ЧАбд
ГЂЪдвЛЯТгУMnistЪ§ОнМЏбЕСЗвЛИіМђЕЅЕФCNNЭјТч,ШЛКѓДюНЈвЛИіОВЬЌвГУц,дкфЏРРЦїЖЫМгдиФЃаЭЪЙгУcanvasЧјгђЕФФкШндЄВтЪжаДЪ§зжЁЃФЃаЭЪЙгУPytorchБраД,гУcpuбЕСЫ10ИіepochжЎКѓЕМГіЮЊonnxФЃаЭЁЃжЎКѓдкфЏРРЦїЖЫЭЈЙ§onnxruntime-webНјааМгди,ВЂНјаадЄВтЁЃ
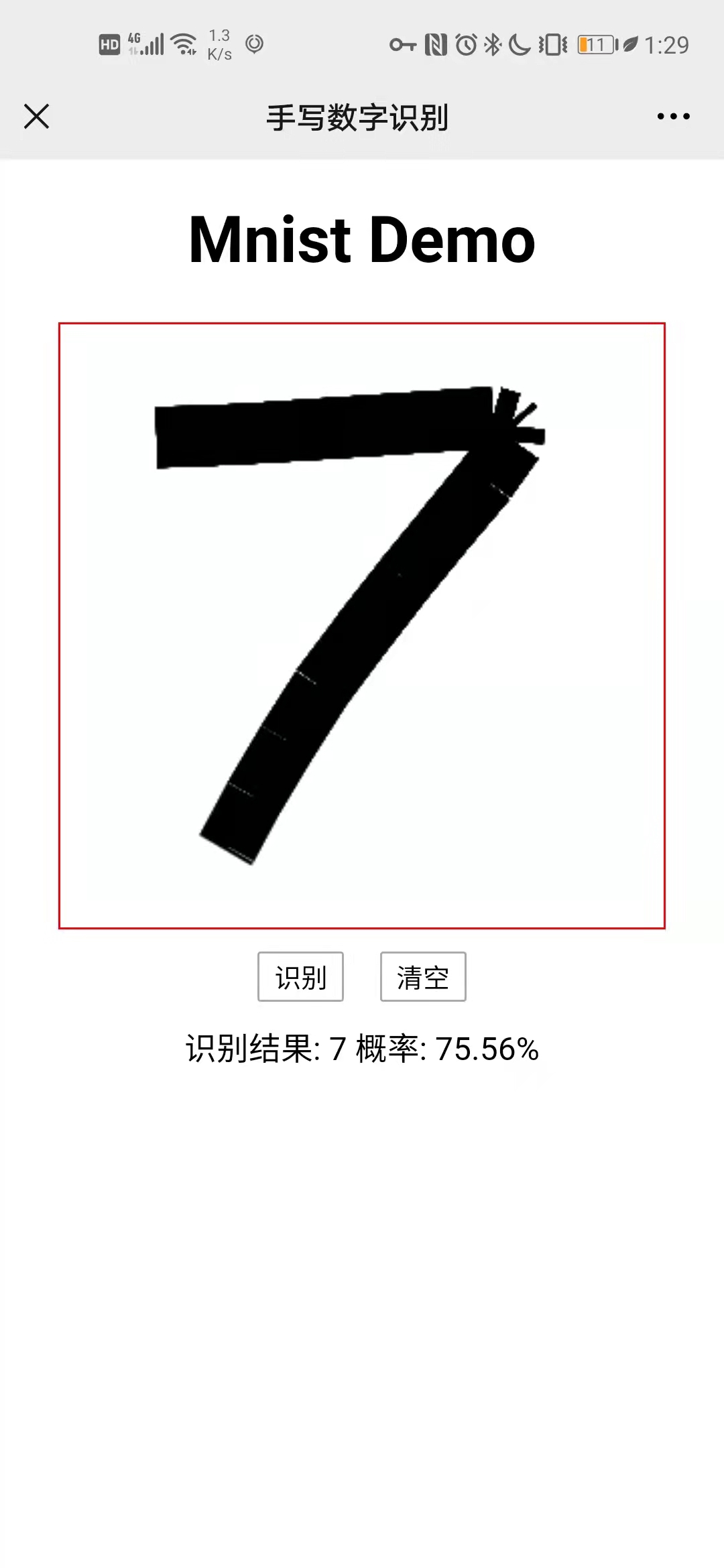
ФЃаЭ
ФЃаЭДњТыЦфЪЕЭјТчЩЯвбОгаКмЖрСЫ,дРэКЭЯИНквВВЛдйзИЪі;ашвЊзЂвтЕФЪЧ,ЪфШыЪЧвЛИіBatchsize x 1 x 28 x 28 ЕФОиеѓ,ЪфГіЮЊBatchsize x 10ЕФОиеѓвВОЭЪЧЫЕЕквЛЮЌЪЧЖЏЬЌЕФ,етОЭОіЖЈСЫЮвУЧдкЕМГіЮЊonnxФЃаЭЪБЕФаДЗЈ:
def transformToOnnx(model, batch_size, name='mnist.onnx'):
model.eval()
x = torch.randn(batch_size, 1, 28, 28)
torch.onnx.export(model, x, name, export_params=True, opset_version=11, do_constant_folding=True, input_names=[
'input'], output_names=['output'], dynamic_axes={'input': {0: 'batch_size'}, 'output': {0: 'batch_size'}})
ЪзЯШашвЊЪЙгУmodel.eval()НЋФЃаЭЧаЛЛЮЊдЄВтФЃЪН,НгЯТРДЮвУЧЫцЛњЩњГЩвЛИіЪфШыЕФВЮЪ§,вВОЭЪЧBatchsize x 1 x 28 x 28ДѓаЁЕФвЛИіЫцЛњОиеѓЁЃдкЕМГіЪБашвЊжИЖЈЕМГіЕФТЗОЖ,ЪфШыКЭЪфГіЕФЗћКХ(ЩЯБпЕФаДЗЈвтЫМЪЧдкКѓајМгдиФЃаЭЕФЪБКђ,ЪфШыБфСПУћЮЊinput,ЪфГіБфСПУћЮЊoutput)ЁЃЭЌЪБгЩгкЪфШыКЭЪфГіЕФЕквЛЮЌЖМЪЧbatchsize,вђДЫАбЫќУЧжИЖЈЮЊЖЏЬЌжсЁЃ
