综述:我们所了解到的机器学习算法的最终目标都是通过数据集的训练,得到一组最优参数,这个过程也称为优化,那么优化的方式有哪些呢,本文介绍梯度下降的一般定义,然后介绍不同数据集下的梯度更新方法,最后介绍深度学习中几种梯度的更新策略。
1、梯度下降简介
梯度下降是一种致力于找到函数极值点的算法。
m
i
n
x
f
(
x
)
其
中
x
为
数
据
集
min_xf(x) 其中x为数据集
minx?f(x)其中x为数据集
已经得到了
(
x
0
,
x
1
,
.
.
.
,
x
i
)
(x_0,x_1,...,x_i)
(x0?,x1?,...,xi?),如何求
x
i
+
1
x_{i+1}
xi+1?
x
i
+
1
=
x
i
+
Δ
x
i
x_{i+1} = x_i + \Delta x_i
xi+1?=xi?+Δxi?
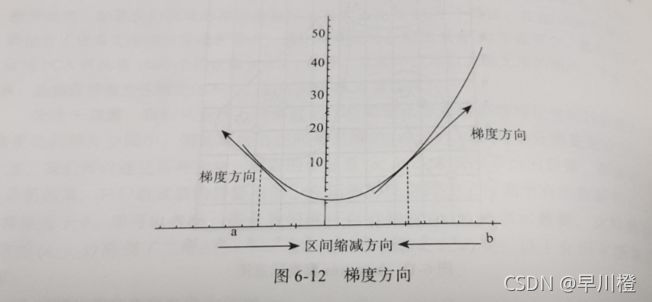
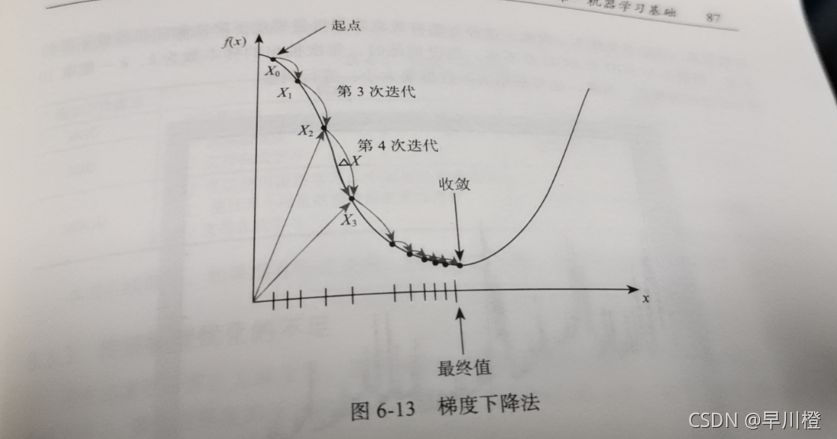
随着迭代次数的增加,将逐渐逼近极值点。逼近过程如下图所示。
2、梯度下降与数据集大小
当数据集的数量非常大的时候,计算梯度将耗费相当长的时间,因此在这种情况下不宜用全量训练数据训练。全量训练又称为批量梯度下降法(BGD),随机梯度下降法(SGD),小批量梯度下降法(MBGD)。
2.1 SGD
每次更新只是用一个样本,因此收敛速度比较快。但样本可能被重复抽取到,而且单个样本数据之间可能差别比较大,可能导致每一次训练时,代价函数产生较大的波动。
2.2 MBGD
小批量梯度下降法介于BGD与SGD之间,每次选取k个数据样本进行训练。MBGD在提升性能的基础上又能保持效率。