知识图谱本质上是一种图结构,在图内部数据规模大且质量高、外部算力足够的情况下,充分利用好图算法,能够最大程度地发挥出其数据价值。实际上,图(Graph)是一个常见的数据结构,现实世界中有很多很多任务可以抽象成图问题,比如社交网络,蛋白体结构,交通路网数据,以及很火的知识图谱等,甚至规则网络结构数据(如图像,视频等)也是图数据的一种特殊形式。而随着数据多样性的发展,图计算已经成为业界的一个重要的研究方向,其中图神经网络广泛应用于图的表征学习,与传统的图学习相比,既能学习图网络的拓扑结构,也能聚合邻居特征,从而能够有效的学习到图网络中的信息,为后续的推荐工作起到关键作用。
一、图模型的典型应用场景
图模型的应用场景可以分为:节点分类、链接预测、聚类、推荐等几类。其中,节点分类旨在基于其他标记的节点和网络拓扑来确定节点的标签(也称为顶点)。链路预测是指预测缺失链路或未来可能出现的链路的任务。聚类用于发现相似节点的子集,并将它们分组在一起;推荐场景则根据节点特征以及其他特征进行搜索推荐。
1、搜索推荐场景
推荐场景是图模型的一个典型应用。例如,在社交人物中的推荐场景中,可以通过一些图结构结合一些算法,比如典型的pagerank算法,找到关键人物,通过对关键人物采取特定性策略(比如定向推广)以提升推荐效果,也可以基于地理、人物任务关系、兴趣爱好组成的圈子,进行产品和广告的推荐。
2、团伙挖掘场景
关联关系识别团伙,无监督方法:通过连通子图算法识别出一个个连通的社区,如果社区规模较大,可能背后业务含义是黑产控制一批账户。 定义社区规模为score,通过调节阈值来控制误杀、召回。
有监督方法-传统:等价为节点分类问题,通过提取节点业务特征、拓扑特征、所属社区特征,训练一个机器学习模型(如GBDT)去预测。有监督方法-图神经网络,将节点业务特征X与网络拓扑结构A作为输入学习函数 ,用于对未知数据的预测。
3、链接预测场景
链路预测场景中主要完成的是对网络中的两个节点是否可能存在链路进行预测。例如,在推荐系统中,我们推荐的是高度“连接”的产品。可以用GNN训练模型来预测这种链路是否存在。
4、节点分类场景:
与序列自然语言处理类似,图模型还可以应用应用于主题文本分类,包括新闻分类、Q&A、搜索结果组织等。
二、图的概念与主要类型
“图”是一种直观自然的数据结构,在数学上表示成G=(V, E),
从图的属构成上看,图可以分成连通图与非连通、未加权图与加权图、有向图与无向图、非循环图和循环图等多种类型。其中: 1)连通图与非连通图。 连通图(Connected Graphs)指图内任意两个节点间,总能找到一条路径连接它们,否则,为非连通图(Disconnected Graphs);2)未加权图与加权图。**未加权图(Unweighted Graphs)的节点和边上均没有权重,对于加权图(Weighted Graphs),所加权重可以代表成本、时间、距离、容量、甚至是指定域的优先级;3)有向图与无向图。**在无向图(Undirected Graphs)中,节点的关系是双向的(bi-directional),如朋友关系,而在有向图(Directed Graphs)中,节点的关系可以指定方向,边如果指向了一个节点,称为 in-link,边如果从一个节点出发,则称为 out-link;4)非循环图和循环图。*图论中,循环指一些特殊的路径,它们的起点和终点是同一个节点。在非循环图(Acyclic Graph)中,不存在循环路径,相反则为循环图(Cyclic Graphs)。
2、节点关系分类下的图类型