ЧАЖЫЪЕЯж
ГѕЪМЛЏЙЄГЬ
ЪзЯШВЩгУviteГѕЪМЛЏвЛИіreact-tsЯюФП,етвЛВНУЛгаЬЋЖрзЂвтЪТЯюЁЃ
ФЃаЭЕФМгдиКЭдЄВт
ЮЊСЫМгдиФЃаЭ,ЮвУЧашвЊЪЙгУonnxruntime-webЁЃonnxruntime-webЪЧвЛИіПЩвддкфЏРРЦїЛЗОГЯТКЭnodejsЛЗОГЯТМгдиonnxФЃаЭЕФПт,ПЩвддкCPUКЭGPUЩЯдЫаа,CPUЪЙгУweb assamblyРДМгдиФЃаЭ,ЖјGPUЪЙгУWebglРДМгди,ФЌШЯдЫаадкCPUЩЯЁЃСНжжЗНАИжЇГжЕФЗћКХМЏВЛЭЌ,wasmЗНЪНжЇГжШЋВПЕФЗћКХМЏ,ЖјwebglЗНЪННіНіжЇГжвЛВПЗжЗћКХМЏ(ОпЬхЕФЫЕУїВЮПМЮФЯз[1]);Г§ДЫжЎЭт,дкiosЕФchromeЁЂedgeКЭsafariфЏРРЦїжаНіжЇГжwasmЁЃБОДЮаЁЪЕбщЕМГіЕФФЃаЭШчЙћВЩгУwebglМгди,ОЭЛсгіЕНЩЯБпЬсЕНЕФЗћКХМЏЕФЮЪЬт,вђДЫВЩгУwasmМгдиФЃаЭЁЃЮвУЧжЛашвЊ:
yarn add onnxruntime-web
БуПЩвддкЙЄГЬжаАВзАетИіАќСЫЁЃ
НгЯТРДЮвУЧашвЊЖдviteЙЄГЬНјаавЛаЉХфжУЁЃгЩгкviteдкЦєЖЏserverЪБгавЛИіpre-bundleЕФЙ§ГЬ,ЪЙгУesbuildНЋИїжжЗЧБъзМЕФФЃПщзЊЛЏЮЊes6ФЃПщЁЃonnxruntime-webжаЪЙгУЕНСЫexport namespace xxЕФаДЗЈ,етаЉЛсдкpre-bundleЕФЪБКђБЈДэ,вђДЫЮвУЧПЩвдбЁдёЭЈЙ§pre-bundleЙ§ГЬ;
ЭЌЪБ,МДБуЮвУЧЬјЙ§СЫpre-bundleЕФЙ§ГЬ,ЮвУЧЛсЗЂЯждкЯюФПЦєЖЏжЎКѓ,onnxruntime-webЛсздЖЏЕФШЅstatic/jsТЗОЖЯТШЅевСНИіwasmЮФМў,ЖјдкЦєЖЏЗўЮёКЭДђАќЕФЪБКђВЂВЛЛсздЖЏЕФМгШыетСНИіЮФМўЁЃЖјШчЙћЮвУЧв§ШыcdnЩЯЕФonnxruntime-webПт,ЮвУЧЛсЗЂЯжЫќЛсздЖЏЕиШЅcdnЕижЗЧыЧѓwasmЮФМў,cdnЩЯетСНИіЮФМўздШЛЪЧДцдкЕФЁЃВЮПМonnxruntimeИјГіЕФdemo[2],ПЩвдПДЕН,ЙйЗНдкЪЙгУwebpackДђАќЕФЪБКђвВЪЧЪЙгУСЫCopyWebpackPluginНЋЖдгІЕФЮФМўПНБДЕНДђАќжЎКѓЕФФПТМжаЁЃЮЊСЫЗНБуПЊЗЂКЭДђАќ,НЈвщЪзЯШЬјЙ§pre-bundleЙ§ГЬ,ШЛКѓВЩгУcdnМгдиonnxruntime-webАќ,ВЂдкvite.config.jsжаЩљУїИУАќЮЊexternal,МД:
// vite.config.js
import { defineConfig } from 'vite'
import react from '@vitejs/plugin-react'
import { viteExternalsPlugin } from 'vite-plugin-externals'
// https://vitejs.dev/config/
export default defineConfig({
plugins: [
react(),
viteExternalsPlugin({ // ЩљУїЮЊexternal
'onnxruntime-web': 'ort'
})
],
optimizeDeps: {
exclude: [ // ЬјЙ§pre-bundle
'onnxruntime-web'
]
},
base: '/mnist-demo/'
})
ШЛКѓдкindex.htmlжаМгЩЯПтЕФcdnЕижЗ:
<script src="https://cdn.jsdelivr.net/npm/onnxruntime-web/dist/ort.min.js"></script>
НгЯТРДЕФЙ§ГЬЦфЪЕОЭКмМђЕЅСЫ,ЮвУЧГЩЙІЕФв§ШыСЫonnxruntime-webПт,ШЛКѓашвЊгУЫќРДМгдиФЃаЭ,ВЂНјаадЄВт:
...
// МгдиФЃаЭ
const session = await ort.InferenceSession.create(model);
