开个系列《刷B站学数分》,总结整理B站上优质的数据分析资源~
目录
0 参考资料
- up主Stone_sl 原视频链接:
【面试大杀器之AB实验|关于AB实验你一定要知道的必考知识点(上)-哔哩哔哩】 - 文章:
《AB实验背后的秘密:样本量计算》 - 书籍
《A/B测试 创新始于试验》
1 AB试验的原理
1.1 来源于假设检验
- 有两个样本组,对其中一个做出改动,然后观测该改动对所关注的核心指标是否有显著影响
- 原假设 H0:改动不会对核心指标有显著影响
- 备择假设 H1:改动对核心指标会有显著影响
- 若做完实验后,发现p值足够小,则推翻原假设,证明这项改动会对核心指标产生显著影响
1.2 一句话概括
- ab实验就是同质样本组的对照试验
2 AB实验中的辛普森悖论
2.1 辛普森悖论
- 在某种条件下我们所关注的两组数据,分别讨论时都会满足某种同样的性质,当把两个子数据集进行合并后观察整体时,就会得出截然相反的结论
2.2 辛普森悖论产生的原因
- 把“值”和“量”两个维度的事情,合并成了“值”一个维度去进行讨论
- 即,在划分子数据集的时候,并没有对流量进行合理分割(流量分布不均匀),导致所选取的实验组并不具有代表性
- eg 互联网产品实践中的辛普森悖论
-
- 用1%的用户跑了一个实验,然后得出结论新版本比老版本更加手用户欢迎,而当新版本上线后发现其实给用户带来体验是更差的
-
- 而事实上,我们选取的1%试验组里往往会挑选那些乐于交流、热衷产品、又或者是付费率高粘性高的用户,把他们的数据与全体用户对比是不客观的
2.3 如何避免辛普森悖论(依据《A/B测试 创新始于试验》补充)
(1)对样本量进行合理的分配
- 保证试验组和对照组里的用户特征是一致的,并都具有代表性,可以代表总体用户特征
-
- eg 观测用户参与活动后领取福利的如何放在哪个入口最容易被用户点击:试验组和对照组所圈定的用户都一定要是参与活动的用户,不能选择整体的大盘用户作为观测基准
- 大流量试验比小流量试验更可能收到辛普森悖论的影响
(2)试验设计:正交试验、互斥试验、定向试验(针对细分人群的试验)
- eg 如果两个变量对试验结果都有影响,应该把两个变量放在同一层进行互斥试验,不要让一个变量的试验动态影响到另一个变量的检验
- eg 如果一个实验可能会对新老客户产生完全不同的影响,应该对新老顾客分别展开定向实验,观察结论
(3)试验实施:细分分析
- 多维度的细分分析,除了对比总体,看细分受众群体的试验结果
-
- eg 一个试验版本提升了总体活跃度,但是可能降低了年轻用户的活跃度,那这个试验版本是不是更好呢?
-
- eg 一个试验版本提升了0.1%的总营收,似乎不起眼,但可能上海地区年轻女性购买率提升了20%,这个试验就很有价值了
3 如何计算试验样本量
3.1 样本量计算公式
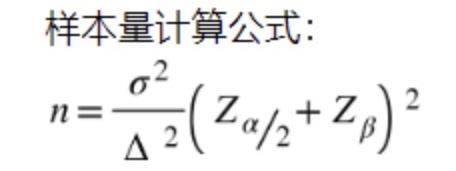
- (1):公式见上图
- (2)n是每组所需样本量,因为A/B测试一般至少2组,所以实验所需样本量为2n
- (3)σ为标准差,衡量数据波动性量,σ越大表示数值波动越厉害
- (4)Δ为两组数值的差异,如注册转换率50%到60%,那么Δ就是10%
- (5)α和β分为第一类错误概率和第二类错误概率,一般分别取0.05和0.2
- (6)Z为正态分布的分位数函数
3.2 计算样本量案例(依据《AB实验背后的秘密:样本量计算》补充)
- 已知:1、注册转换率e1为50%,e2为60% ;2、假设最小标准值为0.8的期望功效;3、显著性水平α为0.05;4、α = 0.05时,Zα/2 = 1.96。β = 0.8时,Zβ = 0.84
- σ^2 = 0.6*(1-0.6)+0.5*(1-0.5)=0.49
- Δ^2 = (0.6 - 0.5) ^2 = 0.01
- n = 384.16
- 因此,试验组和对照组分别需要385个样本,共770个
3.3 样本量的影响因素
- 实验两组数值差异Δ越大或者数值波动性σ越小,所需要的样本量就越小
3.4 样本量计算器

- 工具:Evan’s Awesome A/B Tools
- (1)baseline conversion rate:原来的点击率
通常根据历史数据决定 - (2)minimum detectable effect:代表对判断精度- 的最低要求
- 当参数越大,eg 10%,代表检测出的差别只要达到10%即可
- 当参数越小,eg1%,代表需要检测出的差别值达到1%,判断精度要求更高,相应样本量增加
- (3)significance level = α:显著性水平
要求第一类错误概率 α,不超过5% - (4)statistic power = 1 - β = 80%
统计功效要求第二类错误概率 β,不超过20%
4 脑图总结

PS 红色字体为个人重难点