? ? ? ? 如果你是小白,请慢慢看完~
概念:
????????分类是数据挖掘的一种非常重要的方法。分类的概念是在已有数据的基础上学会一个分类函数或构造出一个分类模型(即我们通常所说的分类器(Classifier))。该函数或模型能够把数据库中的数据纪录映射到给定类别中的某一个,从而可以应用于数据预测。总之,分类器是数据挖掘中对样本进行分类的方法的统称,包含决策树、逻辑回归、朴素贝叶斯、神经网络等算法。#这些算法都很重要,慢慢介绍,请看专题,一定有的!
分类器的构造和实施大体会经过以下几个步骤:
-
选定样本(包含正样本和负样本),将所有样本分成训练样本和测试样本两部分。
-
在训练样本上执行分类器算法,生成分类模型。
-
在测试样本上执行分类模型,生成预测结果。
-
根据预测结果,计算必要的评估指标,评估分类模型的性能
正样本和负样本:正样本是指属于某一类别的样本,反样本是指不属于某一类别的样本比如说你在做字母A的图像识别,字母A的样本就属于正样本,不是字母A的样本就属于负样本。
简单来说就是 准备数据 划分数据集(训练集/测试集)+算法(决策树、逻辑回归、朴素贝叶斯、神经网络)+预测+评估(这模型怎么样loss/accuracy/rmse/mse等等参数)
==================================题外话==================================
最近我导对接企业接了个故障诊断与预测的活儿
我用Keras搭建了个简单的BP多分类网络,数据从论文里面扣了能有30行(还是两种传感器)的数据加起来30行,做监督学习,怎么够・・・
当前进度:
用BP搭建分类网络无奈数据集太少,只有15行数据,做监督学习太难,相关人员评论:
①数据量还没权重的量大
②一类3个样本,都不够划分数据集
训练出来的图是这样的
解决方案:
可行可能不够智能:经验if else 升级 决策树(数据量不够,经验来凑)
好像有相关的研究few-shot叫这种吧,我也不确定,做个非监督聚类吧
当前进度:
用BP搭建分类网络无奈数据集太少,只有15行数据,做监督学习太难,相关人员评论:
①数据量还没权重的量大
②一类3个样本,都不够划分数据集
用神经网络解决代码(难点:数据太少太少了):
数据图
?
我导对接的企业,这会儿在做数据测点,在准备向企业要求数据,希望后面数据能补上。
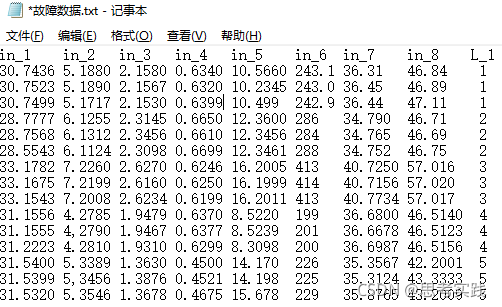
1.加载数据集#前期工作数据还是论文里的,还得用OCR提出来,通过TXT→EXCEL→CSV才得到相对干净的数据
Task:用八维数据预测五类故障,Y_label = 1,2,3,4,5 → Onehot Encoding →Y_onehot_label
import pandas as pd
df = pd.read_csv('./故障检测数据集.csv', engine='python',index_col=0)#index_col=0不要索引
# df = pd.read_csv('./故障检测数据集.csv', usecols=[0,1], engine='python', skipfooter=3)#选
print(df)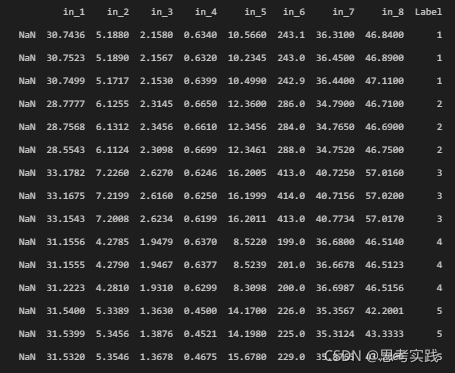
# 制作分类Onehot标签
pd.get_dummies(df.Label)
Y_label = pd.get_dummies(df.Label)
print(Y_label)?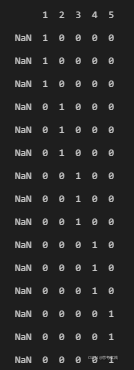
?
#制作输入数据
dataset = df.values
input = df.drop(labels=None, columns= 'Label')
input = input.values
input = input.astype('float32')
input = input.reshape(-1,8)
print(input)
# dataset = df.values#只要value
# dataset = dataset.astype('float32')
# print(dataset)?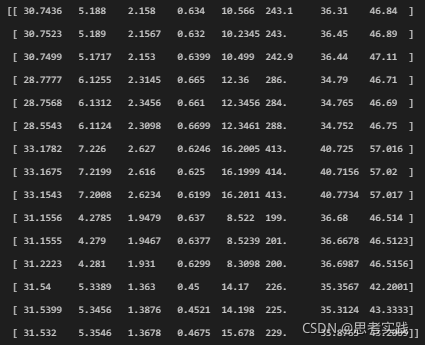
# 数据归一化,方便收敛,不然可能会发散
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler(feature_range=(0, 1))
input = scaler.fit_transform(input)
# print(scaled)#模型准备
import keras
from keras.layers import Dense
model = keras.models.Sequential()
model.add(Dense(5, use_bias=False, input_shape=(8,),name='Dense_ly')) # 8个列输入,仅有的1个权重在这里
model.add(Dense(5, activation='softmax'))
model.compile(optimizer='adam',
loss='categorical_crossentropy',#多分类用的loss
metrics=['acc']
)
# model.compile(loss='mse', optimizer='adam')#回归
# end
model.summary() # 简单查看网络结构呵呵真的是权重量比数据多,有些离谱・・・,想想决策树呢?
#训练调试
print('模型随机权重分配为:%s\n' % (model.layers[0].get_weights())) # 检查随机初始化的权重大小
history = model.fit(input, Y_label,epochs=100,shuffle=True) # 对创建的数据用创建的网络进行训练
print('训练完成后权重分配为:%s\n' % (model.layers[0].get_weights())) # 再次查看训练好的模型中的权重值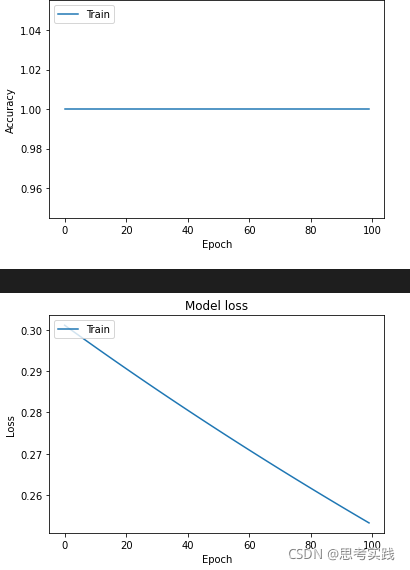
离谱
#预测
import numpy as np
# a = [30.7499,5.1717,2.153,0.6399,10.499,242.9,36.44,47.11]#f_1
a = [28.7568,6.1312,2.3456,0.661,12.3456,284,34.765,46.69]#f_2
# a = [31.1555,4.2790,1.9467,0.6377,8.5239,201,36.6678,46.5123]#f_4
print(a)
b = np.array(a).reshape(-1,1)
scaler_test = MinMaxScaler(feature_range=(0, 1))
b = scaler_test.fit_transform(b)
print(b)
c = b.reshape(-1,8)#转化为可喂模型的测试输入数据
print(c)
print('模型进行预测:%s\n' % (model.predict(c))) # 利用训练好的模型进行预测
print("故障类型:",np.argmax(model.predict(c))+1)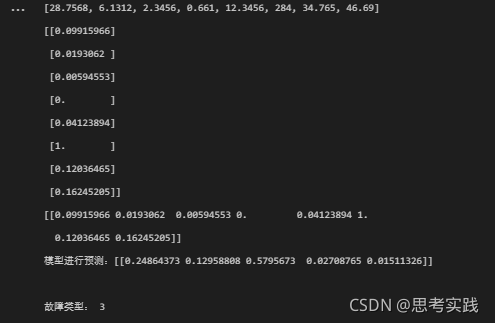
?
?目前数据量太少,无论选择训练集的哪一行数据预测都是故障3,想想别的招吧。
softmax怎么连接Dense层?直接附属的非线性激活函数,预测结果为数组跟着一个np.argmax()得出索引~得到分类结果
Reference:
为什么要用one-hot编码
(P5)使用keras进行多分类问题(2)-独热编码(onehot)【精品】
用keras实现3层BP网络的训练、保存、加载和导入自己手写的数字进行测试【精品】