// ЪфШыЪ§Он,ЕквЛИіВЮЪ§ЪЧЪ§ОнРраЭ,ЕкЖўИіВЮЪ§inputArrayЪЧвЛИівЛЮЌЪ§зщ,ЕкШ§ИіВЮЪ§БэЪОЕФЪЧЮЌЖШ,зЂвташвЊКЭжЎЧАФЃаЭЕМГіЪБЖЈвхЕФЮЌЖШЯрвЛжТ,МД:dynamic x 1 x 28 x 28
const inputs = new ort.Tensor("float32", inputArray, [1, 1, 28, 28]);
// ЪЙгУrunНјаадЄВт,ашвЊзЂвтЕФЪЧ,ЪфШыКЭЪфГігыжЎЧАЕМГіЪБЖЈвхЕФЪфШыЪфГіБфСПУћвЛжТ
const outputs = await session.run({
input: inputs,
});
// дЄВтНсЙћ
console.log(outputs.output.data);
ЕНДЫЮЊжЙ,дкфЏРРЦїМгдиФЃаЭЕФВПЗжОЭЭъГЩСЫ,НгЯТРДжЛашвЊЯыИіАьЗЈЛёШЁЕНгУЛЇЪфШыЕФЪ§Он,ВЂЪЙгУетаЉЪ§ОнНјаадЄВтЁЃ
ЛёШЁЪфШыЪ§Он
ФЃаЭЪфШыЪЧ1x28x28ЕФЭМЦЌ,ЖјШУШЫдкЦСФЛЩЯЪжЖЏЕФШЅдквЛИі28ЯёЫиx28ЯёЫиЕФЧјгђФкЛцжЦПЯЖЈЪЧИіВЛЯжЪЕЕФЪТЧщ(ЬЋаЁСЫ)ЁЃвђДЫЮвУЧашвЊАбЪфШыЕФcanvasЗХДѓ(етРяВЩгУЕФЪЧ300x300),дкдЄВтЪБЖдЛВМЕФЪфШыНјааЫѕаЁ,ВЂзЊЛЏЮЊЕЅЭЈЕРЁЃ
ЮЊСЫЛёШЁЕНетИі300x300ЧјгђФкЕФЯёЫиЪ§Он,ЮвУЧЪЙгУcanvas.getImageData()ЛёШЁЕНетИіЧјгђФкЕФrgbaЪ§зщЁЃНгЯТРД,ЮвУЧашвЊНЋЫќЫѕЗХЮЊ28x28ЕФДѓаЁЁЃетРяв§ШыСЫpicaПт,ЪЙгУpicaЕФresizeBufferКЏЪ§ЖдЯёЫиЧјгђНјааЫѕЗХЁЃ
гЩгкcanvasЕФФЌШЯбеЩЋЪЧКкЩЋЭИУї,вђДЫЮвУЧФУЕНЕФЪ§зщЕФЗЧЛБЪЧјгђЕФrgbaжЕЮЊ(0,0,0,0)ЁЃЭЌЪБзЂвтЕНФЃаЭЕФЪфШыжа,ЛвЖШЕФШЁжЕЗЖЮЇЮЊ-1-1,вђДЫЮЊСЫБЃСєЕЅЭЈЕР,ЮвУЧБЃСєa,ВЂНЋЦфИљОнЪЧЗёЮЊ0,МђЕЅЕигГЩфЕН-1КЭ1ОЭЙЛСЫЁЃ
