第一次组会讲的论文,结合了网上的翻译以及自己的理解。省略了神经网络的部分,这个需要自己后续的理解。第一次接触自动驾驶,看一篇综述理解大致的结构。
摘要
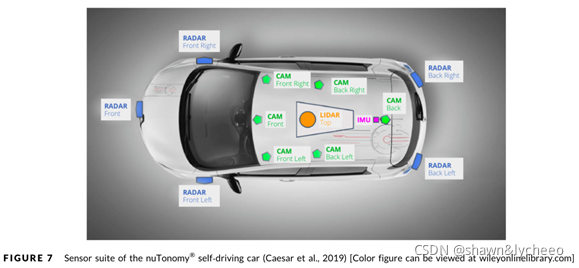
????????????????

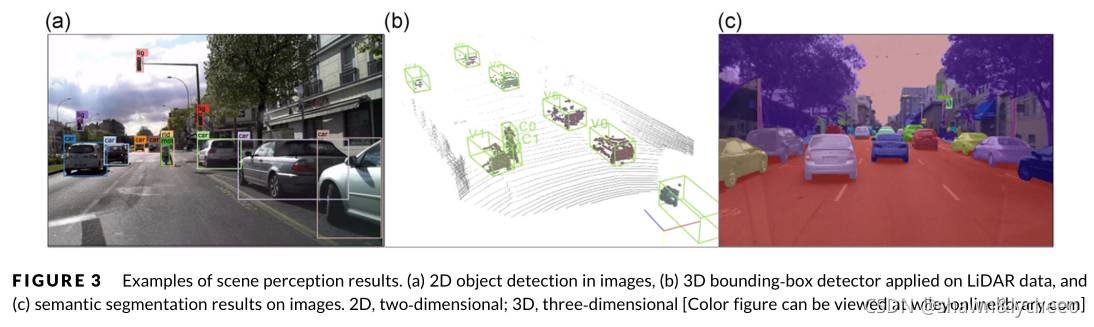
?
(a)图像中的二维目标检测。(b)激光雷达数据三维包围盒探测器。(c)图像的语义分割结果
从摄像机和激光雷达(光检测和测距)设备获取的2D图像和3D点云中检测和识别对象。
在自动驾驶中,三维感知主要基于激光雷达传感器,它以三维点云的形式提供了对周围环境的直接三维表征。激光雷达的性能是通过视场、距离、分辨率和旋转/帧速率来测量的。
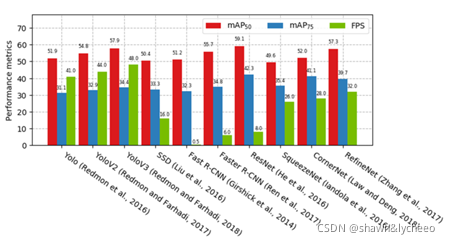
二维目标检测最常用的结构是单级和双级检测(前四种单级,后六种双级)
为了解决点云本身并不包含图像中丰富的视觉信息问题,使用了组合的相机-激光雷达架构,如Frustum PointNet 、Multi-View 3D networks (MV3D) 或RoarNet 。
????????●3.3 语义和实例分割?????
? ? ? ? ? ?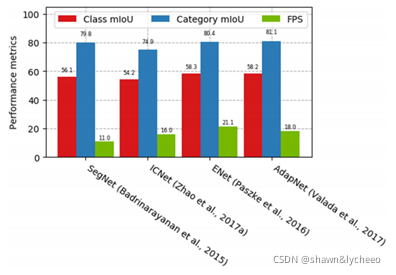
????????语义分割表示图像中每个像素的分类标记
????????实义分割在语义分割的基础上,还需要区分出同一类不同的个体

????????Occupancy Maps也称为占用网格,它是将驾驶空间划分为一组单元并计算每个单元的占用概率的环境表示。
????????深度学习用于Occupancy Maps(占用网格)的上下文中,用于动态目标检测和跟踪,车辆周围占用图的概率估计或用于推导驾驶场景上下文。在后一种情况中,OG是通过随着时间累积数据而构建的,而深度神经网络用于将环境标记到驾驶环境类中,如高速公路驾驶、停车场或市区驾驶。
????????Occupancy Maps代表车内虚拟环境,将感知信息以一种更适合路径规划和运动控制的形式整合在一起。深度学习在OG的估计中起着重要的作用,因为用于填充网格单元的信息是通过使用场景感知方法处理图像和激光雷达数据推断出来的,
?4.基于深度学习的路径规划和行为决策
自动驾驶汽车在两点(即起始位置和目标位置)之间找到路线的能力,它代表了路径规划能力。根据路径规划过程,自动驾驶汽车应该考虑周围环境中存在的所有可能的障碍(物),计算出无碰撞路线的轨迹。
路径规划最具代表性的两种深度学习范式,即模仿学习(IL)和基于深度强化学习(DRL)的规划。
模仿学习的目标是从有记录的驾驶经验中学习人类驾驶员的行为。该策略隐含了从人的演示到汽车学习的过程。模仿学习可以被定义为逆强化学习(IRL)问题,从驾驶员那里学习奖励函数。
路径规划的DRL主要涉及在模拟器中学习驾驶轨迹。在迁移模型的基础上,将真实环境模型抽象转化为虚拟环境。
IL的优势在于它可以通过从真实世界收集的数据进行训练。但是,它缺少在极端的情况下是数据(如越野驾驶、车辆碰撞等),使得训练后的网络在面对未知数据时的响应不确定。
DRL系统能够在模拟世界中探索不同的驾驶情况,但这些模型在移植到真实世界时往往会有偏差行为。
5.基于人工智能的自动驾驶汽车的运动控制器
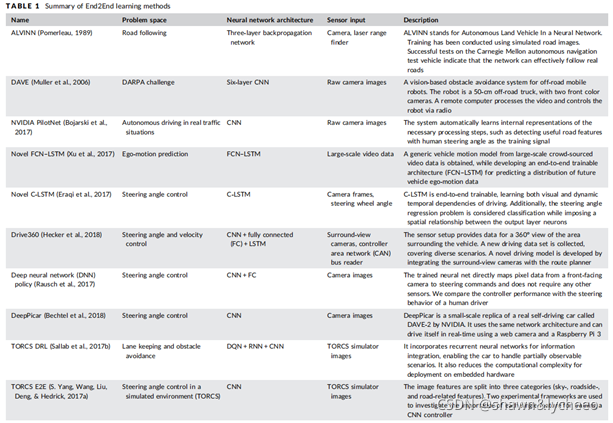
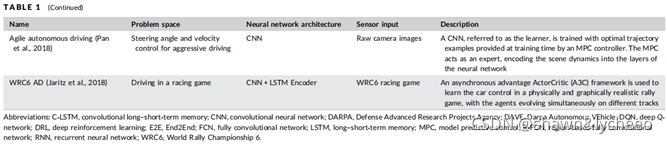
运动控制器负责计算车辆的纵向和横向转向指令。
在自动驾驶环境中,端到端学习控制被定义为从感知数据到控制命令的直接映射。输入通常来自高维特征空间(例如图像或点云)。
端到端控制的系统主要采用在真实世界和/或合成数据上训练深层神经网络,或模拟训练和评估深度强化学习(DRL)系统。还有一些是将仿真训练的DRL模型移植到真实驾驶环境的方法,以及直接基于真实图像数据训练的DRL系统。
6.自主驾驶中深度学习的安全性
演示系统的安全性:
- 理解可能发生的故障的影响
- 了解更广泛系统中的上下文
- 定义有关系统上下文和可能使用它的环境的假设
- 定义安全行为的含义,包括非功能性约束
7.用于训练自动驾驶系统的数据集
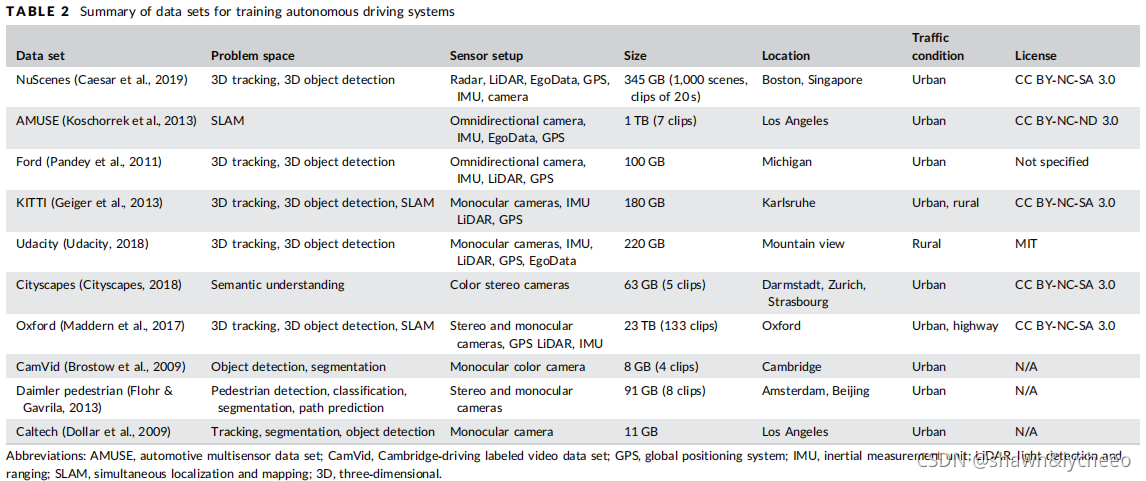
(介绍转自知乎)
KITTI视觉基准数据集(KITTI) 。该数据集由德国卡尔斯鲁厄理工学院(Karlsruher Institut für Technologie,缩写KIT)提供,适用于基准立体视觉、光流、3D跟踪、3D对象检测或SLAM算法的挑战。它是无人驾驶汽车领域最负盛名的数据集。到目前为止,它已经被引用了2000多次。数据采集车配备了多个高分辨率彩色和灰度立体摄像机,一个Velodyne 3D激光雷达和高精度GPS/IMU传感器。它总共提供了卡尔斯鲁厄周围农村和高速公路交通场景中收集的6小时驾驶数据。数据集是在Creative Commons Attribution-Nonbusiness-ShareAlike 3.0协议下提供的。
NuScenes数据集,由nuTonomy公司构建,该数据集包含1000个从波士顿和新加坡收集的驾驶场景,这两个地方以其密集的交通和极具挑战性的驾驶环境而闻名。为了方便常见的计算机视觉任务,如目标检测和跟踪,提供者在整个数据集上以2Hz的精确3D边界框标注了25个对象类别。车辆数据的收集仍在进行中。最终的数据集将包括大约140万张相机图像,40万激光雷达扫描,130万雷达扫描和110万物体边界框,共40万关键帧。数据集是在Creative Commons Attribution-Nonbusiness-ShareAlike 3.0许可下提供的。
Automotive multi-sensor 数据集。由瑞典LINKO?PING大学提供,由配备全方位多摄像头、高度传感器、惯性测量单元、速度传感器和全球定位系统的汽车在各种环境中记录的序列组成。用于读取这些数据集的API被提供给公众,同时还提供了一个长时间的多传感器和多摄像头数据流的集合,这些数据流以给定的格式存储。该数据集是在Creative Commons Attribution-Nonbusiness-NoDerivs 3.0不支持的许可下提供的。
Ford campus vision and lidar dataset (Ford)。该数据集由密歇根大学提供,使用配备专业(Applanix posi - lv)和消费者(Xsens MTi-G)惯性测量单元(IMU)的福特F250皮卡,一个Velodyne激光雷达扫描仪,两个推扫视里格尔激光雷达和Point Grey Ladybug3全方位相机系统收集。2009年,在福特研究院和密歇根州迪尔伯恩市中心记录了100 GB的数据。该数据集非常适合测试各种自主驾驶和同步定位和地图绘制(SLAM)算法。
Udacity数据集。车辆传感器设置包括单目彩色摄像机、GPS和IMU传感器,以及一个Velodyne 3D激光雷达。数据集的大小是223GB。对数据进行标记,并向用户提供相应的人类驾驶员在测试运行期间记录的转向角度。
cityscapes数据集。由德国戴姆勒公司研发中心,德国Max Planck Institute for Informat-ICS(MPI-IS),德国TU Darmstadt Visual Inference Group提供,Cityscapes数据集侧重于城市街景的语义理解,这是它只包含立体视觉彩色图像的原因。图像的多样性非常大:50个城市,不同的季节(春、夏、秋),不同的天气条件和不同的场景动态。详细注释的图片5000张,粗略注释的图片20000张。《Pyramid Scene Parsing Network 》和《 SGN: Sequential Grouping Networks for Instance Segmentation》两个重要的挑战是使用该数据集对语义分割算法的发展进行基准测试和实例分割。
Oxford数据集。数据集收集由英国牛津大学提供,跨度超过1年,产生了超过1000公里的驾驶记录,从安装在车辆上的6个摄像头收集了近2000万张图像,以及LIDAR,GPS和惯性导航系统的地面实况。数据收集在所有天气条件下,包括大雨,夜间,阳光直射和降雪。该数据集的一个特点是,车辆在一年的时间内经常行驶相同的路线,以使研究人员能够在真实世界、动态的城市环境中研究自动车辆的长期定位和地图绘制。
Cambridge-driving Labeled Video数据集(CamVid) 。它由英国剑桥大学提供,是文献中引用最多的数据集之一,也是第一个公开发布的数据集,包含一个带有对象类语义标签的视频集合,以及元数据注释。数据库提供了ground truth标签,将每个像素与32个语义类之一关联起来。传感器的设置仅基于安装在车辆仪表板上的一个单目摄像机。场景的复杂度较低,车辆仅在交通相对较低、天气条件较好的城市地区行驶。
戴姆勒行人基准数据集(Daimler pedestrian benchmark)。该数据集由戴姆勒公司和阿姆斯特丹大学提供,适合行人检测、分类、分割和路径预测等主题。行人数据是观察交通车辆只使用单目和立体摄像机。它是第一个包含行人的数据集。最近,数据集被扩展为使用相同设置捕获的骑自行车者视频样本。
行人检测数据集(Caltech)。数据集由美国加州理工学院提供,包含丰富的注释视频,从移动的车辆上录制,具有挑战性的低分辨率图像,并且经常被遮挡。大约有10小时的驾驶场景累计约250.000帧,共计35万个边界框,2.300条行人专属注释。这些注释包括边界框和详细的遮挡标签之间的时间对应。
?8.结论
?
?
?
?
?
?
?
?