自然语言处理NLP星空智能对话机器人系列:深入理解Transformer自然语言处理 GLUE CoLA
目录
Transformer下游任务继承了模型和来自预训练transformer模型的参数,模型将不断发展,数据库、基准方法、精度测量也将不断发展.
General Language Understanding Evaluation (GLUE)
通用语言理解评估(GLUE)基准是用于训练、评估和分析自然语言理解系统的资源集合。


GLUE包括:
- 九个句子或句子对语言理解任务的基准,建立在已建立的现有数据集上,并选择涵盖各种数据集大小、文本类型。
- 诊断数据集,用于评估和分析自然语言中发现的各种语言现象的模型性能
- 用于跟踪基准性能的公共排行榜和用于可视化诊断集模型性能的仪表板。
GLUE基准的格式是模型不可知的,因此任何能够处理句子和句子对并生成相应预测的系统都有资格参与。选择基准任务是为了有利于使用参数共享或其他迁移学习技术在任务之间共享信息的模型。GLUE的最终目标是推动通用和健壮的自然语言理解系统的开发研究。
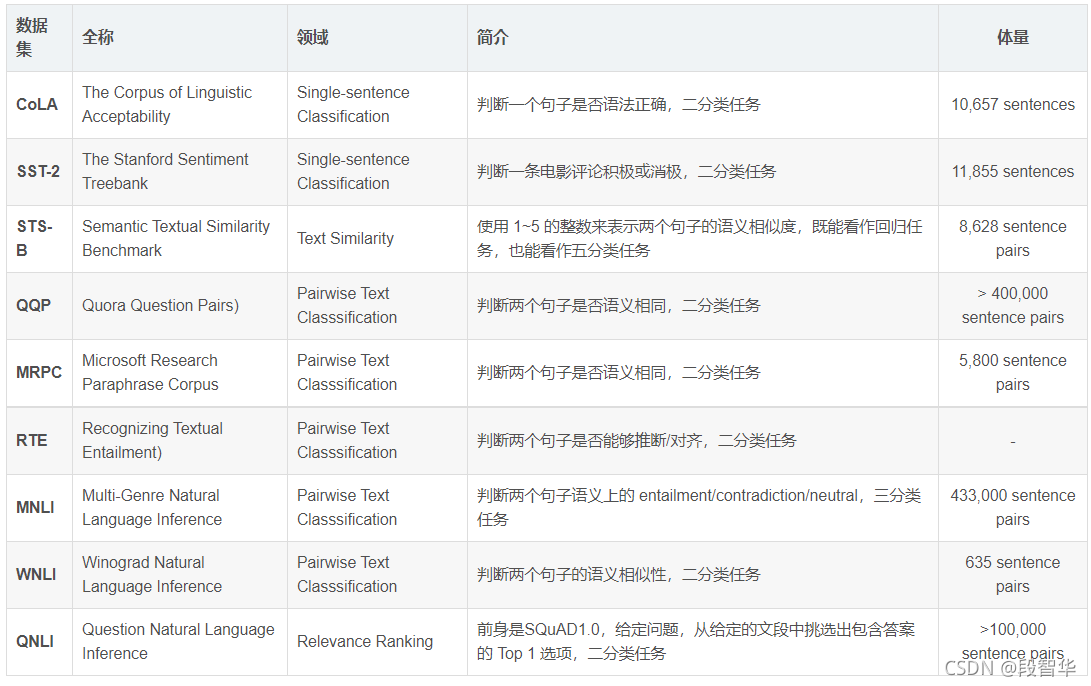
The Corpus of Linguistic Acceptability (CoLA)
Corpus of Linguistic Acceptability (CoLA) 语言可接受性语料库(CoLA),一项GLUE任务,https://gluebenchmark.com/tasks,包含数千个英文样本, 用于单句的二分类问题, 判断一个英文句子在语法上是不是可接受的。
Alex Warstadt et al. (2019)的目标是评估NLP模型的语言能力,以判断句子的语言可接受性。句子被标注为合乎语法或不合语法:
- 如果句子在语法上不可接受,则标签为0。
- 如果句子在语法上是可以接受的,则标签为1。
Classifi cation = 1 for 'we yelled ourselves hoarse.'
Classifi cation = 0 for 'we yelled ourselves.'
我们在博客自然语言处理NLP星空智能对话机器人系列:深入理解Transformer自然语言处理 基于BERT模型微调实现句子分类 使用了CoLA数据
#@title Loading the Dataset
#source of dataset : https://nyu-mll.github.io/CoLA/
df = pd.read_csv("in_domain_train.tsv", delimiter='\t', header=None,
names=['sentence_source', 'label', 'label_notes', 'sentence'])
df.shape
加载了预训练BERT模型
#@title Loading the Hugging Face Bert Uncased Base Model
model = BertForSequenceClassification.from_pretrained("bert-baseuncased",
num_labels=2)
使用的评估指标是Matthews Correlation Coeffi cient (MCC)
星空智能对话机器人系列博客
-
NLP星空智能对话机器人系列:深入理解Transformer自然语言处理 多头注意力架构-通过Python实例计算Q, K, V
-
NLP星空智能对话机器人系列:深入理解Transformer自然语言处理 多头注意力架构 Concatenation of the output of the heads
-
NLP星空智能对话机器人系列:深入理解Transformer自然语言处理 位置编码(positional_encoding)
-
NLP星空智能对话机器人系列:深入理解Transformer自然语言处理 KantaiBERT ByteLevelBPETokenizer
-
NLP星空智能对话机器人系列:深入理解Transformer自然语言处理 KantaiBERT Initializing model
-
NLP星空智能对话机器人系列:深入理解Transformer自然语言处理 KantaiBERT Exploring the parameters
-
NLP星空智能对话机器人系列:深入理解Transformer自然语言处理 KantaiBERT Initializing the trainer
-
NLP星空智能对话机器人系列:深入理解Transformer自然语言处理 KantaiBERT Language modeling with FillMaskPipeline