Communication-Efficient On-Device Machine Learning: Federated Distillation and Augmentation under Non-IID Private Data
论文链接
(源码没有公开)
1 论文概述
1.1 Abstract
终端设备机器学习可以使用大量终端上的数据进行机器学习模型的训练。在这个过程中存在两个问题:1. 设备之间的通信压力问题(模型越大,需要传送的数据量就越大,会有效率问题,安全问题等);2. 不同设备产生的数据不符合独立同分布(会影响模型的效果)。
基于上述两个问题,论文提出了federated distillation(联邦蒸馏)和federated augmentation(联邦增强)方法,并且通过实验证明了方法的有效性
1.2 Introduction
终端设备机器学习通过交换各个设备间的本地模型的参数(设备间的数据不共享),训练全局模型。而这存在几个问题
- 设备间的通信开销于模型的规模存在正相关的关系,不利于训练大规模的模型。
- 不同设备间的数据不符合IID,会影响训练效果。
针对第一个问题,论文提出了联邦蒸馏的方法,使得设备间的通信开销取决于模型输出的维度而不是模型的规模;而在执行联邦蒸馏之前,需要对训练数据集进行处理,减小non-IID问题,方法为使用对抗生成网络生成其他分布的数据,使其分布趋于IID。
2. Federated distillation
2.1 模型简介
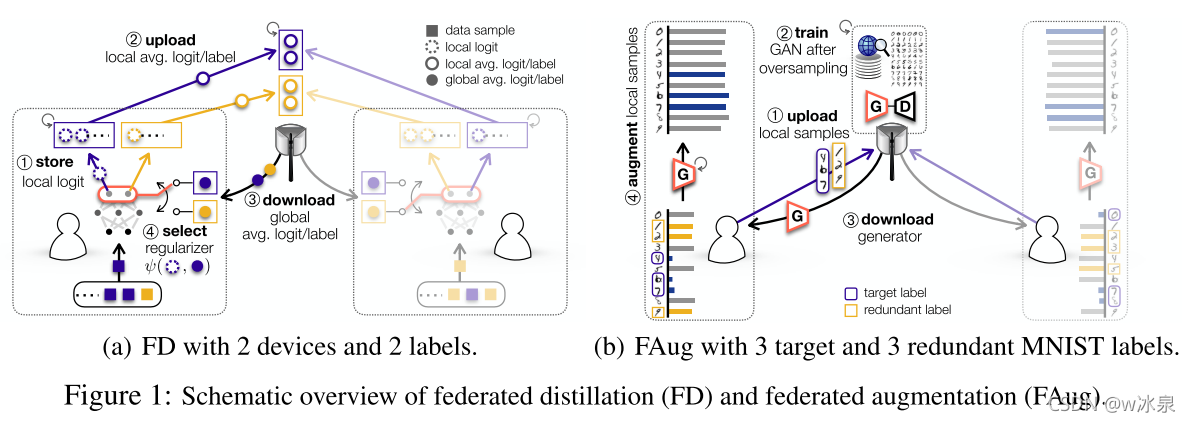
相较于传统的联邦学习通过共享模型参数以训练全局模型,联邦蒸馏通过共享模型输出的结果logits以训练全局模型。联邦蒸馏,与知识蒸馏有关,在该模型中,每一个终端就是学生,而平均模型是老师,(学生和老师的概念源于知识蒸馏模型),老师只将平均模型的输出logits传给学生,然后学生基于该logits进行模型训练。
但是这种方法的可行性不高,因为老师和学生要基于一样的训练数据进行训练(此时的logits才能与输入对齐),而这不能周期进行,因为不同的设备的数据集是不同的。基于这个问题,论文提出了Algorithm 1(使用蒸馏不仅可以减小通信消耗,还能减小在本地训练模型的消耗)
- 本地训练阶段:主要是损失函数部分由两部分组成:1. 与真实标签的交叉熵函数;2. 与全局average logits的交叉熵函数(蒸馏);
- 全局ensemble阶段:基于本地的average logit更新全局average logit

3. Federated augmentation
3.1 模型简介
要解决数据分布不满足IID的问题,可以对设备的数据集补充标签缺失的数据,但这会造成较大的通信开销,而FAug可以通过对抗生成模型在本地直接补充数据,而不用进行设备间的通信。
对抗生成模型在服务器上进行训练,FAug中的每个设备都能识别数据样本中缺少的标签,然后设备会向服务器传这这些标签的几个数据样本(问题:既然缺少,哪来的样本,可能是数量很少,但不为0)。经过服务器的训练,设备下载生成模型后就可以用来补充自己的数据集了。为了保证数据的隐私,设备不仅会传输target label的数据集,还会传输其他label的数据集(个人理解:如果仅仅传输target label的数据集,可能会通过X推断出y,混入其他数据集会降低这个可能性)。
FD和FAug示意图
4. Experiment
…