ЛЙашвЊзЂвтЕФЪЧ,гЩгкЛВМЛсДг300x300ЫѕЗХЕН28x28,вђДЫcanvasЛБЪЕФДжЯИвВЪЧвЛИігАЯьаЇЙћЕФвђЫи:ШчЙћЛБЪЙ§ЯИ,ЫѕЗХжЎКѓЛВМЧјгђЕФЯёЫижЕЖМЪЧ0,вВОЭУЛгааЇЙћСЫ;ШчЙћЛБЪЙ§Дж,ПЩФмЫѕЗХжЎКѓ,дБОИєзХКмдЖЕФСНИіЧјгђБфГЩСЫСкОг,вВЛсгАЯьаЇЙћЁЃ
зюКѓ,ЮвУЧжЛашвЊИљОнЩЯЪіВйзї,ИљОнЫѕЗХЁЂДІРэЙ§КѓЕФЪ§зщЙЙНЈЪфШыЕФTensor,ВЂДЋШыФЃаЭНјаадЄВтОЭПЩвдСЫЁЃ
змНс
ЕНетРя,ЦфЪЕФЃаЭЕФМгдиЁЂдЄВтКЭШчКЮЛёШЁЪфШыЪ§ОнЖМвбОЭъГЩСЫЁЃзюКѓОЭЪЧАбвдЩЯЕФЖЋЮїДЎЦ№РДЁЃЪЕМЪЕФаЇЙћОЭЪЧзюЩЯБпСНеХЭМЕФбљЪН,ЮвАбЫќЗХдкСЫgitee pageЩЯ,ЪЕВтЭјТчЧыЧѓЕФЫйЖШЛЙПЩвдНгЪм:
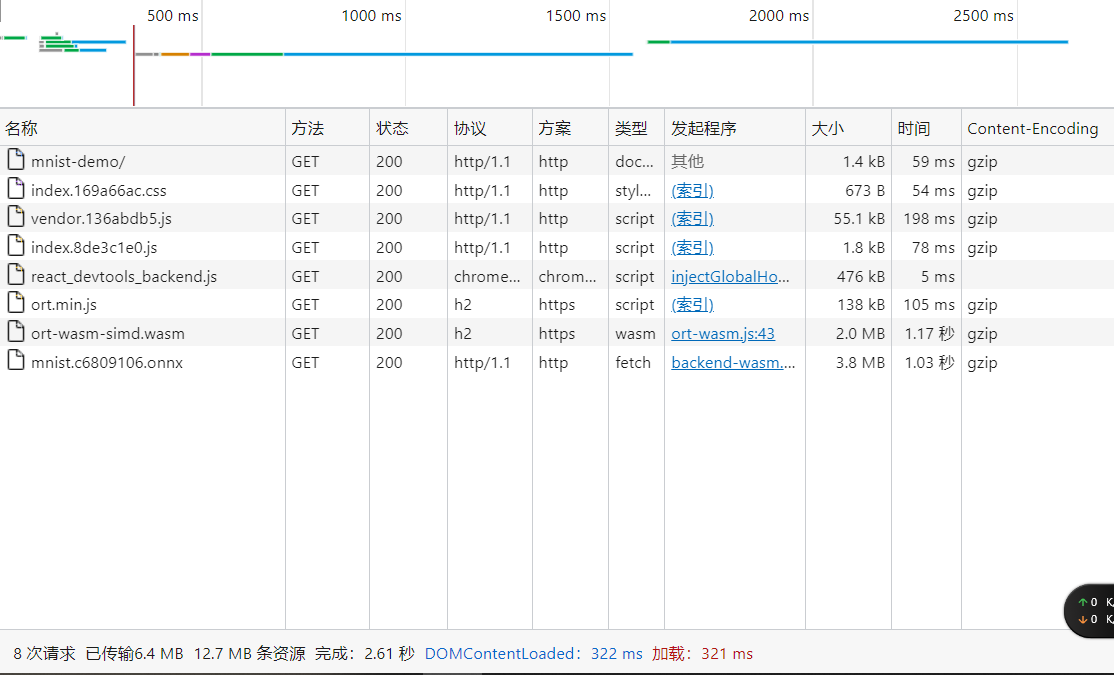
ЭЌЪБЮввВАбЫќВПЪ№дкЮвЕФЗўЮёЦїжа,ФЃаЭЖЊЕНcdnЩЯ,ЫйЖШвВЛЙПЩвдНгЪм(gzipЖдФЃаЭКУЯёбЙВЛСЫЖрЩйбНЁЃЁЃ):
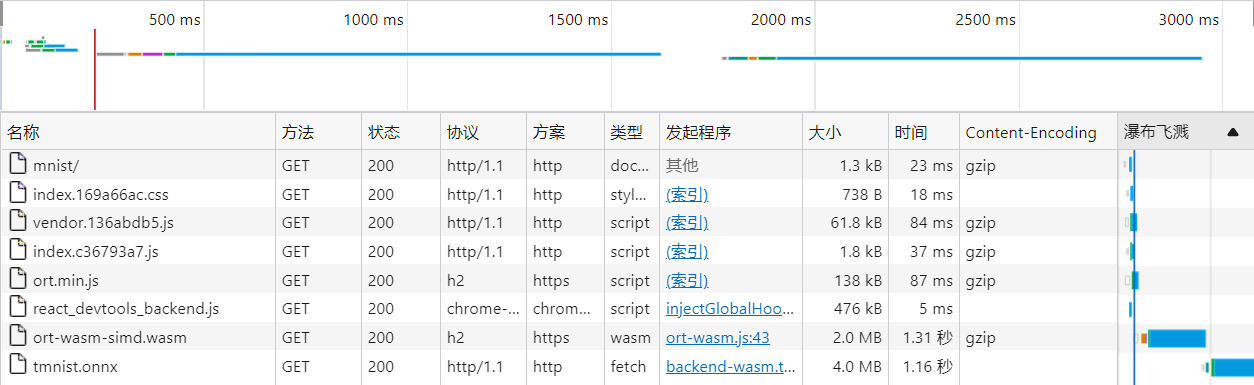
вВОЭЪЧЫЕ,ЖдгквЛаЉМђЕЅЕФФЃаЭ,ЮвУЧЭъШЋПЩвдЖЊЕНgitee pageЩЯНјааЪЙгУ,ЛЙЪЧТљКУЭцЕФЁЃ
зюКѓЖЊИівГУцЕижЗКЭВжПтЕижЗ,гаШЫашвЊЕФЛАЮвдйШЅВЙreadme,ЧђЧђЕуИіЙизЂКЭstarАЩ:
вГУцЕижЗ:
ВжПтЕижЗ:
ВЮПМЮФЯз
[1] onnxruntime web: https://www.npmjs.com/package/onnxruntime-web#Operators
[2] onnxruntime-webЪЙгУdemo https://github.com/microsoft/onnxruntime-inference-examples/tree/main/js/quick-start_onnxruntime-web-bundler