根据节点关系的不同,可以将分类下的图类型主要包括同构图(Homogeneous graph),二部图(Bipartile graph)和异构图(Heterogeneous graph)。1)同构图:**同构图是一个最简单的图类型,图中所有的节点(node)类型和边(edge)类型都只有一种。常见的图算法基本是作用在同质图中,图中的节点类型和关系类型都仅有一种。2)二部图:**二部图中只有两种类型的节点,并且一种类型的节点只会对另一种类型的节点产生关系。如传统的推荐系统中用户与物品的形成的关系图就是二部图。3)异构图:**异构图中可包含多种类型节点和多种关系,相比同构图可以提供更多的信息,减少了冗余边,并且能展示更好的连接关系。比如在风险中我们的交易图。在交易发生过程中会使用到很多实体(图上表现为节点),除了交易本身,比如IP邮箱、邮寄地址、设备ID等都是图上的节点。
三、图模型的典型算法
1、图的路径搜索(生成)
图搜索算法(Pathfinding and Search Algorithms)旨在探索一个图,用于一般发现或显式搜索,这些算法通过从图中找到很多路径,但并不期望这些路径是计算最优的(例如最短的,或者拥有最小的权重和),在实现上包括广度优先搜索和深度优先搜索,它们是遍历图的基础,并且通常是许多其他类型分析的第一步。
路径搜索算法,具体可进一步分为DFS(深度优先遍历) & BFS(广度优先遍历)、最短路径、最小生成树、随机游走算法等。最短路径(Shortest Paths)算法和随机游走算法(Random Walk)是其中的两个重要概念。
最短路径(Shortest Paths)算法计算给定的两个节点之间最短(最小权重和)的路径,能够给出关系传播的度数(degree)以及两点之间的最短距离,并计算两点之间成本最低的路线。这个在networkx、neo4j等图数据库中进行节点关联分析等场景中有直接应用。
随机游走(Random Walk)算法从图上获得一条随机的路径,该算法从一个节点开始,随机沿着一条边正向或者反向寻找到它的邻居,以此类推,直到达到设置的路径长度,一般用于随机生成一组相关的节点数据,作为后续数据处理或者其他算法使用。例如随机游走生成的序列,可以作为node2vec 和 graph2vec 算法的一部分,用于节点向量的生成,从而作为后续深度学习模型的输入,也可以作为 Walktrap 和 Infomap 算法的一部分,用于社群发现。如果随机游走总是返回同一组节点,表明这些节点可能在同一个社群,也可以作为其他机器学习模型的一部分,用于随机产生相关联的节点数据。
2、图的中心性(重要性)计算
图的中心性算法(Centrality Algorithms)用于识别图中特定节点的角色及其对网络的影响,能够帮助识别最重要的节点,包括节点的可信度、可访问性、事物传播的速度以及组与组之间的连接。在实现上,图的中心度算法包括DegreeCentrality、 ClosenessCentrality、BetweennessCentrality、PageRank几种。 其中:
度中心性(Degree Centrality) 表示连接到某节点的边数,一个节点的节点度越大就意味着该节点在网络中就越重要;接近中心性(Closeness Centrality)从某节点到所有其他节点的最短路径的平均长度,以此反映在网络中某一节点与其他节点之间的接近程度;介中心性(Betweenness Centrality)表示某节点在多少对节点的最短路径上,能够反映相应的节点或者边在整个网络中的作用和影响力。
