȡ���ͬһ����Ϊ���ĵ�ê�������,4)��,���ǾͿ��Ի����ָ�����ص�λ��Ϊ���ĵ�����ê���ˡ��ڽ�������������,����[������ (250, 250) Ϊ���ĵĵ�һ��ê��]�������ĸ�Ԫ��:ê�����Ͻǵ�
(
x
,
y
)
(x, y)
(x,y) ����������½ǵ�
(
x
,
y
)
(x, y)
(x,y) ���������������������ֱ����ͼ��Ŀ��Ⱥ߶Ⱥ�,���õ�ֵ�ͽ��� 0 �� 1 ֮�䡣
boxes = Y.reshape(h, w, 5, 4)
boxes[250, 250, 0, :]
tensor([0.06, 0.07, 0.63, 0.82])
#@save
def show_bboxes(axes, bboxes, labels=None, colors=None):
"""��ʾ���б߽��"""
def _make_list(obj, default_values=None):
if obj is None:
obj = default_values
elif not isinstance(obj, (list, tuple)):
obj = [obj]
return obj
labels = _make_list(labels)
colors = _make_list(colors, ['b', 'g', 'r', 'm', 'c'])
for i, bbox in enumerate(bboxes):
color = colors[i % len(colors)]
rect = d2l.bbox_to_rect(bbox.detach().numpy(), color)
axes.add_patch(rect)
if labels and len(labels) > i:
text_color = 'k' if color == 'w' else 'w'
axes.text(rect.xy[0], rect.xy[1], labels[i], va='center',
ha='center', fontsize=9, color=text_color,
bbox=dict(facecolor=color, lw=0))
??�������Ǹղſ�����,���� boxes ��
x
x
x ���
y
y
y �������ֵ�ѷֱ����ͼ��Ŀ��Ⱥ߶ȡ�����ê��ʱ,������Ҫ�ָ�����ԭʼ������ֵ�����,���������涨���˱��� bbox_scale ������,���ǿ��Ի��Ƴ�ͼ����������(250��250)Ϊ���ĵ�ê���ˡ�������ʾ,�߶�Ϊ 0.75 �ҿ��߱�Ϊ 1 ����ɫê��ܺõ�Χ����ͼ���еĹ���
d2l.set_figsize()
bbox_scale = torch.tensor((w, h, w, h))
fig = d2l.plt.imshow(img)
show_bboxes(fig.axes, boxes[250, 250, :, :] * bbox_scale, [
's=0.75, r=1', 's=0.5, r=1', 's=0.25, r=1', 's=0.75, r=2', 's=0.75, r=0.5'
])
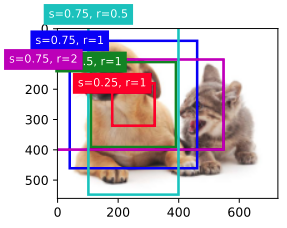
������߶�Ŀ����
3.1 ��߶�Ŀ��������
�ο�:
- https://www.zhihu.com/question/309488424
- https://zhuanlan.zhihu.com/p/54163567
- https://arxiv.org/abs/1809.02165
��߶�Ŀ���ⷽ�����Դ��·�Ϊ����:
- ���������������Ϻ����Ԥ��PVANET(NIPSW16)
- �ֱ��ڲ�ͬ�IJ����Ԥ��RFBnet(CVPR18)
- ����������ַ���FPN(CVPR17)

Faster R-CNN��Ӧͼb,SSD��Ӧͼc,FPN��Ӧͼd
�������Dz���SSD�ķ�����������,�����������һ�������feature map���з�����������������������Ϊ�������ɶ��ê��,561*728��ͼ��ÿ������5����С��ͬ��ê��,���ջ����ɳ���200���ê��
%matplotlib inline
import torch
from d2l import torch as d2l
img = d2l.plt.imread("./data/Coco/catdog.jpg")
h,w = img.shape[:2]
h,w
(561, 728)
3.2 ��߶��������ê������ʾ��
??������ͼ(fmap)������ê��(anchors),����ê���е�(x,y)������ֵ(anchors)�Ѿ�����������ͼ(fmap)�ĸ߶ȺͿ���,������Щֵ���ǽ���[0,1]֮���,��ʾ������ͼ��ê������λ�á�
??����ê��(anchors)�����ķֲ�������ͼ(fmap)�ϵ����е�λ,�����Щ���ı����������Կռ�λ�����κ�����ͼ���Ͼ��ȷֲ����������˵,��������ͼ�Ŀ��Ⱥ߶� fmap_w �� fmap_h ,���º����� ���ȵ� ���κ�����ͼ���� fmap_h �к� fmap_w ���е����ؽ��в�����
����Щ���Ȳ���������Ϊ����,�������ɴ�СΪ s(�����б� s �ij���Ϊ 1)�ҿ��߱�( ratios )��ͬ��ê��
def display_anchors(fmap_w, fmap_h, s):
d2l.set_figsize()
# ǰ����ά���ϵ�ֵ(batch_size,channels)��Ӱ�����
fmap = torch.zeros((1, 10, fmap_h, fmap_w))
anchors = d2l.multibox_prior(fmap, sizes=s, ratios=[1, 2, 0.5])
bbox_scale = torch.tensor((w, h, w, h))
d2l.show_bboxes(d2l.plt.imshow(img).axes, anchors[0] * bbox_scale)
# ����ê��ijߴ�߶�Ϊ0.15,����ͼ�ĸ߶ȺͿ�������Ϊ4
display_anchors(fmap_w=4, fmap_h=4, s=[0.15])

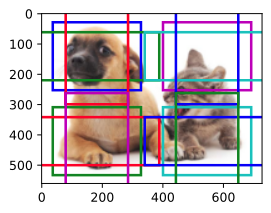
Ȼ��,����[������ͼ�ĸ߶ȺͿ��ȼ�Сһ��,Ȼ��ʹ�ýϴ��ê�������ϴ��Ŀ��]��
���߶�����Ϊ 0.4 ʱ,һЩê�˴��ص���
display_anchors(fmap_w=2, fmap_h=2, s=[0.4])
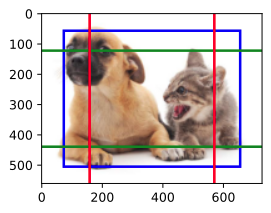
���,���ǽ�һ��[������ͼ�ĸ߶ȺͿ��ȼ�Сһ��,Ȼ��ê��ij߶����ӵ�0.8]��
��ʱ,ê������ļ���ͼ������ġ�
display_anchors(fmap_w=1, fmap_h=1, s=[0.8])
�ġ��ο�����
�������һ��Cite,��л�����λBlog������!!!
- ������Ƶ: https://space.bilibili.com/1567748478/channel/detail?cid=175509&ctype=0
- ������鼮(��汾����ѵ�Ŷ):https://zh-v2.d2l.ai/
- Ŀ�����������:https://zhuanlan.zhihu.com/p/34142321
- Ŀ��������֪ʶ:https://zhuanlan.zhihu.com/p/63024247
- ��߶�Ŀ����
