MindSpore 1.5,确立中文名昇思,使能科研创新和行业应用空山新雨后,天气晚来秋——经过MindSpore社区开发者们勤奋耕耘,在这个丰收的季节,为大家奉上全新的1.5版本,在这个版本中我们正式发布MindSpore中文名:昇思,希望大家能够喜欢!此同时为大家带来全新科学计算行业套件MindScience、亲和算法库MindSpore Boost、支持混合专家(MoE)与异构并行、集群调优支持大规模分布式训练,并完善控制流使用,新增对外开放机制等诸多新特性,在使能科研创新和应用中不断努力,下面就带大家快速浏览1.5版本的关键特性。特性视频一览见昇思MindSpore公众号
1.1?? ?MindScience
科学计算套件,为高性能科学应用提供计算新范式当前多种算力正在激发跨领域的应用融合,AI已经成为研究科学计算的新范式。因此我们将MindSpore拓展到科学计算领域。

通过多尺度混合计算和高阶混合微分两大关键创新,将MindSpore原有的AI计算引擎升级为AI与科学计算的统一引擎,实现融合的统一加速。在此基础上,我们计划面向8大科学计算行业打造MindScience系列套件。这些行业套件包含业界领先的数据集、基础模型、预置高精度模型和前后处理工具,加速科学行业应用开发。当前,我们推出面向电子信息行业的MindElec套件和面向生命科学行业的MindSPONGE套件,分别实现了电磁仿真性能提升10倍和生物制药化合物模拟效率提升50%。
 ?
?
查看介绍:https://www.mindspore.cn/mindscience/
1.1.1?? ?MindElec v0.1
MindElec电磁仿真套件主要由多模数据转换、高维数据编码、基础模型库以及多频信号网络优化等组成,同时支持时域和频域的电磁仿真。其计算过程如下:利用MindElec多模数据转换技术将复杂的CAD结构转换成AI亲和的张量数据,高维的张量数据通过编码方式进行压缩,大幅减少存储和计算量,压缩后的张量数据进入创新的AI电磁仿真基础模型进行训练,训练过程结合多频信号网络优化技术提升模型精度。

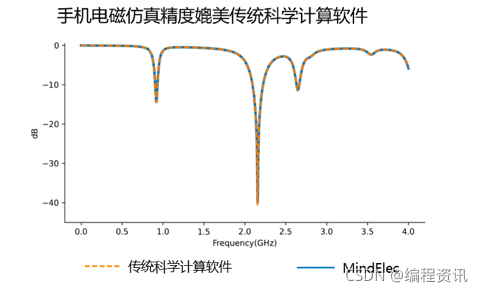
MindElec 0.1版本在手机电磁仿真领域已取得技术突破,仿真精度媲美传统科学计算软件,同时性能提升10倍。
1.1.2?? ?MindSPONGE v0.1
MindSPONGE是由高毅勤课题组(北京大学、深圳湾实验室)、华为MindSpore及 EI Health联合开发的分子模拟库,具有高性能、模块化等特性。

MindSPONGE本次独立成仓,演进为0.1版本,新增支持分子动力学中常见的系综模拟包含NVT、NPT等,例如进行新冠病毒Delta毒株模拟,模拟结果有效反应病毒毒性增强,符合实际情况。MindSPONGE是第一个根植于AI框架的分子模拟工具,当前已内置Molecular CT,SchNet等AI神经网络,可用来进行势能函数的拟合,例如AI力场模拟克莱森重排反应,高效进行融合AI的分子动力学模拟,可看到体系在七元环和三元环之间进行转化。
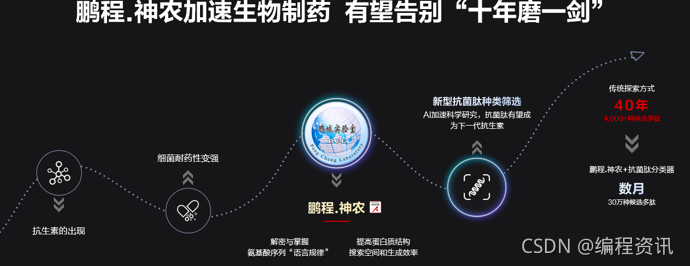
 抗生素的出现让人类的寿命延长了数十年,然而,由于细菌的耐药性变强,人类迫切需要寻找到下一代抗生素——抗菌肽(作为一种可以有效杀灭耐药性病原菌的肽类物质)。MindSpore团队与鹏城实验室等团队合作开发的鹏程。神农平台具有强大的氨基酸序列生成能力,其利用鹏程。盘古大模型完成预训练再通过finetune生成新的氨基酸序列,有望极大提升新型抗菌肽的发现速度。
抗生素的出现让人类的寿命延长了数十年,然而,由于细菌的耐药性变强,人类迫切需要寻找到下一代抗生素——抗菌肽(作为一种可以有效杀灭耐药性病原菌的肽类物质)。MindSpore团队与鹏城实验室等团队合作开发的鹏程。神农平台具有强大的氨基酸序列生成能力,其利用鹏程。盘古大模型完成预训练再通过finetune生成新的氨基酸序列,有望极大提升新型抗菌肽的发现速度。
1.2?? ?自动并行支持混合专家(MoE)与异构并行,既联合中科院发布全球首个三模态大模型—紫东。太初,又实现遥感领域超分辨率图像自动切分
1.2.1?? ?混合专家(MoE)及其并行基于Transformer扩展的大模型是当前各种大模型的主干,现在,混合专家(Mixture of Expert,MoE)结构成为扩展Transformer的一种关键技术。如下图所示,Transformer中每层是由Attention和FeedForward(FFN)这两个基础结构组成的。将FFN看做是一个专家(expert),MoE结构是由多个专家并行组成,其入口是一个路由器(router),负责将token分发给各个专家,可以有多种路由策略可选择(如Top,Top2等),其出口是加权求和。
MoE已被验证过在多种任务上有优异的效果,是万亿以上大模型的基础结构。
 MindSpore 1.5版本已实现了MoE的结构和专家并行的功能:允许多专家在多设备上并行执行。如下图所示,路由器(数据并行)经过AllToAll算子将token分配到各个设备上的专家进行计算,而后,又进过AllToAll将结果汇聚。
MindSpore 1.5版本已实现了MoE的结构和专家并行的功能:允许多专家在多设备上并行执行。如下图所示,路由器(数据并行)经过AllToAll算子将token分配到各个设备上的专家进行计算,而后,又进过AllToAll将结果汇聚。
MindSpore MoE的代码实现详见:https://gitee.com/mindspore/mindspore/blob/r1.5/mindspore/parallel/nn
1.2.2?? ?异构并行受限于GPU/NPU设备的内存瓶颈,有效利用Host端的内存成为解决大模型扩展的一种可行的途径。异构并行训练方法是通过分析图上算子内存占用和计算密集程度,将内存消耗巨大和适合CPU处理的算子切分到CPU子图,将内存消耗较小计算密集的算子切分到硬件加速器子图,框架协同不同子图进行网络训练的过程,能够充分利用异构硬件特点,有效的提升单卡可训练模型规模。对于大规模预训练模型,其主要的瓶颈往往在于参数量过大,设备显存无法存放下来。MindSpore1.5版本在处理大规模预训练网络时,可以通过优化器异构将优化器指定到CPU上,以减少优化器状态量显存占用开销,进而扩展可训练模型规模。如下图所示,将FP32的Adam优化器放置于CPU上进行运算,可以减少60%多的参数显存占用。
 查看文档:
查看文档:
https://www.mindspore.cn/docs/programming_guide/zh-CN/r1.5/design/heterogeneous_training.html
MindSpore联合中科院自动化所发布全球首个三模态大模型—紫东。太初,多模态高效协同支撑图文跨模态理解与生成性能领先SOTA、视频理解与描述性能全球No.1,持续赋能行业,助力人工智能产业繁荣发展。
1.2.3?? ?MoE+异构并行,实现32卡训练2420亿参数模型我们使用MoE结构扩展鹏程·盘古模型【1],同时应用了专家并行+异构并行+数据并行+模型并行。如下示意图,将优化器相关的状态及其计算放到CPU端。在MoE结构中,同时应用了模型并行和专家并行,即在同一专家会切分到Server内部,如图中Server 1上的FFN1被切分到了两个设备上,由此产生的模型并行AllReduce会发生在Server内部;而不同Server的对应设备间是数据并行(和专家并行),即Server 1上的Device 1与Server 2上的Device 1是数据并行(和专家并行),Server 1上的Device 2与Server 2上的Device 2是数据并行(和专家并行),由此产生的AllToAll会发生在Server间。AllToAll用于完成数据并行到专家并行的转换和专家并行到数据并行的转换。
 我们分别在8卡、16卡、32卡昇腾设备上验证了优化器异构和专家并行对训练模型规模提升的效果,如下图所示,使用优化器异构基本都能达到3倍的模型规模提升,在8卡上可以跑到612亿参数量,16卡上可以跑到1210亿参数量,32卡上可以跑到2420亿参数量的模型规模。
我们分别在8卡、16卡、32卡昇腾设备上验证了优化器异构和专家并行对训练模型规模提升的效果,如下图所示,使用优化器异构基本都能达到3倍的模型规模提升,在8卡上可以跑到612亿参数量,16卡上可以跑到1210亿参数量,32卡上可以跑到2420亿参数量的模型规模。
1.2.4?? ?超分辨率图像自动并行,解决遥感影像“大幅面、多通道”的处理难题超分辨率图像往往非常大,以遥感图像为例,分辨率是4*30000*30000,一张图片约14GB,单卡受限于内存无法完成计算,需要对图片进行多机多卡的并行处理。在数据处理的过程中,支持对大幅面遥感影像的解码和数据增强,针对单样本尺寸大的特点,框架根据集群规模的大小,自动将大幅面数据切分成合适的大小(如切分H、W维度),并分发到不同的计算节点,以解决显存不足问题。在训练和推理过程中,由于网络将对图片进行大量的卷积等计算,而图片的H、W维被切分后,对每个计算节点来说,可能有部分边缘特征信息存储在其他节点上,框架将自动识别边缘特征信息的分布情况,采用相邻节点交换等通信技术对分布在周边节点上的特征信息进行整合,最终保证网络执行结果无精度损失。
1.3?? ?推出亲和算法库——MindSpore Boost
众所周知,训练是一个复杂的计算过程,端到端训练包含很多步骤。如下图所示,深度学习训练过程本身是个高冗余的计算过程,需要围绕多个模块分别进行计算优化,最终实现不同AI场景下端到端训练的效率优化。端到端训练要素在MindSpore 1.5版本中,华为中央媒体技术院与MindSpore共同推出亲和算法库MindSpore Boost 1.0,目标都是为了在不同的AI场景下,保持用户训练精度的同时,为用户提供高效的训练体验,包含数据、网络、通信、训练策略和优化器等维度的加速算法,架构图如下所示。
MindSpore Boost 1.0架构除了亲和算法外,我们还提供简易模式,进行算法封装,为用户提供三种不同层级的选择,即O1/O2/O3,随着层级的递增,其加速比例增加,这种模式下,用户无需了解算法细节,仅需要在调用Model的训练入口时,打开加速开关和选择加速层级即可,使用方法如下图所示。简易模式使用示意
1.4?? ?集群调试调优支持大规模分布式训练大模型是当前深度学习领域研究的热点之一。模型的参数量和训练数据集的大小均以指数级的规模快速增长。以MindSpore和鹏城实验室共同发布的鹏程·盘古模型为例,模型的参数量达到了2000亿,使用2K集群历时数月进行训练。在这样的背景下,模型性能调优对减少训练时间和成本有着至关重要的意义。
MindSpore 1.5版本发布集群调试调优工具链,针对K级集群性能数据能够做到一键收集,提供集群慢节点/慢网络、计算通信比、内存热力图等多维性能分析与可视化能力,结合智能集群调优建议,达成小时级性能瓶颈定位。
1.4.1?? ?集群迭代&通信性能分析以集群视角汇总了多项性能关键数据,并对多卡数据提供了排序、分析功能,用户可快速的从K级集群中找到慢节点、慢链路等,并从集群页面跳转到对应的单卡页面,进一步定界节点慢的原因,找到最小性能瓶颈点。
1.4.2?? ?计算通信比分析集群并行训练过程中,通信是影响性能的重要因素,计算通信比指标可以帮助开发者分析网络切分策略是否合理以及是否有优化空间。如下图所示,非overlap 87ms是开发者可关注的性能提升空间。查看文档:https://www.mindspore.cn/mindinsight/docs/zh-CN/r1.5/performance_profiling_ascend_of_cluster.html
1.5?? ?MindSpore Lite新增对外开放机制,支持Hi3516/3549芯片以及NVIDIA GPU的对接此版本中,MindSpore Lite新增了两个对外开放的接入机制:支持南向自定义算子接入,支持第三方AI框架通过Delegate机制接入。南向自定义算子的接入功能,支持用户自定义图优化能力,实现在离线阶段生成特定硬件支持的模型文件,同时支持特有硬件算子接入MindSpore Lite Runtime,实现MindSpore Lite在第三方硬件上高性能推理,当前我们已经接入Hi3516/3559芯片,使机器视觉AI应用开发更加便捷。第三方专用AI芯片南向接入MindSpore Lite
查看文档:https://www.mindspore.cn/lite/docs/zh-CN/r1.5/use/register_kernel.html
Delegate机制,支持有构图能力的第三方AI框架接入MindSpore Lite,充分利用外部AI框架提供的特有硬件算子库或者更优越的推理性能。采用Delegate实现了 Lite+其他AI框架的异构执行,保持了离线模型一致性,当前我们已经通过Delegate机制支持了Kirin NPU以及NVIDIA GPU。通过Delegate接入MindSpore Lite
查看文档:https://www.mindspore.cn/lite/docs/zh-CN/r1.5/use/delegate.html
1.6?? ?灵活表达:完善控制流,支持多种控制语句混合编写,支持循环自动微分在此版本中,在控制流语法的使用方面我们提供以下支持与优化:
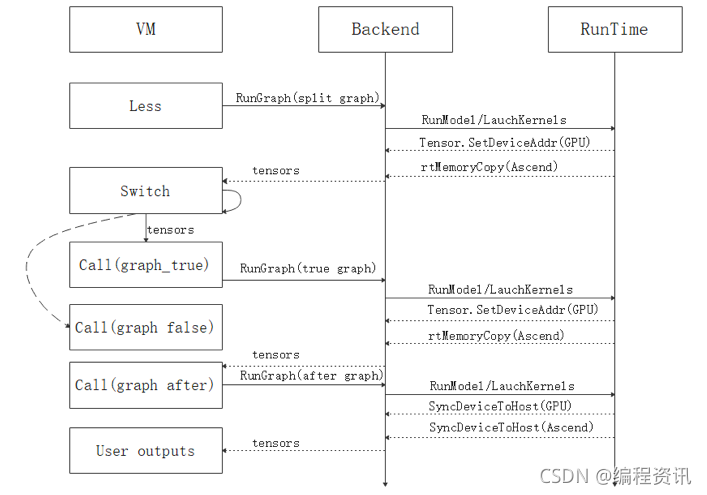
1)进一步强化了对于静态图控制流的支持,通过使用虚拟机机制执行控制流算子,解决了控制流非尾递归场景的图递归执行问题,实现了对循环求反向的支持。同时,我们扩大了控制流的语法支持范围,目前控制流已可以支持if、while、for、break、continue表达。一个if语句基于虚拟机机制的控制流执行流程如图所示:
2)优化静态图编译过程,减少了控制流网络的子图数量,大幅提升部分复杂控制流网络场景下的编译性能和执行性能。
3)支持控制流MindIR导入导出功能,可以在云侧训练控制流网络导出MindIR,在端侧导入MindIR进行推理。查看文档:https://www.mindspore.cn/docs/programming_guide/zh-CN/r1.5/control_flow.html
1.7?? ?参考文献
[1] Zeng, Wei, et al."PanGu-$\alpha $: Large-scale Autoregressive Pretrained Chinese Language Models with Auto-parallel Computation." arXiv preprint arXiv:2104.12369 (2021)。
?
?
?
?
?
?
?
?
?