PageRank 算法是所有的中心性算法中最为出名的一个,并在当前的网页排名,文本关键词抽取中使用十分广泛。该算法统计到节点的传入关系的数量和质量,从而决定该节点的重要性,不但考虑节点的直接影响,也考虑 “邻居” 的影响力。例如,一个节点拥有一个有影响力的 “邻居”,可能比拥有很多不太有影响力的 “邻居” 更有影响力。例如,在网页排名当中,不同的网页之间相互引用,网页作为节点,引用关系作为边,就可以组成一个网络,被更多网页引用的网页,应该拥有更高的权重;被更高权重引用的网页,也应该拥有更高权重。在文本中,通过相似度将不同的句子或者关键词作为节点进行连接,通过 PageRank思想的变体textrank也可以得到相应重要的词语或者句子,完成关键词提取或者摘要生成的任务。
3、图的社群发现(划分)
社群发现算法,又称社团发现,其目标就是将节点准确地划分至不同的社团中, 形成不同的聚类簇,簇内部连边稠密、与外部连边稀疏的节点,这些聚簇也就是社团(Community),这一算法对于识别社群对于评估群体行为或突发事件十分关键。对于一个社群来说,内部节点与内部节点的关系(边)比社群外部节点的关系更多。识别这些社群可以揭示节点的分群,找到孤立的社群,发现整体网络结构关系。在具体实现上,包括MeasuringAlgorithm、ComponentsAlgorithm、 LabelPropagation Algorithm、 LouvainModularity Algorithm等算法,其中, LabelPropagation Algorithm、 LouvainModularity Algorithm算法使用较多。
标签传播算法是一种社群快速发现的算法,该算法认为节点的标签完全由它的直接邻居决定,在初始阶段,标签传播算法对于每一个节点都会初始化一个唯一标签,每一次迭代都会根据与自己相连的节点所属的标签改变自己的标签,更改的原则是选择与其相连的节点中所属标签最多的社区标签为自己的社区标签,随着社区标签不断传播,最终连接紧密的节点将有共同的标签,每个节点都有一个标识其所属社团的标签,也就完成了社团划分。计算结果的高随机性,重复运行两次 LPA 的社团划分结果往往并不一致。
Louvain Modularity 算法,非常适合庞大网络的社群发现,算法采用启发式方式从而能够克服传统 Modularity 类算法的局限。这类算法可以用于检测网络攻击,在大规模网络安全领域中进行快速社群发现,并以来预防网络攻击,也可以用于主题建模,如从 在线社交平台中提取主题,基于文档中共同出现的术语,作为主题建模过程的一部分。
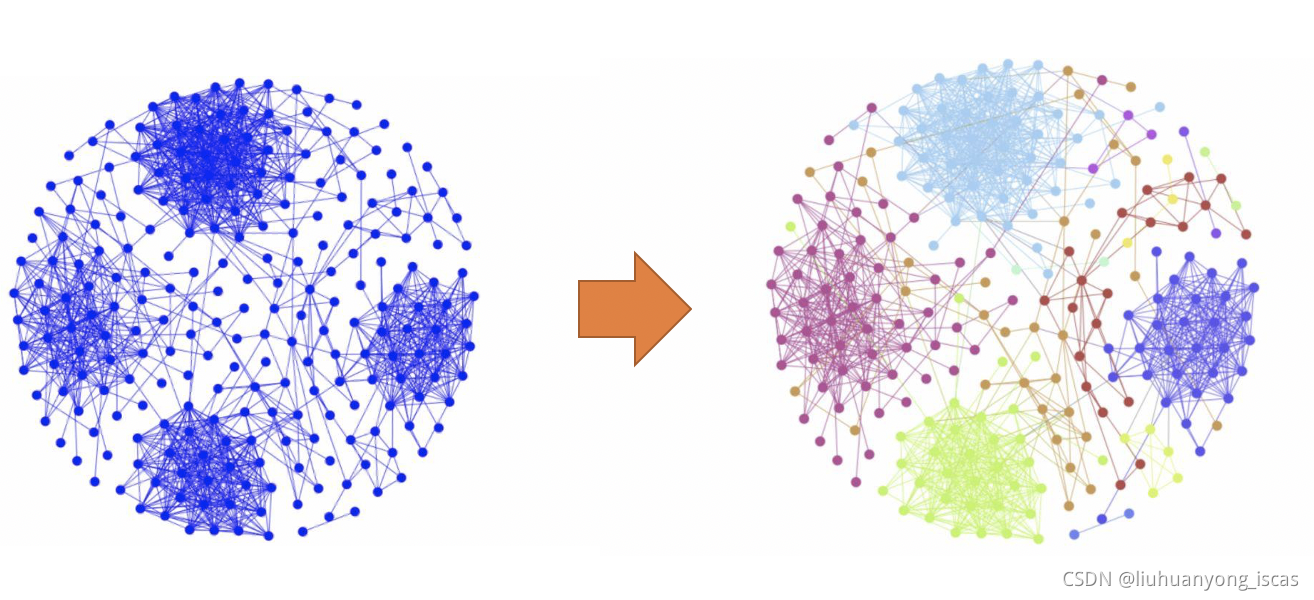
四、基于图的嵌入算法
图的嵌入学习是将机器或深度学习算法应用于图网络的重要前提。图嵌入,又称Graph Embedding(GE,Network Embedding),是一种将图数据(通常为高维稠密的矩阵)映射为低微稠密向量的过程,是将节点和关系进行数值化的重要方式,其思想在于把图中的节点或者边嵌入到一个低维的向量空间中,且节点或边在该低维空间的关系能比较完整地保留原图的结构信息,以解决图数据难以高效输入机器学习算法的问题。图形嵌入领域已经有了大量的研究,大体上分为三大类:基于因子分解的方法、基于随机游走的方法以及基于深度学习的方法。基于随机游走的嵌入学习先进行图的结构学习,再与属性特征融合进行下游任务学习,学习任务是割裂的,图神经网络的结构学习和下游任务是端对端的一个学习过程,比起割裂的学习更加高效,性能也更好。
1)基于因子分解的图嵌入
图分解(Graph Factorization)使用邻接矩阵的近似分解作为嵌入。LINE扩展了这种方法,并试图保持一阶和二阶近似。HOPE通过使用广义奇异值分解( SVD )分解相似性矩阵而不是邻接矩阵来扩展LINE以试图保持高阶邻近性。SDNE 使用自动编码器嵌入图形节点并捕捉高度非线性的依赖关系。
