感知器是人工神经网络中的一种典型结构, 它的主要的特点是结构简单,对所能解决的问题 存在着收敛算法,并能从数学上严格证明,从而对神经网络研究起了重要的推动作用。
1957年,Frank Rosenblatt 从纯数学的角度,指出能够从一些输入输出对(X,y)中通过学习算法获得权重 ω和b。
问题:给定一些输入输出对(X,y),其中 y = +1或-1,求一个函数,使:f( X )= y
感知器算法:设定 f(X)=sign(ωTX+b),从一堆输入输出中自动学习,获得 ω 和 b。
感知器算法(Perceptron Alogorithm)
(1)随机选取 ω 和 b
(2)取一个训练样本(X,y)
(i)若 ωTX+b >=0 且 y=-1,则
ω = ω - X b = b - 1
(ii)若 ωTX+b <0 且 y=+1,则
ω = ω + X b = b + 1
(3)再取另一个(X,y),回到(2)
(4)终止条件:直到所有输入输出对都不满足(2)中(i)和(ii)之一,退出循环。
感知器算法在某些方面和 svm 有些相似,但又不是完全相同:
svm中将所有的x和y输入,基于所有的样本构造一个很大的优化问题,再去解这个优化问题。(以全局眼光进行训练)
而感知器算法思路是对于每个x和y进行测试,不断测试不断调整(以个体的角度进行训练)
从这个角度来看感知器算法更接近于我们日常生活中的习惯。
接下来我们来思考一下感知器算法针对两种情况的处理
若ωTX+b >0 且 y=-1。通过线性分类面的知识,当ωTX+b >0 时应该有 y=+1。由此可见此时的 ω 和 b 对于x不能正确的分类,于是算法进行如下处理
ω(新) = ω - X
b(新) = b -1
于是原式就有
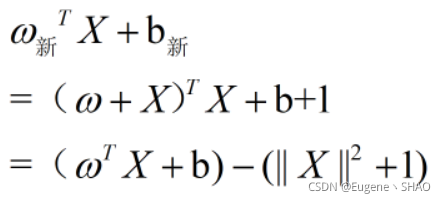
当y小于零时,我们希望可以将ωTX+b >0向负的方向“拉一下“,于是在最后的式子中可以看到,通过减去一个(||X||2+1) 使ωTX+b 变小,并且将其向负的方向至少拉去1。
同理,当y = +1时 ,公式中的减号变为加号,最终可以得到在ωTX+b的基础上加上(||X||2+1) 来达到将其向正方向“拉”的一个作用。
于是,每当出现一次识别不准确的情况, 我们就做一个“拉一下”的操作,直到所有的样本都能够被准确分类为止。
针对感知器算法,Frank Rosenblatt同样给出了一个证明,他提出:若存在一组样本线性可分,则算法会在有限的次数内停止,即完成准确分类。(通俗来说就是“来拉”的过程是有限的)
在初步了解感知器算法后,我们需要使用严格的数学来证明其有效:

定义完成后,对算法进行重新定义,有(下面的Xi没有特指均为X的增广向量):
输入Xi
(1)随机选取 ω
(2)挑一个Xi
若ωT Xi<0,则ω=ω+Xi
(3)回到(2),直到对所有的Xi都不成立时退出。
感知器算法收敛定理
输入{Xi} i=1-N,若线性可分,即 ?ωopt,使得:
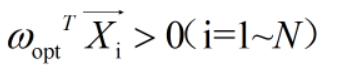
则利用上述感知器算法,经过有限步后,得到一个ω,使
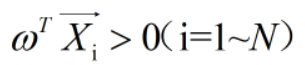
在上述两个公式中的ωopt和ω,相同的概率非常微小,因为存在ωopt,即可以从无限个平面中找到一个ω使其满足关系式,因此满足的ω会有无限个,所以二者未必相同
下面来证明收敛定理
证明:
不失一般性:设 ||ωopt|| = 1(因为 ωopt 与 aωopt 在同一个平面,因此可以通过调整参数a使其成立)
假设第k步的ω(k) ,且有一个 Xi 使
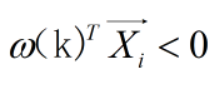
根据感知器算法
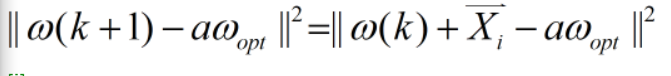
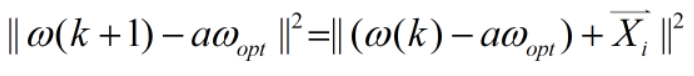 将右式展开,得到
将右式展开,得到
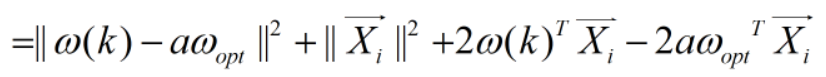 由感知器收敛定理,ωoptT Xi>0 和 ω(k)TXi <0,得到
由感知器收敛定理,ωoptT Xi>0 和 ω(k)TXi <0,得到
一定可以有很大的a,使得下式成立
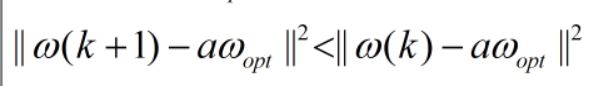
不断迭代,每次都会使ω(k+1)到 aω 的距离变小,直到趋于0
上述是一种关于定性的分析,下面介绍定量的分析
定义 β 和 γ,有
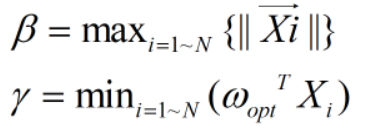
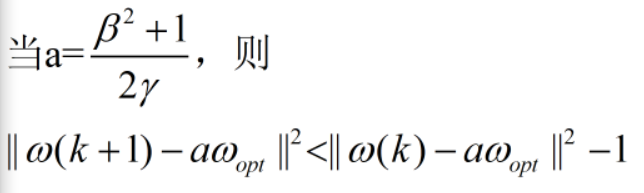 取D ,有
取D ,有
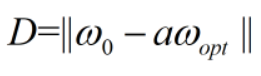
则至多经过D2步,ω将会收敛至 aωopt
注:只有存在Xi使得不等式小于零时,才会进行循环计算,当Xi不存在时,就会立刻退出,因此最终未必会收敛至 aωopt,而这个过程将不会超过D2步,当达到D2步时将会自动收敛至aωopt
(创作不易 ,如需转载请联系作者)