1?transformer的encoder-decoder结构:
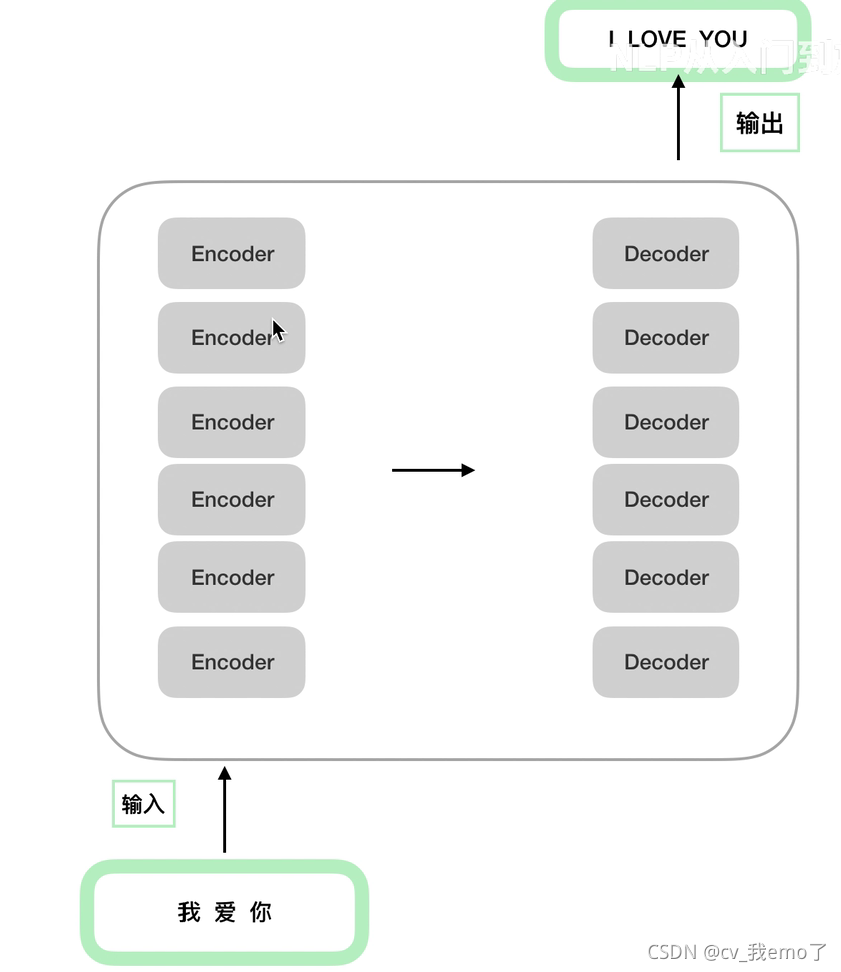
结构内部:
?
2?encoder:

2.1? 输入部分
embedding和postitional encoding(位置编码)
?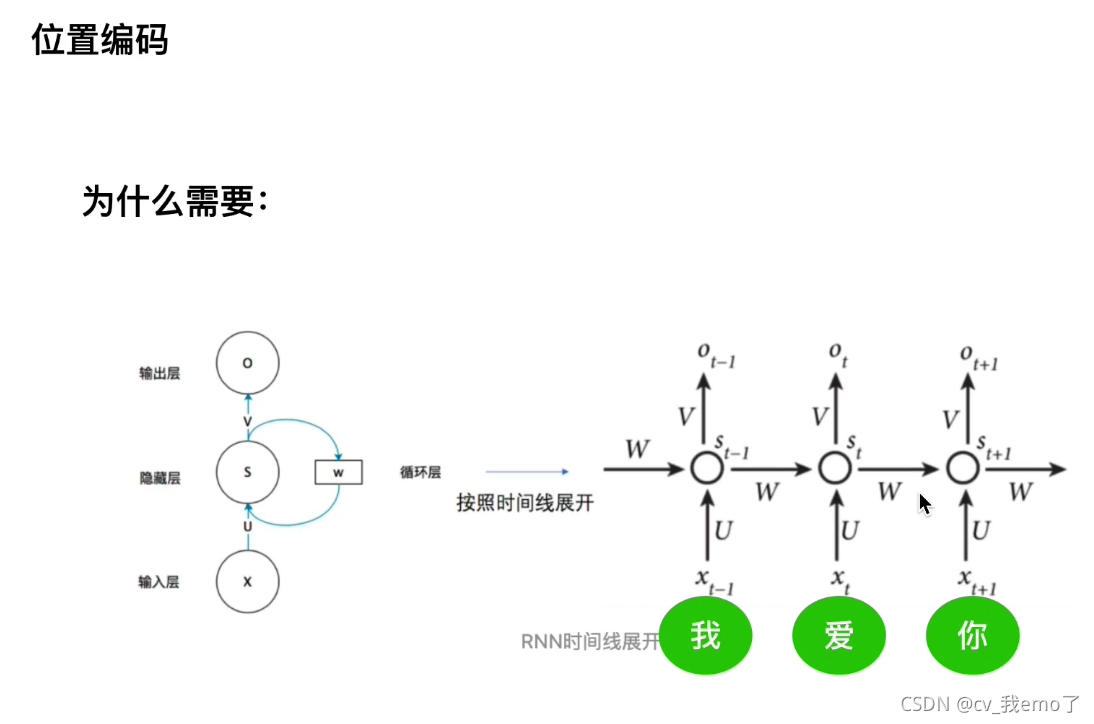
为什么需要位置编码:如RNN每一time steps共享一套参数,串行输入输出,而transformer采用可以并行出入几个单词或者一串句子,优点是处理效率高,缺点是无法表示时序关系,所以要对输入的embedding加上postitional encoding。

?最终输入的数据:
?2.2?注意力机制
?2.2.1 基本的注意力机制

cv中:

?如上图,判断婴儿和(左上、左下、右上、右下)四个区域哪个点乘的结果越大说明:距离越靠近越相似也就是越关注,再和V相乘得到attention value。
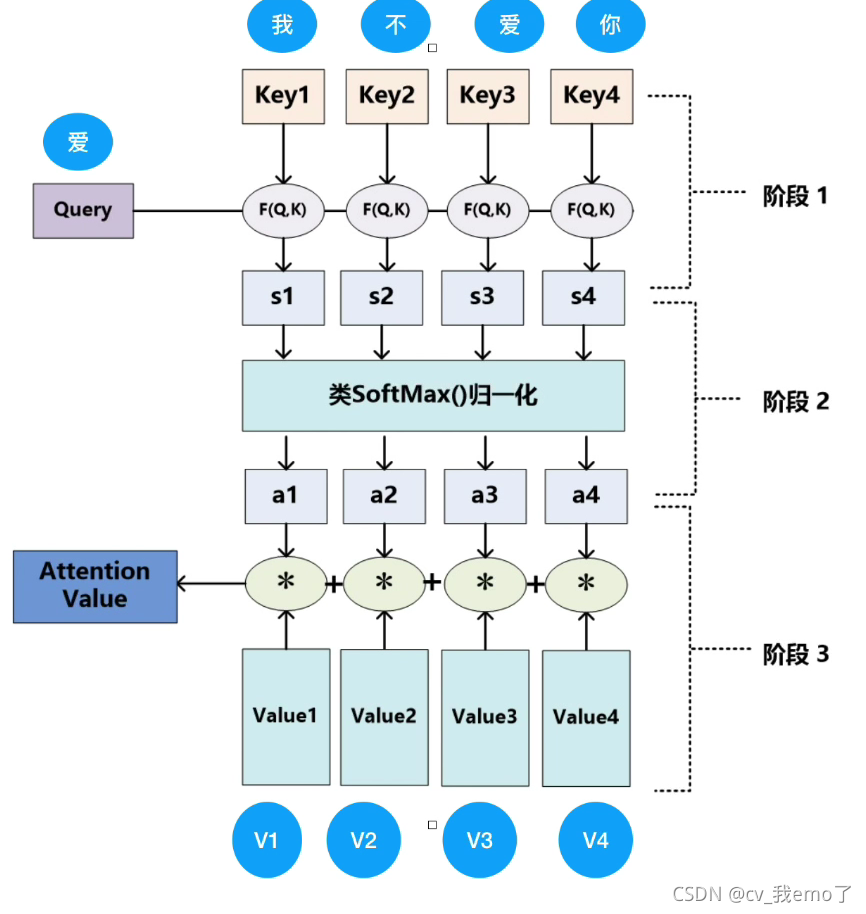
?nlp中:

?
?2.2.2?TRM中的注意力
通过三个权重矩阵WQ,WK,WV和x点乘得到q,k,v,如下图:
?
q*k得到score,除以8(由上面的注意力公式可知,如果q*k值很大,softmax在反向传播时的值就很小,所以除8避免梯度消失)。
比如下图第一个单词thinking,对应的q1、k1、v1,q1*k1/8=14,q1*k1/8=12,...,softmax之后再和每一个v1,v2,...相乘,再求和作为thinking输出z1。
?
?



?Multi-head Attention整体流程:
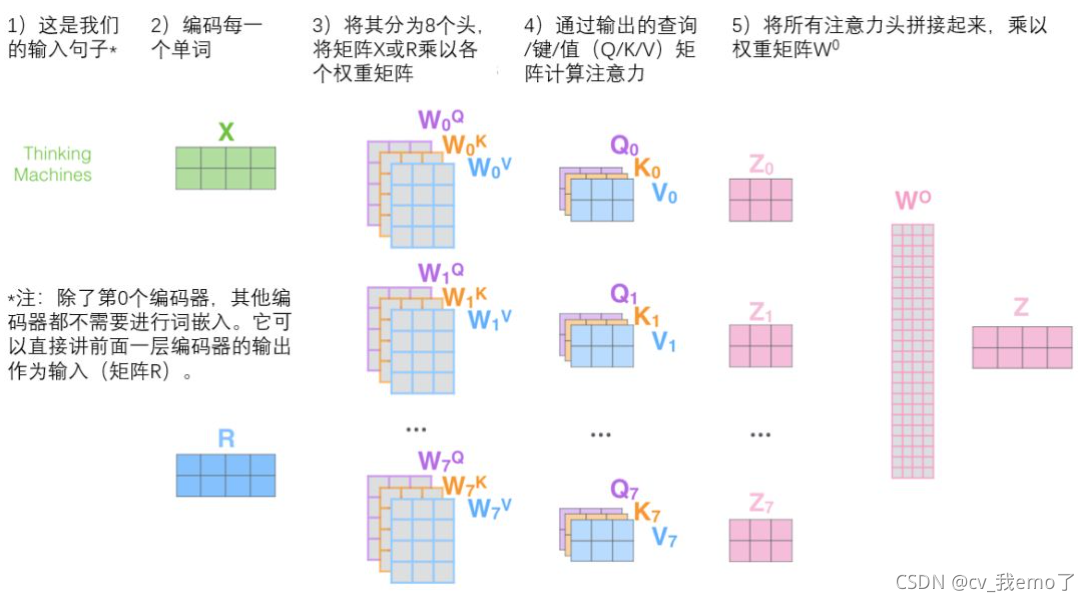
?2.2.3残差和LayNorm
?
?为什么用残差网络(为什么残差网络可以把网络做的很深):?加了个1,所以缓解了梯度消失。

为什么用layer normal:BN在nlp中不太适用,LN更适合nlp中的序列信息。都是为了让网络收敛的更快。BN是对每个特征x1,x2,...做均值方差,LN是对序列做均值方差。
如下图,LN是对‘我爱中国共产党’做均值方差;BN是对‘我’‘今’做,对于同一类的特征(比如体重、身高等)可以用,在nlp中就不适用了。
?
?2.3 前馈神经网络
?
?feed forward:两层的全连接。
?3 decoder
?decoder和encoder有以下一些不同:
?
?3.1 masked multi-head attention
?
?为什么mask:遮盖掉后面的词,模拟真实的预测过程。
?3.2 交互层:
?encoder输出的值去和每一个decoder交互:

?encoder的输出生成的是k,v矩阵,q矩阵来自于decoder:
?
?注:encoder的q是embedding来的,是已知的,而decoder输出的q是预测的,也就是结果预测的词。
?transformer整个过程:
