����Ի��ӿ���类�����ģ�������о�
������������������Կ������Ŀ类���Ե�����ʶ���о�
���ķ�����־:����ҽѧ����ѧ��־
���ķ�������:2021��6��

��ƪ����Ϊ�˽���类��,��ʱ���������������,�������������������Կ�����(MCD_DA),ͨ���������������ʶ��ģ��,��dz��������ȡ���ֱ�Կ������������з�����,����ʹ������ȡ�����������,��ʵ�ֽ������Ϸֲ������ͬʱѵ��������ѧϰ���������Եľ��߽߱硣ʵ��������,�����ͨ�÷�����58.23%��ƽ������ȷ��,�÷�����ƽ������ȷ�ʴﵽ��88.33%��(����:���ƽ������ȷ�������ĸ����ݼ�������,ʵ�鷶ʽ��ʲô)(��:SEED�ϵ���һ���Խ�����֤)
���Բ��ֹؼ�Ҫ����ȡ
- ����Ӧ��Ǩ��ѧϰ��һ�������� ,���о���Ŀ���ǽ��Ͳ�ͬ��֮������ͬʱ,���ֲ�ͬ�����б���Ϣ
- ���ڵ�Ԥ��Ӧ���������ڼ�СԴ���Ŀ�������ض��ռ�ľ��롣(����:֣ΰ��2016��һƪ����,������ֱ��ʽ����Ǩ��,��δ�ҵ�),��ƪ���µ�Ŀ������С��Դ���Ŀ��������ƽ��ƫ���������Ե�ֲ�,SEED��������76.32%���ҡ�
- JIN����������Կ������罨���类�����ʶ��ģ��,ͨ��������ȡ������������ĶԿ���С������,��SEED��������79.19%����(���ĵ�ַ(��ʱ������)) ��������Ҫ�����һ����,�������˵,������DANN�ķ������ֱ��ʽ����Ǩ�Ƶķ���Ҳû�������ٵ㡣
- �����������Ӧ�㷨������,Li���������һ�����Ϸֲ�����Ӧ�㷨,ʹ�öԿ���ѵ����dz���Ե�ֲ�,��ͨ��������ǿ��Ӧ���һ��������ֲ�,ͨ��ͬʱ������Ե�ֲ��������ֲ����Ƶص������Ϸֲ�,��SEED��������86.7%,Ϊ��������õĽ��(����Ӧ,���Ϸֲ�����Ӧ�㷨,��2021��6��Ϊֹ,��SEED��������õĽ��)��ȱ��:��Ҫ����������͵���ʧֵ,������ʧֵ�����յ���ʧ�����е�Ȩ����Ҫ���ѵ������ȷ��,�Ӷ�����ѵ�������е�����,�Բ�ͬ�ı���������Ҫ��ʱ��ĵ��β��ܻ�ýϺõķ�������(�������ʵ�е�����,ͨ������ʵ��ȥȷ�������ʧ��Ȩ��)
- һ�仰������ƪ������������������������Կ�:ͨ�������������Դ�������ֲ���Ϣ�IJ�ͬ�����������,Ѱ�ұ�Դ���ų��Ŀ������������,��һ������������С��ΪĿ��ѵ��������ȡ��,�������ɷ���Դ�������ֲ�������,�Ӷ����������ֲ���
MCD_DA ģ�ͽ��

ͼ��F(feature extractor)Ϊ������ȡ��,C1,C2Ϊ����������,DΪ���������F����Դ���Ŀ�����ǹ���Ȩ�ص�,δ����Ŀ��������������ɿ���Ԥ��,F,C1,C2�ĸ�����Ҫ����Դ����б�ǩ����������з���,����Ҫ�����ܵ�ʹԴ����Ŀ�����Ϊ����(������Ե�ֲ��������ֲ�)�����ǵ���dz�ز�������������������,������ز�����������ض������������,�ڽ�dz�IJ�F��������������D,���ڹ���DANN��D��һ���ж�������������Դ����Ŀ����Ķ�Ԫ������,��ǰ��������,����һ����ͨ�ķ�����,���ڷ���������,����ʹF���ɾ��������ʵ�����,����ͨ��D�е��ݶȷ�ת��ʵ�ֵġ�
���ݼ������Լ�����
- SEED:15��������,ÿ��������5��3��������ʵ��,һ��3��ʵ��,������15��3��15=675���Ե����ݡ�ѡ��DE��Ϊ��������,DE����ά��:62��5=310
- ���ѡȡ��5000Դ��������Ϊѵ������,ѵ�����л�����Ŀ����ȫ��3394��δ��ǵ����ݡ�Ϊ������������������,���������������й�һ������
- �������������ö���֪��,����ھ�����������ܻ�ø��õ�����ӦЧ����
ģ��ѵ������
- ����A:�ھ���������Դ���Ŀ��������ǰ���¼�����Դ�������������ʧ�������Ż��IJ��ص㲻ͬ,��������һ����ʹ�������ֲ�ͬ�IJ������·���������F,D,����Ϊ����Ӧ��������������Ż���,����Ϊ��ʹ�������dz�����������ͳ�������ơ�F,D���Ż���������:




C1,C2���Ż���������:

2. ����B:����һ����,ͬ�����GAN,ѵ�����������ķ�����C1,C2��Ϊ������,F��Ϊ��������ѵ��������ѧϰ���Ŀ����������:�̶�F�IJ���,ѵ�������������ķ�����C1,C2,ʹ��Ŀ�������ݵ�Ԥ��������,�Ӷ����Լ�Ŀ������߽߱總����������

����C:Ϊ������Ŀ������߽߱總����������ģ������,ʹ��ģ�������������������������,ѵ��ģ��ѧϰ��С�����硣

ʵ����
����MCD_DA����һ���Խ�����֤������7��ȷ�����(98.43%),����3��ȷ�����(74.57%),15��ƽ������ȷ��Ϊ(88.33��5.86)%��(������Ҫע��һ��,������һƪ2019���˶ʿ�����п�������Ӧ������WGANDA����һ���Խ����SEED������87.07%,����һƪ21�������,�ɼ���ʵ��ʾ�ĵ���������,ֻ��1��������,������ƪ���¶�������DANNΪ78%���ҵ�Ч��,������Եõ���֤)
Multisource Transfer Learning for Cross-Subject EEG Emotion Recognition
��ԴǨ��ѧϰ�ڿ类���Ե�����ʶ���е�Ӧ��
������Դ:IEEE TRANSACTIONS ON CYBERNETICS ʱ��:2020.6
��ƪ�������õ������,��Ŀ���������ı�����ݿ��Բ��뵽ѵ���С�
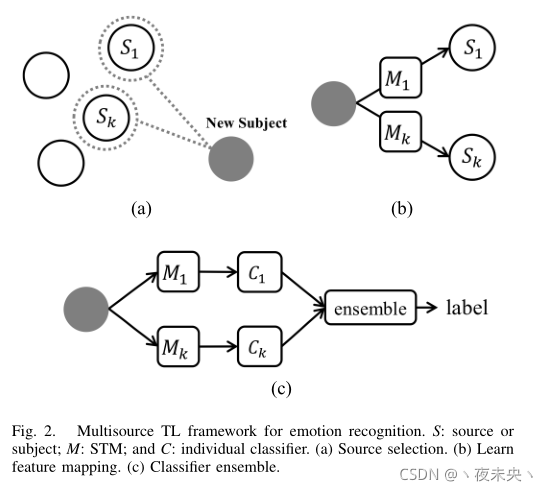
��˵һ����ƪ���µ�����˼·������������Ҫ��ȡĿ������б�ǩ����,����Щ���ݷ�Ϊcalibration sessions(У����)��test sessions(���Լ�),У������������ҪԶԶС����֤��������������Ϊ����Ҳ���ǵ�����ŵ�ʵ��ϵͳ��,Ҫ�����ܼ����±��Ե���ģ�͵�ʱ��,����ֻ��Ҫ������У��������������ģ�;ͺ��ˡ�Ȼ����ô����?�õ�һ���±��Ե�����,��Ҫѡ������Դ��ĺ��ʵ�Դ����,�����±��Ե�У��������ȥѧһ��ӳ���ϵstyle transfer mapping(STM)�������±��ԵIJ��Լ���ʱ������ѧ����STMӳ���ϵtransformһ��,���õ�label��ʱ�����˼���ѧϰ,ѡ������������
C
1
C_{1}
C1?,
C
2
C_{2}
C2?���ۺϵõ����Լ���label��
RELATED WORK
��BCI�д����������͵ķ������⡣
- ����һ������˵,����session������ʵ������,��Ȼ�����ϻ���ֳ�һ����,��session֮��϶�����ڷ�ƽ���ԺͲ����ԡ�˵����,���������ͨ�����̼�(�����Ӱ)�����������Ե��źź����챻ͬһ�̼������������Ե��ź�δ��һ����
- �类��,����ܺ����⡣
��õ�����Ǩ��ѧϰ����:
3. ����Ǩ�ơ���Դ����ѡ��Ȩ������
4. ����Ǩ�ơ�
5. ����Ǩ��
METHODS
Source Selection

A.��˵��������Դ������ѵ����N����������,Ȼ����Ŀ�������ݵ�У����һ��,ѡ������s��accuracy��ߵķ�����,Ȼ��ѧһ��feature mapping function,������ܲ��Լ���ʱ���⼸����������Ҫһ��ó�һ�����,ÿ���������Եó�����в�����Ȩ����һ��ʼ������У������accur����(���͵ļ���ѧϰ)
����,����Ǩ��ѧϰ�ķ�������,ʲô��inductive transfer method?ʲô��transductive transfer method?
Ǩ��ѧϰ��������(����ͼ����Ҫ)
Style Transfer Mapping
���̵漸������:
destination and origin: call the representational patterns(prototypical clustering centers,class mean values) in A S p A^{Sp} ASp the ��destination,�� and samples in A T A^{T} AT the ��origin.��
D:The destination point set is noted as D = { d i �� R m �O i = 1 , . . . , n } D=\left \{ d_{i}\in R^{m}| i=1,...,n \right \} D={di?��Rm�Oi=1,...,n},D is composed of the representational patterns of A S p A^{Sp} ASp
O:The mapping origin of STM is O = { o i �� R m �O i = 1 , . . . , n } O=\left \{ o_{i}\in R^{m}| i=1,...,n \right \} O={oi?��Rm�Oi=1,...,n}
���ѧϰһ��ӳ���ϵ,���Ǽ������ӳ���ϵΪ:
A
o
i
+
b
,
A
��
R
m
?
m
,
b
��
R
m
Ao_{i}+b,A\in R^{m*m},b\in R^{m}
Aoi?+b,A��Rm?m,b��Rm,����

������μ���,�������й�ʽ,����ֱ����,�ⲻ��������ص㡣
����һ��,����֪������μ���һ��ӳ���ϵ��
Mapping Origin and Destination
����mapping destination
A
S
p
A^{Sp}
ASp?
������M������,��train M(M-1)/2��SVMs����,Ȼ��ʹ��һ��һͶƱ���Խ���SVMs����ϡ����������������DZ������ҵ����ֺ�4����ļ�����ƽ�����,��ƽ�����֮��ź�ȷ���������ĺ����ֵ����ƽ��ĸ���Ҳ��M(M-1)/2��
����ƽ���ҳ�����,��Ϊ֧��������λ�ڸ�����ƽ���ϵĵ�,����ζ����������÷����,������Դ������ѵ��֮��Ҫ��ȥ֧��������
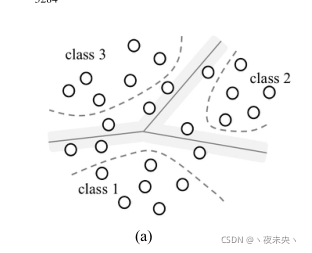
prototype(ԭ��),Ҳ��������Ϊ��������ÿ��������ġ�
����destination point of a sample
x
��
R
m
x\in R^{m}
x��Rm ?
��һ�ַ�ʽ:Nearest Prototype�ⲿ��������ͦ��ʱ��,��ͼ˵��һ�¡�


һ������������кܶ����������,�����ǵõ�һ���µ�origin��ʱ��,���������ڵ��Ǹ������������ľ������ĵ�����,���ԲŻ�����ͼ������ o 1 o_{1} o1?����ôԶȥ�� p 11 p_{11} p11?��Ϊdestination��ԭ��,��Ϊ��������һ���, p 12 p_{12} p12?������Զ��
�ڶ��ַ�ʽ:Gaussian Model


��ͼ�Ѿ�����������ô��destination����,����ÿһ������һ��Gaussian Model,destination��λ��origin��
��
\mu
�������ߺͷֲ��߽�Ľ��㡣
Confidence Setup
���������ֲ���������STM:
- ֻʹ��Ŀ�����е��б�ǩ���ݵ��мල����,����һ���Ƶ�ʽǨ��ѧϰ����
- ��ʹ��Ŀ�����е��б�ǩ����,Ҳʹ��Ŀ�����е��ޱ�ǩ���ݵİ�ල����,����һ��ֱ��ʽǨ��ѧϰ����
�ڼලѧϰ��,���Dz���Ҫ�������Ŷ�,���仰˵���Ŷ�Ϊ1.�ڰ�ලѧϰ��,���Ŷȷdz���Ҫ������δ��ǵ�����,������Ҫ�Ƶ������ı�ǩ,������Ӧ�������ҵ�ӳ���Ŀ�ĵء�����Ƶ����ı�ǩ�Ǵ����,STM���Ὣ����ӳ�䵽�����Ŀ�ĵء�
���������н�����,Ҫ����STM�ȵ�֪��origin�ı�ǩ,�������ĸ���,��������ȥ��origin���������������ľ�������
p
i
j
p_{ij}
pij?�������originû�б�ǩ��?��������Ŷ���ʵ��������α��ǩ�Ŀ��Ŷȡ����Ŀ�������ޱ�ǩ������,����ֻ���ȸ�һ��α��ǩ�������ܽ�һ������STM��
��������������Ŷȵ����÷�ʽ:

dist1 is the distance between the datum and its nearest prototype (e.g., in class 1), and dist2 is the distance between the datum and its nearest prototype in the rest of the classes (e.g.in class 2). The larger the value dist2?dist1 is, the higher confidence we gain when deducing its label.
The confidence is defined as:
F
(
x
)
=
��
(
d
i
s
t
2
?
d
i
s
t
1
)
F\left ( x \right )=\psi \left ( dist2-dist1 \right )
F(x)=��(dist2?dist1)
��
(
c
)
=
1
1
+
e
��
c
+
��
\psi \left ( c \right )=\frac{1}{1+e^{\theta c+\pi }}
��(c)=1+e��c+��1?
The two parameters are determined by cross-validation. For simplicity ,we designate �� \theta �� as -1 and �� \tau �� as 1.

���㷽ʽ�͵�һ��һ��,���������x��˹ģ�;�ֵ������������x��prototypes(�����)������롣
�����ּ������Ŷȵķ�ʽ����:

The distances between a datum
x
��
R
m
x\in R^{m}
x��Rm and each hyper-planes are
d
i
s
t
i
=
W
i
x
+
b
i
��
W
i
��
2
dist_{i}=\frac{W_{i}x+b_{i}}{\left \| W_{i} \right \|^{2}}
disti?=��Wi?��2Wi?x+bi??
c
=
��
w
i
d
i
s
t
i
c=\sum w_{i}dist_{i}
c=��wi?disti?
F
(
x
)
=
��
(
c
)
F\left ( x \right )=\psi \left ( c \right )
F(x)=��(c)
Algorithm Implementation


���ݴ���
DE����,�и�Ϊ1sƬ��û��overlap,����Ԥ������ʽ�����dz��淽ʽ��
Baseline Method
ʹ�ü��ɷ�������Ϊ���߷���,����ʹ��ͶƱ��Ȩ�������Ϸ�����,ͶƱȨ������������У���ݵķ���ȷ�ʾ�����15�������ߵ���һ����ʵ���ƽ��ȷ��Ϊ76.2%
Transfer Learning With Multisource STM
ʹ��K-means++Ϊÿ������ҳ�15����������,���ظ�10�ξ��������Ѱ�ҿɿ��ľ������ġ�
���

No SV:֧��������ȥ����,SV ֧�����������������ˡ�
�ܵ���˵,��һ���ԵĽ��,ֻ�������ı����б�ǩ������õ�������88.92%,���������б�ǩ�Ӵ����ޱ�ǩ���������91.31%��
�������Ǽ�ƪ��������Ӧ(Domain Adaption)����(Domain Generalization)������,���Ի��ء�
Generalizing to Unseen Domains:A Survey on Domain Generalization
Categorize recent algorithms into three classes:
- data manipulation
- representation learning
- learning strategy
Introduction
�ڶ���:������������,�����������������о�����Ĺ�ϵ��
������:չʾ������������ۡ�
���Ľ�:���˼����д����Ե�DG������
�����:����һЩӦ��
������:����DG��һЩ�����ݼ�
���߽�:�������й����ļ����δ��������չ����
Background



- Multi-task learning:�����Ż����ģ���ڶ����ص�������,ͨ������Щ����֮�����representations,�����ܹ�ʹ��ģ����ԭ�����ϵõ����õķ����ԡ�������Ҫע���һ����,������ѧϰ��Ŀ�IJ���Ϊ����һ��new unseen task�ϵõ����õķ����ԡ����ڶ���������ѵ����ԭ����Ϊÿ��ԭʼ����ѧϰ�õ�ģ��,�������µIJ�����
- Transfer learning:��Դ����ѵ��һ��ģ��������Ŀ�����ϵõ��õ�performance,��DG��,���ܷ���Ŀ����
- Domain adaptation:DA��Ŀ��Ҳ���ڸ���ѵ��Դ��������ϣ��ѵһ����Ŀ�������ܵĺõ�ģ�ͳ���������DA��DG��ͬ����,DG���ܿ�Ŀ��������,��DA���Կ�Ŀ��������,��ʹ��DG��DA������ս��,����ʵ��Ӧ���и���ʵ��������
- Meta-learning:Ŀ��ͨ����ǰ�ľ����������ѧϰ�㷨������metal-learning��ѧϰ�����Dz�ͬ��,����DG�е�ѧϰ��������ͬ�ġ�Meta-learning ��һ�ֿ��Ա�����DG�ϵĹ㷺��ѧϰ���ԡ�
- Lifelong Learning:��ע�����ڶ���������/����֮���ѧϰ������Ҫ��ģ��ѧϰ��֪ʶ/�����ͬʱ������֪ʶ����Ҳ���Կ�Դ�����ݡ�
- Zero-shot learning:Ŀ���Ǵӿ��ļ�������ѧϰģ��,��ѵ���п����������������з��ࡣ
- Distributionally Robust optimization(DRO):����ֲ������ѧϰһ��ģ��ϣ���ܹ��ڲ��Լ��Ϸ��������Ƚ�ǿ�����������ע�����Ż�����,DRO��������DG,����DGҲ���Բ���DRO,����data manipulation ����representation learning�ķ��������
Theory
Domain generalization
�����ۿ��ǵ���Ŀ������ȫ��֪�����������п��ܵ�Ŀ�����ƽ�����ա�


The space of
h
h
his taken as a reproducing kernel Hilbert space(RKHS)
������hҲ�����ڷֲ�
P
x
Px
Px,���RKHS���ں�Ӧ�ö���Ϊ
k
��
(
(
P
X
1
,
x
1
)
,
(
P
X
2
,
x
2
)
)
\bar{k}\left ( \left ( P_{X}^{1},x_{1} \right ),\left ( P_{X}^{2},x_{2} \right ) \right )
k��((PX1?,x1?),(PX2?,x2?))
Methodology
Data manipulation
�����ڴ����ݳ���,����ѧϰ����һ���representation��һ�������ּ���:Data augmentation��Data generation.
We formulate the general learning objective of data manipulation-based DG as:

- Domain randomization:It is commonly done by generating new data that can simulate complex environments based on the limited
training samples.such as: altering the location and texture of objects, changing the number and shape of objects, modifying the illumination and camera view, and adding different types of random noise to the data.- Adversarial data augmentation:Adversarial data augmentation aims to guide the augmentation to optimize the generalization capability, by enhancing the diversity of data while assuring their reliability.
�����������ñ�Ҷ˹����Ա�ǩ�����������ʵ��֮���������ϵ���н�ģ,�����һ�ֽ�����������ǿ����CrossGrad,�ò�����������仯���ķ����Ŷ�����,ͬʱ�������ٵظı�����ǩ�����������һ�ֵ�������,���õ�ǰģ���¡�Ӳ��������Ŀ�����е�����������Դ���ݼ�,��ÿ�ε��������ӶԿ��Ե�����,��ʵ������Ӧ���������䡣�����෴��ѵ���任���������������,������ͨ���ݶ�����ֱ�Ӹ������롣
- Data generation-based DG:Here, the function mani(��)can be implemented using some generative models
such as V ariational Auto-encoder (V AE) , and Generative Adversarial Networks (GAN) .

������������ģ��֮��,MixupҲ��һ�����е��������ɼ�����Mixupͨ��ʹ�ô�Beta�ֲ�������Ȩ������������ʵ��֮���Լ����ǵı�ǩ֮��ִ�����Բ�ֵ������������,�ⲻ��Ҫѵ������ģ�͡����,�м���ʹ��DG��Mixup�ķ���,ͨ����ԭʼ�ռ���ִ��Mixup������������,�����������ռ���ִ��Mixup������ԭʼѵ������,�������ռ䲻��ʽ������ԭʼѵ������,��Щ���������еĻ�������ȡ�����������������,ͬʱ�ڸ���ͼ����϶����ּ�
Representation learning
����������������е�,Ҳ�����ִ�������:Domain-invariant representation techniques��Feature disentanglement
Domain-invariant representation techniques:ִ�к�,�Կ���ѵ��,��֮�����ʾ��������������С����ѧϰ������
Feature disentanglement:��ͼ�������ֽ�����������ض��IJ���,�Ի�ø��õķ�����
We decompose the prediction function h as
f
��
g
f\circ g
f��g,where g is a representation learning function and f is the classifier function. The g is a representation learning can be formulated as:

where
l
r
e
g
l_{reg}
lreg? denotes some regularization term and
��
\lambda
�� is the tradeoff parameter.
Domain-invariant representation learning
Kernel methods
���ں˵Ļ���ѧϰ�����ں˺�����ԭʼ���ݱ任����ά�����ռ�,������Ҫ����ÿռ������ݵ�����,���Ǽؼ��������ռ������ж�����֮����ڻ���
���д����Եľ���SVM����������˵,�������㷨���ں˷���,representation learning function
g
g
g������һЩ�˺���,����RBF��,Laplacian�ˡ�

Domain adversarial learning
����GAN�ķ���
��1��V . K. Garg, A. Kalai, K. Ligett, and Z. S. Wu, ��Learn to expect the unexpected: Probably approximately correct domain generalization,�� arXiv preprint arXiv:2002.05660, 2020.
��2��A. Sicilia, X. Zhao, and S. J. Hwang, ��Domain adversarial neural networks for domain generalization: When it works and how to
improve,��arXiv preprint arXiv:2102.03924, 2021.
��3��I. Albuquerque, J. Monteiro, T. H. Falk, and I. Mitliagkas, ��Adversarial target-invariant representation learning for domain generalization,��arXiv preprint arXiv:1911.00804, 2019.
Explicit feature alignment(��ʽ��������)
�ܵ���ͨ����С��Wasserstein���������벻ͬԴ��ı�Ե�ֲ�,�Ӷ������������ռ䡣
F. Zhou, Z. Jiang, C. Shui, B. Wang, and B. Chaib-draa, ��Domain generalization with optimal transport and metric learning,��ArXiv, vol.
abs/2007.10573, 2020.
BN�㱻������-ʵ����һ��(BIN)��ȡ��,BIN��ͨ��ѡ���Ե�ʹ��BN��IN����Ӧ��ƽ��ÿ��ͨ����BN��IN��
H. Nam and H.-E. Kim, ��Batch-instance normalization for adaptively style-invariant neural networks,�� inNeurIPS, 2018, pp. 2558�C2567.
������Ҫ����һ����Instance Normalization�ķ���,���Instance Normalization�ĸ��ַ�����
Invariant risk minimization(IRM)
�������
Feature disentanglement-based DG(������������������DG):
���ڽ������������ͨ�����Խ������ֽ�Ϊ����������/������,����һ���������������߲��������,��һ��������ÿ�����Լ����ض�������
���ڽ���������㷨���Ż�Ŀ����Ը���Ϊ:

g
c
g_{c}
gc?:domain-shared representations
g
s
g_{s}
gs?:domain-specific representations
The loss
l
r
e
g
l_{reg}
lreg?��ʽ�ع������빲����, The loss
l
r
e
c
o
n
l_{recon}
lrecon?��ʾ��ֹ��Ϣ��ʧ��һ���ؽ���ʧ��
Note that
[
g
c
(
x
)
,
g
s
(
x
)
]
[g_{c}(x),g_{s}(x)]
[gc?(x),gs?(x)]denotes the combination/integration of two kinds of features(which is not limited to concatenation operation)
���ڽ�����ķ�����Ҫ������,multi-component analysis and generative modeling

Peng et al. disentangled the fine-grained domain information and category information that are learned in VAEs.
[1]X. Peng, Z. Huang, X. Sun, and K. Saenko, ��Domain agnostic learning with disentangled representations,�� in ICML, 2019.
[2]M. Ilse, J. M. Tomczak, C. Louizos, and M. Welling, ��Diva: Domain invariant variational autoencoders,�� in Proceedings of the Third Con-ference on Medical Imaging with Deep Learning, 2020.
Learning strategy
����������ڿ���ͨ��ѧϰ��������߷�������,��Ҫ�������ַ���:
Ensemble learning:�������ɵ�����ѧϰͳһ�ġ������Ԥ�⺯��;
Meta-learning:����ѧϰ-ѧϰ����,ͨ������Ԫѧϰ������ģ������ת����ѧϰһ��֪ʶ;
Gradient:��ͼͨ��ֱ�Ӷ��ݶȽ��в�����ѧϰ������ʾ������,����������ѧϰ����Ҳ��������DG,���ǽ����ǹ���Ϊ����ѧϰ���ԡ