week 4
1 Movie rating data
1.1 Data precossing

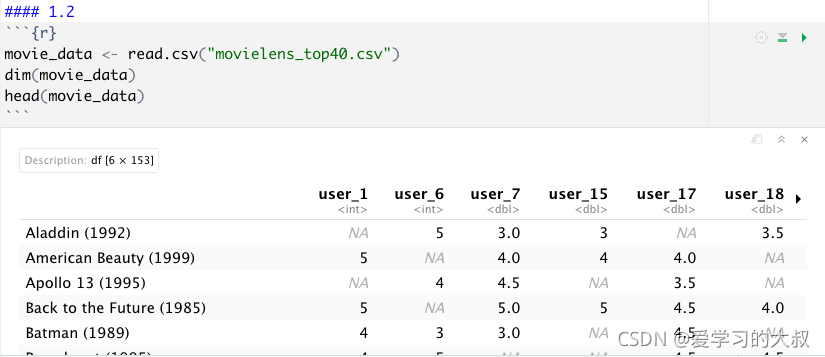
1.2 Data input and IDA
1.3 Hierarchical clustering
hclust(): Hierarchical ����,method��3��:complete,single,average



cutree(): ��tree�ͽṹ���м�֦,k�ǰ���ĸ�����֦,h�ǰ�tree�ĸ߶ȼ�֦��
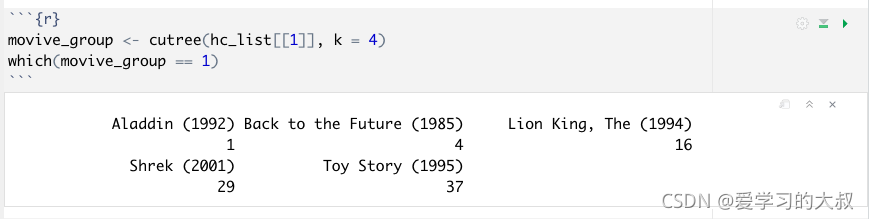

which��θ�ֵ:
ע��which��ֵǰ,Ӧ����as.matrixת����matrix,�ٸ�ֵ

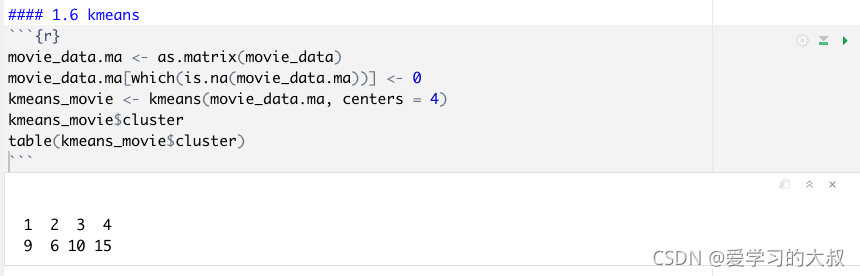
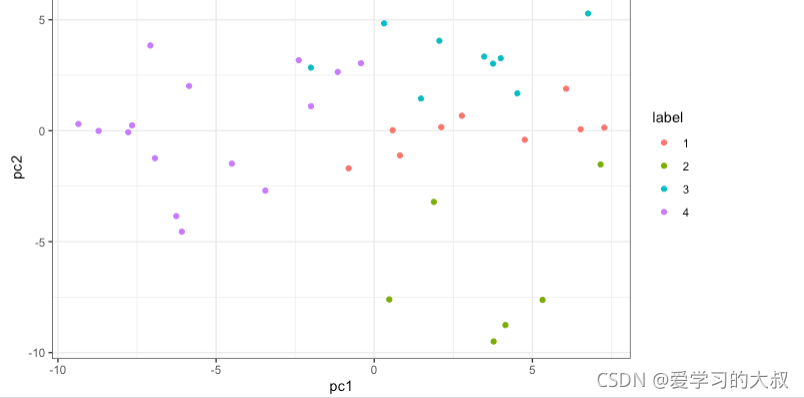
1.6 Kmeans

table(): ������ͬ���ӵĸ���ͳ��ֵ��
kmeans(): Kmeans�����,centre������k,Ҳ���������ĵ㡣

prcomp(): pca�ķ���,ע��scale=T
���ڻ�ͼ:
Ҫ��ͼ,ע����ת��dataframe
label����Ҫ��factor
col���ܷ�������,ֻ�з�������Żᰴlabel����

1.7 Cluster statistics

lapply��sapply������: sapply����һ��list,lapply����һ��2άlist��
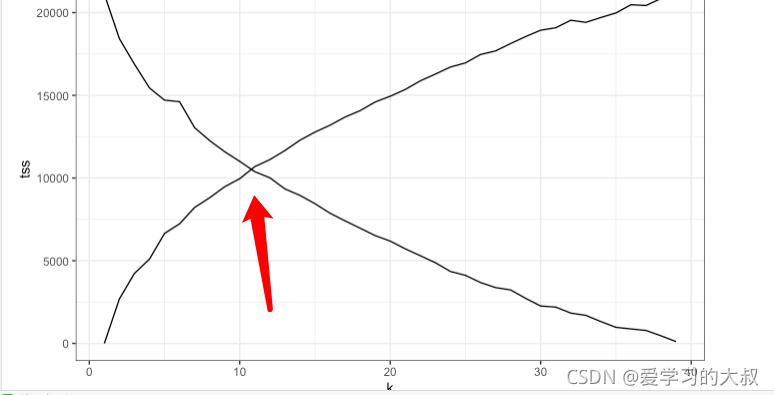
tot.withinss: �����ܺ�,sum(withinss)
betweenss: ����ƽ����,totss �C tot.withinss
Ѱ������������ƽ���,Ӧ������õ�k


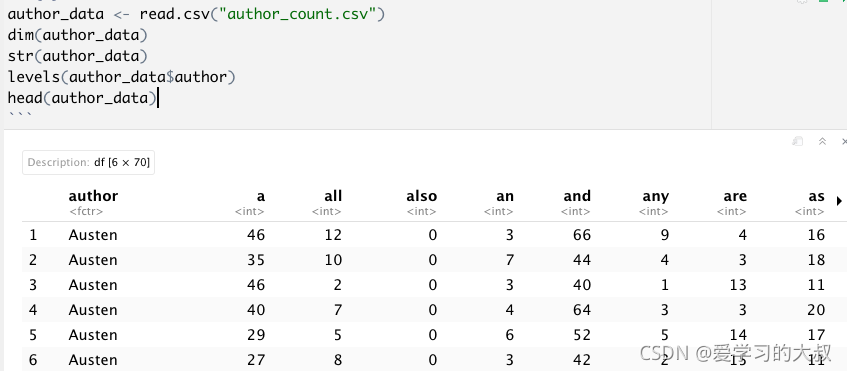
2 Author by word count
2.1 Data Input

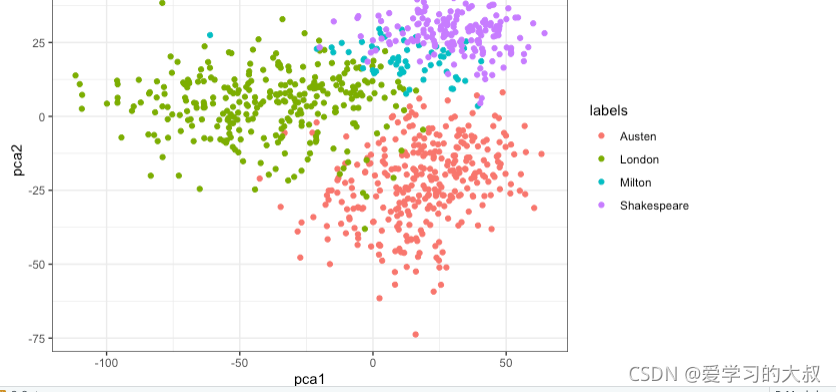
2.2 PCA

2.3 t-SNE

t-SNE t�ֲ��������Ƕ����һ������̽����ά���ݵ���������ά�㷨��
Rtsne: ע�������perplexity���ҳ̶�,���Ե�,Ĭ��dims��2ά��ҪȡY��ֵ,����ȡ��pca��
Ҫ��ͼ��תdata frame
ggplot�ӱ�����ggtitle��
һ��ͼ���õ�lapply����

2.4 MDS

������ͬ������distance

cmdscale(): ����mds
������ҪҪ��attr,����֮���method��ͼ


2.5 Compare and contrast