2)基于随机游走的图嵌入
做过自然语言处理的朋友都知道,word2vec 是一种常用的 word embedding 方法,其通过语料库中的句子序列来描述词与词的共现关系,进而学习到词语的向量表示,Graph Embedding 采用了类似 的的思想,使用图中节点与节点的共现关系来学习节点的向量表示,其首先在 graph 中随机游走生成顶点序列,构成训练集,然后采用 skip-gram 算法,训练出低维稠密向量来表示顶点。GE类的算法本质上就是将低阶特征进行Embedding化,业界常用的有DeepWalk、Node2Vec(基于拓扑结构的)、LINE(加入属性信息的)、EGES、以及通过标签信息和随机性共同考虑去做的图剪辑。Perozzi等人在KDD 2014提出的DeepWalk模型是图嵌入学习的一个开山之作,该方法采用截断式随机游走方式把图中每个节点的局部拓扑结构转换成序列信息,并把Word2vec模型应用于阶段一产生的序列数据,学习序列中每个节点的embedding表示。图嵌入这种做法通常适用于无监督学习,其监督信号与最终目标通常不一致,只适用于多阶段训练。也没有充分发掘高阶的潜在关联关系。
3)基于图神经网络的图嵌入
图神经网络,又称(Graph Neural Networks,GNN),指在图上利用图神经网络,通过端对端的方式,在一个学习过程中进行任务学习。图神经网络在学习的过程中,可以分为信息传递和信息聚合两个阶段,前者通过对邻居节点的Embedding进行消息传递,后者对邻居节点的Embedding进行聚合处理, 不同的GNN对应的聚合方式会有不同, 譬如取均值,加权求和,做基于长短期记忆(LSTM)变换处理。
根据消息的聚合方式不同,目前有图卷积网络GCN、GraphSage、图注意力机制GAT等常见的消息聚合方式。其中:图卷积网络(GCN)是对邻居的Embedding取均值然后与目标节点的Embedding进行加权求和;GraphSage在K-hop的随机采样的子图上对其邻居进行广义的聚合,然后与目标节点的Embedding进行拼接,其聚合方式包括取均值、池化操作以及LSTM计算等;图注意力机制(GAT)认为不同的邻居节点其重要性是不同的,在具体聚合的过程中根据注意力机制,首先计算目标节点和邻居节点的注意力系数,然后把注意力系数标准化后的值作为权重。
实际上,图嵌入的目标是发现高维图的低维向量表示是一件极具挑战的事情,与word2vec一样,如何选择一个质量高的嵌入表示,直接决定了下游任务的精度,一个好的图嵌入,需要从属性选择、可扩展性以及维数等多个方面进行考虑。例如,在属性选择上,节点的“良好”向量表示应保留图的结构和单个节点之间的连接。在实际嵌入时很难找到表示的最佳维数,较高的维数可能会提高重建精度,但具有较高的时间和空间复杂性。较低的维度虽然时间、空间复杂度低,但无疑会损失很多图中原有的信息。
五、开源图算法或模型工具
幸运的是,目前已经陆续开源出来了一些可以即插即用的图算法代码、工具或者框架,这为我们进行快速的实验、效果验证、工程落地提供了有利的条件。通过收集整理,下面列举了当前较为流行的图表示学习与计算框架、知识图谱表示学习框架。
1、图表示学习与计算框架
**1)PyTorch Geometric(PyG):**由德国多特蒙德工业大学研究者推出的基于PyTorch的几何深度学习扩展库。PyG在学术中是比较热门的框架,但是PyG对于异构图以及大规模的图的学习存在着较大的局限性。地址:https://github.com/rusty1s/pytorch_geometric、https://pytorch-geometric.readthedocs.io/
**2)tf_geometric:**受到PyG启发,为GNN创建了TensoFlow版本。在其Github开源的demo中,可以看到GAE、GCN、GAT等主流的模型已经实现。地址:https://github.com/CrawlScript/tf_geometric;https://tf-geometric.readthedocs.io/
**3)Deep Graph Library(DGL):**由New York University(NYU)和Amazon Web Services(AWS)联合推出的图神经网络框架。如今已发布至0.4版本的DGL更是全面上线对于异质图支持模块,复现并开源了相关异质图神经网络的代码,如HAN、Metapath2vec等,此外,DGL也发布了训练知识图谱嵌入专用包DGL-KE,并在许多经典的图嵌入模型上进一步优化了性能。地址:https://github.com/dmlc/dgl;https://docs.dgl.ai/
**4) CogDL:**清华大学知识工程研究室推出了一个大规模图表示学习工具包 CogDL,可以让研究者和开发者更加方便地训练和对比用于节点分类、链路预测以及其他图任务的基准或定制模型。该工具包采用 PyTorch 实现,集成了Deepwalk、LINE、node2vec、GraRep、NetMF、NetSMF、ProNE 等非图神经网络和GCN、GAT、GraphSage、DrGCN、NSGCN、GraphSGAN 等图神经网络模型基准模型的实现。地址:https://github.com/THUDM/cogdl
5)GraphEmbedding: github上开源的图embedding算法实现,包括DeepWalk、LINE、Node2Vec、SDNE和Struc2Vec。地址:https://github.com/shenweichen/GraphEmbedding。
**6)Spark GraphX:**企业对庞大网络中社区结构的洞察需求也越发迫切,基于分布式架构的图处理引擎应运而生,比如Google的Pregel, Apache的开源的图计算框架Giraph,以及卡内基梅隆大学主导的GraphLab等。Spark GraphX是一个分布式图处理框架,它是基于Spark平台针对图计算和图挖掘提供了简洁、易用、丰富的接口,包括连通子图算法、标签传播算法和louvain算法。极大的方便了对分布式图处理任务的需求。地址:http://spark.apache.org/graphx/
7)networkx: networkx是一个用Python语言开发的图论与复杂网络建模工具,内置了常用的图与复杂网络分析算法,可以方便的进行复杂网络数据分析、仿真建模等工作。利用networkx可以以标准化和非标准化的数据格式存储网络、生成多种随机网络和经典网络、分析网络结构、建立网络模型、设计新的网络算法、进行网络绘制,通常配合matplotlib一同使用。地址:https://networkx.org
8)Plato: 图计算的发展和应用有井喷之势,各大公司也相应推出图计算平台,例如Google Pregel、Facebook Graph、阿里GraphScope等。Plato是腾讯开源的一款高性能图计算框架。Plato 的算法库中的图特征、节点中心性指标、连通图、社团识别、图表示学习等多种算法都已经开源。地址:https://github.com/tencent/plato
2、知识图谱表示学习框架

**1)DGL-KE:**亚马逊 AI 团队继 DGL 之后,又开源了一款专门针对大规模知识图谱嵌入表示的新训练框架 DGL-KE,旨在能让研究人员和工业界用户方便、快速地在大规模知识图谱数据集上进行机器学习训练任务。相比于已有的开源框架,基于Pytorch或MXNet的高性能大型图嵌入开源框架,其测评训练速度远快于Pytorch-BigGraph。此外,DGL-KE 支持各种主流知识图谱表示学习算法,包括 TransE、ComplEx、DistMult、TransR、RESCAL、RotatE 等。地址:https://github.com/awslabs/dgl-ke
2)OpenKE: OpenKETHUNLP基于TensorFlow、PyTorch开发的用于将知识图谱嵌入到低维连续向量空间进行表示的开源框架。OpenKE提供了快速且稳定的各类接口,也实现了诸多经典的知识表示学习模型,提供了大规模知识图谱的预训练向量,可以直接在下游任务中使用。地址:https://github.com/thunlp/OpenKE
3)Pytorch-BigGraph: PyTorch-BigGraph(PBG)是faccebook发布的一个分布式系统,用于学习大型图的图形嵌入,特别是具有多达数十亿个实体和数万亿条边的大型Web交互图。地址:https://github.com/facebookresearch/PyTorch-BigGraph
4)GraphVite: GraphVite是通用的图形嵌入引擎,专用于各种应用中的高速和大规模嵌入学习,其全部由C++实现,但目前支持的包括transE、RotateE、DeepWalk、Line、node2vec等模型。地址:https://github.com/DeepGraphLearning/graphvite
5)pykg2vec: pykg2vec是一个集成了当前大部分主流KGE算法的开源库,其基于Pytorch实现,代码结构比较清晰,适合用于KGE算法实现的学习。地址:https://github.com/Sujit-O/pykg2vec。
六、参考文献
1、https://mp.weixin.qq.com/s/svmhGL2i-U0NZRXazcl2pg
2、https://mp.weixin.qq.com/s/jb8c3e1HZn3uLL870rhqUw
3、https://blog.csdn.net/weixin_39526706/article/details/112655303?utm_source=app&app_version=4.15.1
4、https://mp.weixin.qq.com/s/6Obc3RNv5kkz2OEuIwN4SA
5、https://zhuanlan.zhihu.com/p/354867179
6、https://www.cnblogs.com/alan-blog-TsingHua/p/10924894.html
7、https://zhuanlan.zhihu.com/p/100586855
8、https://www.zhuanzhi.ai/document/7913eba0f04d30040b693dd7238d2601
关于作者
刘焕勇,liuhuanyong,现任360人工智能研究院算法专家,前中科院软件所工程师,主要研究方向为知识图谱、事件图谱在实际业务中的落地应用。
得语言者得天下,得语言资源者,分得天下,得语言逻辑者,争得天下。
1、个人主页:https://liuhuanyong.github.io。
2、个人博客:https://blog.csdn.net/lhy2014/。
欢迎对自然语言处理、知识图谱、事件图谱理论技术、技术实践等落地应用的朋友一同交流。